这里梳理一下
OSTEP中对于虚拟内存的说明,本书的组织方式: 机制->策略,并且介绍策略的时候首先提出简单的假设,之后根据假设建立模型,并且论述模型的的特点,最后引出模型的缺点,最后根据缺点提出新的模型, 虚拟内存这一块的组织方式: 简单的存储和地址转换方式 -> 分段 -> 空闲空间管理 -> 分页 ->TLB硬件翻译 -> 多级分页,分段分页
虚拟内存引入
- 首先书中提出了让多个进程使用同样一个物理内存的方法(利用时分复用的方式,也就是么一个进程使用全部内存的一小段时间),之后就引出了保护的概念
- 为了虚拟出每一个进程独占一个很大的内存空间的假象,引出了虚拟内存的概念,对于虚拟内存需要考虑具备的特点就是: 透明(欺骗进程使得它以为自己独占内存空间),高效率,隔离(使得不同的进程之间隔离)
内存操作API,内存泄漏
- 之后引出了内存操作的
API(malloc,free) - 其中介绍了
strdup(这一个函数在堆区开辟空间并且把s中的内容拷贝到开辟的空间并且返回,返回的结果可以使用free进行释放)
char *strdup(const char *s);
- 另外介绍了监视内存的工具:
purify和valgrind(非常强大)valgrind使用
简单的虚拟内存组织方式
无分段
- 首先书中只是假设每一个进程在物理内存中占用一块特定的区域,所以进行虚拟内存和物理内存映射关系的时候利用一个寄存器存储物理内存的基址和最大的物理地址界限,利用
PA = VA + Base就可以通过虚拟地址计算得到物理地址 - 但是这一种方法的缺点就是一块进程占用的一块地址空间中有多个位置回发生空缺(也就是堆栈之间没有使用的位置),所以会产生许多内部碎片,导致物理内存的空间利用率下降
分段
- 接着提出了分段的概念,也就是根据程序内每一个作用不同的连续存储区域进行分段,比如分成堆栈等区域,有了分段的概念之后,就可以给每一个段一个寄存器用于存储每一个段的基址和界限,所以这样寻址方式还是一样的,只不过此时虚拟地址需要利用前面的几位来确定子集所属的段(
segment),此时虚拟地址的组织方式如下: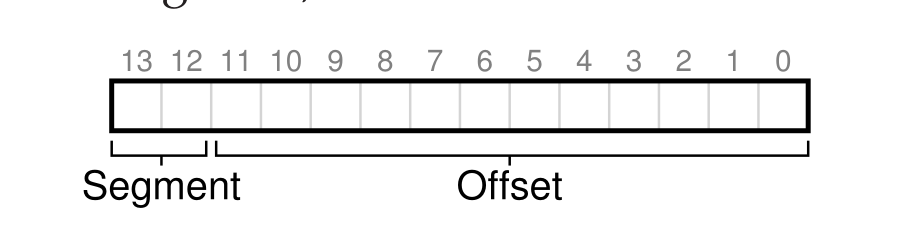
- 这一种方式有效的避免了内部碎片的产生,并且分成的段的大小不一样,所以回造成物理内存的外部碎片增多,导致空间利用率低
空闲空间组织方式
