Kafka官方网站: https://kafka.apache.org/
KafKa 的安装
KafKa使用 Scale进行开发,由于 Scale 运行在 JVM 上面,所以需要 JDK 的环境
- 首先需要到官方网站下载
Kafka, 并且解压 Kafka的启动,可以使用zookeeper或者KRaft启动
- 使用
Zookeeper启动,进入到kafka/bin目录其中就是启动需要的脚本文件,kafka/config其中就有zookeeper的配置文件,启动命令如下:
# 1. 启动 zookeeper 服务器 zookeeper 默认监听 2181 端口
sudo ./zookeeper-server-start.sh ../config/zookeeper.properties &
# 2. 启动 kafka
sudo ./kafka-server-start.sh ../config/server.properties &
# 3. 关闭 kafka
sudo ./kafka-server-stop.sh ../config/server.properties
# 4. 关闭 zookeeper
sudo ./zookeeper-server-stop.sh ../config/zookeeper.properties
顺便补充一下查看进程和端口的命令:
# 查看监听的端口和进程
netstat -nlpt
# 查看进程
ps -ef | grep ProcessName
# 查看端口
lsof -i :port
- 使用
KRaft启动Kafka, 基本思路一样的:
# 1. 生成 Cluster.UUID (集群 UUID)
sudo ./kafka-storage.sh random-uuid
# 2. 启动 KRaft
sudo ./kafka-storage.sh format -t wYart7pTRQaBmxuySsmbIQ -c ../config/kraft/server.properties
# 3. 启动 Kafka
sudo ./kafka-server-start.sh ../config/kraft/server.properties
-
基于
Docker部署Kafka参考 docker -
https://blog.csdn.net/m0_64210833/article/details/134199061
Kafka的基本使用
这一个部分参考 Kafka官方文档,培训班的视频真的是太拖泥带水了 ...
Kafka是一个分布式流处理平台,具有发布和订阅流式的记录,和消息队列类似,可以存储流式的记录,同时也可以在流式记录产生的时候进行处理,可以用于构建实时流数据管道,或者构建实时流式应用程序
Kafka中的一些基本概念:
Kafka作为一个集群,可以运行在一台或者多台服务器上面Kafka通过topic对于存储的流数据进行分类- 每一条记录中包含一个
key, 一个value和一个timestamp
Kafka中包含四个核心的 API:
Producer API: 允许一个应用程序发布流式数据到Kafka topic中,可以理解为所有数据都发送到一个Kafka集群进行处理Conumser API: 允许一个应用程序订阅一个或者多个topic,并且对于发布给他们的流式数据进行处理Stream API: 允许一个引用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流道一个或者多个topic中Connector API: 允许构建并且运行可以重用的生产者或者消费者,将Kafka topics连接到已经存在的引用程序或者数据系统中
我的理解 Producer 和 Consumer 构成消息队列 , Stream 构成数据处理系统,Connector的作用就是可以把这三者连接到Kafka集群中进行一个消息的处理和消费活动
入门
Topics 和 日志
Topics 是 Kafka中的核心,也就是数据主题,可以用于区分业务系统,总是多订阅者模式的,同时一个 topic可以拥有一个或者多个消费者来订阅它的数据,对于 每一个 topic , Kafka维护一个分区日志,每一个分区中存储 commit.log 文件,并且分配一个 id 号表示顺序,称之为 offset , 可以使用 offset 表示分区中的每一条记录
同时在每一个消费者中唯一保存的元数据就是 offset , 也就是消费者在 log 中的偏移,偏移量由消费者控制,通常在读取记录之后(感觉和 Redis中消费者组的概念差不多)
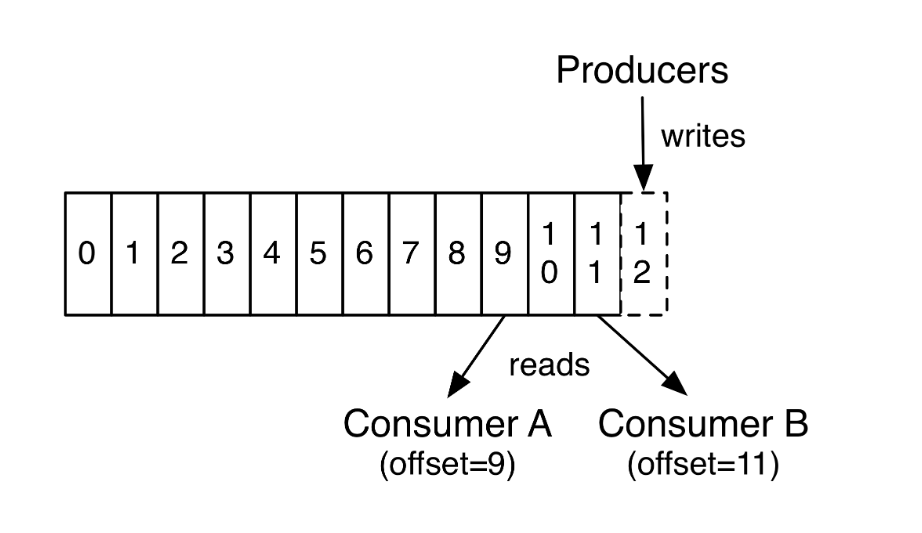
生产者
可以将时局发布到选择的 topic 中,生产者负责将记录分配到 topic 的哪一个分区(partition)中,并且使用循环的方式简单实现负载均衡
消费者
使用消费者组进行标识,但是注意到其实消费者就是一个独立的个体,每一个消费者作为消息读取的独立单位,并且注意到 Kafka只是保证分区内的记录有序,但是不保证 topics 中不同分区中的顺序,每一个 partion 按照 key 值排序即可满足需求
Kafka 作为消息系统(消息队列)
和其他的消息队列基本一样,也就是分为消费者和生产者两个角色,并且中间的消息队列也就是 kafka中的 和 topics以及其中的 partition
Kafka 基本使用
~~和
Redis相比,简直不要太简单
当然所有消息队列的基本使用都一样,都是创建生产者和消费者,生产者向队列中发送消息,消费者从消息队列中取出消息并且进行消息的处理,应该有 Kafka 的客户端
- 创建一个
topic,比如创建一个名为test的topic,拥有一个分区和一个副本:
`> bin``/kafka-topics``.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic` `test`
- 发送一些消息
`bin``/kafka-console-producer``.sh --broker-list localhost:9092 --topic` `test`
- 启动一个
consumer
`> bin``/kafka-console-consumer``.sh --bootstrap-server localhost:9092 --topic` `test` `--from-beginning`
go操作 kafka
- 直接参考: https://www.liwenzhou.com/posts/Go/kafka-go/ 就可以了,重点就是
Reader和Writer的使用,以及消息的发送和读取方式等