这一个部分我其实有很多地方没有仔细看,另外这一部分有大量的内容作者也只是介绍了一部分,所以我这里就总结一些比较基本的文件系统和文件系统实现方式相关的例子
IO设备
- 一个计算机系统的各种
IO设备的一个经典架构如下(IO设备也就是对于内存进行读写的各种设备,比如硬盘,显卡等):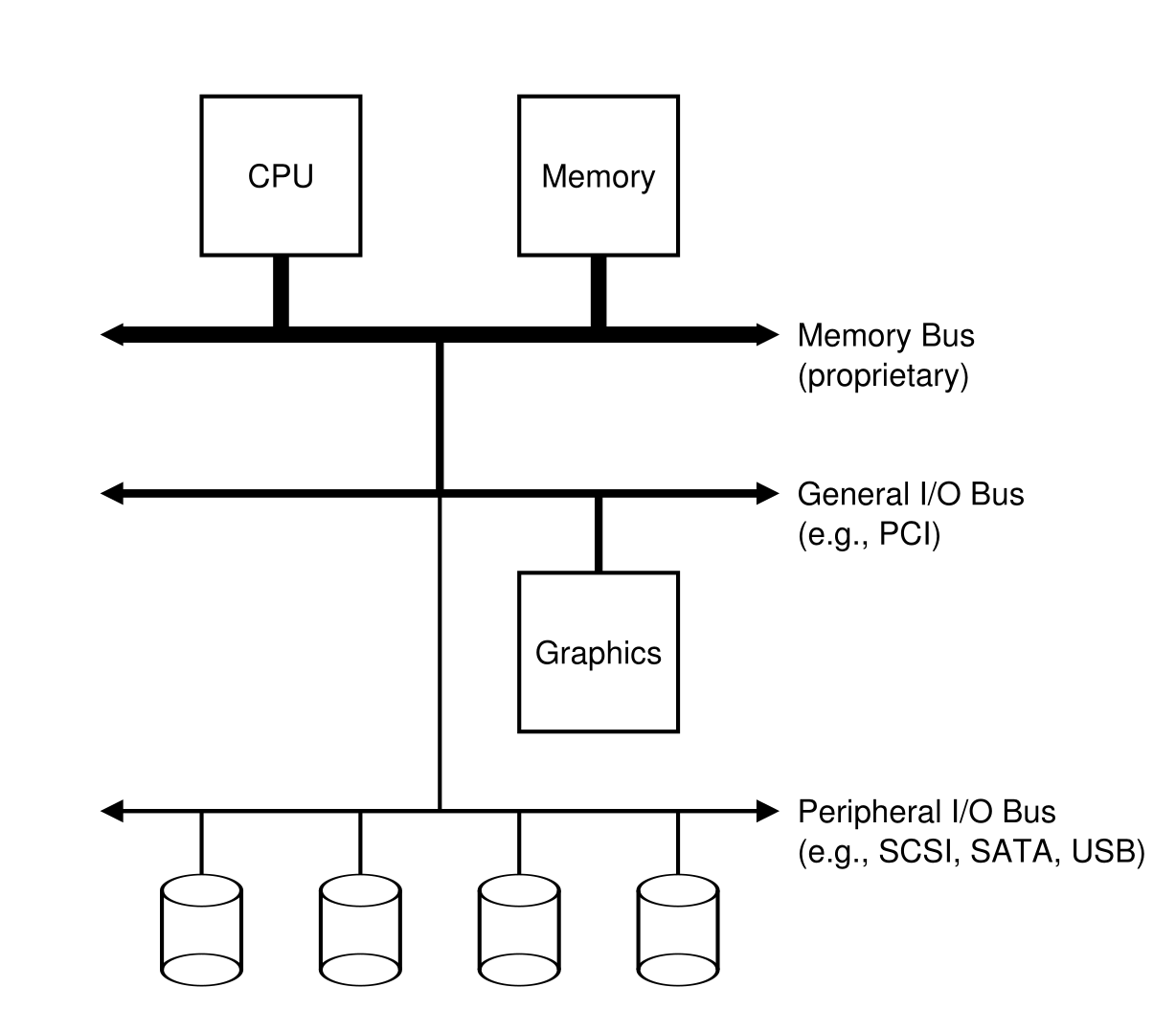
- 这里的各种总线的性质不同并且传递数据的速度也不同
标准设备
- 这里标准设备的一个抽象方式适用于各种硬件,也就是各种硬件向操作系统提供接口,操作系统利用这些接口来实现各种系统调用从而完成对于硬件的控制,一个典型的标准设备如下:

- 这里底层的硬件向上一层提供各种接口(比如状态寄存器,命令寄存器,数据寄存器等)
- 同时标准设备依托于标准协议完成操作系统与硬件之间的交互,一个例子比如操作系统可以通过不断读取硬件提供的接口中的状态寄存器的值来判断硬件的状态从而决定什么时候发送请求,这里如果