- 主要是利用那一种数据结构来存储各种不同的空闲块,另外如何找到适配指定大小的空闲块,可以参考 csapp 以及
Malloc
分页的组织方式
- 以上产生外部碎片的原因就是物理内存中对于虚拟内存的映射块的大小不固定,产生内部碎片的原因就是给进程分块时,很多块没有使用,为了解决这一种问题,就引出了分页的组织方式
分页
- 分页的方法就是把虚拟内存和物理内存都进行分页,并且利用一个映射关系把虚拟内存中分的块和物理内存中的块联系起来为了反应这一种映射关系,就需要引入页表的概念,页表项(
PTE)中记录了这相应的虚拟页号和实际的物理页号的映射关系,组织方式如下: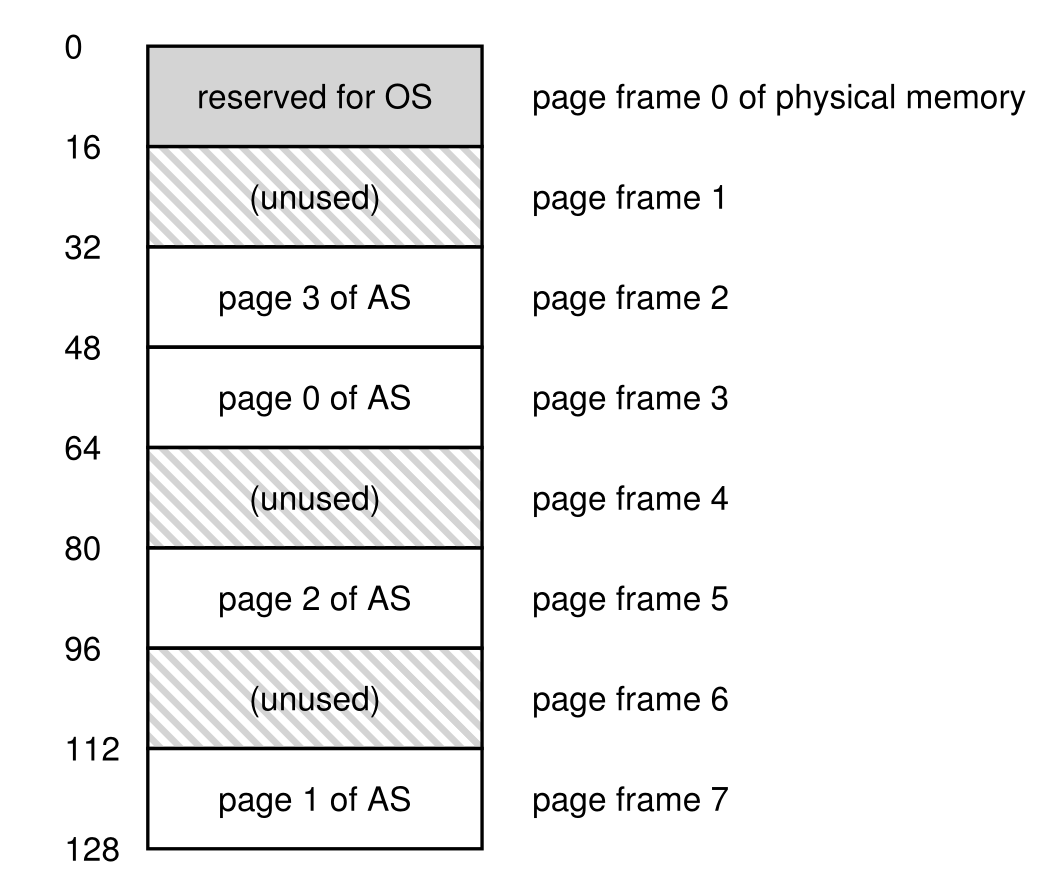
- 一方面为了找到数据在物理内存中的实际地址,虚拟内存中需要记录虚拟页面和偏移量,组织方式如下:
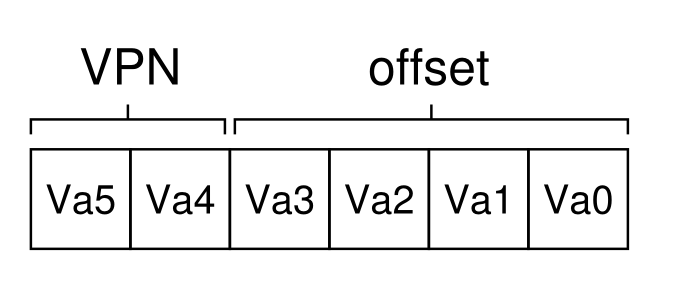
- 对于页表项(
PTE),需要记录VPN和PFN的映射关系,并且还需要各种标志位来记录是否可以访问,是否脏页是否有效等概念,所以组织方式如下:
- 分页存在的问题:
- 页表存在于物理内存中,所以每一次访问一个数据还需要页表(页表的基址存储在一个寄存器中),所以需要两次访问,如果虚拟页表中没有对应的页面还需要在物理内存中分配新的页面并且重试指令
