Linux基本命令
- 终端: 一系列输入输出设备的总称
- 终端内嵌入了
shell,可以执行输入的命令 - 可以查看
/etc/shells查看shell,$SHELL就是现在使用的shell解析器 shell中可以使用的快捷键如下:
| 功能 | 快捷键 | 含义 |
|---|---|---|
| 上 | ctrl+p | previous |
| 下 | ctrl+n | next |
| 左 | ctrl+b | backforward |
| 右 | ctrl+f | forward |
Del | ctrl+d | delete光标之后的 |
Home | ctrl+a | the first letter |
End | ctrl+e | end |
Backspace | Backspace | delete光标之前的 |
类Unix的目录结构
Linux操作系统中一切都是文件Linux的目录结构如下:/dev存放各种设备相关的文件/etc存放相关的配置文件信息,比如/etc/passwd存放着用户的密码和信息/home表示用户目录,进入之后可以看到用户目录/lib表示库目录,使用的所有库都放在这一个/lib中(比如C库等)/root表示root用户的家目录/bin存放着各种命令/usr存放着各种软件资源,安装的各种软件资源都放在/usr中,自己装的软件可以放在/usr/local中/boot存放开机启动程序
文件和目录操作
~表示家目录- 文件类型(
shell编程中提到过):-普通文件d目录文件c字符设备文件(按照字节进行读写)b块设备文件(可以随机读写)l软连接p管道s套接字
rmdir删除空目录(一般使用rm -r)mkdir -p a/b表示递归的创建文件夹cp -a dir ..表示把dir全部拷贝到..中,否则就会略过dir,-a会把所有的信息(包含权限拷贝过去,甚至时间都会被拷贝过去)cat查看文件内容tac表示倒置显示,比如可以查看日志文件可以使用这一个more表示分割显示(空格翻页,enter一行,q退出)less基本一致,但是无法使用ctrl + C退出head读取头部tail读取尾部du查看目录大小df查看磁盘挂载点和使用情况- 不会的命令使用
--help查看帮助文档
软连接和硬连接
- 创建软连接(相当于快捷方式):
ln -s file file.s - 注意此时创建的快捷方式占用的空间大小就是文件名称的大小,实际上访问快捷方式就是访问了关联的文件名称(当成快捷方式看待)
- 为了保证软连接可以任意移动,创建时需要使用绝对路径
- 注意文件权限和软连接的权限(软连接的权限全部开发只是表示软连接本生的读写权限,并且和原始文件无关)
- 硬连接: 注意硬连接和软连接的区别就是硬连接和原始的文件执行同一个数据空间,所以更改任何一个硬连接的内容,原始的内容也会发生改变
- 注意目录不可以创建硬连接
- 硬连接记数:
- 每创建一个硬连接,硬连接技术都会发生改变,当硬连接技术减少为
0的时候,就会删除文件
- 每创建一个硬连接,硬连接技术都会发生改变,当硬连接技术减少为
- 实现方式:
- 各种文件会在一个棵树(节点使用
Inode表示,硬连接都有一个相同的Inode) - 删除的时候,只将硬连接记数减少,当记数减少为
0的时候才会完全删除
- 各种文件会在一个棵树(节点使用
- 可以使用
stat命令查看Inode
创建和修改用户组
whoami查看当前用户chmod [who] [+][-] [mode] 文件名a表示所有人u表示文件所有者(第一个位置)o表示其他人g表示给第二个位置修改权限
- 文件权限修饰:
- 首位表示文件类型
- 之后表示所有者的权限
- 表示用户组的权限
- 表示其他人的权限
- 数组设定法:
r4w2x1
- 比如设置:
chomod 471 文件,结果如下:- -r--rwx--x
chown命令用户修改文件所有者,当创建一个文件的时候,这一个文件属于用户和文件所有者,所以chown可以修改用户组和用户:chown 用户名/用户组 文件名
- 注意修改之后,所有者就会发生改变,所以利用
chmod的时候一定需要注意 adduser表示创建用户:sudo adduser 用户名
addgroup表示添加用户组:sudo addgroup 用户组
chgrp表示修饰文件所有的用户组:chgrp 用户组 文件名
- 或者直接使用
chown 用户:用户组 文件就可以直接设置,创建用户的同时会创建一个同名的用户组 - 删除用户:
deluser:deluser 用户
- 删除用户组:
delgroup:delgroup 用户组名
find命令
find使用方式:find 查找目录 [options] 类型(名称)
options:-type表示文件类型-name表示文件名称-size表示按照文件大小查找-atime(最近访问时间),-mtime(修改时间),-ctime(修改时间)表示按照时间进行修改
- 还可以指定搜索深度(
-maxdepth n表示最大递归深度) - 例如:
# 表示 > 20M < 50M
$ find ~ -size +20M -size -50M
# 表示一天以内修改了
$ find ~ -ctime 1
# 找到的结果交给某一个命令执行
$ find /usr/ -name "*.tmp" -exec ls -l {}\
# 表示执行某一个命令(交互模式)
$ find /usr/ -name "*.tmp" -ok rm -r {}\
- 如果不使用
-size就默认按照块搜索,传统的磁盘的最小计量单位512B,最小的就是512B - 重点掌握参数,可以使用
man find查看帮助文档 grep以文件内容作为搜索对象:
# 表示递归搜索文件夹(按照文件名称搜索)
$ grep -r D 目录名
# 用途搜索指定的进程或者搜索文件名称
$ ps aux | grep bash
# 一般就是结合管道使用
xargs和exec的区别(都是类似于管道的功能):xargs当搜索结果集的大小比较大的时候,那么就会分片执行(执行效率比较高)exec直接执行所有结果集
# 表示打印的结果使用 null 作为结果
$ find ./ -maxdepth 1 -type f -print0 | xargs -print0 ls -l
- 其实搜索到的结果就是一个集合,可以结合管道结合
xargs命令使用,提高效率 - 当文件名中间有空格的时候,比如文件名为:
abc xyz的时候,如果直接使用xargs就会导致解析成两个文件,所以可以使用find的-print0参数(表示每一个结果使用null进行分割)
$ find ./ -size +20k -21k -print0 | xargs -0 ls -l
sed会按照行进行拆分,利用awk会按照列进行拆分
软件的卸载和安装
apt相当于是apt-get的子集,并且比apt更新,推荐使用aptapt换源方式: https://blog.csdn.net/weixin_65451201/article/details/135198265sudo apt update更新软件库sudo apt remove卸载软件sudo apt upgrade升级软件包deb包的安装:sudo dpkg -i xxx.deb安装deb软件包sudo dpkg -r xxx.deb删除deb软件包sudo dpkg -r --purge xxx.deb连同配置文件一起删除sudo dpkg -info xxx.deb查看软件包的信息sudo dpkg -L xxx.deb查看文件拷贝详细命令sudo dpkg -l查看系统中已经安装软件报的信息命令sudo dpkg-reconfigure xxx重新配置软件包命令
- 源代码安装:
- 解压
cd dir./configuremake(编译源码)sudo make install(把库和可执行文件安装到系统路径下)sudo make distclean(删除和卸载软件)
- 压缩包安装:
- 首先解压
- 之后移动到
/usr/local中 - 之后启动脚本文件即可
压缩和解压
- 压缩:
tar -zcvf 需要生成的压缩包 压缩材料,例如:tar -zcvf test.tar.gz file1 dir2
gzip命令用于压缩文件:gzip file,但是弊端就是只可以压缩一个文件,不可以压缩多个文件或者文件夹tar -zcvf中:z表示压缩c表示创建v表示显示压缩过程f表示文件- 创建压缩文件
bzip2命令,bzip2 文件- 所以总结一下解压和压缩的命令:
tar -zcvf 目标文件名 文件表示使用gzip 压缩后缀:.tar.gztar -jcvf 目标文件名 文件使用bzip2进行压缩,后缀也是一样
- 解压缩
tar -zxvf test.tar.gz表示使用gunzip解压tar -jxvf test.tar.gz表示使用bzip2解压
-C表示解压到那一个文件中rar压缩:rar a -r newdir dir表示递归压缩,默认后缀就是.rarunrar x Xxx.rar解压命令
zip压缩 :- 压缩:
zip -r dir.zip dir - 解压:
unzip dir.zip
- 压缩:
- 总结:
linux中解压工具有gzip和bzip2,但是他们都只可以压缩单个文件,所以需要使用tar -zcvf -jcvf -zxvf -jxvf代替- 同时也可以利用
rar和zip工具进行linux下工具的打包
cat &表示后台运行catjobs可以查看后台的作业fg表示切换到前台bg表示切换到后台env表示查看环境变量passwd 用户名表示修改密码ifconfig用于查看当前的ip地址man查看帮助手册:- 第一章节命令
- 第二章: C lib库
man n 命令可以查看某一个命令在某一章的介绍alias表示起别名l$ alias pg='ps aux | grep bash'umask 权限表示掩码,比如664 使用 777 减去就是 113,去掉执行权限之后就是002- 比如
umask 522得到的掩码就是777 - 522 - 111,创建的权限显示之后就可以得到掩码值 - 创建终端:
ctrl + alt + t新建终端ctrl + shfit + t拆分终端
vim 的基本使用方式
三种工作模式
- 命令模式:
i a o I A O s S进入文本模式,:进入末行模式 - 文本模式
esc进入命令模式 - 末行模式: 可以输入各种命令,按下两次
esc键两次也可以回到末行模式 - 不用
vim了,用不来
Shell编程
Shell介绍
linux通过内核操作计算机硬件,内存,磁盘,显示器等- 通过编写
Shell命令发送给linux内核去执行,操作的就是计算机硬件,所以Shell命令是用户操作计算机硬件的桥梁 Shell是一门程序程序设计语言,含有变量,流程控制语句等Shell就是通过shell命令编写的shell文本文件,也就是shell脚本shell脚本 -->shell解析器 --> 内核 ---> 响应- 支持的
shell解析器如下,一般使用bash - 利用
$SHELL可以查看默认的shell解析器,$SHELL是全局环境变量,所有shell程序都可以访问的
Shell入门
- 后缀名:
.sh - 首行需要时设置:
#!/bin/bash表示采用bash解析 - 注释格式:
#多行::<<! # 内容1 # 内容2 ! - 执行方式:
sh解析器执行方式sh Xxx.shbash解析器解析方式bash Xxx.sh- 仅路径执行方式
./Xxx.sh需要权限
环境变量
-
系统环境变量: 是系统提供的共享变量,是
linux系统加载shell配置文件中定义的变量共享给所有的shell程序使用:- 全局配置文件
/etc/profile/etc/profile.d/*.sh/etc/bashrc
- 个人配置文件:
- /.bash_profile
- /.bashrc
- 全局配置文件
-
用户级环境变量:
Shell加载个人配置文件,共享给当前当前用户的Shell程序使用 -
自定义变量:
-
特殊符号变量:
-
可以使用
set变量查看所有函数和系统变量 -
常用的环境变量:
PATH设置命令的搜索路径,使用 : 分割HISTFILE表示命令列表SHELL当前解析器LANG表示使用的字符编码方式
-
env用户查看系统环境变量set还会查看自定义变量和函数
自定义变量
- 自定义局部变量(定义在一个脚本文件中的变量只能在这一个脚本文件中使用的变量)
变量名=变量值注意没有空格,不可以使用关键字作为变量名称 - 自定义常量: 设置值之后就不可以修改了
readonly 变量名=变量值 - 自定义全局变量
- 查询变量的值:
$变量名${变量名}适合拼接字符串
- 删除变量:
unset 变量名
父子Shell环境介绍
- 如果在
A.sh中执行了B.sh那么A.sh就是父Shell环境,B.sh就是子Shell环境 - 如果在
A.sh中定义全局变量,B.sh中也可以使用 - 定义全局变量的方式:
export var_name1 var_name2
- 删除还是使用
unset
特殊符号变量
$n: 用于接受脚本文件传入的参数$1 - $9表示获取第n个参数 或者${数字},$0表示脚本名称$#表示获取所有输入参数的个数$@表示获取所有输入参数的个数,不使用 双引号括起来功能一样"$*"获取所有参数拼接的一个字符串"$@"表示获取一组参数列表对象,利用循环打印所有输入参数$?用于获取上一个Shell命令的退出状态码,或者函数的返回值$$获取当前进程环境的ID
自定义系统环境变量
- 主要编辑
/etc/profile其中就是系统级别的环境变量,当用户进入系统环境初始化的时候,会加载/etc/profle中的环境变量,提供给所有的shell程序使用,只要是所有的Shell程序使用的全局变量都可以定义在这一个文件中 - 创建步骤:
- 增加变量
# 增加命令:
定义变量VAR1=VAR1
并且倒入为环境变量
export VAR1=VAR1
- 重载环境变量
source /etc/profile
vim中使用G定位到文件末尾gg定位到首行位置
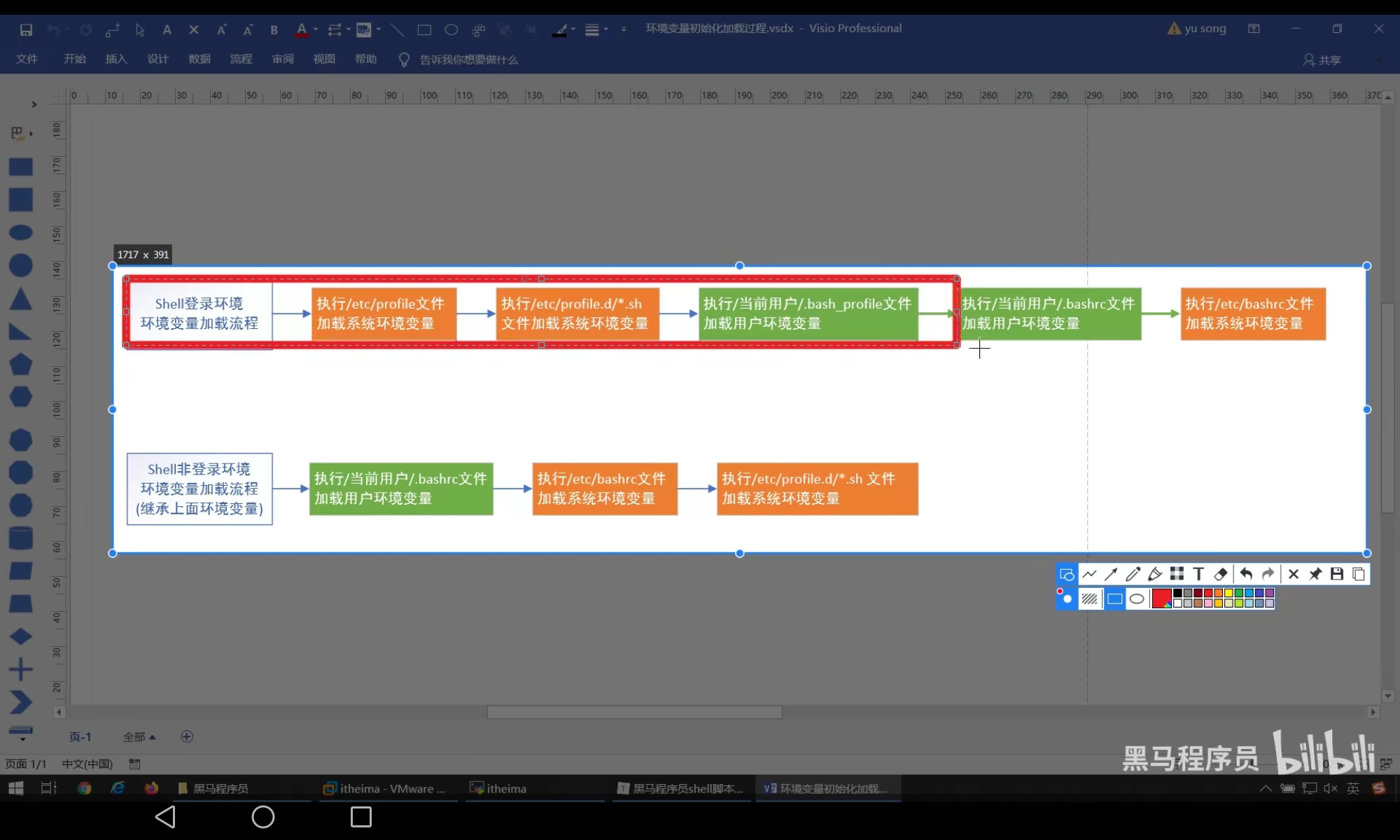
加载流程原理
Shell工作环境: 用户进入linux系统就会初始化shell环境,这一个环境会加载全局配置文件和个人配置文件文件,每一个脚本都有自己的shell环境- 交互式: 与用户进行交互,互动,用户输入,
shell就会作出反映 - 非交互式: 不用用户参与就可以执行多个命令
shell登陆环境: 需要用户名/密码登陆的shell环境shell非登陆环境: 不需要用户名,密码进入的shell环境或者执行脚本文件- 环境变量执行过程:
- 可以查看
/etc/passwd查看用户 - 切换
shell环境,可以指定具体shell环境进行执行脚本文件
sh/bash -l/--login # 登陆环境
bash # 加载 shell 份非登陆环境
sh/bash 脚本文件 # 之间执行脚本文件
- 需要登陆的写在
/etc/profile里面,否则可以写在 ~/.bashrc - 识别
shell环境的命令:echo $0:-bash表示登陆环境bash表示非登陆环境
字符串变量
- 定义方式:
- 单引号(原样输出)
- 双引号
- 不使用引号方式
- 单引号无法解析
${},但是双引号无法解析 - 可以使用 \ 进行转义字符
- 字符串拼接:
- 没有符号拼接
- 双引号拼接
- 混合拼接
字符串截取
- 字符串截取方式:
${变量名:start:length}${变量名:start}${变量名:0-start:length},表示从右边开始截取${变量名#*chars}截取左边出现的某个第一次出现的字符的右边的所有字符${变量名##*chars}截取从右边第一个出现指定的佐夫的右边的所有字符${变量名%chars*}表示按照右边查找第一个截取左边${变量名%%chars*}表示按照右边查找最后一个字符截取左边的
Shell索引数组变量
- 语法:
array_name=(item1 item2) # 方式1
array_name([索引下标1]=item1 [索引下标]=item2)
- 数据类型可以不同,但是注意初始了多少个索引就说明长度为多少
- 获取元素
${arr[index]} - 赋值操作
item=${arr[index]} - 使用
@或者*获取所有元素${arr[@]}arr[*] - 获取指定元素的长度
${#arr[索引]} - 数组的拼接:
arr_new=(${arr1[@/*] ${arr2[@/*]}}) - 删除数组中的元素或者删除整个数组:
unset arr[index]unset arr
shell内置命令
alias设置别名
shell内置命令就是bash自身提供的命令而不是脚本文件type cd就可以查看是否是内其嵌入命令alias命令可以查看所有别名列表- 语法:
alias 别名=命令
unalias别名删除语法:unalias 别名unalias -a删除所有别名
- 内置命令执行速度快,外部脚本文件执行速度慢,执行效率慢
alias lla = "ll -a"
echo命令
echo命令默认换行输出,加上一个参数-n就可以不换行输出- 默认不一会解析换行,但是也可以解析换行,使用
-e表示解析换行符号 - 同时可以配合
\c(用于清除结尾换行符号)
read读取控制台输入
- 语法:
read [-options] [var1,var2 ...]
- 没有设置选项,那么就可以在
REPLY变量中读取到最后一个数据 read 变量名就可以把输入内容输入到变量名中- 选项:
-n num读取num个字符-p prompt显示提示信息-s静默模式-t seconds设置超时时间
- 读取一个字符就可以使用
-n 1就可以了
exit 退出命令
exit用于推出当前shell环境,并且可以返回一个状态码,可以利用$?获取推出状态码- 正确推出状态码:
exit - 错误推出语法:
exit 非0数字 - 可以利用不同的状态定义不同的状态
- 可以使用
$?来确定返回的状态码
declare设置变量
- 可以使用
declared设置变量的属性 - 可以使用
declared查看全部shell变量和函数 - 可以实现索引数组和关联数组赋值
- 语法:
declare [+/-][aArxif][变量名称=设置值]
-
- / - 表示设置或者取消类型
- a array
- A key-value形式的关联容器
- r readonly
- x 设置全局变量
- i 设置整形
- f 设置函数类型
- 关联数组: 键值对数组:
declare -A 关联数组名称=([字符串key]=值1 [字符串key2]=值2)
- 创建所有数组
declare -a 索引数组=(item1 item2)
declare -a 索引数组=([索引1]=value1 [索引2]=value2)
- 获取变量类型一致
运算符
算术运算符
expr命令
- 计算语法:
expr 算术运算符表达式
- 获取计算结果给一个变量:
result=`expr 计算表达式`
- 注意字符之间一定需要空格
expr 1 + 1 - 注意使用
*和()都需要使用\进行转义字符的转义
比较运算符
- 整数比较运算符号:
-eq相等-nq不相等-gt大于-lt小于-ge大于等于-le小于的呢关于><>=<===!=
- 使用方式
[ a -eq -b ],可以使用 $? 查看执行结果 - 使用方式:
(($a>$b)) - 字符串比较运算符号如下: 不成立返回
1否则返回0=或者==表示相等0表示不相等!=<>-z检测字符串长度是否为 0[-z $a],不为空返回1-n检测字符串长度是否不为 0,不为0返回true[ -n "$a" ]$检测是否为空[ $a ]不为空返回0否则返回1
- 使用
[[]]不需要转移,否则就需要转义字符进行转义 - 可以配合
&&和||使用 []和[[]][[]]不会发生分割,[]会发生分割- 就是 "a b" 会被分割
[[]]不需要进行转义,[]不会发生转义
bool运算符
- 如下:
!用于取反-o表示or有一个成立就可以成立[ 表达式1 -o 表达式2 ]-a表示and[ 表达式1 -a 表达式2 ]
逻辑运算符
- 如下:
&&||!
- 使用方式
[[ 表达式1 && 表达式2 ]]
文件测试运算符
- 文件类型:
- 普通文件
- - 目录文件
d - 链接文件
l - 块设备文件
b - 字符设备文件
c
- 普通文件
- 设备文件在
/dev目录下 - 运算符号:
-w是否可以写-r是否可以读-x是否可读-s是否为空-f是否为文件-d是否为目录-e是否存在-nt是否比那一个文件更新
- 使用
[ -w $file_name -a -r $file_name1]
expr命令
- 作用: 表达式求解值(整数计算)
- 字符串操作:
expr length 字符串expr substr 字符串 start end截取expr index 被查找字符串 需要查找的字符查找expr match 字符串 正则表达式(可以自己在网上找到正则表达式)返回匹配的最大长度expr 字符串 : 正则表达式
(()) 命令
- 作用进行整数计算
- 语法:
((表达式)) - 用法:
((b=a-1))a=$((b-1))((a=c-1,b=a+10))echo $((a+10))- ((a>7 && b<8))
- 用于括号内赋值,可以看成
(())就是python运行环境,可以进行多表达式赋值,同时可以结合$进行赋值,也可以进行表达式的操作
let命令
- 语法:
let 赋值表达式
$[]命令
- 作用就是可以进行整数运算,只可以计算结果赋值给变量,但是里面不可以进行赋值运算
bc命令
- 内置的计算器,支持浮点运算,还可以进行进制的转换等操作
- 语法:
bc [options] [参数] - 选项:
-h帮助-v显示版本-lmathlib 使用标准数学库-i强制交互-w显示警告信息-s使用POSIX标准-qquiet不显示欢迎信息
- 同时
bc -q 文件就可以计算文件中的表达式 - 内置变量:
scale指定精度ibase指定输入的数字的进制obase指定输出的数字进制last获取最近计算打印结果的数字
- 内置数学函数:(使用
-l参数)s(x)sinc(x)cosa(x)arctanl(x)log(x)e(x)ej(n,x)贝塞尔函数
- 具体用法:
- 互动式的计算
bc -q进入就可以了 - 使用管道
- 互动式的计算
使用管道进行计算
echo "expression" | bc [options]"expression"必须符合bc命令要求的公式shell中的变量使用$取得- 也可以把
bc变量赋值给 变量
var_name=`echo "expression" | bc [options]`
var_name= $(echo "expression" | bc [options])
非互动式的输重定向运算
- 语法
# 第一种方式
var_name=`bc << EOF`
第一行表达式
第二行表达式
...
EOF
- 作用将多行表达式输入到
bc中
var_name=$(
bc << EOF
表达式1
表达式2
表达式3
...
EOF
)
流程控制语句
if else
if 条件
then
命令
fi
if 命令
then
命令
else
命令
fi
if 条件
then
命令
elif
then
命令
elif
then
命令
else
...
fi
- 条件使用
[[]]或者(())都可以 - 注意
(())中就相当于其他语言运行环境,其中取出变量可以不用使用$ if 表达式; then echo "成立" ;else echo "不成立"; fi;
退出状态
linux命令执行完毕之后都会返回一个退出状态,大多数命令中0表示成功1表示不成功if中使用逻辑连接符号就可以通过返回值判断表达式是否正确
test命令
- 对于整数和字符串和文件的测试
- 语法:
if test 数字1 options 数字2
then
...
fi
options:-eq-ne-gt-lt-ge-le
- 字符串的比较:
=或者==!=\>\<-z 字符串长度为0就是真的-n 字符串字符串的长度不为0就是真
- 文件比较:
- 文件相关的命令
cast 语句
case 值 in
匹配模式1)
命令1
命令2
;;
匹配模式2)
命令1
命令2
;;
..
*)
命令1
命令2
;;
esac
- 只支持如下:
*[abc][m-n]|
case $number in
1)
echo "星期一"
;;
2)
echo "星期二"
;;
3)
echo "星期三"
;;
4)
echo "星期四"
;;
5)
echo "星期五"
;;
6)
echo "星期六"
;;
0|7)
echo "星期日"
;;
*)
echo "数据不合法"
;;
esac
while 语句
- 语法:
while 条件
do
命令1
命令2
...
continue; # 结束当前这一次循环,进入下一次循环
break;
done
- 一行的写法:
while 条件; do 命令; done;
#!/bin/bash
read -p "请输入循环次数" num
count=1
while ((count<=num))
do
if ((count%2==0))
then
echo "${count}是偶数"
else
echo "${count}是奇数"
fi
((count=count+1))
done
until语句
until也是循环语句,但是和while相反,如果条件为false才继续循环- 语法:
until 条件
do
命令
done
- 推荐使用
(())使用[[]]需要使用$
for循环语句
- 语法:
for var in item1 item2 ... itemN
do
命令1
命令2
命令3
...
done
- 一行写法:
for var in item1 item2 ... itemN; do 命令1; 命令2
- 或者范围写法:
for var in {start..end}
do
命令
done
#!/bin/bash
i=0
for i in {1..100}
do
echo "hello,${i}"
done
- 或者第三种方式:
for((i=start;i<=end;i++))
do
命令
done
- 一行写法:
for((i=start;i<=end;i++)); do 命令;done
select 语句
- 用于增强交互性,可以显示带编号的菜单
- 语法:
select var in menu1 menu2 ...
do
命令
done
select是无限循环,输入空值,或者输入的值无效,都不会结束循环,之后只有遇到break或者ctrl + d才会结束循环- 一般可以配合
case使用
#!/bin/bash
echo "请输入你的爱好"
select hobby in "编程" "篮球" "游戏"
do
case $hobby in
"编程")
echo "多敲代码"
break
;;
"篮球")
echo "运动有益于身体健康"
break
;;
"游戏")
echo "少玩游戏"
break
;;
*)
echo "输入有误,重新输入"
;;
esac
done
shell函数
系统函数
- 实现代码复用性
- 常用的系统函数:
basename [string / pathname] [suffix]用于提取文件名称,[suffix]表示曲调文件后缀名称dirname去掉文件名称,只留下目录名称
- 可以使用
declare -f查看所有系统函数
自定义函数
- 语法:
[ function ] funname ()
{
命令
[ reutrn 返回值 ]
}
# 调用函数
funname 参数1 传递参数2 ...
- 可以使用
$?获取返回值
#!/bin/bash
function sum()
{
read -p "请输入第一个数字" first
read -p "请输入第二个数字" second
return $((first + second)) # 表示返回两个数字的和,注意利用 $取出变量
}
sum
echo "返回值为: $?"