CPU使用轮询的方式完成对于硬件状态的判断就会到时这里会浪费大量的时间,所以此时硬件采用中断的方式,也就是硬件完成某一个请求或者发生故障的时候会进行一个时钟中断来同时CPU,所以此时就可以让IO操作与CPU计算并行执行:
DMA
- 但是如果考虑到
CPU还需要从内存送到硬盘硬盘才可以开始IO操作,这就又会产生时间的浪费,所以这里利用DMA来借助CPU完成数据从内存到磁盘的转义,DMA可以协调内存与各种设备之间的数据传递并且不需要CPU介入,利用DMA那么此时的时序图如下(并且DMA可以通过中断来向CPU发送命令完成的信号,中断就类似于进程中的信号):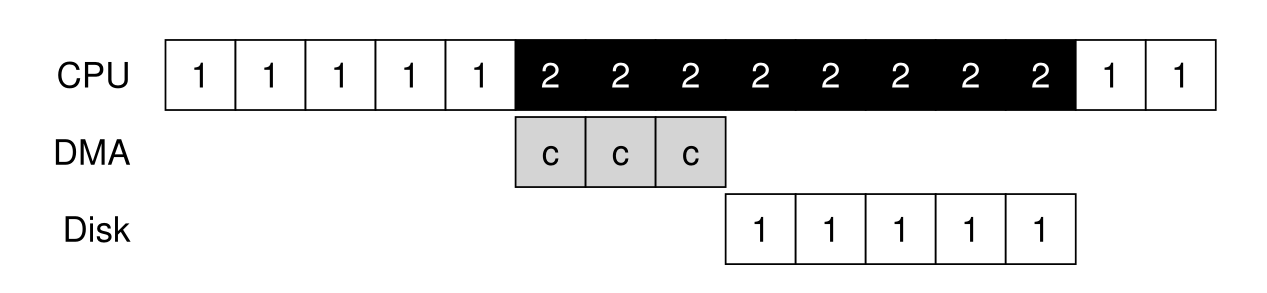
设备的交互方式
- 内存映射: 操作系统把设备寄存器的值当成内存地址使用,这样就可以在每一次读取的时候像读取进程地址空间中存储的变量一样读取到数据了