- 页表的大小比较大(比如一个
32位的地址空间,页的大小为4KB,那么需要的VPN个数为$2^{20}$ ,如果一个PTE的大小为4个字节,那么一个页表的代大小就是4MB,如果100个进程,就需要400MB的空间存储页表,就会有很多页表项(就算没有分配的物理页面只是有效位标记为0而已,还是回被存储)) - 另外页表查询比较慢
TLB: 快递地址转换
TLB时MMU中的一个组成部分,用于缓存地址转换关系,也就是记录这VPN和PFN之间的关系,由于TLB距离CPU比较近,所以访问数据的速度相当快,所以利用TLB缓存进行虚拟地址和物理地址转换非常快- 同时对于一个页中的数据,
VPN相同,但是偏移量不同,所以只需要存储一个页面的VPN和PFN之间的关系就可以找到全页的数据 - 对于
TLB未名中的处理方式(软件处理): 当查询到TLB中没有相应的转换的时候,硬件就会发出一个异常,把控制权交给操作系统,操作系统执行相应的异常处理程序,查询物理内存中的页表项并且把页表项更新到TLB中,之后重试这一条指令导致TLB命中 - 对于
TLB中的内容,必须存在PFN和相应的VPN,同时还需要有效位等(这里的有效位仅仅标记是否时有效的地址映射,页表中的有效位标记是否使用这一个页面),同时有一些系统为了方便上下文切换,防止上下文切换的时候失去之前进程的虚拟内存地址映射缓存,还会存储一些与进程PID有关的位,一种TLB中项的组织方式如下:
- 最后谈到缓存一定会讨论的一个主题就是驱逐方式,常见的驱逐方式比如
LRU,LFU等,之后继续讨论 TLB的出现解决了页表访问速度慢的缺点
多级页表和分段
- 为了解决页表过大的问题,提出了两种方法: 分段和分页结合和多级页表
分段和分页结合
- 这里发现页表过大的一个原因就是页表中需要存储地址空间中所有虚拟页面的
PTE,这就会导致很多没有没有使用的地址空间仍然被分页并且占用页表 - 所以解决方法就是给每一个段一个页表,每一个段进行分页,这样一个页表中只需要存储表较少的表项,最重要的是,没有使用的段就没有对应的
PTE了,这就减少了页表占用的空间,此时虚拟地址的组织方式如下:
- 但是这一种方式的缺点就是: 页表的大小不同,回造成比较多的外部碎片
多级页表
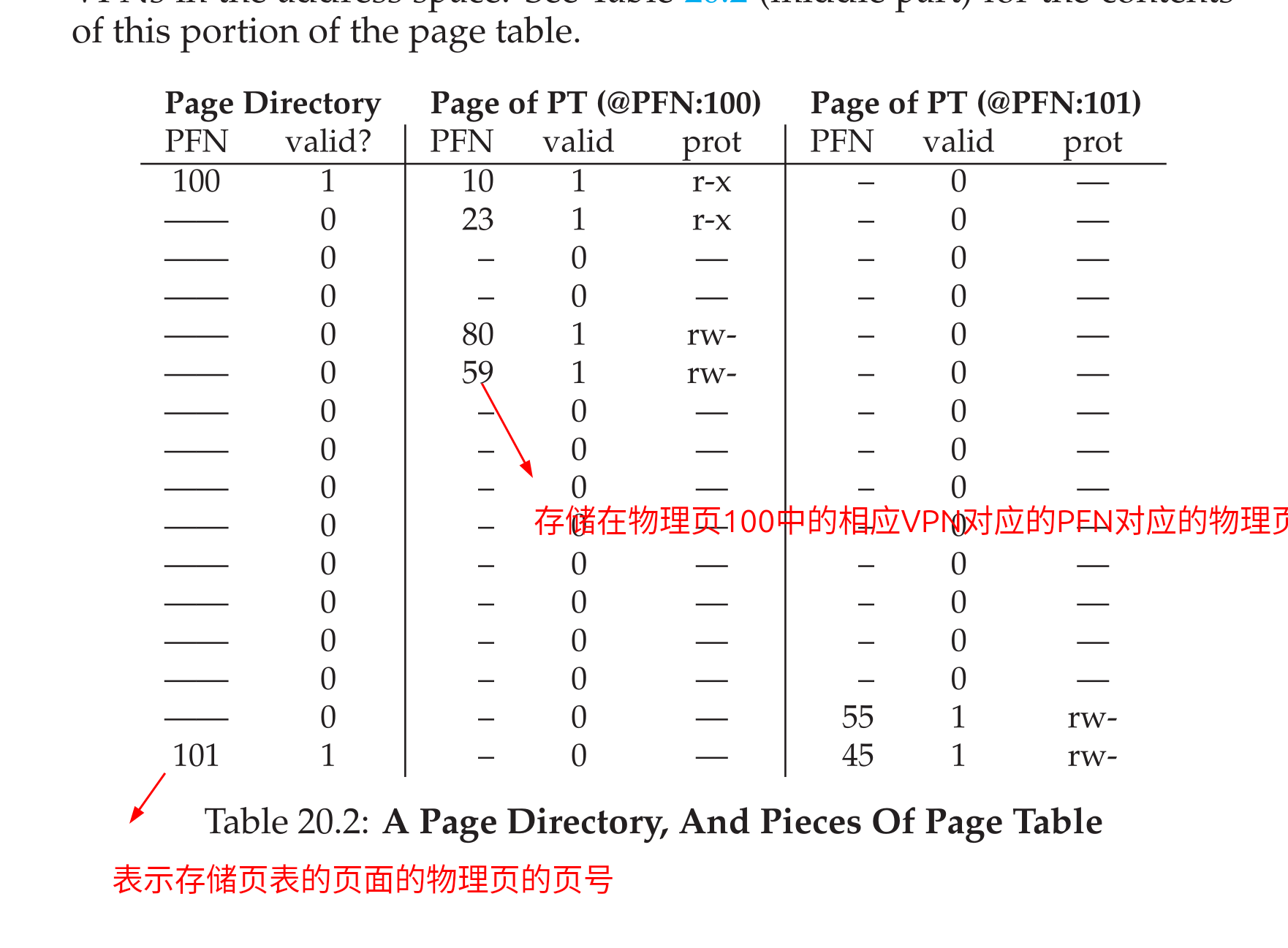