- 注意
(())返回的就是一个变量,可以使用$取得他的值
有参函数
$#表示参数个数$*以一个子夫差un显示所有向脚本传递的参数$$脚本运行的当前进程ID$!后台运行的最后一个进程$@和$*相同,但是使用的时候需要加上 引号,并且在引号中返回每一个参数$?显示最后一个命令的退出状态shell命令和函数的区别:shell命令(包含内置命令和外部脚本文件)在子shell中运行,运行时就会开启一个单独的进程- 但是函数在当前的
shell进程中运行
Shell重定向输入输出
重定向
- 标准输入: 从键盘读取用户输入的数据,然后把数据拿到
shell程序中使用 - 标准输出:
shell程序产生的数据,一般显示显示屏上共用户浏览查看 - 每一个
linux命令运行时就会打开三个文件,如下:stdin(标准输入),文件描述符号为0获取键盘上的输入数据stdout(标准输出),文件描述符号为1,将正确的数据输出到显示屏上stderr(输出文件),文件描述符号2,将错误信息将显示器
- 重定向:
- 标准输出表示从键盘输入到程序,输入重定向就是改变了这一个方向
- 标准输入表示从程序输出到显示器,输出重定向就是改变了这一个方向
- 命令如下(
>表示覆盖方式,>>表示追加数据) - 各种命令如下:
| 命令 | 说明 |
|---|---|
| 命令 > file | 将正确的数据输出到file文件中,覆盖方式 |
| 命令 < file | 将输入重定向从file文件中读取数据 |
| 命令 >> file | 将正确的数据重定向输出到file中,追加方式 |
| 命令 < file1 > file2 | 从file1文件中读取数据,输出数据到file2文件中 |
| 命令 fd > file | 将指定文件描述符fd将数据重定向输出到file文件中,覆盖方式 |
| 命令 fd >> file | 根据指定的文件描述符号fd将数据重定向输出到file文件中,追加方式 |
| 命令 fd > file fd1 >& fd2 | 将fd1 和 fd2文件描述符号合并输出到文件中(表示输入到fd1和fd2) |
| fd1 <& fd2 | 将fd1和fd2文件描述符合并从文件读取输入(合并输入) |
| << tag | 读取终端输出数据,将开始标记tag和结束tag之间的内容作为输入,标记名tag可以任意 |
- 例如:
echo "hello" > log.txt
echo "hello world" >> log.txt
ll -afdasfdf 2 > log.txt
ll -afafas >> log.txt 2>&1
echo "hello world" >> log.txt 2>&1 # 表示输入正确信息和错误信息(都可以输出到文件中)
输入重定向
- 可以使用
wc命令进行统计 wc [options] [文件名]options:-c统计字节数量-wword统计单词数量-lline统计行数
wc -l < log.txt
- 循环读取的方式如下:
while read str; do echo "$str" ; done < log.txt
rowno=1;while read str;do echo "第${rowno}行: $str";let rowno++;done < log.txt
- 通过标记读取数据
$ wc -l << EOF
> aaaa
> bbb
> ccc
> ddd
> eee
> EOF
shell中的工具
cut
cut: 用于切割提取指定列\字符\字节的数据- 语法:
cut [options] filename
options选项分析:-f 提取范围列号,获取第几行-d 自定义分割符自定义分割符号,默认就是制表符号-c 提取范围以字符为单位进行分割-b 提取范围以字节为单位进行分割,这些字节将忽略多字节字符边界,除非也制定了-n标志-n和-b选项连续使用,部分个多字节字符
- 范围说明:
n-表示截取n列之后的n - m表示截取n - m列-m表示截取m列之前的列n1 n2 n3表示截取特定的列
# 表示截取第一列和第三列 d 比较重要
cut cut1.txt -d " " -f 1,3
- 按照字符进行截取
echo "helloworld" | cut -nb 1-3
- 切割一行中的数据
$ cat cut1.txt | grep itheima| cut -d " " -f 2
- 同时可以配合
head等命令使用-n表示条数
$ ps aux | grep bash | head -n 1 | cut -d " " -f 7
$ ifconfig | grep inet | head -n 1 | cut -d " " -f 10
sed
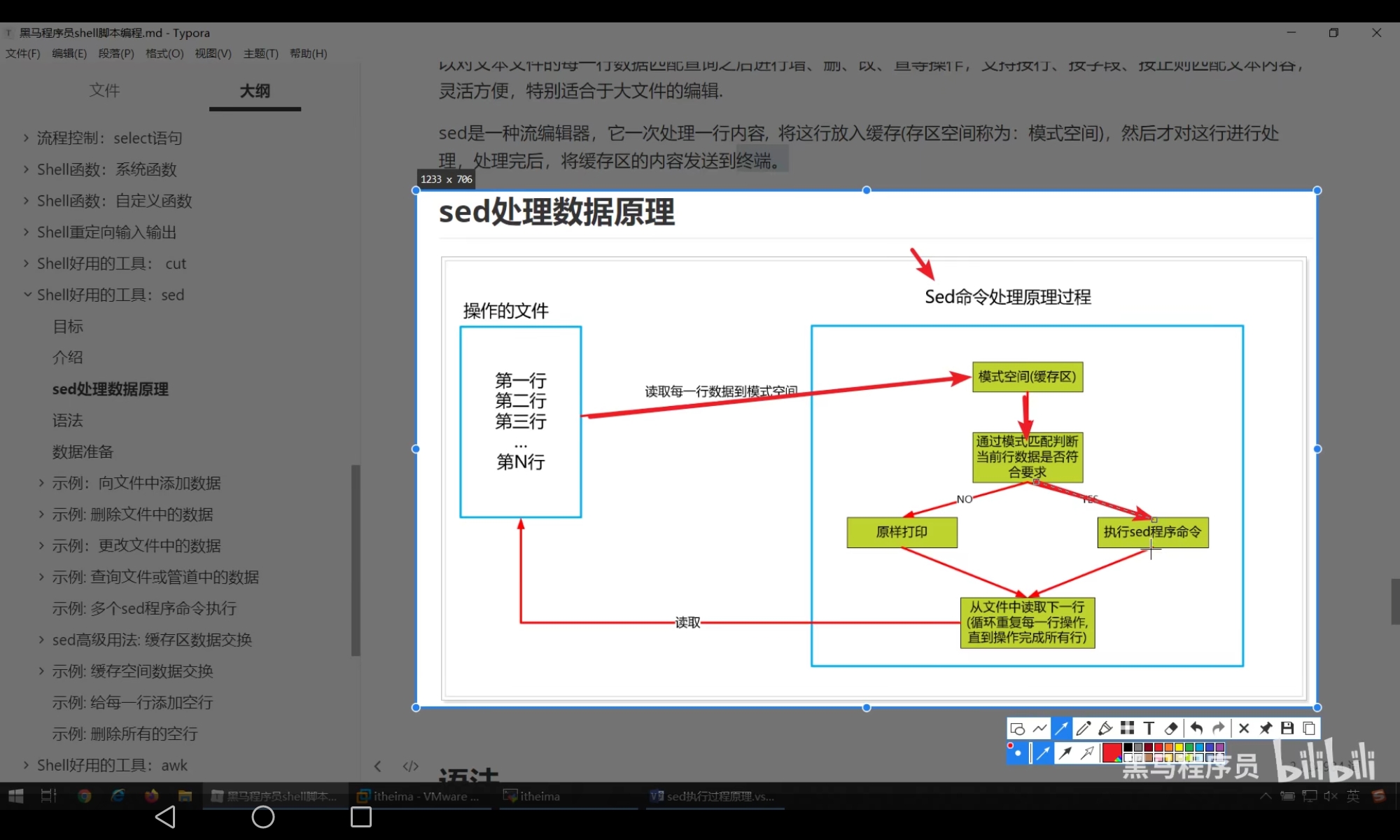
- 一种文件编辑工具:
- 处理流程:
- 语法:
sed [选项参数] [模式匹配/sed程序命令] [文件名]
# 模式匹配,sed会读取每一行数据到模式空间中,之后判断的当前行是否符合模式匹配要求,符合要求就会执行 sed命令,否则就不会执行 sed命令,如果不懈匹配模式,那么每一行都会执行sed程序命令
- 选项参数:
-e直接在指令模式上进行sed动作编辑,他告诉sed下一个参数解释为一个sed指令,只有当命令行上给出多个sed指令才需要使用-e选项,一行命令语句可以指定多个sed命令-i直接对于内容进行修改,不加上-i是默认只是预览,不会对于文件作出实际修改-f后跟上了保存sed指令的文件-n取消默认输出,sed默认会输出所有文本内容,使用-n参数后只会显示处理过的行-r reguler使用拓展正则表达式,默认情况下sed之后识别基本正则表达式*
- 基本命令描述如下:
aadd新增,a的后面可以接上字符串,在下一行出现cchange更改,更改匹配行的内容ddelete删除,删除匹配的内容iinsert插入,向匹配行前面插入内容pprint打印,打印出匹配的内容,通常和-n选项和用ssubstitute替换,替换调匹配的内容=用于打印被匹配的行号n读取下一行,遇到n会自动跳转到下一行
- 特殊符号:
!就像一个sed命令,放在限制条件的后面表示去反{sed命令1;sed命令2}多个命令操作同一个行
- 例如:
- 插入数据
# 基本上就是 `条件 选项 添加字符`的形式
$ sed -i '3ahello' sed.txt
# 表示在第三行的后面加上`hello` `-i`表示修改参数
$ sed '/itheima/ahello' sed.txt
# 表示在 `itheima` 的后面添加数据
$ sed '$ihello' sed.txt
# 表示在最后一行前面添加数据
- 删除文件中的数据
# 删除第二行数据
$ sed '2d' sed.txt
# 删除奇数行 ~表示每隔几行
$ sed '1~2d' sed.txt
# 删除 1 - 3行
$ sed '1,3d' sed.txt
# 取反
$ sed '1,3!d' sed.txt
# 删除最后一行
$ sed '$d' sed.txt
# 删除含有某一行的数据
$ sed '/itheima/d' sed.txt
# 删除匹配和最后一行
$ sed '/itheima/,$d' sed.txt
# 删除匹配和最后一行
$ sed '/itheima/,+1d' sed.txt
# 删除部匹配的行
$ sed '/itheima\|itcast/!d' sed.txt
- 更改文件中的数据
# 包含 itheima 修改为 hello
$ sed '/itheima/chello' sed.txt
# 最后一行修改为 hello
$ sed '$chello' sed.txt
# 替换每行第一个 hello
$ sed 's/itheima/hello/' sed.txt
# 全局匹配替换(一行中所有都会替换)
$ sed 's/itheima/hello/g' sed.txt
# 将每一行中的第二个进行匹配替换
$ sed 's/itheima/hello/2' sed.txt
# 替换之后把内容写入到文件中
$ sed 's/itheima/hello/2w sed2.txt' sed.txt
# 只显示修改的行(p表示显示,n表示匹配)
$ sed -n 's/itheima/hello/2pw sed2.txt' sed.txt
# 正则表达式替换
# // 表示替换成空字符串
$ sed -n '/i/s/t.*//p' sed.txt
# 每一行的末尾拼接 test
$ sed 's/$/& test/' sed.txt
# 每一行行首拼接 #
$ sed 's/^/&#/' sed.txt
- 查询操作
# 查询含有 itcast 的数据
$ sed -n '/itcast/p' sed.txt
# 查询 bash
$ ps aux | sed -n '/bash/p'
- 执行多个命令
# 执行多个shell命令
$ sed -e '1d' -e 's/itheima/itcast/g' sed.txt
# 执行多个shell命令
$ sed '1d;s/itheima/itcast/g' sed.txt
sed高级用法:缓存区数据交换
- 模式空间和暂存空间:
sed命令读出来每一行数据存放的空间叫做模式空间,会在该空间中对于读到的数据作相应处理- 此外
sed还有一个额外的空间就是暂存空间,暂存空间刚开始只有一个空行 sed可以通过相关的命令从模式空间向暂存空间去内容放入到模式空间中
- 命令:
h将模式空间中的内容复制到暂存空间中(覆盖方式)H将模式空间中的内容复制到暂存空间中(追加方式)g将暂存空间中的数据复制到模式空间中(覆盖方式)G将暂存空间中的数据复制到模式空间中(追加方式)x交换两个空间的内容
- 演示
# 将模式空间中的第一行复制到暂存空间(覆盖模式),并且把暂存空间的最后一行复制到模式空间中(追加模式)
$ sed '1h;$G' sed.txt
# 同时删除第一行数据
$ sed '1{h;d};$G' sed.txt
# 第一行的数据赋值粘贴
# 模式空间第一行复制到暂存空间中,最后把暂存空间爱你的内容赋值粘贴从第2行开始到最后一行的数据
$ sed '1h;2,$g' sed.txt
# 将前三行数据复制到暂存空间,之后把暂存空间的所有内容复制到最后一行
$ sed '1,3H;$G' sed.txt
# 暂存空间中有一行空行
# 添加空行,此时会给每一行给一个空行
$ sed 'G' sed.txt
# 删除空行(正则表达式处理)
$ sed '/^$/d' sed.txt
- 暂存空间的作用就是暂存数据进行数据交换
awk
- 一个文本分析工具
- 语法:
awk [options] 'pattern{action}' {filename}
- 选项:
-F指定输入文件拆分分割符号
- 内置变量:
NF浏览记录的域的个数,根据分割符号分割之后的列数量NR已读的记录数量$n表示整条数据$0表示整条记录,$n表示第n个域$NF表示最后一列的信息
- 实例
# 默认按照空格分割数据
$ echo "abc 123 456" | awk '{print $1"&"$2"&"$3}'
# 结果
abc&123&456
# 搜索含有关键字的所有行
$ awk '/root/{print $0}' passwd
# 打印第七列数据
# 注意分割之后还是可以通过 $0 获取到内容
# 注意只有表达式需要 {}
$ awk -F ":" '/root/{print $7}' passwd
# 获取文件名,行号,列号,内容
$ awk -F ":" '{print "文件名:"FILENAME",行号:"NR",烈数:"NF",内容:"$0}' passwd
# 拼接字符串的方式
$ awk -F: '{printf("文件名:%s,行号:%s,列号:%s,内容:%s\n",FILENAME,NR,NF,$0)}' passwd
# 注意内容需要使用 `{}`括号
# 但是 shell 中可以不用使用 () 调用参数即可
# 打印第二行信息
$ awk -F ":" 'NR==2{printf("文件名:%s,内容:%s\n",FILENAME,$0)}' passwd
# c 开头
$ ls -a | awk '/^c/'
# 还可以使用 NF打印最后一列
# 甚至可以写逻辑语句
# 使用多个分割符号进行分割
$ echo "one:two/three" | awk -F "[:/]" '{print $1"&"$2"&"$3}'
# 添加开始和结束
$ echo -e "abc\nabc"| awk 'BEGIN{print "开始 ..."}{print $0}END{print "结束了 ..."}'
# -e 表示处理特殊字符串
# 默认使用空格分割
$ echo "abc itheima itcast" | awk -v str="" '{for(n=1;n<=NF;n++){str=str$n}} END{print str}'
# -v相当于定义变量
# 运算操作
$ echo "2.1" | awk -v i=1 '{print $0+i}'
# 分割操作
$ ifconfig | awk '/broadcast/{print $0}'|head -n 1 | awk '{print $2}'
# 显示行号
$ sed 'G' sed.txt | awk '/^$/{print NR}'
- 总结:
awk在查询数据方面,可以通过条件来进行文本操作,内置多种文本变量,可以通过循环等操作查询到的字符
sort
- 语法:
sort (options) 参数
- 选项:
-nnumber按照数值大小排序-rreverse以相反的顺序来排序-t 分割字符设置排序时使用的分割字符,默认空格就是分割符-k指定需要排列的列2,2表示按照第二列进行排序-d排序时,处理英文字母,数字和空格外,忽略其他字符-f排序时将小写字母视为大写字母-b忽略每一行前面开始出的空格字符-o 输出文件将排序之后的结果存入到指定的文件中-u意味着唯一的(unique),输出的结果时完全去重的-m将几个排序的文件进行合并
- 实例
# 表示分割并且按照第二列排列
$ sort -t " " -k2n,2 sort.txt
# 按照两列去重
$ sort -t " " -k2n,2 -uk1,2 sort.txt
# 保存结果
$ sort -t " " -k2n,2 -uk1,2 -o sort1.txt sort.txt
# 降序排列
$ sort -t " " -k2nr,2 -uk1,2 sort.txt
# 按照多列排序,注意选项含义
$ sort -t "," -k1,1 -k3nr,3 sort.txt
- 使用:
- 字符串升序:
sort -kstart,end 文件 - 字符串降序:
sort -kstartr,end 文件 - 数字升序:
sort -kstartn,end 文件 - 数字下序列
sort -kstarttnr,end文件 - 多列排序:
sort -kstart[nr],end -kstart[nr],end ... 文件
- 字符串升序:
多线程编程
线程概念
Linux下线程的本质:LWP(light weight process) 轻量级的进程,本质仍然是进程(在Linux环境下)- 进程: 有独立的进程地址空间,有独立的
PCB - 线程: 有独立的
PCB,但是没有独立的地址空间(共享) - 区别: 在于是否共享地址空间 独居(进程) 合租(线程)
Linux下:- 线程: 最小的执行单位
- 进程: 最小的分配资源的单位,可以看成只有一个线程的进程
- 当利用
creat函数创建线程之后,进程就会退化成线程 - 所以对于并发执行的进程,如果开启更多的线程,那么就会由更多的线程来抢夺
cpu的执行权利这就使得该进程有更多的机会执行,但是并不是线程越多执行机会越多
- 可以使用
ps -Lf 进程ID来查看进程的线程号(不是线程ID),线程号 -->cpu执行的最小单位
Linux内核线程实现原理
- 注意以下几点:
- 轻量级进程,也有
PCB,创建线程使用的底层函数和进程一样,都是clone - 从内核里面看进程和线程都是一样的,都有各自不同的
PCB,但是PCB中执行内存资源的三级页表是相同的 - 进程可以蜕变成线程
- 线程可以看成寄存器和栈的集合
- 在
linux下,线程是最小的执行单位,进程是最小的分配资源的单位
- 轻量级进程,也有
- 实际上,在一个进程中的用户空间中存储的变量并不是直接通过
MMU映射到真实的物理内存空间,而是首先借助PCB中的指针,这一个指针指向一个页目录,页目录中的指针指向页表,页表中的指针指向物理页面,物理页面存在着真实的目录内存,由于创建线程的过程底层其实就是调用了clone方法,所以他的pcb中的指针和原来的进程的pcb中的指针一样,所以指向同样一块内存地址空间 - 三级映射: 进程
PCB--> 页目录(可以看成数组,首地址位于PCB中) --> 页表 --> 物理页面 ---> 内存单元
线程的共享和非共享
- 线程共享资源:
- 文件描述符号表
- 每一种信号的处理方式
- 当前工作目录
- 用户
ID和组ID - 内存地址空间(
.text./data.bssheap共享库)(没有栈)
- 线程非共享资源:
- 线程
id - 处理器线程和栈指针(内核栈)
- 独立的栈空间(用户栈空间)
errorno变量(是一个全局变量)- 信号屏蔽字
- 调度优先级
- 线程
- 优点:
- 提高程序并法性
- 开销比较小
- 数据通信,共享数据方便
- 缺点:
- 库函数,不稳定
- 调试,编写困难,
gdb不支持 - 对于信号支持不好
Linux下实现方法导致进程,线程差别不是特别大
线程控制原语
创建线程
pthread_self函数
- 作用: 获取线程
ID - 头文件:
<pthread.h> - 函数原型:
pthread_t pthread_self(void);
- 返回值: 返回线程
ID - 注意线程
ID用于在一个进程中标记线程,在Linux本质就是lu的别名,其他的系统中使用结构体的方式实现,线程ID是线程内部的识别标志
pthread_create函数
- 作用: 创建新的线程
- 函数原型如下:
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void *),
void *restrict arg);
- 遍历的时候需要链接
pthread库 - 参数:
thread: 传出参数,作用就是可以带出线程IDattr: 表示设置线程的属性,一般传入NULL表示传入默认属性start_routine: 表示需要传入的执行函数(参数和返回值都是泛型类型)arg: 表示函数的参数
- 演示
demo:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
#include<errno.h>
// 子线程的回调函数
// 注意回调函数的类型 (void*)(*func)(void*)
void* my_func(void* arg)
{
// 获取进程号和线程ID
printf("thread: pid = %d , tid = %lu \n" , getpid() , pthread_self());
return NULL;
}
int main()
{
// 使用 pthread_self 获取线程 ID
pthread_t tid;
tid = pthread_self();
printf("tid = %lu \n" , tid); // 相当于独享进程空间的线程
printf("pid = %d \n" , getpid());
// 使用 pthread_create创建线程
int ret = pthread_create(&tid , NULL , my_func , NULL);
if(ret != 0){
perror("create a thread failed !!! \n");
exit(1);
}
printf("main: pid: %d , tid: %lu \n" , getpid() , pthread_self());
// 需要让主线程阻塞等待一段时间
sleep(1);
}
-
注意得到的结果中,
main和pthread的pid一样但是tid不一样 -
由于需要传入的函数必须是
void*(*func)(void*)类型,所以如果需要传入各种参数那么就需要定义结构体来作为传入参数,函数会被自动调用
循环创建子线程
- 如果使用以下代码循环创建子线程:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
// 回调函数
void* print_pthread(void* args)
{
int i = *((int*)args); // void* 类型相当于泛型,可以传递各种类型
printf("pthread %d: pid - %d , tid - %lu \n" , i + 1, getpid() , pthread_self());
return NULL;
}
int main()
{
// 循环创建多个子线程
pthread_t tid;
int ret , i;
for(i = 0 ; i < 5 ; i ++){
ret = pthread_create(&tid , NULL , print_pthread , (void*)&i);
if(ret != 0){
perror("create thread failed !!! \n");
exit(1);
}
}
printf("main: pid - %d , tid - %lu \n" , getpid() , pthread_self());
sleep(1);
}
- 就会发生如下结果:
pthread 4: pid - 88902 , tid - 124829323757248
pthread 5: pid - 88902 , tid - 124829334243008
pthread 5: pid - 88902 , tid - 124829313271488
pthread 5: pid - 88902 , tid - 124829302785728
main: pid - 88902 , tid - 124829340292928
pthread 6: pid - 88902 , tid - 124829292299968
- 错误原因分析: 以上代码中,由于
main函数和不同的线程有不同的栈帧,main函数的栈帧中存在变量i,如果使用地址传递的方式传递参数,就会导致此时线程的栈中的变量指向main函数的栈中的变量,但是main函数中的变量在不断变化,所以就会造成以上结果 - 所以最好在创建子线程的时候,使用值拷贝的方式传递参数
- 这里的
void*尽管可以当成一个可以转换为任意数据类型的泛型(类似于go中的空接口类型),void*占用8个字节,int占用4个字节所以转换的时候不会造成精度的缺失 - 各种类型占用的空间如下,注意指针占用
8个字节(64位编译器):
- 这里解释以下为什么说
64位操作系统中int占用8个字节:- 注意这里的
int并不是指的就是int,而是int类型的变量,比如long等,long在32位操作系统中占用4个字节但是在64位操作系统中占用8个字节,位数不同的操作系统的寻址能力不同,体现与指针的位数,比如64位操作系统中的寻址范围就是 $2^64$ 所以指针就占用8个字节也就是64个bit
- 注意这里的
- 正确代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
// 回调函数
void* print_pthread(void* args)
{
int i = (int)args; // void* 类型相当于泛型,可以传递各种类型
printf("pthread %d: pid - %d , tid - %lu \n" , i + 1, getpid() , pthread_self());
return NULL;
}
int main()
{
// 循环创建多个子线程
pthread_t tid;
int ret , i;
for(i = 0 ; i < 5 ; i ++){
ret = pthread_create(&tid , NULL , print_pthread , (void*)i);
if(ret != 0){
perror("create thread failed !!! \n");
exit(1);
}
}
printf("main: pid - %d , tid - %lu \n" , getpid() , pthread_self());
sleep(1);
}
线程和共享
- 线程之间共享全局变量
- 线程默认共享数据段,代码段的呢个地址空间,常用的就是全局变量,但是进程不会共享全局变量,只可以借助
mmap(进程中遵循读时共享,写时复制的原则,其实就是建立了副本)
- 线程默认共享数据段,代码段的呢个地址空间,常用的就是全局变量,但是进程不会共享全局变量,只可以借助
- 注意共享的含义就是子线程改变变量,父线程中的数据也会进行相同的改变
- 验证:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
int var = 20;
void* pthread_handler(void* arg)
{
var = 200;
printf("thread: var = %d \n" , var);
return NULL;
}
int main()
{
pthread_t tid ;
int ret;
ret = pthread_create(&tid , NULL , pthread_handler , NULL);
if(ret != 0){
perror("creat thread failed !!! \n");
exit(1);
}
sleep(1);
printf("main: var = %d \n" , var);
}
- 注意
C语言中各个内存区域和作用:
pthread_exit函数
- 作用: 线程退出
- 函数原型:
[[noreturn]] void pthread_exit(void *retval);
- 参数:
retval表示传出参数,用于承载子线程中返回值 - 为什么使用
pthread_exit,这是由于exit用于退出整个进程,而不是退出线程,return表示返回给函数调用者 - 利用
pthread_exit退出只是将线程退出,并且不会影响其他进程 - 各种退出效果总结如下:
return返回到调用者那里去pthread_exit将调用该函数的线程退出exit退出它的进程
- 三者的对比如下:
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#include<unistd.h>
// 演示 return exit pthread_exit 三者之间的区别
void* pthread_handler(void* arg)
{
int i = (int)arg;
if(i == 2){
// exit(0); // 表示退出当前进程
// return NULL; 返回给函数的调用这
pthread_exit(NULL); // 表示退出线程
}
printf("The %d th thread , tid: %ld \n" , i + 1 , pthread_self());
return NULL;
}
int main()
{
pthread_t tid;
int ret;
int i;
for(i = 0 ; i < 5 ; i ++){
ret = pthread_create(&tid , NULL , pthread_handler , (void*)i);
if(ret != 0){
perror("create thread failed !!! \n");
exit(1);
}
}
// sleep(1);
pthread_exit(NULL); // 表示退出父进程
}
pthread_join函数
- 作用: 阻塞等待线程退出,获取线程退出状态,其作用就是对应于进程中的
waitpid()函数 - 函数原型:
int pthread_join(pthread_t thread, void **retval);
- 参数:
thread表示需要回收的线程IDretval表示获取函数的退出状态(需要回收void*)(比如进程的退出值就是pid)(注意这里的设计逻辑,如果返回值是int类型,那么就需要使用int*类型回收返回值,如果返回值是void*类型,那么就需要使用void**回收返回值)(参考wait函数使用&status作为传出参数)
- 注意
pthread_join会阻塞等待 - 另外一个小的知识点,注意指针只有分配了内存空间才可以使用常量赋值,但是如果没有分配内存空间还是可以使用指针或者地址赋值
char* p = NULL;
p = "123";// error
char* p = (char*)malloc(sizeof(char) * 10);
p = "hello"; //正确
int* p;
int k = 1;
p = &k // 正确
pthread_join使用方式如下:
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#include<unistd.h>
#include<string.h>
// 用于传递的数据
struct thrd{
int var;
char name[256];
};
void* thread_handler(void* arg)
{
struct thrd* ret_val;
ret_val = (struct thrd*) malloc (sizeof(struct thrd));
ret_val -> var = 100;
// 注意常量无法使用 = 进行赋值操作
strcpy(ret_val -> name , "hello thread!!!");
return (void*)ret_val;
}
int main()
{
pthread_t tid;
int ret;
ret = pthread_create(&tid , NULL , thread_handler , NULL);
if(ret != 0){
perror("create thread failed !!! ");
exit(1);
}
// 进行回收
struct thrd* res;
ret = pthread_join(tid , (void**)&res); // 注意参数
if(ret != 0){
perror("resouce my child failed !!!");
exit(0);
}
// 打印数据
printf("var = %d , name = %s \n" , res -> var , res -> name);
pthread_exit(NULL);
}
- 需要注意的事项如下:
- 在线程执行的函数中,不要返回一个局部变量的地址(此时这个函数的栈帧已经被销毁了,返回一个没有意义的栈地址)
- 可以在
main函数中定义一个变量,之后在线程的执行函数中操作这一个变量,这是由于函数执行完了之后main函数的栈地址仍然存在依然可用
- 以下情况也正确但是还是最好在堆区开启空间:
- 可以返回局部变量的值,但是不可以返回局部变量的地址
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#include<unistd.h>
#include<string.h>
// 用于传递的数据
struct thrd{
int var;
char name[256];
};
void* thread_handler(void* arg)
{
struct thrd* ret_val = (struct thrd*) arg;
// ret_val = (struct thrd*) malloc (sizeof(struct thrd));
ret_val -> var = 100;
// 注意常量无法使用 = 进行赋值操作
strcpy(ret_val -> name , "hello thread!!!");
return (void*)ret_val;
}
// void* thread_handler(void* arg)
// {
// return (void*)100;
// }
int main()
{
pthread_t tid;
int ret;
struct thrd* arg;
ret = pthread_create(&tid , NULL , thread_handler , (void*)arg);
if(ret != 0){
perror("create thread failed !!! ");
exit(1);
}
// 进行回收
struct thrd* res;
// int res;
ret = pthread_join(tid , (void**)&res); // 注意参数
if(ret != 0){
perror("resouce my child failed !!!");
exit(0);
}
// 打印数据
printf("var = %d , name = %s \n" , res -> var , res -> name);
printf("var = %d , name = %s \n" , arg -> var , arg -> name);
// printf("var = %d \n" , res);
pthread_exit(NULL);
}
- 连续: 循环创建多个子线程并且回收:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<pthread.h>
void* thread_handler(void* arg)
{
int i = (int)arg;
printf("I am the %d th child , my tid is %ld \n" , i + 1, pthread_self());
return NULL;
}
int main()
{
// 循环创建多个子线程
pthread_t tid[5];
int ret;
for(int i = 0 ; i < 5 ; i ++){
ret = pthread_create(&tid[i] , NULL , thread_handler , (void*)i);
if(ret != 0){
perror("create thread failed !!! ");
exit(1);
}
}
// 循环退出
for(int i = 0 ; i < 5 ; i ++){
ret = pthread_join(tid[i] , NULL);
printf("Successfully resource my child: %d \n" , i + 1);
}
pthread_exit(NULL);
}
pthread_cancel函数
- 作用: 用于杀死线程
- 函数原型如下:
int pthread_cancel(pthread_t thread);
- 参数:
thread表示需要杀死的进程ID
- 注意利用
pthread_cancel把进程杀死的时候 - 注意利用
pthread_cancel杀死进程的时候进入内核,需要进入内核的契机,如果子进程一直执行就没有取消点了,如果没有保存点,那么就可以使用pthread_testcancel()来设置取消点 - 成功被
pthread_cancel杀死的线程,返回-1,可以使用pthread_join回收这一个值 - 演示
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
#include<string.h>
void* thread_handler(void* arg)
{
while(1){
// printf("I am the child , tid : %ld \n" , pthread_self());
// sleep(1);
pthread_testcancel();
}
return (void*)100;
}
int main()
{
// 利用 pthread_cancel 杀死线程
pthread_t tid;
int ret = pthread_create(&tid , NULL , thread_handler , NULL);
sleep(5);
// 杀死线程
ret = pthread_cancel(tid);
if(ret != 0){
perror("can not canel this thread !!!");
exit(1);
}
// 进行线程的回收
int res;
ret = pthread_join(tid , (void**)&res);
if(ret != 0){
perror("resource thread failed !!!");
exit(1);
}
printf("exit code is %d \n" , res);
}
pthread_detach函数
- 作用: 实现线程分离,让线程脱离与主线程而存在
- 函数原型如下:
int pthread_detach(pthread_t thread);
- 参数:
- 线程号
- 对于线程中出现的错误,不可以使用
perror进行打印,这是由于无法翻译错误条件,可以使用strerror(errno)结合fprintf进行错误处理即可 - 注意即检测出错返回的方式 !!!