- 特权指令(比如各种
IO指令),通过IO指令完成设备之间的交互
驱动程序
- 操作系统的一部分就是驱动程序
- 驱动程序解决的问题就是对于同一个操作系统,不同的设备提供不一样的接口,那么如何统一各种设备的接口使用方式,这里驱动程序其实也就是一个中间层,把硬件接口转换为操作系统可用的,统一的接口,比如文件系统栈如下:

- 这样对于不同的设备就可以统一交互方式了
磁盘驱动器(磁盘)
- 偏向于硬件并且过时,不做阐述
RAID
- 本质上是一个系统,充当磁盘驱动器的作用,可以提供各种数据存储服务和差错校验方式,不做阐述
文件与目录
- 这一个部分介绍了操作文件和目录的各种方式以及相关操作,这里介绍重要的知识点
fsync用于直接把写入到文件中的内容同步到硬盘中- 获取文件信息的方式:
stat函数,当然也可以使用stat命令: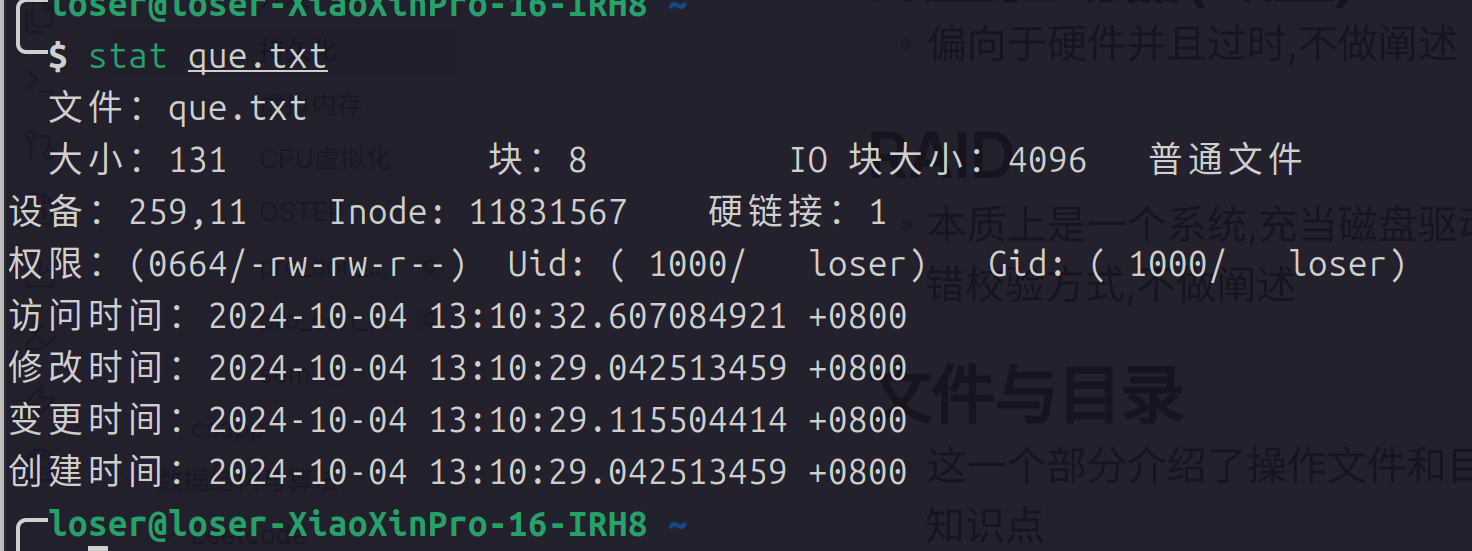