- 核心思想: 把原来的页表分到很多页面中,如果整个页面的页表中都没有有效的数据,直接不分配这一个页的页表即可,同时使用页目录的结构来寻找页表页,组织方式:
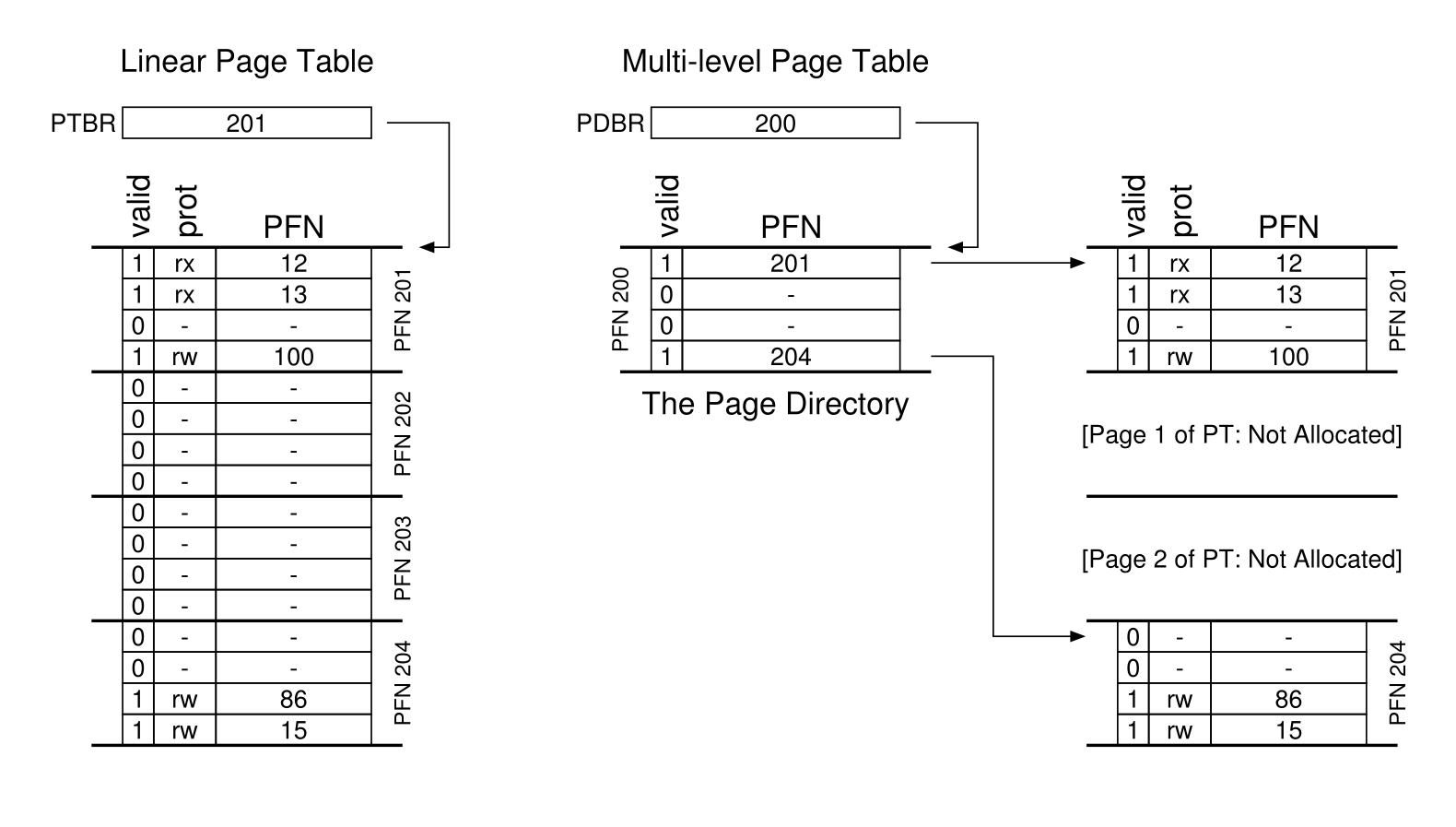
- 所以为了标记页目录和页表的位置虚拟地址的组织方式如下:
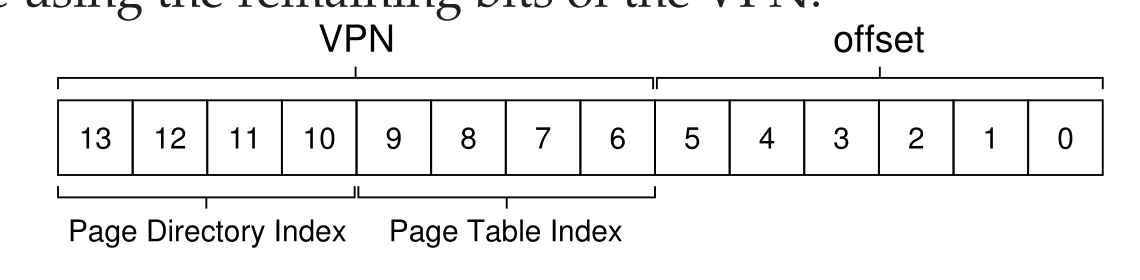
- 另外有时候如果页目录的大小比较大(比如页目录比较到到时无法放入到一个页面中,此时就需要多级分页),比如对于三级页表的虚拟地址的组织方式如下(寻地址方式和二级一样):
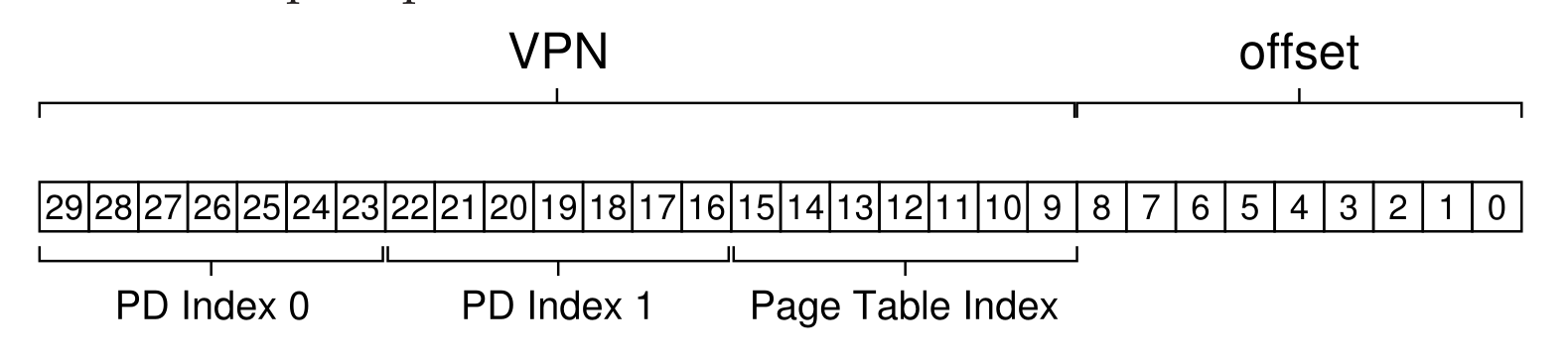
- 利用一个多级页表的缺点就是当
TLB寻址失败的时候就会导致需要多次访问物理内存才可以确定一个地址的实际位置
超越物理内存
机制
- 有时候物理内存比较小,所以我们的目标就是扩展物理内存(比如有时候计算机的内存只有
4GB,却可以运行8GB程序),机制就是使用了交换分区,也就是回利用硬盘中的空间来存储一些页面并且这一部分位置被成为交换分区,交换分区中的分页会与物理内存中的分页进行交换,比如: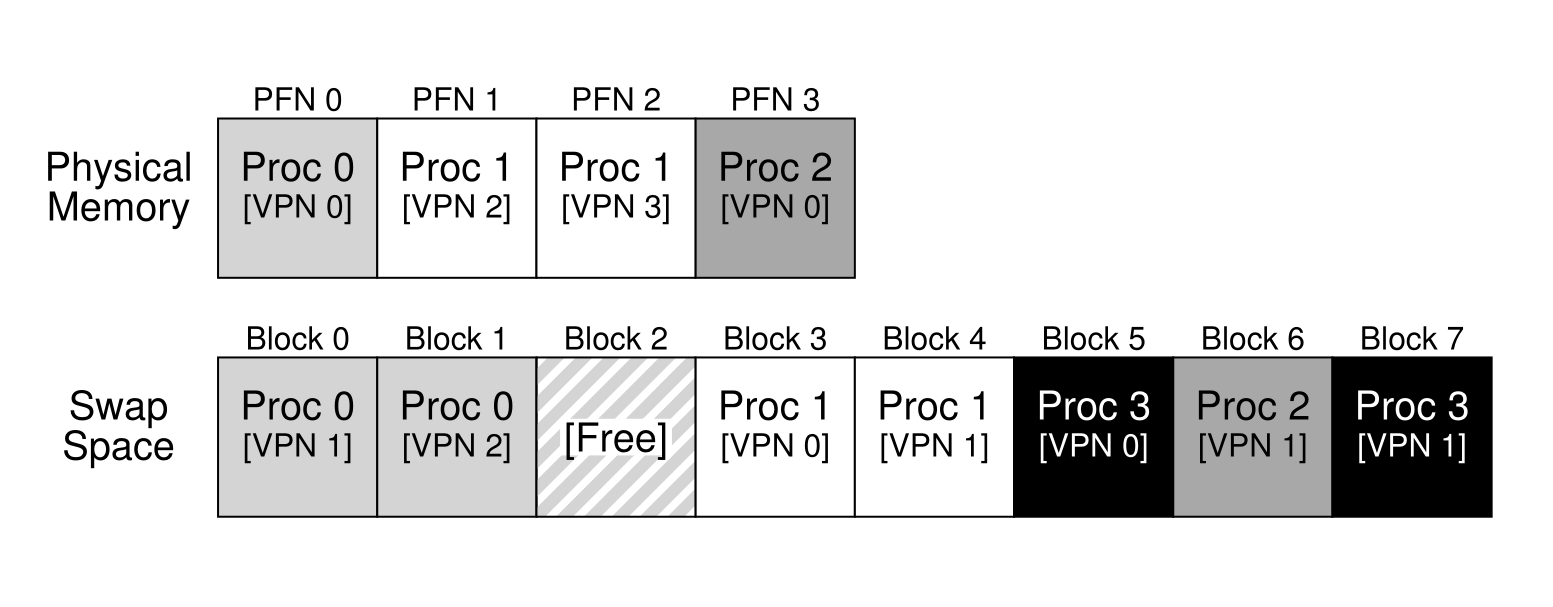