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
#include<string.h>
// 创建子线程任务
void* thread_handler(void* arg)
{
while(1){
printf("[thread] pid : %ld \n" , pthread_self());
sleep(1);
}
return NULL;
}
int main()
{
// 创建
pthread_t tid;
int ret = pthread_create(&tid , NULL , thread_handler , NULL);
if(ret == -1){
// 注意错误处理方式
fprintf(stderr , "create thread failed: %s \n" , strerror(ret));
exit(1);
}
sleep(1);
ret = pthread_detach(tid);
if(ret != 0){
fprintf(stderr , "detach thread failed: %s \n" , strerror(ret));
exit(1);
}
ret = pthread_join(tid , NULL);
if(ret != 0){
// perror("resource thread failed !!!");
fprintf(stderr , "resource thread failed: %s \n" , strerror(ret));
exit(1);
}
}
进程控制原语和线程控制原语的区别
- 创建:
forkpthread_create - 回收:
wait waitpidpthread_join - 杀死:
killpthread_cancel - 获取信息:
getpid()pthread_self - 退出:
pthread_exitexit
线程属性设置分离线程
- 线程属性就是创建线程时候的第二个参数
- 早期的
Linux kernel中的线程状态结构体:
typedef struct {
int etachstate; // 线程的分离状态
int schedpolicy; // 线程调度策略
struct sched_param schedparam; // 线程的调度参数
int inheritsched; // 线程的继承性
int scope; // 线程的作用域
size_t guardsize; // 线程栈末尾的警戒缓冲区大小
int stackaddr_set; // 线程栈的设置
void* stackaddr; // 线程栈的位置
size_t stacksize; // 线程栈的大小
}pthread_attr_t;
设置线程的分离状态
- 注意设置线程分离状态的好处: 不用回收线程,线程执行完之后自动就可以被回收了
- 线程属性初始化,使用如下两个函数:
pthread_attr_init用于初始化线程属性pthread_attr_destory销毁线程属性所占用的资源- 注意这两个函数的作用就是操作线程属性而不是操作线程
int pthread_attr_init(pthread_attr_t *attr);
int pthread_attr_destroy(pthread_attr_t *attr);
分离状态以及非分离状态
- 非分离状态: 线程默认的属性就是非分离状态,这一种情况下,原有的线程等待创建的线程结束,只有当
pthread_join函数返回的时候,创建的线程才算终止,才可以释放自己占用的系统资源 - 分离状态: 分离线程没有被其他的线程等待,自己运行结束了,线程也终止了,马上释放系统资源,应该根据自己的需要,选择适当的分离状态
- 设置线程分离的函数:
pthread_attr_setdetachstate - 查看线程分离状态的函数:
pthread_attr_getdetachstate - 参数(detachstate):
PTHREAD_CREATE_DETACHED(分离线程)PTHREAD_CREATE_JOINABLE(非分离线程)
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
int pthread_attr_getdetachstate(const pthread_attr_t *attr,
int *detachstate);
- 演示
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
#include<errno.h>
#include<string.h>
void* thread_handler(void* arg)
{
while(1){
printf("[thread] pid : %ld \n " , pthread_self());
sleep(1);
}
return (void*)100;
}
int main()
{
pthread_attr_t attr;
int ret = pthread_attr_init(&attr);
if(ret != 0){
fprintf(stderr , "init attr failed: %s \n" , strerror(ret));
exit(1);
}
// 设置分离
ret = pthread_attr_setdetachstate(&attr , PTHREAD_CREATE_DETACHED);
if(ret != 0){
fprintf(stderr , "detach thread failed: %s \n" , strerror(ret));
exit(1);
}
// 查看
int detachstate;
pthread_attr_getdetachstate(&attr , &detachstate);
if(detachstate == PTHREAD_CREATE_DETACHED) {
printf("Successfully set status !!! \n");
}
// 创建线程
pthread_t tid;
ret = pthread_create(&tid , &attr , thread_handler , NULL);
if(ret != 0){
fprintf(stderr , "create thread failed: %s \n" , strerror(ret));
exit(1);
}
// 回收线程
ret = pthread_join(tid , NULL);
if(ret != 0){
fprintf(stderr , "resource thread failed : %s \n" , strerror(ret));
exit(1);
}
ret = pthread_attr_destroy(&attr);
if(ret != 0){
fprintf(stderr , "destroy attr failed : %s \n" , strerror(ret));
exit(1);
}
}
- 总结:
- 定义线程属性
- 初始化线程属性
- 设置线程属性为分离状态
- 借助修改之后的线程属性来创建分离态的线程
- 回收看是否分离成功
线程的使用注意事项
- 主线程退出其他线程不退出,主线程需要调用
pthread_exit方法 - 避免僵尸线程:
pthread_joinpthread_detachpthread_create指定分离属性,被join线程会受到线程在回收之前可能就释放完了自己的所有内存资源,所以不应当返回被回收线程栈中的值 malloc和mmap申请的内存可以被其他线程释放(共享堆区)- 需要避免在多线程模型中调用
fork,除非马上exec,子进程只有调用fork的进程存在,其他进程在子进程中都需要使用pthread_exit - 信号的复杂语义很难和多线程共存,应该避免在多线程中引入信号机制
线程同步
- 线程同步,指的就是一个线程发生功能调用的瞬间,在没有得到结果之前,该调用不用返回 同时其他线程为保证数据一致性,不能调用该功能
- 多个线程同时操作一个共享变量的时候就需要进行进程同步操作(比如取钱的时候,如果一个线程作了判断之后另外的线程也进来对于数据进行操作,那么就会导致两个线程都对于这一个数据进行了操作,但还是以为只有一个变量对于数据进行了操作导致出错)
- 数据混乱的原因:
- 资源共享(独享资源则不会)
- 调度随机(意味着数据访问会出现竞争)
- 线程之间缺乏必要的同步机制
利用互斥锁进行线程同步
互斥量(mutex)
- 也就是互斥锁,作用就是利用互斥锁锁住全局变量,那么就可以保证公共资源每一次只会被一个线程进行操作,但是如果某一个线程直接访问全局变量那还是会导致数据不同布的问题,所以这些解决线程同步问题使用的锁都是建议锁而不是强制锁
- 锁的使用:
- 建议锁,用于锁住全局变量,锁住全局变量之后,就只有一个线程可以操作全局变量
操作函数
- 需要使用的函数如下:
pthread_mutex_init 函数
pthread_mutex_destory 函数
pthread_mutex_lock 函数
pthread_mutex_trylock 函数
pthread_mutex_unlock 函数
- 以上几个函数的返回值都是: 成功返回
0, 失败返回错误号 - 关注以下几个类型:
pthread_mutex_t 类型 本质是一个结构体,为了简化理解,应用的时候可以忽略实现细节,简单当成整数看待
pthread_mutex_t mutex; 变量 mutext只有两种取值: `0` 和 `1`
- 使用锁的步骤:
pthread_mutex_t lock创建锁pthread_mutex_init初始化pthread_mutex_lock加锁- 操作全局变量
pthread_mutex_unlock解锁pthread_mutex_destroy销毁锁
pthread_mutex_init函数
- 作用: 初始化锁
- 函数原型:
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
- 参数:
mutex表示锁attr表示锁相关的配置
- 成功返回
0失败返回errorno restrict关键字用于限定指针变量,被该关键字限定的指针变量所指向的内存操作,必须由本指针完成
pthread_mutex_destory函数
- 作用: 销毁锁
- 函数原型:
int pthread_mutex_destroy(pthread_mutex_t *mutex);
- 参数:
- 表示需要释放的锁
pthread_mutex_lock函数
- 作用: 加锁
- 函数原型:
int pthread_mutex_lock(pthread_mutex_t *mutex);
- 参数:
- 表示所加上的锁
- 成功返回
0,失败返回errorno
pthread_mutex_unlock函数
- 作用: 解锁
- 函数原型:
int pthread_mutex_unlock(pthread_mutex_t *mutex);
- 参数: ...
- 返回值: ...
- 进行互斥锁操作的
demo如下: - 这里操作的全局变量就是
stdout
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#include<unistd.h>
#include<string.h>
// 定义锁
pthread_mutex_t mutex;
// 子线程需要执行的操作
void* thread_handler(void* arg)
{
while(1){
pthread_mutex_lock(&mutex);
printf("hello ");
sleep(rand() % 3);
printf("world \n");
pthread_mutex_unlock(&mutex);
sleep(rand() % 3);
}
return NULL;
}
int main()
{
// 随机时间种子
srand(time(NULL));
// 初始化锁
pthread_t tid;
int ret;
ret = pthread_mutex_init(&mutex , NULL);
if(ret != 0){
fprintf(stderr , "init mutex failed: %s \n" , strerror(ret));
exit(1);
}
ret = pthread_create(&tid , NULL , thread_handler , NULL);
if(ret != 0){
fprintf(stderr , "create thread failed: %s \n" , strerror(ret));
exit(1);
}
sleep(3);
while(1){
pthread_mutex_lock(&mutex);
printf("HELLO ");
sleep(rand() % 3);
printf("WORLD \n");
pthread_mutex_unlock(&mutex);
sleep(rand() % 3);
}
ret = pthread_mutex_destroy(&mutex);
if(ret != 0){
fprintf(stderr , "destory mutex failed: %s \n" , strerror(ret));
exit(1);
}
}
- 使用技巧: 注意
mutex的位置,不要再锁操作的代码中进行休眠,否则很容易导致某一个线程不断执行某一个业务逻辑,长时间占用CPU - 一定需要注意锁的粒度,越小越好(访问共享数据之前加锁,访问结束之后立刻解锁)
mutex类型可以看成int类型,初始化之后可以看作mutex = 1lock可以想象成mutex --同时unlock可以想象成mutex++,虽然本质就是结构体,但是这样利于学习- 对于
mutex的操作:- 加锁:
--操作,阻塞线程 - 解锁:
++操作,唤醒阻塞在锁上的线程 try锁: 尝试加锁,成功++,失败返回(注意此时不会阻塞,设置错误号为EBUSY)
- 加锁:
try锁使用pthread_mutex_trylock函数
死锁
- 不是一种锁,而是一种现象,是使用锁不恰当而导致的错误
- 会产生死锁的现象:
- 对于一个锁反复
lock(自己把自己锁住了) - 两个线程各自持有一把锁,都在请求另外一把锁
- 对于一个锁反复
- 两种现象的解释如下:

- 第一种情况的死锁:
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#include<unistd.h>
#include<string.h>
pthread_mutex_t mutex; // 模拟死锁
int var = 1;
void* thread_handler(void* arg)
{
while(var <= 100){
pthread_mutex_lock(&mutex);
pthread_mutex_lock(&mutex);
printf("[thread] tid = %ld , var = %d \n" , pthread_self() , var);
var ++;
pthread_mutex_unlock(&mutex);
pthread_mutex_unlock(&mutex);
}
return NULL;
}
int main()
{
pthread_t tid;
int ret;
ret = pthread_mutex_init(&mutex , NULL);
if(ret != 0){
fprintf(stderr , "init mutex error: %s \n" , strerror(ret));
exit(1);
}
ret = pthread_create(&tid , NULL , thread_handler , NULL);
if(ret != 0){
fprintf(stderr , "create mutex error: %s \n" , strerror(ret));
exit(1);
}
// 阻塞回收
ret = pthread_join(tid , NULL);
if(ret != 0){
fprintf(stderr , "join mutex error: %s \n" , strerror(ret));
exit(1);
}
// 销毁
ret = pthread_mutex_destroy(&mutex);
if(ret != 0){
fprintf(stderr , "destory mutex error: %s \n" , strerror(ret));
exit(1);
}
}
- 第二种情况的死锁:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<pthread.h>
pthread_mutex_t mutex_a;
pthread_mutex_t mutex_b;
int var1 = 1;
int var2 = 1;
void* thread_handler1(void* arg)
{
while(var1 <= 100){
pthread_mutex_lock(&mutex_a);
pthread_mutex_lock(&mutex_b);
printf("[thread] tid = %ld , var1 = %d \n " , pthread_self() , var1);
var1 ++;
pthread_mutex_unlock(&mutex_b);
pthread_mutex_unlock(&mutex_a);
}
return NULL;
}
void* thread_handler2(void* arg)
{
while(var2 <= 100){
pthread_mutex_lock(&mutex_b);
pthread_mutex_lock(&mutex_a);
printf("[thread] tid = %ld , var1 = %d \n " , pthread_self() , var2);
var2 ++;
pthread_mutex_unlock(&mutex_a);
pthread_mutex_unlock(&mutex_b);
}
return NULL;
}
int main()
{
pthread_t tid[2];
int ret;
ret = pthread_mutex_init(&mutex_a , NULL);
if(ret != 0){
fprintf(stderr , "init mutex_a failed: %s \n" , strerror(ret));
exit(1);
}
ret = pthread_mutex_init(&mutex_b , NULL);
if(ret != 0){
fprintf(stderr , "init mutex_b failed: %s \n" , strerror(ret));
exit(1);
}
ret = pthread_create(&tid[0] , NULL , thread_handler1 , NULL);
if(ret != 0){
fprintf(stderr , "create thread_a failed: %s \n" , strerror(ret));
exit(1);
}
ret = pthread_create(&tid[1] , NULL , thread_handler2 , NULL);
if(ret != 0){
fprintf(stderr , "create thread_b failed: %s \n" , strerror(ret));
exit(1);
}
// 回收
for(int i = 0 ; i < 2 ; i ++){
ret = pthread_join(tid[i] , NULL);
if(ret != 0){
fprintf(stderr , " join thread failed: %s \n" , strerror(ret));
exit(1);
}
}
// 销毁
ret = pthread_mutex_destroy(&mutex_a);
if(ret != 0){
fprintf(stderr , "destory thread_a failed: %s \n" , strerror(ret));
exit(1);
}
ret = pthread_mutex_destroy(&mutex_b);
if(ret != 0){
fprintf(stderr , "destory thread_b failed: %s \n" , strerror(ret));
exit(1);
}
}
读写锁
- 与互斥锁类似,但是读写锁允许更高的并型性,他的特性为: 写独占,读共享
- 注意特点:
- 读共享,写独占
- 写锁优先级高
- 只有一把锁
- 使用读的方式给数据加锁--读锁,以写的方式给数据加锁--写锁
- 注意如果一个线程已经拿到锁了,就算是写锁的线程也会被阻塞,拿不到锁
- 这里思考以下为什么写锁的优先级别高,这是由于只有在写锁之后,读取到的数据才是真正的数据,避免了"读未提交的问题"
- 这里介绍几种情况,
Tn表示每一个线程n表示线程的顺序,n越小表示顺序越靠前:- 如果
T1为rT2为w那么T2就会获取锁 - 如果
T1为r并且已经获取到锁了,如果T2为w,那么T2还是会被阻塞,这是由于此时锁已经被获取了 - 如果
T1为r并且获取了锁 ,T2为rT3为w由于此时T3和T2都没有获取到锁,所以此时更具写锁优先级别高的元素应该是T3首先拿到锁,之后T2拿到进行数据的读取
- 如果
读写锁特性
- 读写锁是 "写模式加锁" 时,解锁之前,所有对该解锁加锁的线程都会被阻塞
- 读写锁是"读模式加锁" 时,如果线程使用读模式对其加锁成功,如果线程以写模式则会阻塞
- 读写锁时 "读模式加锁" 时,既有试图使用写模式加锁的线程,也有试图使用读模式加锁的线程,那么读写锁会阻塞随后的读模式锁请求,优先满足写模式锁,读锁写锁并行阻塞,但是写锁的优先级别高于读锁
- 读写锁也叫做共享-独占锁,当读写锁使用读模式锁住的时候,它是使用共享模式锁住的,当它使用写模式锁住的时候,它是使用独占模式锁住的,写独占,读共享
- 读写锁非常适合于对于数据结构的读的次数远大于写的次数
读写锁的常用函数
pthread_rwlock_initpthread_rwlock_destorypthread_rwlock_wrlockpthread_rwlock_rdockpthread_rwlock_trywrlockpthread_rwlock_tryrdlockpthread_rwlock_unlock- 以上的几个函数成功返回
0失败返回可以通过strerror()判断 - 锁的类型如下:
pthread_rwlock_t类型,用于定义一个读写锁变量pthread_rwlock_t rwlock
- 读写锁在读的线程多的时候效率会高于互斥锁
pthread_rwlock_init函数
- 作用: 初始化读写锁
- 函数原型:
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,
const pthread_rwlockattr_t *restrict attr);
- 参数参考
pthread_lock_init
pthread_rwlock_destory函数
- 作用: 销毁读写锁
- 函数原型:
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
- 注意其他函数基本可以参考互斥锁的相关的
API - 注意三句话即可:
- 读共享,写独占
- 写锁优先级高
- 全局只有一把读写锁
- 读写锁的
demo演示:
#include<stdio.h>
#include<pthread.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
// 读锁
int counter = 1;
pthread_rwlock_t rwlock; // 表示全局的读写锁
void* read_handler(void* arg)
{
int i = (int)arg;
while(1){
pthread_rwlock_rdlock(&rwlock);
printf("---------------read %d , tid = %lu , counter = %d \n" , i , pthread_self() , counter);
pthread_rwlock_unlock(&rwlock);
usleep(2000);
}
return NULL;
}
void* write_handler(void* arg)
{
int i = (int)arg;
int t;
while(1){
pthread_rwlock_wrlock(&rwlock);
usleep(1000);
t = counter;
printf("---------------write %d , tid = %lu , t = %d , counter = %d \n" , i , pthread_self() , t , ++counter);
pthread_rwlock_unlock(&rwlock);
usleep(5000);
}
return NULL;
}
int main()
{
// 初始化
pthread_rwlock_init(&rwlock , NULL);
pthread_t tid[8];
// 创建线程
int ret;
for(int i = 0 ; i < 3 ; i ++){
ret = pthread_create(&tid[i] , NULL , write_handler , (void*)i);
if(ret != 0){
fprintf(stderr , "create write thread failed: %s \n" , strerror(ret));
exit(1);
}
}
for(int j = 3 ; j < 8 ; j ++){
ret = pthread_create(&tid[j] , NULL , read_handler , (void*)j);
if(ret != 0){
fprintf(stderr , "create read lock failed: %s \n" , strerror(ret));
exit(1);
}
}
// 开始循环回收
for(int k = 0 ; k < 8 ; k ++){
pthread_join(tid[k] , NULL);
}
// 销毁锁
pthread_rwlock_destroy(&rwlock);
}
- 互斥锁:
pthread_mutex_t - 读写锁:
pthread_rwlock_t
条件变量
- 条件变量本身不是锁,但是它也可以造成线程阻塞,通常情况下与互斥锁配合使用,给多线程提供一个会合的场所
主要的应用函数
pthread_cond_initpthread_cond_destroypthread_cond_wait(相当于条件满足)pthread_cond_timewait(等待条件满足相当于try锁)pthread_cond_signal(表示条件满足进行通知)pthread_cond_broadcast(表示通知的时候使用广播模式)- 以上六个函数的返回值都是成功返回
0, 失败直接返回错误号 - 常用类型:
pthread_cond_t类型,用于定义条件变量pthread_cond_t cond
pthread_cond_init函数
- 作用: 初始化一个条件变量
- 注意条件判断
- 函数原型:
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
- 参数和返回值不用多说,此时可以说一下后面的静态初始化方式,其实就是利用宏定义来初始化这一个锁,基本上和
pthread_mutex_init和pthread_rwlock_init类似
pthread_cond_wait函数
- 作用:
- 阻塞等待条件变量
cond满足 - 释放已经掌握的互斥锁(解锁互斥量),相当于
pthread_mutex_unlock(注意1和2是一个原子操作) - 当被唤醒,
pthread_cond_wait函数返回的时候,解除阻塞并且重新申请互斥锁(pthread_mutex_lock)
- 阻塞等待条件变量
- 函数原型:
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);
pthread_cond_wait工作原理:
条件变量的生产者消费者模型
- 生产者消费者模型图如下:

- 公共操作:
- 首先定义锁
pthread_mutex_t lock - 初始化锁
pthread_mutex_init(&lock , NULL)
- 首先定义锁
- 消费者:
- 加锁(尝试获取数据):
pthread_mutex_lock(&lock) - 条件是否满足,不满足阻塞等待:
pthread_cond_wait(&cond , &lock) - 访问共享数据
- 释放锁
pthread_mutex_unlock(&lock),并且循环上述操作
- 加锁(尝试获取数据):
- 生产者:
- 生产数据
- 尝试获取锁(加锁):
pthread_mutex_lock(&lock) - 将数据存放到公共区域
- 解锁
pthread_mutex_unlock(&lock) - 唤醒消费者,满足条件:
pthread_cond_signal(&cond)或者pthread_cond_broadcast(cond) - 循环生产后续数据
- 消费者生产者模型代码实现:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<pthread.h>
typedef struct msg{
int num;
struct msg* next;
}Msg; // 共享数据相当于链表
pthread_mutex_t mutex; // 互斥锁
pthread_cond_t cond; // 条件变量
Msg* pub_msg; // 表示公共的数据
int i; // 表示消息的编号
// 消费者
void* consumer_handler(void* arg)
{
while(1){
// 1. 首先尝试获取数据,加锁
pthread_mutex_lock(&mutex);
// 2. 判断条件变量是否满足
while(pub_msg -> next == NULL){ // 注意条件判断,如果公共数据区存在数据的,那么就可以直接取出数据
pthread_cond_wait(&cond , &mutex);
}
// 3. 访问共享数据,此时已经加锁了
// 利用头删法消费数据
Msg* temp = pub_msg -> next;
pub_msg -> next = temp -> next;
printf("消费者获取: Message-%d \n" , temp -> num);
free(temp);
// 4. 释放锁
pthread_mutex_unlock(&mutex);
sleep(rand() % 3);
}
return NULL;
}
// 生产者
void* producer_handler(void* arg)
{
while(1){
// 1. 首先生产数据
Msg* node = (Msg*) malloc (sizeof(Msg));
sleep(1);
node -> num = i;
i ++;
// 2. 尝试加锁
pthread_mutex_lock(&mutex);
// 3. 把数据放入到公共区域
node -> next = pub_msg -> next;
pub_msg -> next = node;
printf("生产者生产: Message-%d \n" , node -> num);
// 4. 解锁
pthread_mutex_unlock(&mutex);
// 5. 唤醒消费者
pthread_cond_signal(&cond);
sleep(rand() % 3);
}
return NULL;
}
int main()
{
// 初始化
srand(time(NULL));
i = 1;
pthread_mutex_init(&mutex , NULL);
pthread_cond_init(&cond , NULL);
pub_msg = (Msg*) malloc (sizeof(Msg));
// 创建线程
int ret;
pthread_t consumer_tid , producer_tid;
ret = pthread_create(&consumer_tid , NULL , consumer_handler , NULL);
if(ret != 0){
fprintf(stderr , "create consumer failed: %s \n" , strerror(ret));
exit(1);
}
ret = pthread_create(&producer_tid , NULL , producer_handler , NULL);
if(ret != 0){
fprintf(stderr , "create producer failed: %s \n" , strerror(ret));
exit(1);
}
// 回收
pthread_join(consumer_tid , NULL);
pthread_join(producer_tid , NULL);
pthread_cond_destroy(&cond);
pthread_mutex_destroy(&mutex);
}
多个消费者使用while做
- 分析一下多个消费者消费时候的流程: 当某一个线程被唤醒的时候,由与使用的都是同样一个
cond所以都会被唤醒,所以如果被唤醒之后即可结束(使用if)判断条件的情况下,这一个线程就会立刻阻塞到lock的位置导致缺少对于公共数据是否为空减少判断导致出错 - 改进代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<pthread.h>
typedef struct msg{
int num;
struct msg* next;
}Msg; // 共享数据相当于链表
pthread_mutex_t mutex; // 互斥锁
pthread_cond_t cond; // 条件变量
Msg* pub_msg; // 表示公共的数据
int i; // 表示消息的编号
// 消费者
void* consumer_handler(void* arg)
{
int v = (int)arg;
while(1){
// 1. 首先尝试获取数据,加锁
pthread_mutex_lock(&mutex);
// 2. 判断条件变量是否满足
while(pub_msg -> next == NULL){ // 注意条件判断,如果公共数据区存在数据的,那么就可以直接取出数据
pthread_cond_wait(&cond , &mutex);
}
// 3. 访问共享数据,此时已经加锁了
// 利用头删法消费数据
Msg* temp = pub_msg -> next;
pub_msg -> next = temp -> next;
printf("消费者:%d 获取: Message-%d \n" , v + 1, temp -> num);
free(temp);
// 4. 释放锁
pthread_mutex_unlock(&mutex);
sleep(2);
}