stat结构体的成员如下,可以利用其中的各种成员来判断文件的类型等信息:
stat系统调用如下:
int stat(const char *restrict pathname,struct stat *restrict statbuf);
- 硬链接: 可以看作创建了这一个文件的副本和这一个文件指向同一个
Inode,并且每一次创建一个硬链接都会使得硬链接数量增加 - 符号链接(软链接): 相当于创建了一个快捷方式,也就是符号链接原来的文件,所以一旦删除原来的文件,符号链接就不起作用了
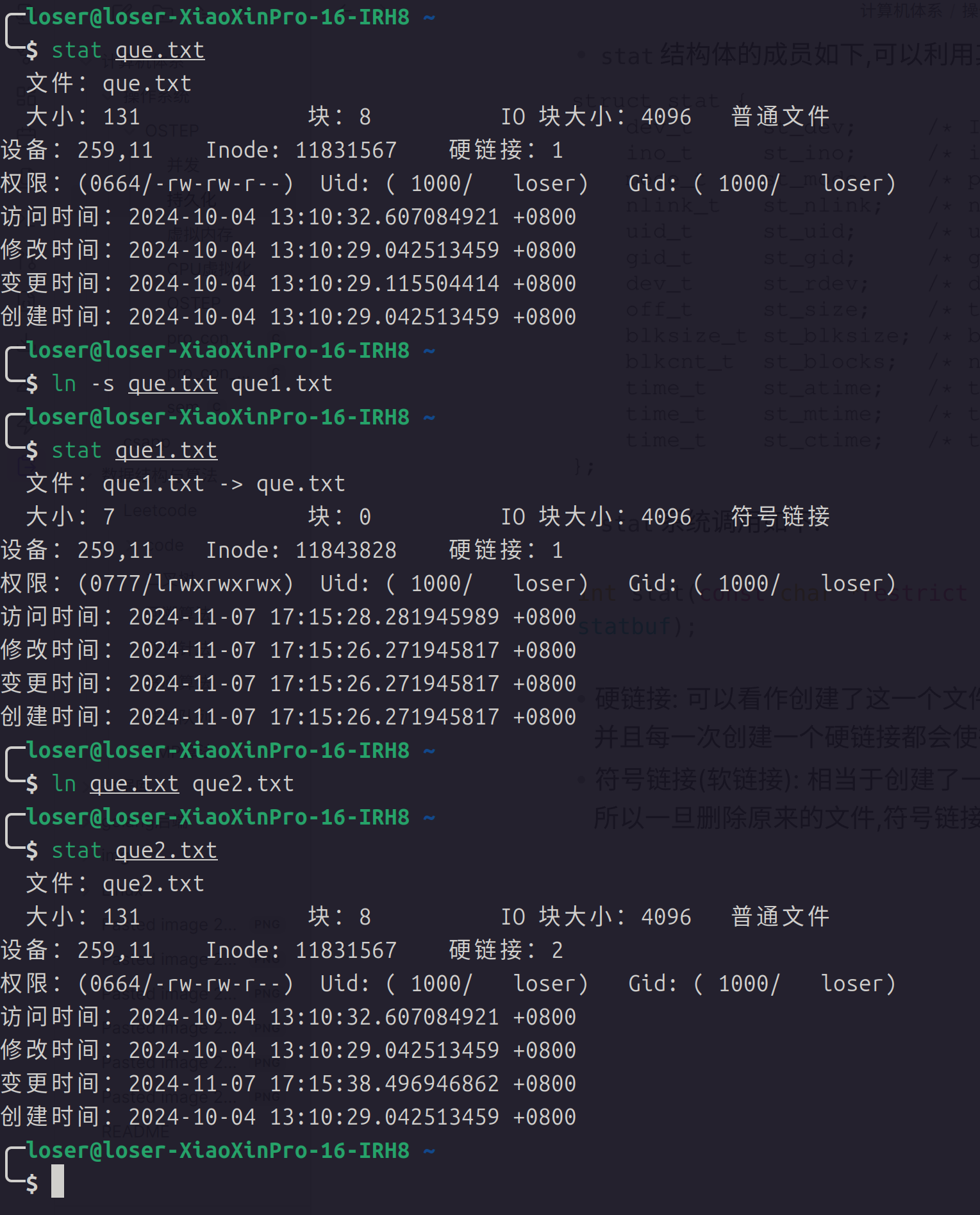
- 文件系统的挂载,可以使用
mount命令完成对于文件系统的挂载,所以可以间的即使在同一个目录下的不同的文件夹可能处于的文件系统或者所处与的磁盘都是不同的,所以不要一位/目录下的全部空间都是用于分配下面的所有目录,很多目录可以使用不同的文件系统甚至占用不同的磁盘,比如使用mount命令可以查看挂载情况,或者进行挂载,比如:
mount -t ext3 /dev/sda1 /home/users // 表示在这一块磁盘中利用ext3文件系统挂载目录 /home/user,此时/home/users 相等于文件系统的根目录
文件系统的实现方式
整体组织方式
- 包含超级块,
inode和数据位图以及inode还有各种数据,整体组织方式如下: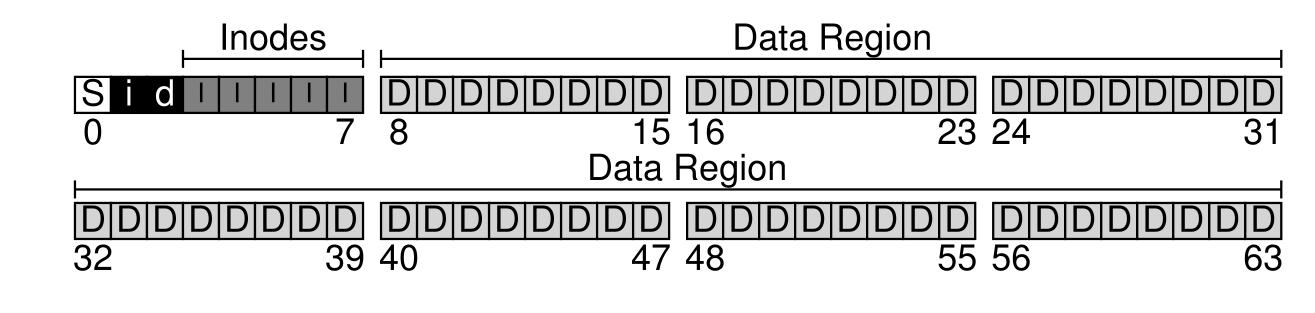
inode组织方式
- 可以认为
inode就是一个结构体记录着文件的各种信息,并且inode通过顺序排列的方式进行组织,并且每一个inode都有一个索引编号,所以利用相应的索引编号就可以锁定inode结构体的位置了,inode的组织方式如下: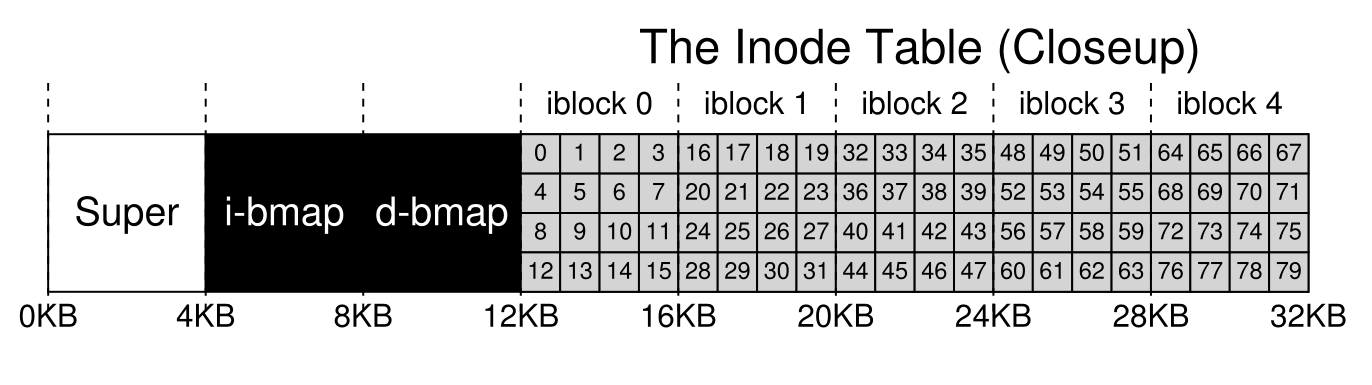