- 为了标记一个页面是否存在于物理内存中,
PTE中利用一个存在位来标记一个页面是否存在于物理内存中,同时可以利用这一个位来标记是否存储硬盘中数据的地址 TLB发现页面不在物理内存中就会发生页错误(缺页故障),此时就会发出异常交给操作系统的却页处理程序来处理,这一个程序会首先找到一个可用的物理页面(基于驱逐算法或者空闲的页),之后把这一个数据交换到物理内存中,同时重试指令(当然此时访问TLB时还是会发生重试)- 另外交换发生的时间还会基于一定的算法
策略
- 主要是各种驱逐算法:
FIFO也就是驱逐最先加入的页Random随机算法LRU(如果在循环的例子中命中率很差)- 近似
LRU: 通过硬件模拟LRU,比如利用几个寄存器记录优先级别(每一次访问就会把优先级别-1),当优先级减少为0就会驱逐
VAX/VMS虚拟内存系统
- 页表的组织方式: 使用分段 + 分页
- 地址空间的组织(和
Linux系统太不一样了):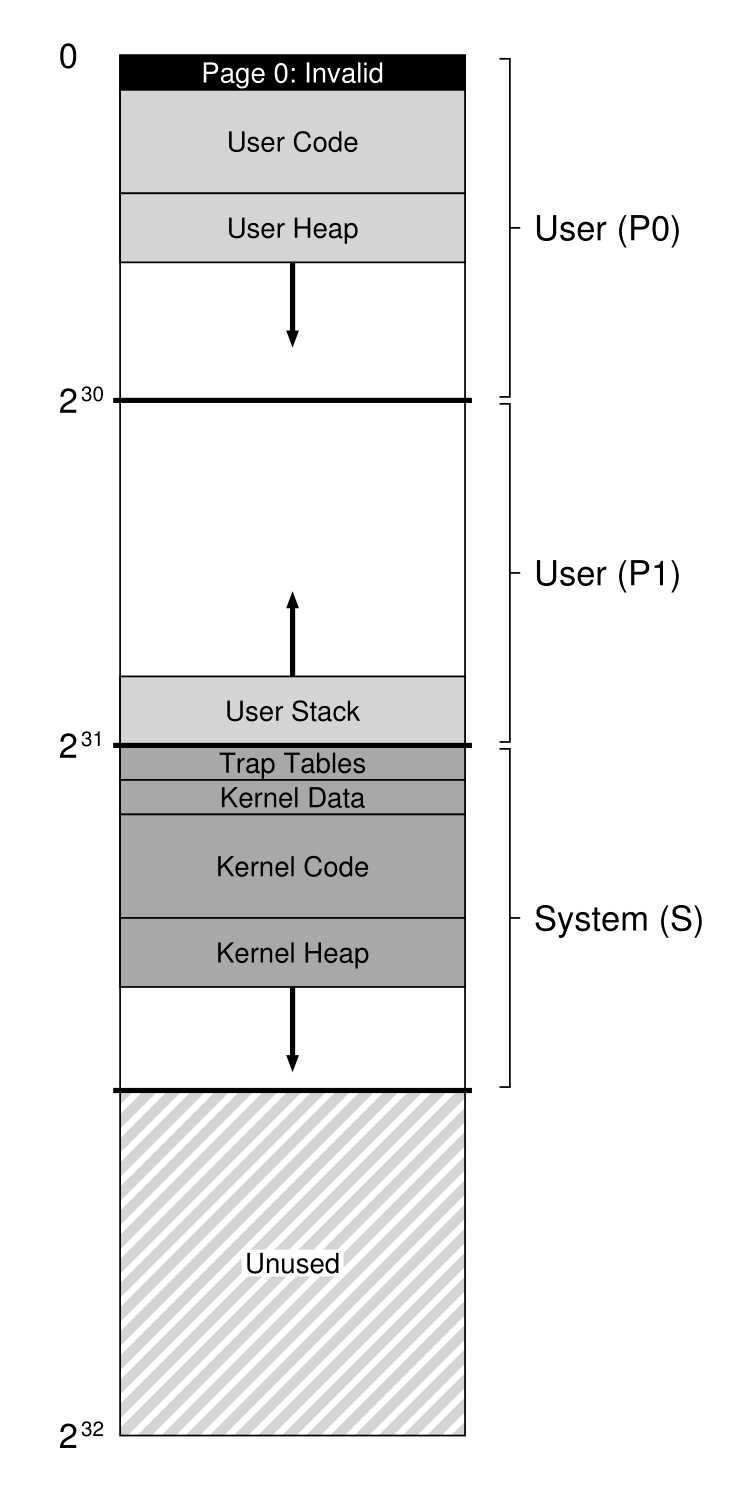
- 替换策略: 利用