return NULL;
}
// 生产者
void* producer_handler(void* arg)
{
while(1){
// 1. 首先生产数据
Msg* node = (Msg*) malloc (sizeof(Msg));
sleep(1);
node -> num = i;
i ++;
// 2. 尝试加锁
pthread_mutex_lock(&mutex);
// 3. 把数据放入到公共区域
node -> next = pub_msg -> next;
pub_msg -> next = node;
printf("生产者生产: Message-%d \n" , node -> num);
// 4. 解锁
pthread_mutex_unlock(&mutex);
// 5. 唤醒消费者
pthread_cond_signal(&cond);
sleep(0.5);
}
return NULL;
}
int main()
{
// 初始化
srand(time(NULL));
i = 1;
pthread_mutex_init(&mutex , NULL);
pthread_cond_init(&cond , NULL);
pub_msg = (Msg*) malloc (sizeof(Msg));
// 创建线程
int ret;
pthread_t producer_tid;
pthread_t consumer_tid[2];
for(int j = 0 ; j < 2 ; j ++){
ret = pthread_create(&consumer_tid[j] , NULL , consumer_handler , (void*)j);
if(ret != 0){
fprintf(stderr , "create consumer failed: %s \n" , strerror(ret));
exit(1);
}
}
ret = pthread_create(&producer_tid , NULL , producer_handler , NULL);
if(ret != 0){
fprintf(stderr , "create producer failed: %s \n" , strerror(ret));
exit(1);
}
// 回收
for(int j = 0 ; j < 2 ; j ++){
pthread_join(consumer_tid[j] , NULL);
}
pthread_join(producer_tid , NULL);
pthread_cond_destroy(&cond);
pthread_mutex_destroy(&mutex);
}
条件变量 signal注意事项
pthread_cond_signal(): 唤醒阻塞在条件变量上的(至少)一个线程pthread_cond_broadcast(): 唤醒阻塞在条件变量上的所有线程
信号量
- 相当于初始化值为
N的互斥量,可以当成锁看待(这样允许有N个线程同时操作共享变量,提高了执行效率)(N表示可以同时执行对于共享变量操作的线程个数)
主要应用函数
sem_initsem_destroysem_waitsem_trywait(相当于pthread_mutex_trylock)sem_timedwaitsem_post- 以上函数的返回值都是成功返回
0,失败返回-1,同时设置error(注意没有pthread前缀) - 使用的信号量类型:
sem_t类型: 本质仍然是结构体,但是应用期间可以看成简单函数,忽略实现细节(类似于文件描述符)sem_t sem规定信号量sem不可以< 0- 头文件:
<semaphore.h>
信号量操作函数
sem_wait:- 信号量大于
0,则信号量-- - 信号量等于
0,则造成信号阻塞 - 对应于
pthread_mutex_lock
- 信号量大于
sem_post:- 将信号量
++,同时唤醒阻塞在信号量上面的线程(类比pthread_mutex_unlock)
- 将信号量
- 但是,由于
sem_t的实现对于用户隐藏,所以所谓的操作++或者--都是只可以通过函数实现,不可以直接通过++,--符号 - 信号量的初始值决定了占用信号量的线程个数
- 信号量: 可以应用于线程或者进程
sem_init函数
- 作用: 初始化信号量
- 函数原型:
int sem_init(sem_t *sem, int pshared, unsigned int value);
- 参数:
sem信号量pshared0表示线程之间同步,1表示进程之间同步value就是表示 信号量的N
其他函数
sem_timedwait: 指定阻塞时间(尝试时间)- 函数原型如下:
int sem_timedwait(sem_t *restrict sem,
const struct timespec *restrict abs_timeout);
- 注意第二个参数:
abs_timeout就是指的绝对时间相当于1970.01.01
利用信号量实现生产者消费者模型
- 利用信号量实现生产者消费者模型:

- 注意实现方式中可以把
sem_wait当成对于信号量的--操作,sem_post看成++操作 - 代码实现如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
#include<string.h>
#include<semaphore.h>
#define NUM 5 // 表示队列的最大长度
int queue[NUM]; // 表示队列
sem_t star_num; // 表示 物品的数量
sem_t blank_num; // 表示空格的数量
// 消费者
void* consumer_handler(void* arg)
{
int i = 0; // 表示开始下标
while(1){
// 1. 首先利用 star_num 锁住
sem_wait(&star_num);
// 2. 消费元素
int target = queue[i];
printf("-----consumer: %d \n" , target);
queue[i] = 0;
// 3. 唤醒生产者
sem_post(&blank_num);
i = (i + 1) % NUM;
sleep(rand() % 3);
}
return NULL;
}
// 生产者
void* producer_handler(void* arg)
{
int i = 0;
while(1){
// 1. 首先利用blank_num锁住
sem_wait(&blank_num);
queue[i] = rand() % 1000 + 1;
printf("-----producer: %d \n" , queue[i]);
// 2. 表示唤醒消费者
sem_post(&star_num);
i = (i + 1) % NUM;
sleep(rand() % 3);
}
return NULL;
}
int main()
{
// 初始化信号量
srand(time(NULL));
for(int i = 0 ; i < NUM ; i ++){
queue[i] = 0;
}
sem_init(&star_num , 0 , 0);
sem_init(&blank_num , 0 , NUM);
// 创建线程
pthread_t consumer_tid , producer_tid;
int ret;
ret = pthread_create(&consumer_tid , NULL , consumer_handler , NULL);
if(ret != 0){
fprintf(stderr , "create consumer failed : %s \n" , strerror(ret));
exit(1);
}
ret = pthread_create(&producer_tid , NULL , producer_handler , NULL);
if(ret != 0){
fprintf(stderr , "create producer failed : %s \n" , strerror(ret));
exit(1);
}
// 回收
pthread_join(consumer_tid , NULL);
pthread_join(producer_tid , NULL);
// 销毁
sem_destroy(&star_num);
sem_destroy(&blank_num);
}
gcc
gcc 编译四步骤
gcc编译四步骤:- 预处理(展开宏定义,头文件,替换条件编译,删除注释,空行空白)
- 编译(检查语法规范,得到汇编代码)
- 汇编(将汇编指令翻译成机器指令)
- 链接(数据段合并,地址回填)
- 注意
-o的作用就是起名字,而不是链接 - 其中编译阶段消耗时间和系统资源最多
g++使用方式一样:
$ g++ -E hello1.cpp -o hello1.i
$ g++ -S hello1.i -o hello1.s
$ g++ -c hello1.s -o hello1.o
$ g++ hello1.o -o hello1
gcc常用的参数
-I 目录用于指定头文件,头文件和源代码不再同一个目录下就需要指定头文件- 制定了头文件的位置,或者指定了位置
# 指定头文件所在的目录
$ gcc hello.c -I ../inc -o hello
-c预处理编译和汇编,相当于进行了后面的步骤,前面的步骤执行了,所以最后使用的编译命令:
# 这里没有参数,已经完成了链接和之前的操作
$ gcc hello.c -o hello
-g编译时添加调试语句(可以调试)-On n=0~3编译优化,n的值越大优化越多(嵌入式编程中需要使用放置优化)-Wall显示所有的警告信息
$ gcc hello.c -o hello -Wall
-D表示向当前程序中注册一个宏,一般可以配合#ifdef使用,注意#ifndef表示没有定义
gcc hello.c -o hello -D HELLO
#include "../inc/hello.h"
#ifdef HELLO
#define HI 20
#endif
void say_hello()
{
printf("hello world");
}
int main()
{
say_hello();
printf("%d\n",HI);
return 0;
}
静态库和共享库(动态库)
- 静态库: 任何一个程序需要使用必须编译这一个静态库,静态库被编译到程序中,相当于库就相当于自己的函数
- 动态库: 只需要链接就可以了,不用编译到程序中
- 静态库优点:
- 效率比较高
- 动态库优点:
- 占用空间比较小
- 静态库: 对于空间要求比较低,时间要求比较高,比如操作系统的启动文件中
- 动态库: 对于时间要求比较低,对于空间要求比较高
制作静态库
- 自己写程序一般不写静态库
- 制作语法:
- 首先生成
.o文件
- 首先生成
# 获取 .o
$ gcc -c hello.c -o hello.o
$ ar rcs libmylib.a file1.o
linux中静态库的后缀:.a,windows中后缀:.lib
$ gcc -c add.c -o add.o
$ gcc -c sub.c -o sub.o
$ ar rsc mymathlib.a add.o sub.o
- 使用静态库
- 编译阶段出错会有行号
ld表示连接器,所以如果有ld就是链接出错
# 直接把静态库编译进去就可以了
$ gcc test.c mymathlib.a -o test
- 加上
-Wall会有如下警告信息: - 意思就是隐式声明,原因就是当函数没有定义并且没有声明的时候,编译器就会隐式声明
- 但是隐式声明必须需要推导出返回值和参数类型
test.c:6:28: warning: implicit declaration of function ‘add’ [-Wimplicit-function-declaration]
6 | printf("a + b = %d\n", add(a , b));
- 头文件守卫(作用就是放置同一个头文件重复包含)
#ifndef _MYMATH_H_
#define _MYMATH_H_
int add(int a , int b);
int sub(int a , int b);
#endif
- 总结一下问题:
- 如果没有在头文件中定义需要使用的函数,那么就会导致使用的时候如果使用
-Wall参数就会报错implicit declaration of ... - 所以在制作静态库的时候需要提供一个头文件用于声明好需要使用的函数
- 编译时利用
-I参数连接好头文件就可以了,当然需要在代码中include头文件
- 如果没有在头文件中定义需要使用的函数,那么就会导致使用的时候如果使用
- 常用的
C项目结构如下:inc: 存放头文件lib: 存放库文件src: 存放源代码
$ gcc test.c ../lib/mymathlib.a -o ../output/test -I ../inc
制作动态库
- 只有当调用到动态库中的函数的时候,才会加载这一个文件
- 地址回填: 汇编阶段之后,生成了
Xxx.o二进制代码,但是这一个代码中main函数的地址还没有确定(运行时才会确定),但是main函数中自己定义的函数的地址和main发生了绑定关系,比如main函数中定义了func那么汇编阶段之后,func的地址虽然没有确定,但是与main函数地址之间的关系确定了,当运行阶段main地址分配了,就叫做地址回填,此时func的地址才可以确定 - 只有在运行的时候,动态库的函数才可以被
main调用,所以动态库的函数晚绑定,所以需要生成地址固定的代码才可以制作动态库 - 制作过程:
- 利用
-c制作.o文件,制作位置无关的代码,这是由于调用的过程中需要让地址固定(-fPIC参数可以做到) - 使用
gcc -shared 制作动态库
- 利用
# 生成代码与位置无关的 .o 文件
gcc -c add.c -o add.o -fPIC
# 利用生成的代码制作动态库
gcc -shared -o lib库名.so add.o sub.o div.o
# 使用动态库.编译可执行程序的时候,指定使用的动态库 -l 指定库名 -L: 指定库的路径
gcc test.c -o test -l mymath -L ./lib
-l 指定库名-L 指定库的路径
# 编译指令
$ gcc dtest.c -o ../output/dtest -l mymath -L ../lib -I ../inc
- 注意上面会报错,找不到文件:
- 原因:
- 链接器: 工作处于链接阶段,工作时需要
-l和-L参数(完成数据段合并和地址回填) - 动态链接器: 工作处于程序运行阶段,工作时需要提供动态库所在的目录位置,会到特定的位置去找动态库(
LD_LIBRARY_PATH=./lib)
- 链接器: 工作处于链接阶段,工作时需要
- 注意动态库的名称一定需要需要使用 lib库名.so 的名称,链接时需要使用 库名(去掉 lib 和 so)
- 但是直接改变
LD_LIBRARY_PATH的方法不可取,最好把动态库安装到/usr/lib目录下便于寻找 - 为什么我的可以运行?
- 可以使用
ldd查看加载动态库的路径 - 解决方式:
- 改变
LD_LIBRARY_PATH的值 - 把自己的动态库放在
/lib下,这是由于gcc编译器会自动在/lib下寻找动态库(利用ldd可以查看) - 配置文件法:
- 编辑配置文件
/etc/ld.so.conf,include自己的动态库路径即可 - 之后让这一个配置文件生效
ldconfig /etc/ld.so.conf即可
- 编辑配置文件
- 改变
- 注意动态库和静态库都需要指定头文件
- 数据段合并的原理(之后学习了操作系统的内存管理在看):
- 其实底层就是链接时期,完成
.bss和.data的合并和.rodata和.text的合并
- 其实底层就是链接时期,完成
- 总结:
- 静态库制作步骤:
# 首先生成 .o 文件
$ gcc -c add.c -o add.o
$ gcc -c sub.c -o sub.o
# 利用 .o 文件生成静态库
$ ar rsc 静态库名称.a add.o sub.o
# 使用静态库
$ gcc test.c 静态库名.a -I 头文件路径 -o a.out
- 动态库制作步骤:
# 首先生成 .o 文件(地址和代码位置无关)
$ gcc -c add.c -o add.o -fPIC
$ gcc -c sub.c -o sub.o -fPIC
# 利用 .o 文件生成静态库
$ gcc -shared -o lib动态库名.so add.o sub.o
# 使用静态库
$ gcc test.c -o a.out -l 动态库名 -I 头文件路径 -L 动态库路径
- 解决动态链接器找不到动态库的问题:
- 改变(
LD_LIBRART_PATH) - 把
.so放在/lib下 - 配置
/etc/ld.so.conf,并且利用ldconfig时的这一个文件生效
- 改变(
gdb
- 调试作用
- 注意需要加上
-g用于生成调试信息,从而可以使用gdb进行检测 - 使用方式:
gdb 可执行程序名称进入调试状态list或者l显示源码list n或者l n表示从第n行开始显示源码b n表示在第n行设置断点run或者r表示执行程序,一般用于执行到断点的位置n表示next越过这一行直接进入下一行(在调试的时候使用)s表示进入这一行(step)p value可以用于查看变量的值,这就是表示查看value的值continue表示继续执行下面的函数,相当于放行quit退出
gdb进阶命令
- 如果出现了段错误,那么直接使用
run命令就可以,直接使用run命令,停止的位置就是段错误的位置 start命令表示从当前行开始执行(相当于当前行打了一个断点),之后可以使用s或者n进行下一步finish表示退出当前函数,回到进入函数的位置(结束当前函数调用,返回进入点)- 注意设置断点之后一定需要 `run
set args表示设置程序运行的参数,set args "aa" "bb" "cc" "dd"info b表示设置断点信息b 20 if i = 5表示只有i = 5的时候才可以设置断点,相当于循环中间才会让断点生效ptype 变量表示查看变量的类型- 栈帧: 表示随着函数的调用而在
stack开辟的一片内存空间,用于存放函数调用时产生的局部变量和临时值,当函数执行完毕的时候,栈帧就会消失,并且栈帧中存储着函数执行过程中的局部变量 backtrace(bt)查看函数的调用的栈帧和层级关系frame(f)切换函数的栈帧,作用就是可以在执行一个函数的同时切换到另外一个函数的栈帧的位置查看另外一个函数中的局部变量,但是前提就是这些函数没有执行完毕(注意使用run执行到断点的位置)display设置跟踪变量,对于一个变量使用了display之后,这一个变量就会被纳入到跟踪列表,之后使用display就可以跟踪变量undisplay 号码就可以取消对应号码的跟踪,下一次使用display就不会展示这一个变量了delete删除断点info locals查看局部变量- 常见错误:
- 没有符号表读取: 没有
-g选项
- 没有符号表读取: 没有
Makefile
- 相当于脚本,相当于一组命令的集合
Makefile中的注意点:- 一个规则
- 两个函数
- 三个自动变量
规则
- 一个规则:
- 目标: 依赖条件 # 表示格式
(一个
tab缩进)命令 - 命名方式(
makefile或者Makefile)
- 目标: 依赖条件 # 表示格式
(一个
- 一个最简单的
makefile如下:
hello:hello.c # 目标:依赖
gcc hello.c -o hello # 生成目标的命令
- 另外一个例子:
# hello:hello.c
# gcc hello.c -o hello
hello:hello.o
gcc hello.o -o hello
hello.o:hello.c
gcc -c hello.c -o hello.o
- 规则: 如果想要生成目标(比如
hello.o),检查规则中的依赖条件是否存在,如果不存在,就可以寻找是否存在规则用来生成该依赖文件(可以使用hello.c生成规则) - 考虑如下的
makefile文件:
test: add.c sub.c div1.c mul.c test.c
gcc test.c add.c sub.c div1.c mul.c -o test
- 如果这样写的话,如果其中的某一个文件发生了改变,如果还是利用这一个指令,那么没有改变的文件救护重复编译,造成时间的浪费
- 所以可以提前生成
.o文件 - 改写之后的
makefile如下:
# test: add.c sub.c div1.c mul.c test.c
# gcc test.c add.c sub.c div1.c mul.c -o test
test:add.o sub.o div1.o mul.o test.o
gcc test.o add.o sub.o div1.o mul.o -o test
add.o:add.c
gcc -c add.c -o add.o
sub.o:sub.c
gcc -c sub.c -o sub.o
div1.o:div1.c
gcc -c div1.c -o div1.o
mul.o:mul.c
gcc -c mul.c -o mul.o
test.o:test.c
gcc -c test.c -o test.o
- 此时指挥编译被修改过的文件
- 规则2: 检测规则中的目标是否需要更新,必须首先检测他的所有依赖,依赖中有任何一个被更新,则目标都会被更新
- 总结规则:
- 目标的时间必须晚于依赖条件的时间,否则就会更新目录
- 依赖条件如果不存在,找寻新的规则去产生依赖
- 注意
makefile会默认把第一个遇到的目标作为终极目标,如果这一个目标的依赖关系已经满足,那么就不会继续执行下面的目标了,所以生成可执行文件需要写在前面 - 但是可以指定
ALL 目标文件就可以解决这一个文件
# test: add.c sub.c div1.c mul.c test.c
# gcc test.c add.c sub.c div1.c mul.c -o test
# 表示指定终极目标
ALL: test
add.o:add.c
gcc -c add.c -o add.o
sub.o:sub.c
gcc -c sub.c -o sub.o
div1.o:div1.c
gcc -c div1.c -o div1.o
mul.o:mul.c
gcc -c mul.c -o mul.o
test.o:test.c
gcc -c test.c -o test.o
test:add.o sub.o div1.o mul.o test.o
gcc test.o add.o sub.o div1.o mul.o -o test
函数
wildcard函数
src = $(wildcard *.c)用于找到当前目录下的所有的.c文件,赋值给src
patsubst
obj = $(patsubst %.c , %.o , $(src))把src变量里面所有后缀为.c的文件替换成.o- 作用: 将包含参数
1的部分,替换成参数2 - 同时可以使用
clean删除所有的.o文件和原来生成的可执行文件 - 首先使用
make clean -n查看清除语句 - 之后利用
make clean删除语句
src = $(wildcard *.c) # src = add.c sub.c div1.c mul.c test.c
obj = $(patsubst %.c , %.o , $(src)) # obj = add.o sub.o div1.o mul.o test.o
test:$(obj)
gcc $(obj) -o test
add.o:add.c
gcc -c add.c -o add.o
sub.o:sub.c
gcc -c sub.c -o sub.o
div1.o:div1.c
gcc -c div1.c -o div1.o
mul.o:mul.c
gcc -c mul.c -o mul.o
test.o:test.c
gcc -c test.c -o test.o
clean:
-rm -rf $(obj) test
- 注意
clean没有依赖,并且-rm中-的作用就是删除不存在的文件的时候不会报错
自动变量
$@表示规则中的目标,在规则的命令中表示目标,只可以出现在命令的位置$<表示规则中的第一个条件,在规则的命令中表示第一个依赖条件如果引用到模式规则中,他可以把依赖条件列表中的依赖一次取出,套用于模式规则(相当于 一次循环)$^表示规则中的所有条件,表示所有依赖条件
src = $(wildcard *.c) # src = add.c sub.c div1.c mul.c test.c
obj = $(patsubst %.c , %.o , $(src)) # obj = add.o sub.o div1.o mul.o test.o
test:$(obj)
gcc $^ -o $@
add.o:add.c
gcc -c $< -o $@
sub.o:sub.c
gcc -c $< -o $@
div1.o:div1.c
gcc -c $< -o $@
mul.o:mul.c
gcc -c $< -o $@
test.o:test.c
gcc -c $< -o $@
clean:
-rm -rf $(obj) test
- 好处就是当程序中多了一个模块的时候,不用修改
makefile就可以了利用make编译得到可执行程序 - 模式规则: 可以使用模式匹配模拟规则:
%.o:%.c命令也是通用的 - 模式规则如下:
src = $(wildcard *.c) # src = add.c sub.c div1.c mul.c test.c
obj = $(patsubst %.c , %.o , $(src)) # obj = add.o sub.o div1.o mul.o test.o
test:$(obj)
gcc $^ -o $@
%.o:%.c
gcc -c $< -o $@
clean:
-rm -rf $(obj) test
- 静态模式规则:
$(obj):%.o:%.c gcc -c $< -o $@
- 表示对于某一个条件套用某一个模式规则,当模式规则不只有一个的时候,那么就会导致不知道需要找到那一个依赖才可以满足依赖关系
src = $(wildcard *.c) # src = add.c sub.c div1.c mul.c test.c
obj = $(patsubst %.c , %.o , $(src)) # obj = add.o sub.o div1.o mul.o test.o
test:$(obj)
gcc $^ -o $@
$(obj):%.o:%.c
gcc -c $< -o $@
%.s:%.c
gcc -S $< -o $@
clean:
-rm -rf $(obj) test
- 如果定义一个
clean文件,使用make clean的时候,就会被错误解析成需要制作一个clean文件 - 所以此时需要使用伪目标(不论是否符合条件都需要生成目标)
- 就是无论符合条件都会执行(
PHONY)
src = $(wildcard *.c) # src = add.c sub.c div1.c mul.c test.c
obj = $(patsubst %.c , %.o , $(src)) # obj = add.o sub.o div1.o mul.o test.o
test:$(obj)
gcc $^ -o $@
$(obj):%.o:%.c
gcc -c $< -o $@
%.s:%.c
gcc -S $< -o $@
clean:
-rm -rf $(obj) test
.PHONY: clean ALL
- 同时也可以链接静态库和动态库(
-l-L-Wall) - 注意
makefile中*的作用就是通配符号,但是%表示占位符号,用于指定特殊为位置的字符,一定需要注意二者的区别,在进行模式匹配的时候,一定需要注意使用%指定目标和依赖的位置关系
src = $(wildcard ./src/*.c) # src = *.c
obj = $(patsubst ./src/%.c , ./obj/%.o , $(src)) # obj = ./obj/add.o ./obj/sub.o ./sub/mul.c
ALL: test
include_path = ./inc
my_args = -Wall -g
test:$(obj)
gcc $^ -o $@ $(my_args) -I $(include_path)
$(obj):./obj/%.o:./src/%.c # 此时 注意 % 匹配的就是 add sub mul 就可以了,注意一定需要找到依赖的位置
gcc -c $< -o $@ $(my_args) -I $(include_path)
clean:
-rm -rf $(obj) test
.PHONY: clean ALL
# 注意头文件链接发生在预处理阶段,这里只需要链接所以不用 -I ./inc
- 注意预处理阶段就完成了头文件的展开,所以这里的链接阶段应该不需要头文件,但是为什么没有头文件也会报错 ????
- 或者可以使用如下参数:
-n模拟执行make命令-f指定文件执行make命令xxx.mk
- 注意
$(obj):%.o:%.c的含义,表示如果依赖是$(obj)需要依靠这一条规则生成,如果没有如上依赖,那么就不会作任何事情 - 以下
makefile用于生成该目录下所有可执行程序
src=$(wildcard *.c)
out=$(patsubst %.c,%,$(src))
ALL: $(out)
%:%.c
gcc $< -o $@
clean:
-rm -rf $(out)
.PYHONY: clean ALL
- 注意静态模式匹配的含义: 确定了需要匹配的字符串,对于这一个字符串,利用
%进行模式匹配,同时依赖中的%依赖于target中的% - 如果在同一个目录下
%表示匹配同一个名称 - 还可以指定文件:
src=$(wildcard ./src/*.c)
out=$(patsubst ./src/%.c,./out/%,$(src))
ALL: $(out)
./out/%:./src/%.c
gcc $< -o $@
clean:
-rm -rf $(out)
.PYHONY: clean ALL
- 总结一下: 如果使用模式匹配的方式,首先会利用依赖的匹配字符串在依赖的目录位置找到名称,确定
%的值,从而确定目标的名称,确定目标的名称之后,就可以通过命令生成对应的目标了 - 静态模式匹配使用的情况就是可以使用多种方式生成依赖,指定生成的方式,所以一般情况下不要使用
CMake
介绍
- 一种项目构建工具,如果使用编写
makefile的方式构建项目,由于不同的平台使用的构建构建工具不同(VS中的nmake和QtCreator中qmake)所以makefile依赖于当前的平台,利用cmake构建项目就可以自动生成makefile达到了跨平台的效果,同时由于makefile编写起来工作量太大,使用cmake可以更加便捷的帮助我们管理大型项目
CMake使用
注释
- 单行注释:
# 这是单行注释
- 多行注释:
#[[
这是多行注释
]]
入门案例
- 程序结构如下:
./Cmake-demo1/
├── add.c
├── app.c
├── div1.c
├── head.h
└── sub.c
- 在这一个目录中编写
CMakeLists.txt
cmake_minimum_required(VERSION 3.25.0)
project(calc)
add_executable(app app.c div1.c add.c sub.c)
- 程序解释如下:
cmake_minimum_required表示使用的cmake的最低版本要求,可选project指定项目的基本信息,包含名称,语言等信息add_excutable定义工程生成一个可执行程序,这里可以指定多个可执行程序
project可选参数如下:
# PROJECT 指令的语法是:
project(<PROJECT-NAME> [<language-name>...])
project(<PROJECT-NAME>
[VERSION <major>[.<minor>[.<patch>[.<tweak>]]]]
[DESCRIPTION <project-description-string>]
[HOMEPAGE_URL <url-string>]
[LANGUAGES <language-name>...])
add_excutable使用
add_excutable(可执行程序名称,源文件名称)
- 执行构建操作:
cmake CMakeLists.txt所在的路径用于执行CMakeLists.txt- 自动生成了
makefile执行make命令即可得到可执行程序
- 执行
cmake 目录命令之后的文件夹内容如下:
.
├── add.c
├── app
├── app.c
├── CMakeCache.txt
├── CMakeFiles
│ ├── 3.28.3
│ │ ├── CMakeCCompiler.cmake
│ │ ├── CMakeCXXCompiler.cmake
│ │ ├── CMakeDetermineCompilerABI_C.bin
│ │ ├── CMakeDetermineCompilerABI_CXX.bin
│ │ ├── CMakeSystem.cmake
│ │ ├── CompilerIdC
│ │ │ ├── a.out
│ │ │ ├── CMakeCCompilerId.c
│ │ │ └── tmp
│ │ └── CompilerIdCXX
│ │ ├── a.out
│ │ ├── CMakeCXXCompilerId.cpp
│ │ └── tmp
│ ├── app.dir
│ │ ├── add.c.o
│ │ ├── add.c.o.d
│ │ ├── app.c.o
│ │ ├── app.c.o.d
│ │ ├── build.make
│ │ ├── cmake_clean.cmake
│ │ ├── compiler_depend.make
│ │ ├── compiler_depend.ts
│ │ ├── DependInfo.cmake
│ │ ├── depend.make
│ │ ├── div1.c.o
│ │ ├── div1.c.o.d
│ │ ├── flags.make
│ │ ├── link.txt
│ │ ├── progress.make
│ │ ├── sub.c.o
│ │ └── sub.c.o.d
│ ├── cmake.check_cache
│ ├── CMakeConfigureLog.yaml
│ ├── CMakeDirectoryInformation.cmake
│ ├── CMakeScratch
│ ├── Makefile2
│ ├── Makefile.cmake
│ ├── pkgRedirects
│ ├── progress.marks
│ └── TargetDirectories.txt
├── cmake_install.cmake
├── CMakeLists.txt
├── div1.c
├── head.h
├── Makefile
└── sub.c
- 可见如果在当前目录中执行
CMake就会导致的当前目录结构十分混乱,所以一般都需要新建一个build目录,在build目录中执行构建操作 build目录中的构建结果如下:
.