inode结构体记录的内容如下(ext2文件系统为例,类似于stat结构体):
多级索引
- 为类支持大文件,
inode固定的文件指针是不够的,所以引出了间接指针的方式(和多级页表的设计方式几乎一样),让一个指针直线一个间接块,这一个间接块中存储者更多指针
目录组织方式
- 目录就是内容为
(文件名,inode)列表的文件,和文件一样拥有inode号等信息
空间空间管理
- 通过两个
bitmap,也就是数据位图和inode位图来判断相应的位置是否被占用
读取和写入
- 读取: 首先读取顶层目录,找到下一层目录的
inode,之后利用这一个inode找到相应文件的inode并且对于文件指针等信息进行更改即可,比如读取过程如下: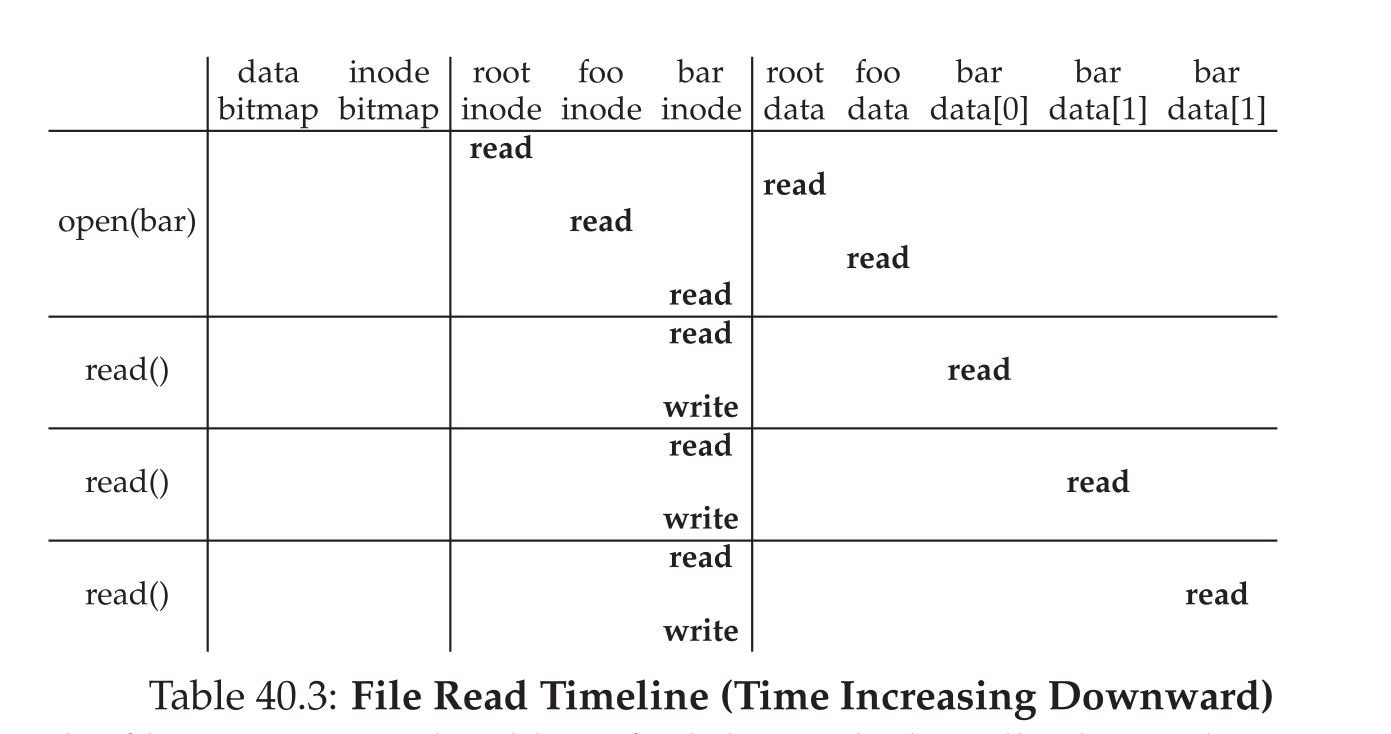
- 写入磁盘的过程也是一样的,但是此时需要查询数据位图和
inode位图从而找到空闲的块进行空间分配: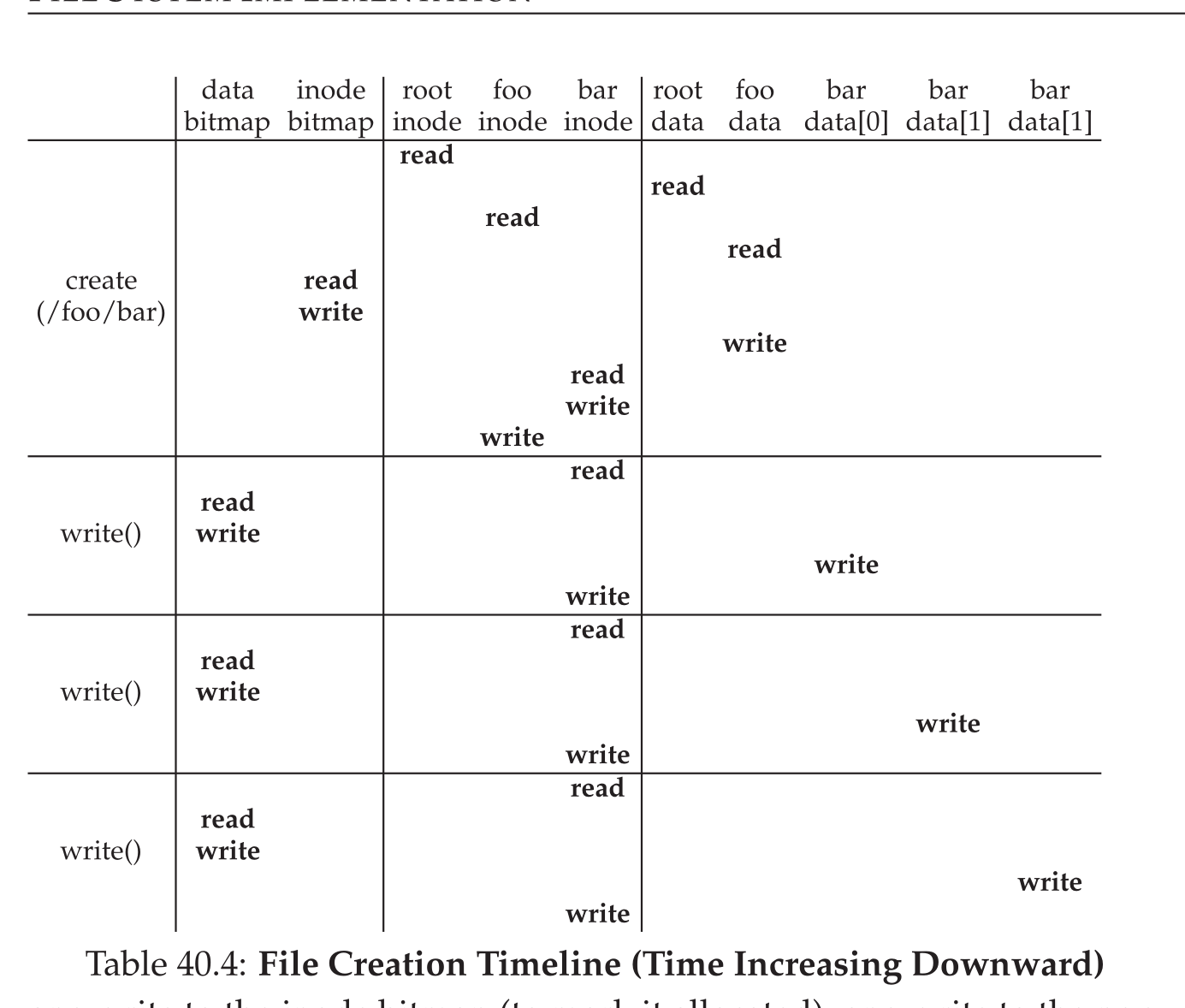