FIFO,为么以一个进程设置一个RSS(驻留集大小),当该进程需要的页面超过RSS的时候就会驱逐首先加入的页面,如果一个页面真的被驱逐,会有一个二次机会队列,如果是干净的页就加入到干净页队列,脏页就加入到脏页队列,如果一个进程需要新的页面就在干净页队列中找对应的页,如果一个进程需要回收原来的页面,首先在脏页队列中寻找(这就体现了软件控制逻辑和硬件控制逻辑的区别,软件可以通过不同的数据结构来提高效率,但是硬件本身具有比较快的速度) - 页聚集: 把脏页列表中的页聚集在一起并且一起写入到磁盘中
- 比较好的虚拟内存技巧:
- 按需要放置
0: 操作系统在页表中标记不可以访问的条目,当进程需要读写这一个空间的时候就会导致操作完成物理寻址并且置0,并且映射到进程的地址空间中 - 写时赋值(
copy-on-write): 如果多个地址空间共享一个页,那么就把这一个页标记为只读,如果有一个进程写这一个页就会进入操作系统,操作系统就会分配新的页面,并且把这一个页面的数据复制到新的页面中,这就使得共享库不会占用进程空间,并且fork就是利用这一种机制完成创建子进程的
- 按需要放置
- 最后: 以上的所有讨论中物理页面可能存在于物理内存或者高速缓存中(高速缓存的访问也是使用物理地址),可以参考 csapp 中讲解缓存的一个章节