├── app
├── CMakeCache.txt
├── CMakeFiles
├── cmake_install.cmake
└── Makefile
set函数的使用
- 可以用于设置变量的值(变量之间使用
;或者空格进行分割)
# SET 指令的语法是:
# [] 中的参数为可选项, 如不需要可以不写
SET(VAR [VALUE] [CACHE TYPE DOCSTRING [FORCE]])
- 使用方式如下:
cmake_minimum_required(VERSION 3.25.0)
project(calc)
set(SRC app.c div1.c add.c sub.c)
add_executable(app ${SRC})
- 指定使用的
C++标准
- 如果使用
g++指定方式如下:
$ g++ test.c -std=c++11 -o test
- 使用
set设置CMAKE_CXX_STANDARD变量的值
set(CMAKE_CXX_STANDARD 11)
- 在使用
cmake命令进行构建的时候,指定DCMAKE_CXX_STANDARD这一个宏定义的值
$ cmake CMakeLists.txt所在的目录 -DCMAKE_CXX_STANDARD 11
- 指定输出路径
- 直接修改
EXECUTABLE_OUTPUT_PATH即可
set(EXECUTABLE_OUTPUT_PATH, 目录名)
- 使用
set之后的CMakeLists.txt
cmake_minimum_required(VERSION 3.25.0)
project(calc)
set(SRC app.c div1.c add.c sub.c)
# set(CMAKE_CXX_STANDARD 11)
set(HOME /home/loser/公共/C++后端/Linux系统编程/code/Cmake/Cmake-demo1)
set(EXECUTABLE_OUTPUT_PATH ${HOME}/out)
add_executable(app ${SRC})
搜索文件
- 使用
aux_source_directory搜索路径
aux_source_directory(需要搜索的路径,存储搜索结果的变量)
- 改变项目的目录结构
.
├── build
├── CMakeFiles
│ ├── 3.28.3
│ │ ├── CMakeCCompiler.cmake
│ │ ├── CMakeCXXCompiler.cmake
│ │ ├── CMakeDetermineCompilerABI_C.bin
│ │ ├── CMakeDetermineCompilerABI_CXX.bin
│ │ ├── CMakeSystem.cmake
│ │ ├── CompilerIdC
│ │ │ ├── a.out
│ │ │ ├── CMakeCCompilerId.c
│ │ │ └── tmp
│ │ └── CompilerIdCXX
│ │ ├── a.out
│ │ ├── CMakeCXXCompilerId.cpp
│ │ └── tmp
│ ├── app.dir
│ │ ├── add.c.o
│ │ ├── add.c.o.d
│ │ ├── app.c.o
│ │ ├── app.c.o.d
│ │ ├── build.make
│ │ ├── cmake_clean.cmake
│ │ ├── compiler_depend.make
│ │ ├── compiler_depend.ts
│ │ ├── DependInfo.cmake
│ │ ├── depend.make
│ │ ├── div1.c.o
│ │ ├── div1.c.o.d
│ │ ├── flags.make
│ │ ├── link.txt
│ │ ├── progress.make
│ │ ├── sub.c.o
│ │ └── sub.c.o.d
│ ├── cmake.check_cache
│ ├── CMakeConfigureLog.yaml
│ ├── CMakeDirectoryInformation.cmake
│ ├── CMakeScratch
│ ├── Makefile2
│ ├── Makefile.cmake
│ ├── pkgRedirects
│ ├── progress.marks
│ └── TargetDirectories.txt
├── CMakeLists.txt
├── inc
│ └── head.h
├── out
│ └── app
└── src
├── add.c
├── app.c
├── div1.c
└── sub.c
- 使用方式如下:
cmake_minimum_required(VERSION 3.25.0)
project(calc)
# set(SRC app.c div1.c add.c sub.c)
# 搜索头文件
include_directories(${PROJECT_SOURCE_DIR}/inc)
aux_source_directory(${CMAKE_CURRENT_SOURCE_DIR}/src SRC)
# set(CMAKE_CXX_STANDARD 11)
set(HOME /home/loser/公共/C++后端/Linux系统编程/code/Cmake/Cmake-demo1)
set(EXECUTABLE_OUTPUT_PATH ${HOME}/out)
add_executable(app ${SRC})
- 注意
PROJECT_SOURCE_DIR表示项目所在的目录,就是当前CMakeLists.txt所在的目录 CMAKE_CURRENT_SOURCE_DIR也是当前CMakeLists.txt所在的目录
- 使用
file函数
file函数的使用方式如下:
file(GLOB/GLOB_RECURSE 变量名 需要搜索的目录)
- 使用方式:
file(GLOB MAIN_SRC ${CMAKE_CURRENT_SOURCE_DIR}/src/*.cpp)
file(GLOB MAIN_HEAD ${CMAKE_CURRENT_SOURCE_DIR}/include/*.h)
- 使用
file之后的CMakeLists.txt
cmake_minimum_required(VERSION 3.25.0)
project(calc)
# set(SRC app.c div1.c add.c sub.c)
# 搜索头文件
include_directories(${PROJECT_SOURCE_DIR}/inc)
# aux_source_directory(${CMAKE_CURRENT_SOURCE_DIR}/src SRC)
file(GLOB SRC ${CMAKE_CURRENT_SOURCE_DIR}/src/*.c)
# set(CMAKE_CXX_STANDARD 11)
set(HOME ${CMAKE_CURRENT_SOURCE_DIR})
set(EXECUTABLE_OUTPUT_PATH ${HOME}/out)
add_executable(app ${SRC})
- 注意
aux_source_directory指定的是文件夹 file指定的是具体的文件
包含头文件
- 上面使用过的,使用
include_directories函数
include_directories(头文件所在的目录名称)
- 使用方式:
cmake_minimum_required(VERSION 3.25.0)
project(calc)
# set(SRC app.c div1.c add.c sub.c)
# 搜索头文件
include_directories(${PROJECT_SOURCE_DIR}/inc)
# aux_source_directory(${CMAKE_CURRENT_SOURCE_DIR}/src SRC)
file(GLOB SRC ${CMAKE_CURRENT_SOURCE_DIR}/src/*.c)
# set(CMAKE_CXX_STANDARD 11)
set(HOME ${CMAKE_CURRENT_SOURCE_DIR})
set(EXECUTABLE_OUTPUT_PATH ${HOME}/out)
add_executable(app ${SRC})
PROJECT_SOURCE_DIR一般就是cmake后面跟的路径
制作库文件
制作静态库
- 使用
add_library函数即可
add_library(库名称 STATIC 源文件 ...)
- 注意
linux下的库名称lib + 库名称 + .a这里只用指定库名称,其他的自动生成 CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.25.0)
project(cacl)
include_directories(${PROJECT_SOURCE_DIR}/inc)
file(GLOB SRC ${CMAKE_CURRENT_SOURCE_DIR}/src/*.c)
add_library(mymath STATIC ${SRC})
制作动态库
- 还是一样的方式,利用
add_library函数
add_library(库名称 SHARED 源文件...)
- 注意
linux下动态库的库名:lib + 库名 + .so,这里只用指定库名称就可以了 - 具体编写的
CMakeLists.txt如下
cmake_minimum_required(VERSION 3.25.0)
project(cacl)
include_directories(${PROJECT_SOURCE_DIR}/inc)
file(GLOB SRC ${CMAKE_CURRENT_SOURCE_DIR}/src/*.c)
add_library(cacl SHARED ${SRC})
指定输出路径
- 由于动态库具有可执行权限,所以被当成可执行程序处理,可以利用
set设置EXECUTABLE_OUTPUT_PATH即可
- 好像没有用
CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.25.0)
project(cacl)
include_directories(${PROJECT_SOURCE_DIR}/inc)
file(GLOB SRC ${CMAKE_CURRENT_SOURCE_DIR}/src/*.c)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/lib)
add_library(cacl SHARED ${SRC})
- 设置
LIBRAYR_OUTPUT_PATH的值
cmake_minimum_required(VERSION 3.25.0)
project(cacl)
include_directories(${PROJECT_SOURCE_DIR}/inc)
file(GLOB SRC ${CMAKE_CURRENT_SOURCE_DIR}/src/*.c)
set(LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/lib)
add_library(cacl STATIC ${SRC})
包含库文件
- 此时使用的目录结构如下:
.
├── build
├── CMakeLists.txt
├── inc
│ └── head.h
├── lib
│ ├── libcacl.a
│ └── libcacl.so
├── out
└── src
└── app.c
链接静态库
- 使用
link_libraries命令,使用方式如下:
link_libraries(静态库名称1 静态库名称2 ...)
- 静态库名称可以时全名
lib + 库名 + .a,也可以就是库名 - 如果不是系统提供的库,而是第三方库的,还需要指定路径,使用
link_directories函数
link_directories(静态库路径名称)
- 使用静态库的
CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.25.0)
project(test)
file(GLOB SRC ${PROJECT_SOURCE_DIR}/src/*.c)
include_directories(${PROJECT_SOURCE_DIR}/inc)
link_directories(${PROJECT_SOURCE_DIR}/lib)
link_libraries(libcacl.a) # 或者指定库名就可以
set(EXECUTABLE_OUTPUT_PATH ${CMAKE_CURRENT_SOURCE_DIR}/out)
add_executable(app ${SRC})
链接动态库
- 链接动态库可以使用
target_link_libraries函数,函数的使用方法如下:
target_link_libraries(target_name [item1 [item2 [...]]]
[<debug|optimized|general> <lib1> [<lib2> [...]]])
target可以是源文件,可执行程序或者库文件PRIVATE|PUBLIC|INTERFACE表示动态库的访问权限- 如果动态库之间没有依赖关系,随便如何填写
- 链接具有传递性,类似于
maven的依赖传递原则,比如A链接BCD链接A,那么D也会链接B和C
- 三种访问权限的作用如下:
PUBLIC:在public后面的库会被Link到前面的target中,并且里面的符号也会被导出,提供给第三方使用。PRIVATE:在private后面的库仅被link到前面的target中,并且终结掉,第三方不能感知你调了啥库INTERFACE:在interface后面引入的库不会被链接到前面的target中,只会导出符号。
- 这里我的理解就是动态库也是一个可执行程序,所以可以链接到另外的可执行程序上面,相当于链式的链接
- 比如:
target_link_directories(app calc pthread)
- 相当于把
pthread连接到calc在把calc连接到app上 - 动态库和静态库之间的区别:
- 静态库会在生成可执行程序的链接阶段被打包到可执行程序中,所以可执行程序启动,静态库就被加载到内存中了。
- 动态库在生成可执行程序的链接阶段不会被打包到可执行程序中,当可执行程序被启动并且调用了动态库中的函数的时候,动态库才会被加载到内存
- 所以链接需要放在生成可执行程序之后
- 如果是调用第三方库,还需要指定库的路径,还是可以利用
link_directories函数指定库的路径 - 所以使用动态库的
CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.25.0)
project(test)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/out)
include_directories(${PROJECT_SOURCE_DIR}/inc)
file(GLOB SRC ${CMAKE_CURRENT_SOURCE_DIR}/src/*.c)
link_directories(${PROJECT_SOURCE_DIR}/lib)
add_executable(app ${SRC})
target_link_libraries(app cacl pthread)
- 注意
target_link_libraries和link_libraries的区别:- 后者用于全局链接库,之后生成的目标都会受到影响
- 前者用于对于目标链接库,控制更为精确
日志操作
- 可以使用
message控制CMake日志输出:
message([STATUS|WARNING|AUTHOR_WARNING|FATAL_ERROR|SEND_ERROR] "message to display" ...)
- 各种状态如下:
- (无) :重要消息
STATUS:非重要消息WARNING:CMake 警告, 会继续执行AUTHOR_WARNING:CMake 警告 (dev), 会继续执行SEND_ERROR:CMake 错误, 继续执行,但是会跳过生成的步骤FATAL_ERROR:CMake 错误, 终止所有处理过程
利用 set 进行变量的拼接
set(变量名1 ${变量名1} ${变量名2} ...)
利用 list 进行各种列表的操作
list([OPTIONS] <list> [<element> ...])
- 各种选项可以见: https://subingwen.cn/cmake/CMake-primer/#%E4%BD%BF%E7%94%A8set%E6%8B%BC%E6%8E%A5
宏定义
CMake中可以自定义宏定义,作用就是昨天说的,可以作为开关控制程序的运行,使用add_definitions函数即可
add_definitions(-D宏定义)
- 各种宏定义如下:
| 宏 | 功能 |
|---|---|
| PROJECT_SOURCE_DIR | 使用cmake命令后紧跟的目录,一般是工程的根目录 |
| PROJECT_BINARY_DIR | 执行cmake命令的目录 |
| CMAKE_CURRENT_SOURCE_DIR | 当前处理的CMakeLists.txt所在的路径 |
| CMAKE_CURRENT_BINARY_DIR | target 编译目录 |
| EXECUTABLE_OUTPUT_PATH | 重新定义目标二进制可执行文件的存放位置 |
| LIBRARY_OUTPUT_PATH | 重新定义目标链接库文件的存放位置 |
| PROJECT_NAME | 返回通过PROJECT指令定义的项目名称 |
| CMAKE_BINARY_DIR | 项目实际构建路径,假设在build目录进行的构建,那么得到的就是这个目录的路径 |
其他的高级操作
- 包含
CMakeLists.txt的嵌套(大型项目中使用到),以及循环控制语句的使用,可以参考: https://subingwen.cn/cmake/CMake-advanced/
文件 IO
open/close 函数
open 函数
open/close是系统函数/系统调用- 作用: 打开或者创建文件
- 头文件:
<fcntl.h>(存储这宏定义) - 头文件:
<unistd>(存储这open函数) - 函数原型:
int open(const char *pathname, int flags, ...
/* mode_t mode */ );
int open(const char *pathname, int flags, ...
mode_t mode );
- 参数如下:
pathname表示文件路径名称flag打开的状态:O_RDONLYO_WRONLYO_RDWRO_APPENDO_CREATEO_EXCL(是否存在)O_TRUNC(截断)O_NONBLOCK(没有阻塞)
mode表示执行权限(一般和umask相关,文件权限=mode&~umask)
- 返回值就是一种文件描述符
- 注意出现的三种错误:
#include<stdio.h>
#include<unistd.h> // 表示 unix 标准库文件 open
#include<fcntl.h> // 使用 宏定义 需要的头文件
#include<errno.h> // 表示 errno
int main()
{
int fd;
// 如果文件存在的打开并且只读,并且截断成 0
// 如果文件不存在创建文件,并且设置权限为 644
// 创建是的权限就是 mode & ~umask
fd = open("./file/dict.cp" , O_RDONLY | O_CREAT | O_TRUNC, 0644); // -rw-r--r--
// 错误1: 打开不存在的文件
int fd1 = open("./file/dict.cp11," , O_RDONLY);
// 错误2: 使用写的方式打开只读文件
int fd2 = open("./file/dict.cp" , O_WRONLY);
// 错误3: 使用只写的方式打开一个目录
int fd3 = open("./file" , O_WRONLY);
printf("fd1 = %d , errorno = %d \n" , fd1 , errno);
printf("fd2 = %d , errorno = %d \n",fd2, errno);
printf("fd3 = %d, errno = %d \n",fd3, errno);
printf("fd = %d \n" , fd);
close(fd);
return 0;
}
close函数
- 作用关闭文件
- 注意多使用
man查看系统函数man 2 函数名即可查看 - 函数原型:
int close(int fd);
fd表示文件描述符号- 返回值:
0成功 ,-1失败
read/write函数
read函数
- 作用: 读取文件
- 头文件:
<unistd.h> - 函数原型:
ssize_t read(int fd, void buf[.count], size_t count);
- 参数:
fd表示需要读取的文件描述符buf[.count]表示缓冲区count缓冲区的大小
- 返回值: 返回
0表示读取到了文件末尾,读取成功返回的就是读取到的字节数量,失败就会返回-1
write函数
- 向文件中写入数据
- 头文件:
<unistd> - 函数原型:
ssize_t write(int fd, const void buf[.count], size_t count);
- 参数:
fd表示文件描述符buf表示缓冲区count表示每一次最多写入的字节数量
- 返回值:
- 成功返回写入的字节数量
- 失败返回
-1
- 利用
read和write实现cp命令的过程如下:
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char* argv[])
{
char buf[1024]; // 注意缓冲区的创建
int fd1 = open(argv[1] , O_RDONLY); // 第一个文件
// printf("fd1 = %d \n" , fd1);
// 这里阶段表示阶段文件,之后进行写入的操作
int fd2 = open(argv[2] , O_RDWR | O_CREAT | O_TRUNC , 0644); // 第二个文件
int n = 0;
while((n = read(fd1 , buf , 1024)) != 0){
// printf("n = %d \n",n);
write(fd2 , buf , n); // 表示读取多少写多少
}
close(fd1);
close(fd2);
}
- 可以使用
void perror(const char* error)用于打印错误信息
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char* argv[])
{
char buf[1024]; // 注意缓冲区的创建
int fd1 = open(argv[1] , O_RDONLY); // 第一个文件
// printf("fd1 = %d \n" , fd1);
if(fd1 == -1)
{
perror("open argv[1] error!"); // 表示打印错误信息
exit(1); // 表示退出
}
// 这里阶段表示阶段文件,之后进行写入的操作
int fd2 = open(argv[2] , O_RDWR | O_CREAT | O_TRUNC , 0644); // 第二个文件
if(fd2 == -1)
{
perror("opee argv[2] error!");
exit(1);
}
int n = 0;
while((n = read(fd1 , buf , 1024)) != 0){
// printf("n = %d \n",n);
if(n == -1)
{
perror("read argv[1] fail!");
exit(1); // 表示异常退出
}
write(fd2 , buf , n); // 表示读取多少写多少
}
close(fd1);
close(fd2);
}
系统调用和库函数比较
- 库函数都是通过调用系统调用函数来控制驱动完成功能的
- 库函数
fputc和write函数的调用关系如下:
- 但是
fputc的速度比write更加快,这是为什么? - 可以使用
strace 可执行程序名称查看可执行程序调用的时候进行的系统调用 - 注意
fputc的底层调用write的时候,每一次设置缓冲区的大小就是4096字节 - 从用户空间切换到内核空间使用的时间比较大
fputc内部有一个缓冲区,缓冲区的大小就是4096字节,当缓冲区的大小为4096的时候,才会完成用户到内核的切换,把数据写入到内核的缓冲区- 预读入缓输出机制如下:

- 所以有时候可以使用库函数的地方,还是需要优先使用库函数(库函数积累了多年,所以可能性能比较好)
- 有时候可以根据特殊的场景确定特殊的需求
文件描述符
PCB进程控制块(进程描述符号),本质就是一个结构体,结构体中有一个成员叫做文件描述符表- 文件描述符其实本质就是键值对映射,可以看成一个文件结构体指针,相当于打开文件描述信息,
open函数返回的文件描述符号其实就是文件描述符表的下标,之后系统通过下标就可以找到file结构体,操作系统隐藏了底层细节 - 文件描述符号:
stdin==0STDIN_FILENOstdout==1STDOUT_FILENOstderr==2STDERR_FILENO
- 之后打开文件就会随着这下标递增,如果把
0关了,那么下一次开启得到的文件描述符号就是0 - 一个进程最大可以打开的文件就是
1024(0-1023) PCB进程控制块 包含 文件描述符号表 包含文件描述符号为索引,文件指针为内容的键值对
阻塞和非阻塞
- 读常规文件是不会发生阻塞的
- 产生阻塞时间场景:
- 读取设备文件
- 读取网络文件
/dev/tty对应着终端文件- 如下,读取设备文件的时候,就会发生阻塞
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
int main()
{
char buf[10];
int n;
n = read(STDIN_FILENO,buf,10);
if(n == -1)
{
perror("读取失败");
exit(1);
}
write(STDOUT_FILENO , buf ,n);
return 0;
}
- 注意阻塞就是文件的属性,设备文件默认的属性就是阻塞
- 可以利用
open函数,把文件的属性设置为O_NOBLOCK状态 - 对于非阻塞文件,如果文件中没有数据,就会返回
-1(读取失败),但是此时errno会被设置为EWOULDBLOCK - 注意 如果
read返回-1并且errno为EAGIN或者EWOULDBLOCK不是说明read失败,而是read在使用非阻塞的方式读取一个设备文件(网络文件),并且文件没有数据 - 所以处理这一种阻塞的方式,可以设置一个超时时间,当超时时间过了的情况下就会相应失败,但是这一种方式仍然不是最优的,最好是可以自己报告阻塞状态,这个就和之后要学习的
poll和epoll有关
fcntl函数
- 作用: 改变一个已经打开的文件的访问控制权限
- 头文件:
<fcntl.h> - 函数原型:
int fcntl(int fd, int op, ... /* arg */ );
- 参数:
fd: 文件描述符op: 表示可选选项,比如:F_GETFL表示获取文件状态F_SETFL表示设置文件状态
- 返回值:
- 其实返回值就是一个位图,位图是一个整形类型,比如
int占用4个字节,包含32个比特位,每一个比特位就可以表示一种文件描述符的状态,所以可以对于得到的flags(位图)进行位置运算就可以加上新的权限
- 其实返回值就是一个位图,位图是一个整形类型,比如
- 一个
demo如下:
int flag = fcntl(STDIN_FILENO,F_GETFL);
flag |= O_NONBLOCK; // 表示加上这一个属性
fcntl(STDIN_FILENO,F_SETFL,flag);
- 可以使用
~进行文件属性的减少等操作
lseek函数
- 作用:控制文件指针的位置
- 函数原型如下:
off_t lseek(int fd, off_t offset, int whence);
- 参数:
fd表示文件描述符号offset表示偏移量whence表示开始位置:SEEK_SET开始位置SEEK_CUR当前位置SEEK_END结尾位置
- 返回值:
- 成功返回相对于文件头部的偏移量
- 否则返回
-1
lseek允许超过文件末尾位置,同时文件的读写使用同样一个偏移位置- 使用
demo如下:
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<fcntl.h>
#include<cstdlib> // 注意包含标准 C 库
int main()
{
int fd1 = open("./file/dict.txt" , O_TRUNC | O_RDWR);
if(fd1 == -1){
perror("can not open file!");
exit(1);
}
// 开始写入数据
char* msg = "hello world\n";
char ch;
int n = write(fd1,msg,strlen(msg));
//设置偏移
lseek(fd1,0,SEEK_SET);
if(n == -1){
perror("write into file error!");
exit(1);
}
// 开始读取文件
int res = 0;
while((res = read(fd1,&ch,1)) != 0)
{
if(res == -1)
{
perror("read from file error!");
exit(1);
}
// 写入到标准输出中
int n1 = write(STDOUT_FILENO,&ch,1);
if(n1 == -1)
{
perror("write into stdout fail!");
exit(1);
}
}
}
- 应用场景:
- 文件的读写使用同一个偏移位置
- 使用
lseek获取,拓展文件大小位置(wherence设置为SEEK_END,offset设置为0) - 可以用于拓展文件大小(超出偏移量): 但是注意一定需要有
IO操作
- 使用情况:
#include<stdio.h>
#include<cstdlib>
#include<string.h>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char* argv[])
{
int fd = open(argv[1] , O_RDWR);
if(fd == -1)
{
perror("open file error !");
exit(1);
}
int len = lseek(fd,0,SEEK_END);
printf("文件大小为: %d\n" , len);
// 拓展文件大小
lseek(fd , 100 , SEEK_END);
write(fd , "/0" , 1);
close(fd);
}
- 命令:
od -tcx filename查看文件十六进制格式od -tcd filename查看文件十进制格式
- 利用
truncate也可以拓展文件大小
传入参数和传出参数
- 传入参数(用于读取):
- 指针作为函数参数
- 通常有
const关键字修饰 - 指针执行有效区域,在函数内部作读操作,在函数内部作读操作
- 传出参数(用于写入):
- 指针作为函数参数
- 在函数调用之前,指针指向的空间可以没有意义,但是必须有效
- 在函数内部,可以作读写操作
- 函数调用结束之后,充当函数返回值
- 传入传出参数(用于独处写入):
- 指针作为函数操作
- 在函数调用之前,指针指向的空间有实际意义
- 在函数内部,先做读操作,之后做写操作
- 函数调用结束之后,可以充当函数返回值
- 典型函数就是
strtok(char* str , const char*delim char ** saveptr)
文件系统
文件存储
Inode
- 可以根据
stat 文件名命令来查看文件的相关信息,文件属性中包含一个inode inode本质就是一个结构体,里面包含存储文件的属性信息(权限,大小,类型,时间,用户,盘符位置...),大多数的inode存储在磁盘中,少数的inode存储在内存中- 文件名单独存储和
inode值存储在dentry中 dentry中存储着文件名和inode值,inode值指向了inode结构体,inode结构体中存储着文件在磁盘中的地址,可以通过地址取得文件的内容- 注意当创建硬链接的时候,其实只是创建了新的
dentry,并且dentry中存储的文件名不同,但是inode相同 - 总结:
- 文件存储的方式: 创建一个
dentry结构体(存储着inode和文件名),inode指向一个结构体存储着文件的各种属性(包含文件位置),通过这一个结构体就可以找到文件的位置,取出文件的内容
- 文件存储的方式: 创建一个
stat函数
- 作用: 获取文件内容
- 函数原型:
int stat(const char *restrict pathname,
struct stat *restrict statbuf);
- 参数:
pathname文件路径名称statbuf一个传入参数,调用函数之后就有意义了,里面的成员存储这文件的各种内容(比如访问权限,所有者等信息)
- 返回值:
0表示成功1表示失败,可以通过errorno确定错误类型
- 演示
demo如下,还可以使用相应的函数判断文件类型: - 但是如下
demo中,如果使用软链接作为参数的时候,那么就会发生stat穿透 - 获取文件大小:
- 文件大小:
st_size - 获取文件类型和权限:
st_mode
- 文件大小:
#include<stdio.h>
#include<cstdlib>
#include<unistd.h>
#include<fcntl.h>
#include<sys/stat.h>
int main()
{
struct stat* res = (struct stat*) malloc (sizeof(struct stat));
int status = stat("./file/dict.txt" , res);
if(status == -1)
{
perror("get file status failed!");
exit(1);
}
printf("file-size = %d \n" , res->st_size);
printf("file-mode = %d \n" , res -> st_mode);
mode_t mode = res -> st_mode;
switch (mode & S_IFMT) {
case S_IFBLK: printf("block device\n"); break; // 块文件
case S_IFCHR: printf("character device\n"); break; // 字符文件
case S_IFDIR: printf("directory\n"); break; // 目录
case S_IFIFO: printf("FIFO/pipe\n"); break; // FIFO
case S_IFLNK: printf("symlink\n"); break; // 软链接
case S_IFREG: printf("regular file\n"); break; // 普通文件
case S_IFSOCK: printf("socket\n"); break; // socket
default: printf("unknown?\n"); break; // UNKNOWN
}
// 注意还可以使用函数
if(S_ISREG(mode))
{
printf("普通文件!!!\n");
}
return 0;
}
- 注意以上的
demo中,每一个宏定义的内容如下: - 注意第一个
S_IFMT就是一个掩码类型 - 同时也可以使用宏函数判断文件类型(
S_IFDIR(mode_t mode))
#define __S_IFMT 0170000 /* These bits determine file type. */
/* File types. */
#define __S_IFDIR 0040000 /* Directory. */
#define __S_IFCHR 0020000 /* Character device. */
#define __S_IFBLK 0060000 /* Block device. */
#define __S_IFREG 0100000 /* Regular file. */
#define __S_IFIFO 0010000 /* FIFO. */
#define __S_IFLNK 0120000 /* Symbolic link. */
#define __S_IFSOCK 0140000 /* Socket. */
lstat函数
stat会穿透符号连接但是lstat不会(符号连接就是当传入参数为软链接的时候,就会导致其实判断的就是他执行的文件)- 函数原型:
int lstat(const char *restrict pathname,
struct stat *restrict statbuf);
- 返回值和参数和
stat一样 - 传出参数
statbuf相当于传递进入一个地址,把函数的结构带回来,所以函数调用之前不一定需要有意义,还可以使用引用传递
link函数和UNlink隐式回收
link函数
- 可以用于创建硬链接
- 函数原型如下:
int link(const char *oldpath, const char *newpath);
unlink函数
- 作用: 可以用于删除文件(删除硬链接,使得硬链接参数减少)
- 函数原型:
int unlink(const char *pathname);
unlink函数的特征: 清除文件的时候,如果文件硬链接数量减少到0,没有dentry对应,但是该文件不会立刻被释放,需要等到所有打开该文件的进程关闭该文件,系统才会条时间把该文件释放(只是让该文件具有了可以释放的条件)- 使用
link和unlink完成文件的移动操作:
#include<stdio.h>
#include<cstdlib>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char** argv)
{
// 模拟 mv 命令
int ret1 = link(argv[1] , argv[2]);
if(ret1 == -1)
{
perror("create new file failed !");
exit(1);
}
int ret2 = unlink(argv[1]);
if(ret2 == -1)
{
perror("delete source file failed!");
exit(1);
}
return 0;
}
- 隐式回收:
- 当进程结束运行的时候,所有该进程打开的文件爱你会被关闭,申请的内存空间会被释放,系统这一个特性被成为隐式回收资源
- 演示
demo,可以写入文件成功:
#include<stdio.h>
#include<cstdlib>
#include<unistd.h>
#include<fcntl.h>
#include<cstring>
int main()
{
int fd,ret;
char* p1 = "hello temp!\n";
char* p2 = "error happended!\n";
fd = open("temp.txt" , O_CREAT | O_RDWR , 0644);
if(fd == -1)
{
perror("open file failed!");
exit(1);
}
// 直接 Unlink文件
ret = unlink("temp.txt");
if(ret == -1)
{
perror("unlink file failed!\n");
exit(1);
}
// 写入文件
ret = write(fd , p1 , strlen(p1));
if(ret == -1)
{
perror("write into file failed 1 !!! \n");
exit(1);
}
ret = write(fd , p2 , strlen(p2));
if(ret == -1)
{
perror("write into file failed2 !!! \n");
exit(1);
}
p1[3] = 'c';
// 关闭文件
close(fd);
}
文件目录rwx权限差异
- 可以使用
readlink命令查看文件本身 rename函数用于重命名getcwd函数拥有查看当前工作目录chdir函数用于改变当前进程的工作目录
文件目录的权限
linux中一切都是文件,所以目录也是一个文件- 使用
vim 目录名就可以看到文件列表 - 目录和文件的
rwx权限:
| 类型 | r | w | x |
|---|---|---|---|
| 文件 | 文件的内容可以被查看,cat,less,more | 内容可以被修改,vi,> | 可以运行产生一个进程 ./文件名 |
| 目录 | 目录可以被浏览ls,tree | 创建,修改删除文件 | cd |
目录操作函数
opendir函数
-
作用: 打开目录,库函数
-
头文件:
#include <sys/types.h>#include <dirent.h>
-
函数原型:
DIR *opendir(const char *name);
readir函数
- 作用读取目录,可以获取到文件名称
- 头文件:
#include <dirent.h>
- 函数原型:
struct dirent *readdir(DIR *dirp);
- 返回值:
- 是一个结构体,可以用于获取其中文件的名称
struct dirent {
ino_t d_ino; /* Inode number */
off_t d_off; /* Not an offset; see below */
unsigned short d_reclen; /* Length of this record */
unsigned char d_type; /* Type of file; not supported
by all filesystem types */
char d_name[256]; /* Null-terminated filename */
};
- 利用
opendir和readdir模拟ls命令:
#include<stdio.h>
#include<cstdlib>
#include<cstring>
#include<dirent.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char** argv)
{
// 1. 打开文件
DIR* dir = opendir(argv[1]);
if(dir == NULL)
{
printf("open dir failed !!!\n");
exit(1);
}
// 2. 读取文件内容
dirent* sdp; // 表示文件内容
while((sdp = readdir(dir)) != NULL)
{
if((sdp -> d_name)[0] == '.')