- 另外对于如此大量的文件
inode的读取和写入过程,怎么可能少了缓存,所以这里内存中会有一块区域来缓存磁盘中的某些信息,另外为了避免对于磁盘的多次操作还会使用缓冲的方式,也就是把写入的内容放入到缓冲区中,一起写入,当然可以利用系统调用fsync来进行数据的直接写入
局部文件系统和快速文件系统(FFS)
- 改变磁盘组织方式,添加柱面组的概念,从而保证时间和空间局部性
- 大文件组织方式: 首次适配,为了不破坏之后数据的局部性
崩溃一致性: FSCK和日志
fsck: 简单的扫描磁盘从而确定那一些数据发生了丢失,检查的时候根据不同的状态确定应对策略
日志
数据日志
- 也就是在写入真实的数据的时候首先写入数据日志,从而可以根据数据日志的内容对于崩溃的内容进行恢复,数据日志的一种组织方式如下:

- 利用数据日志之后的写入方式如下:
- 日志写入
- 加检查点(也就是写入带处理的元数据和实际数据)
- 为了保证日志的崩毁一致性,引入了事物的概念,所以此时需要改变写入顺序:
- 日志写入
- 日志提交(等待写入
TxE) - 加检查点
- 可以通过把一系列的读写操作组织在一起从而形成同一个事务
- 为了使得日志占用的空间有限使用循环队列的方式存储数据并且即使释放数据
元数据日志
- 为了方式对于同一个数据的多次写入利用元数据日志,基本没有什么不同的,组织方式如下:

- 此时的操作顺序为:
- 数据写入
- 日志元数据写入
- 日志提交
- 加检查点元数据
- 释放
日志文件系统(LFS)
- 组织方式如下:
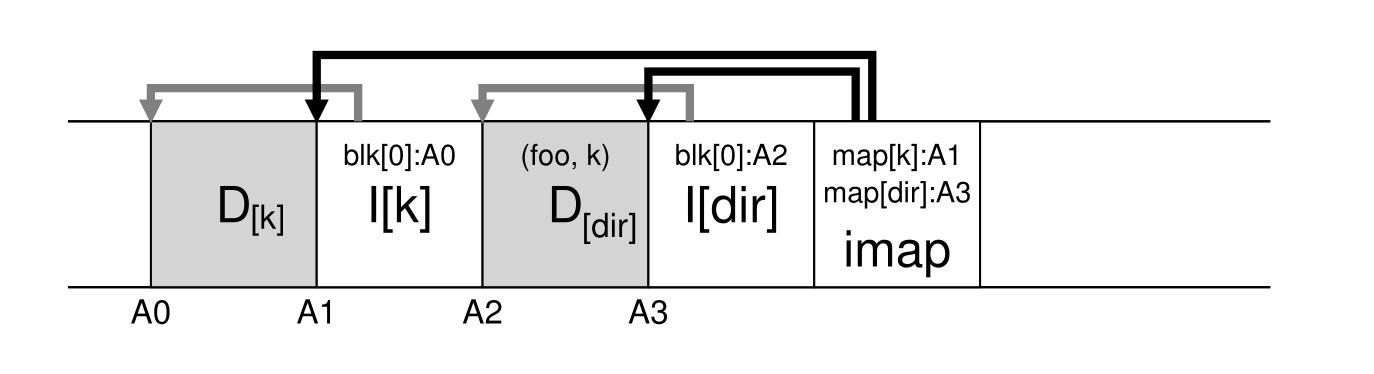
- 这一种文件系统在写入的时候总是把数据写入到没有使用的块,对于使用过的块总是采用清除的方式,这一种方式提高了写入的速率,在文件系统中成为写时复制(
Copy-on-write)