{
continue;
}
printf("%s \t" , sdp -> d_name);
}
printf("\n");
}
案例: 递归遍历文件
- 要求: 递归遍历文件并且显示文件大小
- 思路:
- 首先进行判断:
- 如果是文件之间打印大小和名称
- 如果是目录,进行递归遍历
- 首先进行判断:
- 注意使用
strcmp进行比较,利用strcat进行拼接 demo:
#include<stdio.h>
#include<cstdlib>
#include<cstring>
#include<sys/types.h>
#include<dirent.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/stat.h>
void travel_dir(const char* pathname)
{
// 首先获取状态
struct stat* status = (struct stat*) malloc (sizeof(struct stat));
int res = stat(pathname , status);
// printf("%d\n",res);
if(res == -1)
{
perror("get the status of file failed !!!\n");
exit(1);
}
if(!S_ISDIR(status -> st_mode))
{
// 不是文件显示大小
printf("%-20s\t%lu \n" , basename(pathname) , status -> st_size);
free(status);
return ;
}
DIR* dir;
dirent* dirent;
dir = opendir(pathname);
if(dir == NULL)
{
perror("open file failed!!!");
exit(1);
}
// 开始遍历
while((dirent = readdir(dir)) != NULL){
// 开始遍历
printf("%s \n" , dirent -> d_name);
if((dirent -> d_name)[0] == '.'){
continue;
}
// 注意拼接
// pathname + / + dirent -> d_name
char buf[1024];
sprintf(buf,"%s/%s",pathname,dirent -> d_name);
travel_dir(buf);
}
closedir(dir);
}
int main(int argc , char** argv)
{
// printf(argv[1]);
// printf("\n");
if(argc == 1)
{
travel_dir(".");
return 0;
}
travel_dir(argv[1]);
}
char* 和 const char* 和 char[] 的区别
char*表示一个字符指针,可以表示字符串,它可以指向任何区域(包含常量区,栈区,堆区等),利用常量字符串初始化的char*指向常量区,它指向的内容不可以修改,但是指针的指向仍然可以改变const char*表示指针指向的内容不可以修改char[]表示一个字符数组,其中的内容可以修改,但是指针的指向不可以修改char* const表示指针常量不可以修改
#include<stdio.h>
#include<cstring>
int main()
{
char* pstr1 = "hello";
// pstr1[1] = 'X' error
pstr1 = "world";
printf("%s \n" , pstr1);
// 最好写成如下形式
const char* pstr2 = "hello";
// pstr2[1] = 'X' error
pstr2 = "fajlsdfajdslf";
printf("%s \n" , pstr2); // true
char* const pstr3 = "good";
// pstr3 = "hello"; // error
}
- 可以通过传递函数地址的方式来调用函数,当然
C++中是使用std::function<return_value(...)>
重定向
dup和dup2函数
dup函数
- 作用: 重定向(相当于把输入流中的内容重定向到文件中)
- 函数原型:
int dup(int oldfd);
- 参数:
oldfd: 旧的文件描述符号
- 返回值:
- 新的文件描述符号
demo如下:
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char* argv[])
{
int fd = open(argv[1] , O_RDONLY);
printf("fd = %d \n" , fd);
int new_fd = dup(fd);
// 作用就是起到一个保存的作用
printf("new_id = %d \n" , new_fd);
}
dup2函数
- 作用改变文件描述符号
- 函数原型:
int dup2(int oldfd, int newfd);
- 参数:
oldfd表示旧的文件描述符newfd表示新的文件描述符
- 作用就是可以在文件描述符表中的
oldfd的位置拷贝给newfd那么就会导致newfd和oldfd执行同一个文件位置 dup2会返回新的文件描述符号,并且会让新的文件描述符号和旧的文件描述符号执行同一个文件位置- 注意执行关系
#include<stdio.h>
#include<cstdlib>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char** argv)
{
int fd1 = open(argv[1] , O_RDWR);
int fd2 = open(argv[2] , O_RDWR);
int fd_ret = dup2(fd1 , fd2);
printf("fd_ret = %d \n" , fd_ret);
// 开始进行写操作
int ret = write(fd2 , "123456" , 7);
// 这就成为了重定向文件
if(ret == -1)
{
printf("write into file failed...\n");
}
dup2(fd1,STDOUT_FILENO); // 表示重定向
// 表示把标准输出拷贝给文件
printf("看到了没有\n");
return 0;
}
利用 fcntl 函数完成 dup2的功能
- 使用方式:
int fcntl(目标文件描述符号 , F_DUPFD , 新的文件描述符)
- 第三个参数:
- 被占用的,返回最小可用的
- 没有被占用的,返回
=该值文件描述符号
demo:
#include<stdio.h>
#include<cstdlib>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char** argv)
{
int fd = open(argv[1] , O_RDWR);
printf("fd = %d \n" , fd);
int new_fd = fcntl(fd , F_DUPFD , 0); // 0 被占用,fcntl使用文件描述符表中最小的文件描述符号返回
printf("new_fd = %d \n" , new_fd);
int new_fd2 = fcntl(fd , F_DUPFD , 7); // 指定 7 的时候没有被占用,就会返回一个 >= 7 的文件描述符号
printf("new_fd2 = %d \n" , new_fd2);
write(new_fd2 , "abc" , 3); // 文件描述符号在头部
}
进程
进程和程序以及CPU相关
- 进程与程序:
- 程序: 死的,只会占用磁盘空间(相当于剧本)
- 进程: 活的,运行起来的程序,占用内存,
cpu等系统资源(相当于戏剧)
- 同一个程序可以加载成不同的进程
- 并发与并行:
- 并发:
- 在操作系统中,一个时间段中有多个进程都处于已经启动运行到运行完毕之间的状态,但是任意一个时间节点都只有一个程序在执行(单
CPU同时执行多个任务)
- 在操作系统中,一个时间段中有多个进程都处于已经启动运行到运行完毕之间的状态,但是任意一个时间节点都只有一个程序在执行(单
- 并行:
- 表示多
CPU同时执行多个任务
- 表示多
- 并发:
- 通过时钟中断来控制进程的调度
CPU的工作机制:- 注意一个寄存器的大小就是
4096B也就是4K CPU与MMU(虚拟内存映射单元)
虚拟内存和物理内存的映射关系
- 注意程序不占用资源(只会占用磁盘空间)
CPU一般会被内存分级,把用户空间映射到3级,把内核空间映射成0级,所以从用户空间到内存空间的映射时间消耗比较长- 虚拟内存映射如图:
MMU的大小为4KB
PCB进程控制块
PCB进程控制块是一个结构体,存储在/usr/src/linux-headers-6.8.0-40/include/linux /sched.h中struct task_struct- 重点成员如下:
- 进程
id - 进程的状态,就绪,运行,挂起(表示暂时停止(比如执行了
sleep函数)),停止 - 进程切换时需要保存和恢复的一些
CPU寄存器 - 描述虚拟地址空间的信息
- 占用终端的信息
- 当前的工作目录
umask掩码- 文件描述描述符号表
- 和信号相关的信息(信号屏蔽字和未决信号集)
- 用户
id和组id - 会话(
Session)和进程组 - 进程可以使用的资源上限(
Resource limit)
- 进程
环境变量
LD_LIBRARY_LIB动态链接器的寻找目录PATH可执行程序的路径SHELL查看当前使用的shell解析器TERM查看当前使用的终端HOME表示家目录env查看所有环境变量(环境变量存放在用户空间和内核空间之间,这里还存放着main函数的参数)
进程控制
fork函数原理
- 作用: 创建一个子进程
- 函数原型:
pid_t fork(void);
- 返回值:
- 如果成功的话,在父进程中返回子进程的
PID,并且在子进程中返回0(表示子进程创建成功) - 如果创建失败就会返回
-1
- 如果成功的话,在父进程中返回子进程的
fork相当于赋值,fork之后,子进程和父进程基本一样
fork的演示demo如下:
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
printf("before fork1 ...\n");
printf("before fork2 ...\n");
printf("before fork3 ...\n");
printf("before fork4 ...\n");
pid_t pid = fork();
if(pid == -1)
{
perror("fork error!!!\n");
exit(1);
} else if(pid == 0) {
printf("child is created ... \n");
} else if (pid > 0){
printf("my child pid is %d \n" , pid);
}
printf("after fork1 ... \n");
printf("after fork2 ... \n");
printf("after fork3 ... \n");
printf("after fork4 ... \n");
}
- 执行结果如下:
before fork1 ...
before fork2 ...
before fork3 ...
before fork4 ...
my child pid is 16048
after fork1 ...
after fork2 ...
after fork3 ...
after fork4 ...
child is created ...
after fork1 ...
after fork2 ...
after fork3 ...
after fork4 ...
- 可见,子进程的代码和父进程一致,但是
fork之前的代码没有机会执行,fork之后的代码有机会执行,所以就会执行两次后面的操作,并且子进程和父进程的的执行相互独立
getpid 和 getppid
getpid用于获取当前进程自己的pidgetppid用于获取当前进程的父进程的pid- 演示
demo:
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
printf("before fork1 ...\n");
pid_t pid = fork();
if(pid == -1)
{
perror("fork error!!!\n");
exit(1);
} else if(pid == 0) {
printf("child is created ... \n");
printf("I am the child , my pid is %d \n" , getpid());
printf("my father's pid is %d \n" , getppid());
} else if (pid > 0){
printf("my child pid is %d \n" , pid);
printf("I am the father , my pid is %d \n" , getpid());
printf("and my father's pid is %d \n" , getppid());
}
printf("after fork1 ... \n");
}
- 父进程的父进程就是
bash
循环创建子进程
- 如果利用如下代码循环创建多个子进程:
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
// 循环创建 n 个子进程
for(int i = 0 ; i < 3 ; i ++){
int pid = fork();
if(pid == 0){
// 表示子进程
printf("我是第 %d 个子进程,我的pid为: %d \n", i + 1 , getpid());
}
}
}
- 但是最后结果创建了
7个子进程,这是由于fork之后,之后的循环代码,子进程仍然会继续调用余下的代码,调用图如下:
- 可以让父进程执行外之后退出,并且不再创建子进程了,所以演示代码如下:
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
// 循环创建 n 个子进程
for(int i = 0 ; i < 5 ; i ++){
int pid = fork();
if(pid == 0){
// 表示子进程
printf("我是第 %d 个子进程,我的pid为: %d \n", i + 1 , getpid());
break; // 注意需要退出,此时子进程就需要退出
}
}
}
- 但是可能出现如下问题:
我是第 2 个子进程,我的pid为: 38367
我是第 1 个子进程,我的pid为: 38366
我是第 3 个子进程,我的pid为: 38368
我是第 5 个子进程,我的pid为: 38370
我是第 4 个子进程,我的pid为: 38369
- 这是由于虽然每一个子进程被
fork出来的顺序是按照顺序的,但是他们都会抢占CPU的执行权,所以首先抢占到CPU执行的进程就会执行打印的代码 - 也可以使用
sleep函数完成礼让的作用:
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
int i = 0;
// 循环创建 n 个子进程
for(i = 0 ; i < 5 ; i ++){
if(fork() == 0){
break;
}
}
if(i == 5){
sleep(5);
printf("I am the parent!!! \n");
} else {
sleep(i);
printf("I am the %d th child \n",i + 1);
}
}
进程共享
- 刚刚
fork之后,父子进程的资源如下:- 父子进程相同之处: 全局变量,
data,.text(代码段),栈,堆区,环境变量,用户ID,宿主目录,进程工作目录,信号处理方式都相同 - 父子进程不同之处: 进程
IDfork返回值 父进程ID进程运行时间 闹钟(定时器) 未决信号集
- 父子进程相同之处: 全局变量,
- 但是并不是子进程完全赋值父进程的用户空间,父子进程之间遵循着读时共享,写时复制的原则,这样设计,无论子进程和父进程执行各种操作都可以节约空间
- 测试
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int var = 100; // 全局变量
int main()
{
int pid = fork();
if(pid == -1){
perror("fork failed!\n");
} else if(pid == 0){
var = 200;
printf("I am child , my pid is %d , my father's pid is %d , var is %d \n" , getpid() , getppid() , var);
} else if(pid > 0){
var = 300;
printf("I am the father , my pid is % d , var is %d \n" , getpid() , var);
}
}
父子进程共享
- 父子进程共享:
- 文件描述符
mmap映射区域
- 共享遵循读时共享,写时复制(所以并不是完全共享全局变量)
- 但是父子进程的执行时机依赖于父进程的调度算法
父子进程 gdb 调试
- 主要是两个命令:
set follow-fork-mode child命令设置gdb在fork之后跟踪子进程set follow-fork-mode parent设置跟踪父进程
- 注意一定需要在
fork函数之前执行
exec 函数族
- 作用: 让子进程和父进程执行程序
exec函数族中的函数如下:
int execl(const char *pathname, const char *arg, ...
/*, (char *) NULL */);
int execlp(const char *file, const char *arg, ...
/*, (char *) NULL */);
int execle(const char *pathname, const char *arg, ...
/*, (char *) NULL, char *const envp[] */);
int execv(const char *pathname, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);
exec函数族执行的过程:- 当父进程在
fork之后调用了exec函数,那么子进程在调用到exec函数之后,就不会在接着执行接下来的代码了,而是执行exec指定的任务
- 当父进程在
- 但是执行任务的子进程还没有改变

execl 和 execlp 函数
execlp函数
- 作用: 加载一个进程,借助
PATH环境变量 - 函数原型:
int execlp(const char *file, const char *arg, ...
/*, (char *) NULL */);
- 该函数一般用于调用系统函数,比如
lsdatecpcat等命令 - 参数:
file可执行程序文件名称arg表示选项
- 注意最后一定需要加上一个
NULL作为一个哨兵,表示结束 - 但是注意参数从
arg0开始计算,并且arg0就是命令名称本身 - 一个小的细节(
ls -lh) 表示显示单位并且使用长列表的方式显示文件列表 - 调用
execlp方法执行系统的函数方式如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>
int main()
{
// 子进程使用 exelp 调用系统函数
int pid = fork();
if(pid == -1){
perror("fork child failed !!! \n");
} else if (pid == 0) {
printf("this is child \n");
// execlp("ls" , "ls" , "-l" , "-h" , NULL);
execlp("date" , "date" , NULL);
printf("child finished !!! \n");
} else {
sleep(1);
printf("I am the parent !!! \n");
}
}
execl 函数
- 作用: 可以执行第三方的程序,比如自己写的程序,之后的参数基本和
execlp一致 - 设置知道系统函数的路径之后,可以调用系统函数
- 演示
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>
int main()
{
int pid = fork();
if(pid == -1){
perror("fork failed!!!");
exit(1);
} else if (pid == 0){
printf("I am the child !!! \n");
// execl("./create_loop_fork" , "./create_loop_fork",NULL);
// 执行系统的命令
execl("/usr/bin/ls" , "ls" , "-l" , "-h" , NULL);
printf("child finshed !!! \n"); // 没有了
} else {
sleep(1);
printf("I am the father !!! \n");
}
}
- 一个小的案例: 把
ps的内容输入到文件中,注意利用dup2进行重定向输出
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
// 利用 ps 命令把进程信息写入到文件中
int pid = fork();
if(pid == -1){
perror("fork failed !!!");
exit(1);
} else if (pid == 0){
// 1. 首先创建文件
int fd = open("./out" , O_CREAT | O_RDWR | O_TRUNC , 0644);
// 2. 重定向
int new_fd = dup2(fd , STDOUT_FILENO); // 表示把标准输出重定向到 fd 中
// 3. 调用 ps 命令
execlp("ps" , "ps" , "aux",NULL);
} else {
sleep(1);
printf("I am the father !!! \n");
}
}
其他函数
execvp函数: 作用基本和execl基本一样,唯一的不同就是第二个参数是一个数组不是可变参数exec函数族的特点:- 只有错误才会返回
-1
- 只有错误才会返回
- 所以一般就在
exec后面调用perror函数和exit函数 exec函数各种后缀的含义:l(list): 命令行参数列表p(path): 搜索变量的时候使用path变量v(vector): 使用命令行参数数组e(environment): 使用环境变量数组,不使用进程原有的环境变量,设置新加载程序运行时的环境变量
- 六种函数之间的关系,注意只有
exece是系统调用,其他的都是封装了exece:
回收子进程
孤儿进程
- 孤儿进程: 父进程先于子进程结束,则子进程成为孤儿进程,子进程的父进程成为
init进程,成为init进程领养孤儿进程(相当于进程孤儿院) ps ajx用于查看子进程的父进程- 代码演示如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>
int main()
{
// 演示孤儿进程
int pid = fork();
if(pid == -1){
perror("fork failed !!! \n");
exit(1);
} else if(pid == 0){
while(1){
printf("I am the child , my pid is %d , ppid is %d \n" , getpid() , getppid());
sleep(1);
}
} else if(pid > 0){
printf("I am the father , my pid is %d \n" , getpid());
sleep(5);
}
}
僵尸进程
- 僵尸进程: 进程停止,父进程尚未回收,子进程残留资源(
PCB)存放在内核中,变成僵尸进程(Zombie)进程,理论上来说,基本所有进程都会经历僵尸进程的状态,其实回收的就是PCB,其中会记录子进程结束的原因 - 处理僵尸进程的方式: 将它的父进程杀死,让子进程变成孤儿进程从而被回收
- 代码演示如下:
#include<stdio.h>
#include<stdlib.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{
int pid = fork();
if(pid == -1){
perror("fork failed !!! \n");
exit(1);
} else if (pid == 0){
printf("I am the child , my pid is %d , my ppid is %d \n" , getpid() ,getppid());
sleep(5);
} else if(pid > 0){
while(1){
printf("I am the father , my pid is %d , my son's pid is %d \n" , getpid() , pid);
sleep(1);
}
}
}
wait 函数
- 作用: 用于回收子进程
- 原理: 可以根据子进程残留的
PCB进程块获取到子进程的信息,从而回收子进程 - 父进程调用
wait函数可以回收子进程终止信息,该函数有三个状态:- 阻塞等待子进程退出
- 回收子进程残留资源
- 获取子进程结束状态(退出原因)
- 头文件:
<sys/wait.h> - 函数原型:
pid_t wait(int *_Nullable wstatus);
pid_t waitpid(pid_t pid, int *_Nullable wstatus, int options);
int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);
/* This is the glibc and POSIX interface; see
NOTES for information on the raw system call. */
- 参数:
status表示子进程的状态,可以传入一个整形参数的地址用于接受即可(并且可以利用宏函数来判断子进程退出原因)
- 返回值: 回收失败就会返回
-1 - 演示
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/wait.h>
int main()
{
int pid = fork();
int status;
int wpid;
if(pid == -1){
perror("fork failed !!! \n");
exit(1);
} else if(pid == 0) {
printf("I am the child , my pid is %d , my parent's pid is %d \n",getpid(),getppid());
sleep(5);
} else if(pid > 0){
wpid = wait(&status);
if(wpid == -1){
perror("failed to resouce the child !!! \n");
exit(1);
}
printf("wid = %d \n" , wpid);
printf("successfully resouce the child !!! \n");
}
}
获取子进程退出值和异常终止信号
- 一般来说都是由于信号才会时的进程终止,比如
kill -l可以查看所有信号量 - 利用各种宏定义函数可以判断子进程突出原因:
WIFEXITED返回true表示子进程正常退出,如果使用exit函数默认返回1WEXITSTATUS上面一个返回true的情况下,返回子进程退出的返回值(return)WIFSIGNALED如果子进程被信号终止,就会返回trueWTERMSIG返回子进程被终止的信号WIFSTOPPED判断进程是否暂停WSTOPIG获取暂停子进程的信号WIFCOUNTINE获取让子进程继续执行的信号
- 演示
demo:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/wait.h>
int main()
{
int pid = fork();
int status;
int wpid;
if(pid == -1){
perror("fork failed !!! \n");
exit(3); // 如果调用 exit函数默认返回 1
} else if(pid == 0) {
printf("I am the child , my pid is %d , my parent's pid is %d \n",getpid(),getppid());
sleep(20);
exit(10);
} else if(pid > 0){
wpid = wait(&status); // 如果子进程没有终止,父进程就会阻塞
if(wpid == -1){
perror("failed to resouce the child !!! \n");
exit(1);
}
if(WIFEXITED(status)){ // 正常退出
int res = WEXITSTATUS(status); // 获取退出状态
printf("child return the number: %d \n" , res);
}
if(WIFSIGNALED(status)) { // 表示异常终止,说明子进程被信号终止
// 查看信号
printf("child killed with signale: %d \n" , WTERMSIG(status));
}
printf("wid = %d \n" , wpid);
printf("successfully resouce the child !!! \n");
}
}
waitpid函数
- 作用: 回收子进程
- 头文件:
<sys/wait.h>
- 函数原型:
pid_t waitpid(pid_t pid, int *_Nullable wstatus, int options);
- 参数:
pid需要回收子进程的pid:>0指定ID的子进程-1回收任意子进程(相当于wait)0回收和当前调用waitpid一个组的所有子进程<-1回收指定进程组里面的任意子进程(组号等于绝对值)
wstatus记录子进程的状态options可以设置函数的属性,比如可以设置函数的属性为非阻塞的形式
- 返回值:
- 成功回收返回子进程
id - 函数调用的时候,指定了
WNOHANG,并且没有子进程结束 - 失败返回
-1和errorno
- 成功回收返回子进程
- 细节: 无论是
wait还是waitpid调用,只是可以回收一个子进程 - 演示
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/wait.h>
int main()
{
int pid,wait_pid;
int target;
int i ;
for(i = 0 ; i < 5 ; i ++){
pid = fork();
if(i == 2 && pid > 0){
target = pid;
}
if(pid == 0){
printf("I am the child , my pid is %d \n" , getpid());
break;
}
}
// 开始回收
if(i == 5){
sleep(5);
// 1. 回收任意的 pid
// wait_pid = waitpid(-1 , NULL , WNOHANG); // 表示不会阻塞
// 此时没有回收的进程成为孤儿进程被回收
// 2. 指定 pide
wait_pid = waitpid(target , NULL , 0);
printf("wait_pid = %d \n" , wait_pid);
printf("I am parent , my pid is %d \n" , pid);
} else {
printf("I am the %d th child , my pid is %d \n" , i + 1 , getpid());
}
}
- 进程编程的时候,一定需要注意父子进程进行变量共享的时候,遵循读是共享,写时复制的原则
- 总结:
wait和waitpid的区别:wait只可以阻塞的等待并且不可以指定具体需要回收那一个子进程,waitpid可以指定是否阻塞并且需要回收那一个子进程- 共同之处: 只可以回收一个子进程,不可以回收多个子进程
利用 waitpid 回收多个子进程
- 需要使用循环回收多个子进程
- 演示
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<sys/wait.h>
#include<unistd.h>
#include<fcntl.h>
int main()
{
int i ;
for(i = 0 ; i < 5 ; i ++){
if(fork() == 0){
break;
}
}
if(i == 5){
// 回收
// 1. 阻塞的方式回收
printf("I am the father , I am gonna to resource my child \n");
int wpid;
// while((wpid = waitpid(-1 , NULL , 0)) != -1){
// printf("Successfully resource child, pid: %d \n" , wpid);
// }
// 2. 非阻塞的方式回收
while((wpid = waitpid(-1 , NULL , WNOHANG)) != -1){
if(wpid == -1){
break;
} else if(wpid == 0){
sleep(1);
} else if(wpid > 0){
printf("Successfully resource child, pid: %d \n" , wpid);
}
}
} else {
printf("I am the %d th child , my pid is %d \n" , i + 1 , getpid());
}
}
- 相当于:
waitpid(-1 , &status , 0) == wait(&status)
综合案例
- 要求父进程
fork3个子进程,三个子进程一个调用ps命令,一个调用自定义程序1(正常) , 另外一个调用自定义程序2(发生段错误),父进程使用waitpid对于子进程进行回收 - 演示
demo如下:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/wait.h>
#include<fcntl.h>
int main()
{
int i ;
int status;
for(i = 0 ; i < 3 ; i ++){
if(fork() == 0){
break;
}
}
// 开始调用
if(i == 0){
printf("I am the %d child , my pid is %d \n" , i + 1 , getpid());
// 调用 ps 命令
int fd = open("./out" , O_CREAT | O_TRUNC | O_RDWR , 0644);
// 重定向
int new_fd = dup2(fd , STDOUT_FILENO);
// ps 命令
execlp("ps" , "ps" , "aux" , NULL);
// 无法关闭文件, 利用父进程
} else if(i == 1) {
// 调用正常的程序
printf("I am the %d child , my pid is %d \n" , i + 1 , getpid());
execlp("./test_demo1" , "./test_demo1" ,NULL);
} else if(i == 2) {
// 调用异常程序
printf("I am the %d child , my pid is %d \n" , i + 1 , getpid());
execlp("./test_demo2" , "./test_demo2" , NULL);
} else if (i == 3) {
printf("I am the father !!! \n");
// 开始进行回收
int wpid;
while((wpid = waitpid(-1 , &status , 0)) != -1){
if(wpid > 0){
// 首先判断状态
if(WIFEXITED(status)){
// 表示正常退出
printf("返回值为: %d \n" , WEXITSTATUS(status));
}
if(WIFSIGNALED(status)){
printf("异常终止,终止信号为: %d \n" , WTERMSIG(status));
}
printf("Successfully resource the child whose pid is %d \n" , wpid);
}
}
}
}
进程间通信方式
- 由于父子进程之间基本隔离,所以如果需要进行数据的相互交换,那就需要进行进程之间的通信,进程之间通信(
IPC) - 原理:
- 父子进程公用一个内核空间(当然这是物理上的),其实父子进程之间的桥梁就是内核中的一个缓冲区(默认大小为
4096B(4K))
- 父子进程公用一个内核空间(当然这是物理上的),其实父子进程之间的桥梁就是内核中的一个缓冲区(默认大小为
- 进程中通信的方式(最常用的四种):
- 管道(使用最简单)
- 信号(开销最小)
- 共享映射区(无血缘关系)
- 本地套接字(最稳定)
匿名管道(pipe)
管道的性质
- 管道是一种最基本的
IPC机制,作用于有血缘关系的进程之间,完成数据的传递,调用pipe系统函数就可以创建一个管道,有如下性质:- 本质就是一个伪文件(处理普通文件,目录,软链接等,其他的都是伪文件,不会占用磁盘空间)
- 有两个文件描述符引用,一个表示读端,另外一个表示写端
- 规定数据从管道的写端流入管道,从读端流出管道
- 管道的原理: 管道实际上是内核使用循环队列的形式实现出来的,借助内核缓冲区
(4K)实现 - 管道的局限性:
- 数据不可以自己写入,自己读取
- 管道中数据不可以重复读取,一旦读走,管道中就不再存在了
- 采用(双向)半双工通信方式,数据只可以在单方向上流动
- 只能在有公共祖先的进程之间使用管道
- 单工通信: 比如遥控器
- 半双工通信: 比如对讲机,每一次只有一个端可以传递信息
- 全双工通信: 相当与打电话(
WebSocket)
pipe函数
- 作用: 创建一个管道,并且打开管道
- 函数原型:
int pipe(int pipefd[2]);
- 参数:
pipefd[0]表示读端pipedf[1]表示写端
- 返回值:
- 成功返回
0失败返回-1
- 成功返回
- 相当于传递着一个数组之后,就可以把着一个数组中填充读端和写端,父子进程都可以获取到管道的两端
- 最后一定需要注意关闭读端或者写端,调用
close函数,一个写的时候,必须关闭另外一个端 - 注意利用
read读取之后,可以使用write写入到STDOUT中 - 管道演示
demo:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>
#include<string.h>
int main()
{
int pipefd[2];
// 1. 创建管道
int res = pipe(pipefd);
char buf[1024]; // 这样可以节约空间
if(res == -1){
perror("create pipe failed!!! \n");
exit(1);
}
// 2. 利用 fork调用子进程
int pid = fork();
if(pid == -1){
perror("fork the child failed !!! \n");
exit(1);
} else if(pid == 0) {
// 表示子进程
// 读取数据
close(pipefd[1]); // 关闭写端
int ret = read(pipefd[0] , buf , 1024);
if(ret == -1){
perror("read from pipe failed !!! \n");
exit(1);
}
write(STDOUT_FILENO , buf , ret);
} else if(pid > 0) {
// 表示父进程
// 向管道中写入数据
close(pipefd[0]); // 关闭读端
char* str = "hello pipe\n";
write(pipefd[1] , str , strlen(str));
// 关闭读端
sleep(1);
close(pipefd[1]);
}
}
管道的读写行为
- 读管道:
- 如果管道中有数据,
read返回时机读到的字节数 - 如果管道中没有数据:
- 管道写端被全部关闭,
read返回0(就像读到了文件结尾) - 管道写端没有被全部关闭,
read阻塞等待(不久的将来可能会有数据到达,此时会让出cpu)
- 管道写端被全部关闭,
- 如果管道中有数据,
- 写管道:
- 如果管道的读端被完全关闭,进程异常终止(也有可能捕捉
SIGPIPE信号,使得进程不终止) - 管道读端没有全部关闭:
- 管道已满,
write阻塞 - 管道没有满,
write将数据写入,并且返回时机写入的字节数量
- 管道已满,
- 如果管道的读端被完全关闭,进程异常终止(也有可能捕捉
案例
- 实现父子之间进程的通信,实现
ls | wc -l,假设父进程实现ls,子进程实现wc - 注意几个细节:
ls默认把信息输入到stdout所以需要让stdout指向pipefd[1]wc默认从stdin中读取, 所以需要让stdin指向pipefd[0]
- 实现
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
int main(int argc , char** argv)
{
int pipefd[2];
int ret = pipe(pipefd);
if(ret == -1){
perror("create pipe failed !!! \n");
exit(1);
}
int pid = fork();
if(pid == -1){
perror("fork child failed !!! \n");
exit(1);
} else if(pid == 0) {
// 实现 wc
close(pipefd[1]);
// 重定向
int ret = dup2(pipefd[0] , STDIN_FILENO); // wc -l 从输入中读取,其实就是从pipe[0]中读取
if(ret == -1){
perror("dup2 failed !!! \n");
exit(1);
}
execlp("wc" , "wc" , "-l" , NULL);
} else if(pid > 0) {
char* target;
if(argv[1] == NULL){
target = ".";
} else {
target = argv[1];
}
// 实现 ls 命令
// 1. 重定向
int newfd = dup2(pipefd[1] , STDOUT_FILENO);
if(newfd == -1){
perror("dup2 error !");
exit(1);
}
// 2. 调用
close(pipefd[0]);
execlp("ls" , "ls" , target , NULL);
}
}
兄弟进程之间的通信
- 利用兄弟之间进程通信实现
ls | wc -l - 注意对于一个管道,一定需要形成一个消息传递链,如下代码中如果没有在父进程中加上关闭写端和读端的操作,就会造成如下结果:

- 没有达到管道的回路状态
- 正确的代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/wait.h>
int main()
{
// 实现兄弟之间进程的通信
int i ;
int pipefd[2];
int ret = pipe(pipefd);
if(ret == -1){
perror("create pipe failed !!! \n");
exit(1);
}
for(i = 0 ; i < 2 ; i ++){
if(fork() == 0) {
break;
}
}
if(i == 0) {
// 第一个进程
// 实现 ls
printf("I am going to do ls , my pid is %d \n", getpid());
close(pipefd[0]);
int newfd = dup2(pipefd[1] , STDOUT_FILENO);
if(newfd == -1 ) {
perror("dup2 failed!!! \n");
exit(1);
}
// 开始执行操作
execlp("ls" , "ls" , NULL);
sleep(5);
} else if (i == 1) {
// 第二个进程
// 实现 wc 操作
printf("I am going to do wc , my pid is %d \n", getpid());
close(pipefd[1]);
int newfd = dup2(pipefd[0] , STDIN_FILENO);
if(newfd == -1){
perror("dup2 failed !!! \n");
exit(1);
}
// 开始执行操作
execlp("wc" , "wc" , "-l" , NULL);
} else if(i == 2){
// 父亲进程
// 进行进程的回收
close(pipefd[1]);
close(pipefd[0]);
printf("I am the parent , going to resource my child !!! \n");
int wpid;
// sleep(10);
while((wpid = waitpid(-1 , NULL , 0)) != -1){
if(wpid != -1){
printf("Successfully resource my child whose pid is %d \n" , wpid);
}
}
}
}
多个读写端操作和管道缓冲区的大小设置
- 结论: 一个
pipe可以有多个写端,一个读端,但是最好不用这样用,这样难以进行定点之间信息的传递,但是需要经可能避免这一种情况,并且无法控制消息的顺序 - 使用
ulimit -a可以查询缓冲区的大小,管道的缓冲区大小为4K - 还可以使用
fpathconf查询管道大小,函数原型如下:
long fpathconf(int fd, int name);
name可以传入多种宏定义,用于判断查询类型
管道的优缺点
- 优点: 简单,相比于信号,套接字实现进程间通信,简单很多
- 缺点:
- 只可以单向通信,双向通信需要建立两个管道
- 之可以用于父子,兄弟进程(有共同祖先)间通信,该问题之后使用
fifo有名管道解决
具名管道(fifo)
- 基本原理和
pipe差不多: 都是利用在内核空间建立缓冲区的方式实现管道的,不同之处在于fifo给管道起了名字
创建方式
- 创建方式:
- 命令:
mkfifo 管道名 - 库函数:
mkfifo
- 命令:
mkfifo函数原型如下:
int mkfifo(const char *pathname, mode_t mode);
- 头文件:
<sys/types.h><sys/stat.h>
- 参数:
pathname路径mode类似于open选项(权限值)
- 返回值:
- 成功返回
0失败范围-1
- 成功返回
- 创建管道的
fifo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
int main()
{
// 创建管道
int ret = mkfifo("./myfifo" , 0644);
if(ret == -1){
perror("create fifo failed !!! \n");
exit(1);
}
}
利用fifo实现非血缘关系进程之间通信
- 把
fifo看成一个文件:- 写端: 打开文件(只是写入方式) , 利用
write写入数据 - 读端: 读取文件(只是读方式) , 利用
read读文件
- 写端: 打开文件(只是写入方式) , 利用
- 可以实现一个写端多个读端和多个读端一个写端
- 读的方式如下:
#include<stdlib.h>
#include<string.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char** argv)
{
// 演示从管道中读取数据
if(argc < 2){
perror("请输入管道名称 \n");
exit(1);
}
int fd = open(argv[1] , O_RDONLY);
// 不断读取数据
char buf[1024];
int n = 0;
while((n = read(fd , buf , 1024)) != 0) {
if(n == -1){
perror("read from fifo failed !!! \n");
exit(1);
}
write(STDOUT_FILENO , buf , n);
sleep(1);
}
}
- 写的方式如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
int main(int argc , char** argv)
{
// 向管道中写入数据
if(argc < 2){
perror("请输入管道名称 !!! \n");
exit(1);
}
// 打开
int fd = open(argv[1] , O_WRONLY);
// 开始写入数据
char buf[1024];
int i = 1;
while(1){
sprintf(buf , "hello fifo %d \n" , i);
int ret = write(fd , buf , strlen(buf));
if(ret == -1){
perror("write into fifo failed !!! \n");
exit(1);
}
i ++;
sleep(1);
}
}
文件用于进程之间的通信
- 使用文件也可以完成
IPC,理论依据就是fork之后,父子共享文件描述符,所以父子进程之前,可以通过同一个文件描述符号找到同一个文件,一个进行读操作,另外一个进行写操作即可 - 对于不同的进程,由于不同的进程的
PCB不同,所以肯能文件描述符号不同,但是不同的文件描述符号还是指向了同一个文件,所以还是可以对于一个文件进行读操作,另外一个文件进行写操作,所以没有血缘关系的进程也可以打开同一个文件进行通信
存储映射 I/O
- 存储映射: 使得一个磁盘与存储空间爱你的一个缓冲区向映射(其实就是磁盘和内存的映射),并且进入内存之后就可以得到地址,利用地址就可以使用指针进行
IO操作,而不依赖与read和write函数对于文件进行操作 - 映射方式如下:

mmap函数
- 作用: 完成存储映射
- 头文件:
<sys/mmap.h> - 函数原型:
void *mmap(void addr[.length], size_t length, int prot, int flags,
int fd, off_t offset);
- 参数:
addr指定映射区域的首地址(通常可以传递NULL表示让系统自动分配)length表示共享内存映射区域的大小 (<=文件大小)prot表示共享内存区域的读写属性:PROT_READ只读PROT_WRITE只写PROT_READ | PROT_WRITE读写
flags标记共性属性(MAP_SHAREDMAP_PRIVATE(对于内存的修改不会同步到磁盘))fd用于创建共享内存映射区域的文件的文件描述符号offset偏移位置(相当于磁盘中的文件)(必须是4K的整数倍)(0表示映射文件的全部)
- 返回值(泛型指针):
- 成功: 成功创建的内存映射区域的首地址
- 失败:
MAP_FAILED就是(void*)(-1)并且设置errorno
利用 mmap 建立映射区域
- 注意使用
munmap函数进行映射空间的释放 - 函数原型:
int munmap(void addr[.length], size_t length);
- 注意拓展文件的方式:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/mman.h>
#include<fcntl.h>
#include<string.h>
void sys_exit(const char* msg)
{
perror(msg);
exit(1);
}
int main()
{
// 利用 mmap 创建内存映射
// 1. 首先获取文件
int fd = open("temp.txt" , O_CREAT | O_TRUNC | O_RDWR , 0644);
if(fd == -1){
sys_exit("create file failed !!!");
}
// 2. 对于文件进行扩容操作
// 2.1 第一种方式,使用 lseek
// lseek(fd , 10 , SEEK_END);
// write(fd , "\0" , 1);
// 2.2 利用 ftrancate 函数
ftruncate(fd , 20); // 扩容函数
// 3. 获取文件大小
int len = lseek(fd , 0 , SEEK_END); // 获取长度
// 4. 调用 mmap 函数
char* p = NULL;
// 相当于自动类型转换
p = mmap(NULL,len, PROT_READ | PROT_WRITE , MAP_SHARED , fd , 0);
if(p == MAP_FAILED){
sys_exit("mmap failed!!!");
}
strcpy(p , "hello mmap!!!\n");
// 5. 释放映射区域
int ret = munmap(p , len);
if(ret == -1){
sys_exit("munmap failed !!!");
}
}
mmap使用注释事项
-
用于创建映射区域的大小为
0, 实际指定非0大小创建映射区域,会出现 总线错误(或者偏移大于文件大小) -
用于创建映射区的文件大小为
0, 实指定0大小创建映射区,出 无效参数错误 -
用于创建文件读写属性为只读,映射区域属性为读写(必须读写或者前者大于后者),出 无效参数错误
-
使用
ftruncate扩展文件,需要向文件中写入数据,所以需要把文件的权限设置为可写 -
创建映射区域需要
read权限(创建的时候需要从文件中的读出信息来建立映射区域),mmap的读写权限必须小于等于文件的open权限 -
文件描述符号
fd在创建文件映射区域完毕之后就可以关闭了,之后直接操作地址即可 -
offset必须是4096的整数倍,和MMU相关,注意MMU映射的最小长度就是4K -
对于申请的内存,不可以越界访问
-
mumap释放的地址必须是mmap创建得到的地址,就是不可以改变指针的位置 -
一定需要检测
mmap操作是否成功 -
映射区域访问权限为
MAP_PRIVATE表示设置私有权限,就会导致在内存中对于文件的操作不会反映到磁盘上 -
设置
prot权限为MAP_PRIVATE的时候,只需要open的时候有读权限,用于创建映射区域就可以了,用于创建映射区域即可,原因就是不用同步到磁盘上 -
mmap函数的保险调用方式:open(O_RDWR)mmap(NULL , 有效大小 , PROT_READ | PROT_WRITE , MAP_SHARED , fd , 0)
mmap建立父子之间通信
- 为了保证通信可行,所以
flags需要设置为MPA_SHARED(否则就会归父进程私有) - 首先利用
mmap建立映射区域,之后利用fork创建子线程 - 父子进程使用
mmap进行通信:- 首先创建映射区域:
openmmap,指定权限为MAP_SHARED - 创建子进程
- 一个进程读,一个进程写
- 首先创建映射区域:
- 父子进程之间通信的方式如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<sys/mman.h>
#include<unistd.h>
#include<fcntl.h>
void sys_exit(const char* msg)
{
perror(msg);
exit(1);
}
int main()
{
int ret;
int fd = open("out" , O_CREAT | O_TRUNC | O_RDWR , 0644);
if(fd == -1){
sys_exit("open file failed !!! \n");
}
// 扩容
ret = ftruncate(fd , 20);
if(ret == -1){
sys_exit("ftruncate failed !!! \n");
}
// 获取长度
int len = lseek(fd , 0 , SEEK_END);
// 建立内存映射区域
char* p = mmap(NULL , len , PROT_READ | PROT_WRITE , MAP_SHARED , fd , 0);
if(p == MAP_FAILED){
sys_exit("mmap failed !!! \n");
}
// 创建子进程
int pid = fork();
if(pid == 0){
// 子进程
// 发送消息
strcpy(p , "hello father!");
} else if (pid > 0){
// 父进程
sleep(1);
write(STDOUT_FILENO , p , strlen(p));
}
close(fd);
ret = munmap(p , len);
if(ret == -1){
sys_exit("umap failed !!! \n");
}
}
mmap进行非血缘关系进程之间通信
- 注意其实内存中的操作最终会被同步到磁盘,所以和利用文件进行通信类似,但是这一种方式基于内存,操作更快更加便捷
- 好处就是可以传递任意数据类型(包含结构体等信息)
- 注意可以使用
memcpy作内存拷贝(注意不是拼接而是拷贝)(类似于strcpy) - 函数原型如下:
void *memcpy(void dest[restrict .n], const void src[restrict .n],
size_t n);
- 写进程代码如下:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<fcntl.h>
#include<sys/mman.h>
void sys_exit(const char* msg);
void sys_exit(const char* msg)
{
perror(msg);
exit(1);
}
struct student {
int age;
char name[256];
int id;
};
int main()
{
int ret;
struct student stu = {18 , "xiaoming" , 1};
int fd = open("out" , O_CREAT | O_TRUNC | O_RDWR , 0644);
if(fd == -1){
sys_exit("open file failed !!! \n");
}
// 扩容
ret = ftruncate(fd , sizeof(stu));
if(ret == -1){
sys_exit("truncate file failed !!! \n");
}
int len = lseek(fd , 0 , SEEK_END);
struct student* p = mmap(NULL , len , PROT_READ | PROT_WRITE , MAP_SHARED , fd , 0);
if(p == MAP_FAILED){
sys_exit("mmap failed !!! \n");
}
// 写入数据
while(1){
memcpy(p , &stu , sizeof(stu));
stu.id ++;
sleep(1);
}
}
- 读进程如下:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<fcntl.h>
#include<sys/mman.h>
void sys_exit(const char* msg);
void sys_exit(const char* msg)
{
perror(msg);
exit(1);
}
struct student {
int age;
char name[256];
int id;
};
int main()
{
// 打开文件
int fd = open("out" , O_RDWR);
if(fd == -1){
sys_exit("open file failed !!! \n");
}
// 读取文件内容
int len = lseek(fd , 0 , SEEK_END);
struct student* p = mmap(NULL , len , PROT_READ | PROT_WRITE , MAP_SHARED , fd , 0);
if(p == MAP_FAILED){
sys_exit("mmap failed !!! \n");
}
close(fd);
// 开始读取文件
while(1){
printf("id = %d , name = %s , age = %d \n" , p-> id , p->name , p -> age);
sleep(1);
}
}
- 支持一个读端多个写端,一个写端多个读端
- 没有血缘关系进程之间通信:
- 两个进程同时打开同一个文件,创建映射区
- 指定
flag为MAP_SHARED
- 注意没有血缘关系的进程之间通信的两种方式比较:
mmap可以多次读fifo只可以一次读
mmap匿名映射区
- 删除用于创建映射区的文件删除之后仍然可以创建映射区,所以可以创建匿名映射区
- 此时
fd参数可以指定为-1 - 函数的使用方式:
mmap(NULL , 40 , PROT_READ|PROT_WRITE , MAP_SHARED | MAP_ANONYMOUS , -1 , 0);
- 但是无法完成非血缘关系进程之间的映射
信号
- 信号的特点:
- 简单
- 不可以携带大量信息
- 满足特定条件才可以发送信号
信号的机制
- 信号的特质:
- 信号是软件层面的中断,一旦信号产生,无论程序执行到什么位置,必须停止运行,处理信号,处理结束,在继续执行后续指令
- 所有信号都是由内核发送并且处理的
与信号相关的时间和状态
- 产生信号:
- 按键产生:
Ctrl + CCtrl + Z - 系统调用产生:
killraise - 软件条件产生: 比如定时器
alarm(比如sleep) - 硬件异常产生, 比如: 非法访问内存(段错误),除
0,内存对齐错误 - 命令产生,比如
kill命令
- 按键产生:
- 递达(递送到达): 递达并且到达进程
- 未决: 产生和递归之间的状态,主要由于阻塞(屏蔽)导致着一个状态
- 信号的处理方式:
- 执行默认动作
- 忽略
- 捕捉(调用用户处理函数)
Linux内核的进程控制块PCB是一个结构体,task_struct除了包含进程id, 状态,工作目录,用户id,组id,文件描述符,还包含了信号相关的信息,主要指的就是阻塞信号集和未决信号集- 阻塞信号集(信号屏蔽字): 将某些信号加入到集合中,对他们设置屏蔽,当屏蔽x信号之后,在受到该信号,**该信号的处理将推后(**接触屏蔽之后)
- 未决信号集:
- 信号产生,未绝信号集中描述该信号的位立刻翻转为
1,表示信号处于未决状态,当信号被处理,对应的位立刻翻转为0,这一个时刻往往比较短暂 - 信号产生之后,由于某些原因(主要是由于阻塞)不可以抵达,这一类信号的集合称之为未决信号集,在屏蔽接触之前,信号一直处于未决状态(屏蔽的时候产生)
- 信号产生,未绝信号集中描述该信号的位立刻翻转为
- 信号都是固定的,未决信号集和信号屏蔽字中都是存储着他各种信号状态(信号种类都是由操作系统规定的)
- 信号处理过程如下:

常见的信号和信号四要素
- 利用
kill -l查看各种信号
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
-
信号四要素:
- 编号
- 名称
- 事件
- 默认处理动作
-
利用
man 7 signal可以查看信号的各种特征 -
Linux常见信号一览表: -
常见的信号比如:
SIGHUPSIGINTSIGKILLSIGQUITSIGBUS(总线错误)SIGPESIGUSR1SIGSEGVSIGUSR2SIGPIPESIGALRMSIGTERMSIGCHLDSIGSTOP
-
默认动作:
Term: 终止进程lgn: 忽略信号(默认就是对该信号忽略操作)Core: 终止进程,生成Core文件(查验进程死亡原因,用于gdb调试)Stop: 停止(暂停)进程Cont: 继续执行进程
-
但是注意
9)SIGKILL和19)SIGSTOP不允许忽略或者捕捉,甚至不可以设置未屏蔽 -
只有每一个信号对应的时间发生了,该信号才可以被递达,不可以乱发信号
kill函数与kill命令
kill命令
- 利用
kill命令产生信号:kill -SIGKILL 进程号就是kill -信号号码 进程号
kill函数
- 作用: 向某一个进程发送信号
- 头文件:
<signal.h> - 函数原型:
int kill(pid_t pid, int sig);
- 参数:
pid需要给那一个进程发送信号pid > 0发送信号给默认的进程pid = 0发送信号给调用kill函数进程属于同一个进程组的所有进程pid < -1取pid发送给对应的进程组(进程组号就是-pid)pid = -1发送给进程所有权限发送的系统中的所有进程
sig信号编号(宏定义)
- 返回值:
- 成功返回
0 - 失败返回
-1设置errono
- 成功返回
- 普通用户的基本规则就是: 发送者的实际或者有效用户
ID== 接受者实际或者有效的用户ID
#include<stdio.h>
#include<stdlib.h>
#include<signal.h>
#include<unistd.h>
int main()
{
int pid = fork();
if(pid == 0){
printf("I am child , my pid is %d , my ppid is %d \n" , getpid() , getppid());
// kill(getppid() , SIGSEGV); // 表示段错误
// kill(getppid() , SIGKILL) 表示强制杀死进程
while(1){
printf("I am child ! \n");
sleep(1);
}
} else if(pid > 0){
printf("I am the parent , my pid is %d \n",getpid());
// while(1){
// printf("this is my code !!! \n");
// sleep(1);
// }
// 进程组 id 其实就是当前进程的id
// kill(- getppid() , SIGKILL);
}
}
- 循环创建进程并且杀死指定进程:
#include<stdio.h>
#include<stdlib.h>
#include<signal.h>
#include<unistd.h>
#include<string.h>
int main()
{
// 循环创建5个子进程并且利用 kill 函数杀死任意一个进程
int target; // 记录需要杀死的子进程假设就是 第三个
int i ;
for(i = 0 ; i < 5 ; i ++){
int pid = fork();
if(pid == -1){
perror("fork failed !!!");
exit(1);
}
if(pid == 0){
break;
}
if(pid > 0 && i == 2){
target = pid;
}
}
if(i >= 0 && i <= 4){
// 子进程
printf("I am the %d th child , my pid is %d \n",i + 1 , getpid());
sleep(10);
} else if(i == 5){
sleep(2);
int ret = kill(target , SIGKILL);
if(ret == -1){
perror("kill failed !!!");
exit(1);
}
printf("ret = %d \n" , ret);
}
}
alarm函数
- 作用: 设置定时器(闹钟),指定
seconds之后,内核会给当前进程发送14)SIGALRM信号,进程受到信号之后,默认动作终止,每一个进程都有且仅有唯一一个定时器 - 头文件:
<unistd.h> - 函数原型:
unsigned int alarm(unsigned int seconds);
- 参数: 表示设置的秒数
- 返回值:
0或者剩余的秒数(重置定时器之前的剩余秒数),没有失败的情况 - 比如以下过程中:
alarm(5) -- 3 sec -- alarm(4) -- 5sec -- alarm(5) -- alarm(0) - 此时
alarm(4)返回5 - 3 = 2alarm(5)由于上一次定时器超过时间返回0alarm(0)返回上一次定时器的剩余时间5 alarm(0)用于清除定时器- 闹钟时间到的时候,就会向程序发送信号表示闹钟结束,会终止进程
- 可以使用
time命令,程序运行的瓶颈在于IO,优化程序,首选优化IO - 实际执行时间 = 系统时间 + 用户时间 + 等待时间
setitimer函数
- 函数功能: 设置定时器,可以替代
alarm函数精度微秒可以设置定时周期 - 头文件:
<sys/timer.h> - 函数原型:
int setitimer(int which, const struct itimerval *restrict new_value,
struct itimerval *_Nullable restrict old_value);
- 参数:
which:- 自然定时:
ITIMER_REAL -> 14) SLGLARM计算自然时间 - 虚拟空间计时(用户空间):
ITIMER_VIRTUAL -> 26) SIGVTALRM只是计算进程占用CPU的时间 - 运行时计时(用户+内核) :
ITIMER_PROF -> 27)SIGPROF只计算占用cpu和执行系统调用的时间
- 自然定时:
new_value新的定时时间old_value传出参数,表示剩余的时间,是一个传出参数
- 返回值:
- 成功返回
0 - 失败返回
-1设置errorno
- 成功返回
struct itimerval类型的定义如下:
struct itimerval {
struct timeval it_interval; /* Interval for periodic timer */
struct timeval it_value; /* Time until next expiration */
};
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};
it_interval用于设定两次定时任务之间的时间间隔it_value定时的时长- 演示
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/time.h>
int main()
{
// 使用 setitmer 完成定时任务
struct itimerval new_value;
struct itimerval old_value;
new_value.it_interval.tv_sec = 1;
new_value.it_interval.tv_usec = 0;
new_value.it_value.tv_sec = 1;
new_value.it_value.tv_usec = 0;
// 相当于设置 alarm(1) ,可以一次设置多个值
setitimer(ITIMER_REAL, &new_value , &old_value);
printf("old_value.it_interval.tv_sec = %ld \n" , old_value.it_interval.tv_sec);
printf("old_value.iterval.tv_usec = %ld \n" , old_value.it_interval.tv_usec);
int i = 1;
while(1){
printf("%d \n" , i);
i ++;
}
}
- 但是如果使用第一种模式,其实他会发送一个终止进程的停止闹钟信号,所以就像只是设置了一轮一样,注意两个定时器时间间隔和一个定时器的执行之间之间的区别
信号集操作函数
- 阻塞信号集可以操作,未决信号集不可以操作但是通过阻塞信号集的方式操作未决信号集
- 作用: 设置自定义信号集,后面就是传入参数
- 信号集设置的函数如下:
int sigemptyset(sigset_t *set);
int sigfillset(sigset_t *set);
int sigaddset(sigset_t *set, int signum);
int sigdelset(sigset_t *set, int signum);
int sigismember(const sigset_t *set, int signum);
- 名称可以显示各个函数的作用,作用分别是:
- 信号集设置为空
- 信号集填充
- 信号集添加某一个位
- 信号集删除某一个位
- 判断信号集中的位
- 参数:
set表示一个位图
sigprocmask 函数
- 作用: 用于屏蔽信号,解除信号也可以使用这一个函数,他的本质,读取或者修改进程的信号品屏蔽字(
PCB中) - 注意: 屏蔽信号,只是将信号延后执行(延后到接触屏蔽),并且忽略将信号丢处理
- 函数原型如下:
int sigprocmask(int how, const sigset_t *_Nullable restrict set,
sigset_t *_Nullable restrict oldset);
- 参数解释
set: 表示一个传入参数,是一个位图,set中位置为1,就表示当前进程屏蔽哪一个信号oldset: 传出参数,保存旧的信号屏蔽集(就的mask)how参数取值: 假设当前的信号屏蔽字为maskSIG_BLOCK当how设置为这一个值的时候,set表示需要屏蔽的信号,相当于mask = mask | setSIG_UNBLOCK当how设置为这一个值的时候,set表示需要解除屏蔽的信号,相当于mask = mask & ~setSIG_SETMASK当mask设置为这一个值的时候,set用于替代与原始屏蔽和新的屏蔽集,相当于mask = set,调用sigprocmask解除了对于当前若干个信号的阻塞,则在sigprocmask返回之前,至少将其中一个信号递达
sigpending函数
- 作用: 读取未决信号集
- 函数原型:
int sigpending(sigset_t *set);
-
参数:
set表示一个传出参数
-
实践方式: 首先利用
sigemptyset等函数自定义信号集对于set进行设置,之后利用sigprocmask函数操作信号即,注意how参数,利用sigpending查看未决信号集 -
信号集合函数演示如下:
-
注意信号一定需要产生之后,才可以被屏蔽,如果信号产生也就谈不上是否被屏蔽,屏蔽之后对应的位图中的位就会发生改变
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<signal.h>
#include<errno.h>
void sys_err(const char* msg)
{
perror(msg);
exit(1);
}
void print_set(sigset_t* set)
{
for(int i = 1 ; i <= 32 ; i ++){
if(sigismember(set , i)){
// 表示存在
putchar('1');
} else {
putchar('0');
}
}
printf("\n");
}
int main()
{
sigset_t set , oldset;
int ret;
sigemptyset(&set);
sigaddset(&set , SIGINT);
sigaddset(&set , SIGKILL);
sigaddset(&set , SIGSTOP);
sigaddset(&set , SIGQUIT);
// 开始进行改变
ret = sigprocmask(SIG_BLOCK , &set , &oldset);
if(ret == -1){
sys_err("sigprocmask error");
}
sigset_t pedset;
// 注意发生信号才可以解析
while(1){
ret = sigpending(&pedset);
if(ret == -1){
sys_err("sigpending failed !!! \n");
}
print_set(&pedset);
sleep(1);
}
}
信号捕捉
signal函数
- 作用: 注册一个捕捉函数(并不是完成信号的捕捉)(这是信号递达之后的事情)
- 函数原型:
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
- 注意函数指针的定义方式,这样定义就会使得,
sighandler_t成为一个类型,这一个类型指向形如function<void(int)>的函数,当然可以使用function<void(int)>进行包装 - 参数:
signum表示信号handler表示处理方式
- 演示
demo如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<signal.h>
void handler_func(int signal)
{
printf("catch you !!! %d \n" , signal);
}
int main()
{
// 演示捕捉进程
while(1){
signal(SIGINT , handler_func);
}
}
sigaction函数
- 实现捕捉函数的注册
- 函数原型如下:
int sigaction(int signum,
const struct sigaction *_Nullable restrict act,
struct sigaction *_Nullable restrict oldact);
- 参数:
signum: 需要捕捉的信号act: 指定捕捉函数,sa_mask sa_flags等信息oldact: 传出参数表示之前的配置信息
- 参数中的结构体如下:
struct sigaction {
void (*sa_handler)(int); // 信号处理方式
void (*sa_sigaction)(int, siginfo_t *, void *); // 携带复杂结构体
sigset_t sa_mask; // 作用于信号捕捉函数活动期间
int sa_flags;
void (*sa_restorer)(void);
};
- 由于信号捕捉的优先级高于信号处理的优先级别,如果不设置
sa_mask变量,PCB中的mask从进程创建开始一直存在,所以如果在这一个进程执行的时候,由另外一个信号发送给这一个进程如果还是依赖于同样的mask就会导致相当的信号重复捕捉重复执行到时循环,所以引入sa_mask,这一个变量在信号处理的过程中替代mask从而防止这一种情况 - 绝大多情况下
sa_mask和sa_flags都可以传递0作为参数 - 使用
demo如下:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<signal.h>
void catch_signal(int signal)
{
printf("catch you %d !!! \n" , signal);
}
int main()
{
// 利用 sigaction 函数进行信号的捕捉
struct sigaction act , oldact;
act.sa_handler = catch_signal;
// 注意清除的方式
sigemptyset(&act.sa_mask); // 相当于清空 sa_mask
act.sa_flags = 0;
// 开始注册
int ret;
ret = sigaction(SIGINT , &act , &oldact);
if(ret == -1){
perror("sigaction failed !!! \n");
exit(1);
}
ret = sigaction(SIGQUIT , &act , &oldact);
if(ret == -1){
perror("sigaction failed !!! \n");
exit(1);
}
while(1);
}
信号捕捉特性
- 进程正常运行的时候,默认的
PCB中一个信号屏蔽字(mask),他决定了进程自动屏蔽那些信号,当注册了某个信号捕捉函数,捕捉到该信号之后,要调用该函数,而该函数有可能需要执行很长时间,在这一个期间所屏蔽的信号不会由mask来指定,而是由sa_mask指定,调用完信号处理函数就会恢复为mask XXX信号捕捉函数执行期间,XXX信号自动屏蔽(sa_flags = 0)- 阻塞的常规信号不支持排队,产生多次只会记录一次(但是后面32个实时信号支持排队)
- 如果需要在捕捉某一个信号的同时屏蔽另外一个信号可以考虑设置
sa_mask的值来屏蔽另外一个信号
内核实现进程捕捉的过程

SIGCHLD信号
SIGCHLD信号的产生条件:- 子进程终止的时候
- 子进程接收到
SIGSTOP信号停止的时候 - 子进程处于停止状态,接收到
SIGCONT之后唤醒
使用 SIGCHLD 信号回收子进程
- 子进程结束之后,其父进程会受到
SIGCHLD信号,该信号的默认处理动作就是忽略,可以捕捉该信号,在捕捉函数中完成进程状态的回收 - 如果使用如下代码,那么就会导致处理信号的时候,子进程发送的信号就会被屏蔽,导致子进程无法被回收,导致僵尸进程的产生
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<signal.h>
#include<sys/wait.h>
void handler_child(int signo)
{
// 回收子进程
int wpid;
wpid = wait(NULL);
printf("Successfully resource my child: %d \n" , wpid);
}
int main()
{
// 利用 SIGNCHLD 信号回收子进程
int i ;
for(i = 0 ; i < 5 ; i ++){
if(fork() == 0){
break;
}
}
if(i == 5){
// 表示父进程,开始回收子进程
// 回收
// 首先注册
struct sigaction act;
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
act.sa_handler = handler_child;
sigaction(SIGCHLD , &act , NULL);
while(1){
printf("I am the parent , my pid is %d \n" , getpid());
sleep(1);
}
} else {
// 子进程
printf("I am the child ,my pid is %d , my ppid is %d \n" , getpid() , getppid());
}
}
- 利用
SIGCHLD进行的最佳实践如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/wait.h>
#include<signal.h>
// 定义捕捉函数
void catch_child(int signo)
{
int wpid ,status;
// 循环回收连续结束的子进程
while((wpid = waitpid(-1 , &status , 0)) != -1){
if(WIFEXITED(status)){
printf("Successfully resource child whose pid is %d and return_val is %d \n" , wpid , WEXITSTATUS(status));
}
}
}
int main()
{
// 设置 SIGCHLD 阻塞
sigset_t sig;
sigemptyset(&sig);
sigaddset(&sig , SIGCHLD);
sigprocmask(SIG_BLOCK , &sig , NULL);
int i;
for(i = 0 ; i < 15 ; i ++){
if(fork() == 0){
break;
}
}
if(i == 15){
// 父进程
// 首先进行注册
struct sigaction act;
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
act.sa_handler = catch_child;
sigaction(SIGCHLD , &act , NULL);
// 解除
sigset_t new_sig;
sigemptyset(&new_sig);
sigaddset(&new_sig , SIGCHLD);
sigprocmask(SIG_UNBLOCK , &new_sig , NULL);
while(1){
printf("I am parent , my pid is %d \n" , getpid());
sleep(1);
}
} else {
printf("I am child , my pid is %d , my ppid is %d \n" , getpid() , getppid());
return i + 1;
}
}
- 首先明确第一程序中出现的问题: 当父进程回收其他子进程的时候,此时另外的子进程发送
SIGCHLD信号,此时这些信号就不会被捕捉到,所以这里采用循环捕获的方法进行捕获,从而使得多个子进程同时死亡的时候可以捕获 - 另外一个问题就是如果子进程在注册捕捉函数之前死亡,父进程就无法捕捉到了,所以这里首先需要在主进程中屏蔽调
SIGCHLD信号,之后注册完成之后继续取消对于SIGCHLD信号的屏蔽 - 利用
SIGCHLD的方式回收子进程的一个好处就是可以不再妨碍父进程的工作的情况下进行子进程的回收
中断系统调用
- 两类系统调用:
- 慢速系统调用: 可能会使进程永远阻塞的一类,如果在阻塞期间受到一个信号,该系统调用就会被中断,不再继续执行(早期),也可以设定系统调用是否重启,比如
read,write,pause,wait(子进程不死,就会一直阻塞) ... - 其他系统调用:
getpidgetppidfork...
- 慢速系统调用: 可能会使进程永远阻塞的一类,如果在阻塞期间受到一个信号,该系统调用就会被中断,不再继续执行(早期),也可以设定系统调用是否重启,比如
- 满足系统调用被中断的相关行为,其实都是
pause的行为,比如read- 想要中断
pause, 信号不可以被屏蔽 - 信号的处理方式必须是捕捉(默认,忽略都不可以)
- 中断之后返回
-1, 设置errorno为EINTR(表示 "被信号中断")
- 想要中断
- 可以修改
sa_flags参数来设置被信号中断之后,系统调用是否重启,SA_INTERRURT表示不重启,SA_RESTART表示重启 - 拓展了解:
sa_flags还有很多可选参数,适用于不同的情况,比如捕捉到信号之后,在执行捕捉函数的期间,不希望自动阻塞该信号,可以将sa_flags设置为SA_NODERER,除非sa_mask中包含这一个信号
- 如果想要给捕捉信号发送结构体等类型,需要(
sa_flags)传递SIGINFO参数
会话
- 会话: 表示用户和操作系统进行交互的一段时间,
Linux下的体现就是终端 - 创建一个会话需要注意以下
6点:- 调用进程不可以是进程组组长,该进程变成会话首进程(
session header) - 该进程成为一个新进程组组长的组长进程
- 需要有
root权限(ubuntu不需要) - 新的会话丢弃原有的控制终端,该会话没有控制终端
- 该调用进程未组长进程,就会出错返回
- 建立新的会话的时候,首先调用
fork, 父进程终止,子进程调用setsid()
- 调用进程不可以是进程组组长,该进程变成会话首进程(
getsid函数
- 获取进程所属的会话
IDpid_t getsid(pid_t pid)- 成功返回调用进程的会话
ID,失败就会返回-1并且设置errorno
setsid函数
- 作用: 创建一个会话,并且使用自己的
ID设置进程组ID,同时也是新会话的ID - 函数原型:
pid_t setsid(void);
- 返回值:
- 成功返回调用进程的会话
ID - 失败返回
-1并且设置errorno
- 成功返回调用进程的会话
ps ajx命令中的SID TTY就是会话id- 利用子进程调用会话之后可以得到:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int main()
{
int pid = fork();
if(pid > 0){
printf("I am father , my pid is %d \n" , getpid());
} else if(pid == 0){
// 表示子进程
// 首先查看 sid
int old_sid = getsid(0); // 表示查看当前进程的 sid
printf("old_sid = %d \n " , old_sid);
printf("group id = %d \n" , getpgid(0));
printf("old_pid = %d \n" , getpid());
setsid(); // 表示开启新的会话
int new_sid = getsid(0);
printf("new_sid = %d \n " , new_sid);
printf("group id = %d \n" , getpgid(0));
printf("new_pid = %d \n" , getpid());
}
}
- 调用结果如下:
I am father , my pid is 99089
old_sid = 98861
group id = 99089
old_pid = 99090
new_sid = 99090
group id = 99090
new_pid = 99090
- 可见,用于创建会话的进程首先使用自己的
pid创建会话,同时以自己的pid命名进程组并且成为进程组的组长
守护进程
Daemon(精灵)守护进程,是Linux中后台服务进程,通常独立于控制终端并且周期性执行某种任务或者等待某些发生的事件,一般都是采用d结尾的名称命名Linux后台的一些系统服务进程,没有控制终端,不可以直接和用户进行交互,不受用户登陆,注销的影响,一直在运行着,他们都是守护进程,比如预读入缓输出机制的实现:ftp服务器,nfs服务器等- 创建守护进程,最关键的一部就是调用
setsid函数创建一个新的Session并且成为Session leader
创建守护进程
- 创建守护进程流程分析:
- 创建子进程,父进程退出(所有工作在子进程中进行形式脱离了控制终端)
- 在子进程中创建新会话(
setsid()函数,使得子进程完全独立出来,脱离控制) - 改变当前目录位置(
chdir()函数,防止占用可以卸载的文件系统(比如U盘等),可以换成其他目录(最好固定比如~或者/)) - 设置文件权限掩码(
umask()函数,防止继承的文件创建屏蔽字拒绝某些权限,增加守护进程灵活性) - 关闭文件描述符(标准输入标准输出等)(继承的打开文件不会用到,浪费系统资源,无法卸载)(或者重定向给
/dev/null(空洞)) - 开始执行守护进程核心工作,守护进程退出处理程序模型
创建守护进程实现方式
- 相当于创建了一个后台运行的一个程序
- 创建代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/stat.h>
int main()
{
// 1. 首先创建子进程
int pid = fork();
int ret;
if(pid > 0){
// 父进程
exit(0);
} else if(pid == 0){
// 等待父进程退出
sleep(1);
// 2. 创建会话
ret = setsid();
if(ret == -1){
perror("setsid() error ");
exit(1);
}
// 3. 改变工作目录
ret = chdir("/home/loser");
if(ret == -1){
perror("chdir() error");
exit(1);
}
// 4. 设置 umask
umask(0022); // 由于新创建的文件没有执行权限,所以需要利用这一掩码 权限 & ~umask
// 5. 进行输入输出重定向或者关闭
int fd = open("/dev/null" , O_RDWR);
if(fd == -1){
perror("open() failed ");
exit(1);
}
close(STDIN_FILENO); // 关闭文件描述符 0
dup2(fd , STDOUT_FILENO);
dup2(fd , STDERR_FILENO);
// 6. 处理核心业务逻辑
while(1){
// 模拟守护进行的业务逻辑
}
}
}
- 注意文件掩饰代码的设置,可以参考: https://blog.csdn.net/2401_84967954/article/details/138983541
Socket编程
套接字
- 在通信过程中,套接字都是成对出现的,可以理解为插头和插座的关系,只有两者成对出现的时候,才可以进行通电
- 套接字的通信原理如下:
- 注意只有一个文件描述符号但是有两个缓冲区(对于服务器端的
connfd和客户端端的clientfd都有一个读缓冲,一个写缓冲)
- 一个文件描述符指向一个套接字(该套接字内部由内核借助两个缓冲区实现),在通信过程中一定时成对出现的
网络字节序
- 首先了解以下小端法和大端法: https://blog.csdn.net/qq_41337034/article/details/112818650
- 小端法(
pc本地存储): 高位存储高地址,低位存储低地址 - 大端法(网络存储): 高为存储低地址,低位存储高地址
- 网络数据流采用大端字节序
- 可以调用如下库函数完成网络字节序和主机字节序的转换:
#include<arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint32_t htons(uint32_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint32_t ntohs(uint16_t netshort);
- 其中
h表示host,n表示network,l表示32位长整数(IP协议),s表示16位短整数(port) - 应用场景如下:
htonl: 本地 -> 网络 (IP)htons: 本地 -> 网络 (port)ntohl: 网络 -> 本地 (IP)ntohs: 网络 -> 本地 (port)
- 对于
IP地址, 点分十进制(string) -->atoi-->htonl
IP转换函数
- 利用以下两个函数可以完成点分十进制和网络字节序列的相互转换:
#include<arpa/inet.h>
int inet_pton(int af , const char* src , void* dst);
const char* inet_ntop(int af , const void* src , char* dst , socklen_t size);
inet_pton函数
- 作用: 完成点分十进制到网络字节序列的转换
- 函数原型如下:
int inet_pton(int af, const char *restrict src, void *restrict dst);
- 参数:
af指定使用ipv4还是ipv6,使用两个宏定义指定:AF_INET和AF_INET6src: 表示需要传入的IP地址dst: 传出参数,转换之后的网络字节序的IP地址
- 返回值:
- 成功:
1 - 异常:
0, 说明src指向的不是一个有效的ip地址 - 失败:
-1并且设置errorno
- 成功:
inet_ntop函数
- 作用: 把网络字节序列转换为本地字节序列
- 函数原型:
onst char *inet_ntop(int af, const void *restrict src,
char dst[restrict .size], socklen_t size)
- 参数:
af指定使用ipv4还是ipv6src指定网络字节序IP地址dst(缓冲区): 本地字节序(string IP)size: 缓冲区大小
- 返回值:
- 成功:
dst - 失败: 返回
NULL
- 成功:
sockaddr地址结构
sockaddr地址结构和之后的衍生结构如下:
- 但是之前
unix设计的函数中的参数只可以使用sockaddr(当时没有出现泛型指针),并且之前的API不好用,所以可以强制类型转换的方式对于参数进行转换
bind函数
- 作用: 绑定
IP + port - 函数原型:
int bind(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);
- 参数:
sockfd: 套接字的文件描述符addr: 表示sockaddr地址结构,但是一般都是利用sockaddr_in强制转换为sockaddr使用
struct sockaddr_in {
sa_family_t sin_family; /* ()(使用那一种类型的 IP 地址)address family: AF_INET */
in_port_t sin_port; /* (表示端口号)port in network byte order */
struct in_addr sin_addr; /* (IP地址,32位)internet address */
};
/* Internet address */
struct in_addr {
uint32_t s_addr; /* address in network byte order */
};
addrlen表示取得到sockaddr地址结构所占用的字节数量(长度)- 调用
bind函数的实例如下: - 特别注意
sockaddr_in的初始化方式 - 由于本地的变量存储都是使用小端法,但是网络中的变量存储都是使用的大端法,所以一定需要进行转换,把本地的变量转化为网络传输中可以使用的变量
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<sys/socket.h>
#include<arpa/inet.h>
#include <netinet/in.h>
int main()
{
// 首先准备结构体
struct sockaddr_in addr;
// 初始化成员
addr.sin_family = AF_INET; // 表示使用 ipv4
addr.sin_port = htons(3306); // 注意这一个函数表示把本地的变量转换为网络序列中的变量
int dst;
inet_pton(AF_INET , "192.168.59.132" , (void*)&dst);
addr.sin_addr.s_addr = dst; // 注意也是一个结构体
// addr.sin_addr.s_addr 的另外一种初始化方式
addr.sin_addr.s_addr = htonl(INADDR_ANY); // 这一个宏定义默认取出系统任意有效的 IP 地址,二进制类型
// bind(fd , (struct sockaddr_in*)&addr , sizeof(addr))
}
socket模型创建流程
- 注意一个客户端和一个服务端进行通信的时候,会有三个文件描述符
- 通信的大体流程如下:

- 具体的细节如下:

socket函数
- 作用: 创建一个
socket - 函数原型如下:
int socket(int domain, int type, int protocol);
- 函数参数:
domain: 表示使用那一种形式(ipv4ipv6):AF_INET,AF_INET6,AF_UNIXtype:SOCK_STREAM(流式协议,TCP) ,SOCK_DGRAM(报式通信,UPD)protocol: 和上一个参数配合表示使用那一种协议,如果上面传递流式协议那么这里传递0表示使用TCP
- 返回值: 成功返回文件描述符(新套接字对应的文件描述符),失败返回
-1并且设置errno
bind函数
- 作用: 给套接字绑定地址结构(
IP+port) - 函数原型如下:
int bind(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);
- 参数:
sockfd: 表示需要绑定结构地址的socket的文件描述符号fdsockaddr: 需要利用struct sockaddr_in进行强制类型转换(两种方法,参考前面)addrlen: 地址结构的大小(sizeof(addr))
- 返回值: 成功返回
0, 失败返回-1
listen函数
- 作用: 设置同时与服务器建立连接的上限数量(同时进行三次握手的客户端数量)
- 函数原型如下:
int listen(int sockfd, int backlog);
- 函数参数:
sockfd: 表示socket的文件描述符号backlog: 表示最大的连接上限数量
- 返回值:
- 成功:
0 - 失败:
-1
- 成功:
accept函数
- 作用: 阻塞等待客户端建立连接,成功返回一个与客户端成功连接的
socket文件描述符 - 函数原型:
int accept(int sockfd, struct sockaddr *_Nullable restrict addr,
socklen_t *_Nullable restrict addrlen);
- 参数:
sockfd: 表示套接字的文件描述符addr: 传出参数(成功与服务器建立连接哪一个客户端的地址结构(IP+port))addrlen: 传入传出参数, 传入:addr的大小,传出: 客户端addr的实际大小(比如定义方式:socket_t socket_client_size = sizeof(addr))
- 返回值:
- 可以和客户端进行通信的文件描述符
- 失败返回
-1, 设置errorno
connect函数
- 作用: 与服务器建立连接,使用现有的
socket建立连接 - 函数原型:
int connect(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);
- 参数:
sockfd: 表示客户端的fdaddr: 传入参数,表示服务器的地址结构addrlen: 表示服务器地址结构的大小
- 如果不使用
bind函数绑定客户端的地址结构,采用"隐式绑定"的方式
客户端服务端实现
server:socket()创建socketbind()绑定服务器地址结构listen()设置监听上限accept()阻塞监听客户端连接read(fd)读取socket获取客户端数据- 业务逻辑操作
write(fd)写数据close()关闭连接
client:socket()创建socketconnect()连接服务器write()写数据到socketread()读转换之后的数据- 业务逻辑处理
close()
server实现
server的实现如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<sys/socket.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<ctype.h>
#define SERVER_PORT 10087
void sys_err(const char* msg)
{
perror(msg);
exit(1);
}
int main()
{
// 1. 首先利用 socket() 获取 socket
int socket_fd = socket(AF_INET , SOCK_STREAM , 0); // 表示采用 tcp
if(socket_fd == -1){
sys_err("create a socket failed !!!");
}
// 2. 使用 bind 进行绑定
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(SERVER_PORT);
addr.sin_addr.s_addr = htonl(INADDR_ANY); // 当然也可以使用 inet_pton 函数
bind(socket_fd , (struct sockaddr*)&addr , sizeof(addr));
// 3. 利用 listen 指定最大连接数量
listen(socket_fd , 128);
// 4. 利用 accept 进行阻塞并且获取新的 fd
printf("等待客户端连接 ... \n");
struct sockaddr_in target_addr;
socklen_t target_len = sizeof(target_addr);
int fd = accept(socket_fd , (struct sockaddr*)& target_addr , &target_len);
if(fd == -1){
sys_err("accept client failed !!!");
}
printf("连接成功 ... \n");
// 获取客户端的地址和端口号
// printf("address: %d \n" , ntohsl(target_addr.sin_addr.s_addr));
// 注意需要使用 inet_ntop
char client_IP[1024];
// 注意进行转换
inet_ntop(AF_INET , (void*)&(target_addr.sin_addr.s_addr) , client_IP , sizeof(client_IP));
printf("addresss: %s \n" , client_IP);
printf("port: %d \n" , ntohs(target_addr.sin_port));
// 5. 开始循环读取写入
char buf[BUFSIZ]; // 表示 4096
while(1){
int n = read(fd , buf , BUFSIZ);
// 如果读取到信息
if(n > 0){
if(strcmp(buf , "exit") == 0){
close(fd);
printf("服务器端退出了 ... \n");
exit(0);
}
// 进行转换
// 进行转换
for(int i = 0 ; i < n ; i ++){
buf[i] = toupper(buf[i]);
}
// 写回去
write(fd , buf , n);
}
}
}
client实现
client实现方式如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<arpa/inet.h>
#include<sys/socket.h>
#include<unistd.h>
#define CLINET_PORT 10089
#define SERVER_PORT 10087
void sys_err(const char* msg)
{
perror(msg);
exit(1);
}
int main()
{
// 1. 首先获取 socket
int ret;
int socket_fd;
socket_fd = socket(AF_INET , SOCK_STREAM , 0);
if(socket_fd == -1){
sys_err("socket failed !");
}
// 2. 可选,绑定 端口号和 IP 地址
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(CLINET_PORT);
bind(socket_fd , (struct sockaddr*)&addr , sizeof(addr));
// 3. connect 进行连接
struct sockaddr_in server_addr;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERVER_PORT);
server_addr.sin_family = AF_INET;
ret = connect(socket_fd , (struct sockaddr*)&server_addr , sizeof(server_addr));
if(ret == -1){
sys_err("connect failed !");
}
// 建立连接开始循环读取
char buf[BUFSIZ];
while(1){
// 通过重定向的方法进行数据的输入和输出
scanf("%s" , buf);
write(socket_fd , buf , strlen(buf));
// 开始读取结果
int n = read(socket_fd , buf , sizeof(buf));
if(n > 0){
write(STDOUT_FILENO , buf , n);
}
}
close(socket_fd);
}
- 注意函数
strlen和sizeof函数的区别,定义字符串首选字符数组格式的 - 可以使用
nc工具模拟客户端和服务器端进行通信
TCP通信时序和代码的对应关系
TCP通信时许和代码的对应关系,一定需要注意connect和accept函数的返回时机,另外还需要注意read(0)的时候对因半关闭建立完成(无法接受数据)
- 注意利用
read方法读取socket中的数据是阻塞形式的
错误处理函数的封装
- 可以把所有错误处理封装到一个函数中去,从而时的不用再主程序中检测返回值是否正确
- 错误处理的方式如下:
- 使用前面系统函数名第一个字母变成大小即可跳转
man手册
#include "wrap.h"
void sys_err(const char* msg)
{
perror(msg);
exit(1);
}
// socket 函数封装
int Socket(int domain, int type, int protocol)
{
int fd = socket(domain , type , protocol);
if(fd == -1){
sys_err("create socket failed !");
}
return fd;
}
// bind 函数封装
int Bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen)
{
int ret = bind(sockfd , addr , addrlen);
if(ret == -1){
sys_err("bind Ip and port failed !");
}
return ret;
}
// listen 函数封装
int Listen(int sockfd, int backlog)
{
int ret = listen(sockfd , backlog);
if(ret == -1){
sys_err("bind max num to connect the server failed !");
}
return ret;
}
// accept函数封装
int Accept(int sockfd, struct sockaddr* addr,socklen_t* addrlen)
{
int n;
while((n = accept(sockfd , addr , addrlen)) < 0){
if(errno == ECONNABORTED || errno == EINTR){
// 继续循环
continue;
} else {
sys_err("accept failed !");
}
}
return n;
}
// connect 函数封装
int Connect(int sockfd, const struct sockaddr *addr,socklen_t addrlen)
{
int n;
n = connect(sockfd , addr , addrlen);
if(n == -1){
sys_err("connect failed !");
}
return n;
}
- 注意
static关键字的作用: 限制函数的作用域,只在当前模块里面有用 - 注意注意指针的运用
- 封装
readn和readline封装思想如下:
// 封装 Readn 函数指定读取 n个字节
ssize_t Readn(int sockfd , void* vptr , size_t n)
{
char* ptr = vptr; // 指向 vptr
size_t nleft = n; // 剩余的字节数量
size_t nread;
while(nleft > 0){
if((nread = read(sockfd , ptr , nleft)) < 0){
if(errno == EINTR){
nread = 0;
} else {
return -1;
}
} else if(nread == 0){
// 表示读完了
break;
}
nleft -= nread;
ptr += nread; // 进行偏移防止覆盖
}
return n - nleft;
}
- 关于
static关键字的介绍: https://blog.csdn.net/xiaozhiwise/article/details/111871556
端口复用函数
setsockopt函数
- 作用: 可以用于实现端口复用
- 函数原型:
int setsockopt(int sockfd, int level, int optname,
const void optval[.optlen],
socklen_t optlen);
- 使用方法:
int opt = 1setsockopt(sockfd , SOL_SOCKET , SO_REUSEADDR , (void*)&opt , sizeof(opt))
- 直接使用以上代码就可以进行代码复用
int opt = 1;
setsockopt(lfd , SOL_SOCKET , SO_REUSEADDR , (void*)&opt , sizeof(opt));
Libevent库
- 优点:
- 开源,精简,跨平台,专注与网络通信
- 安装源码包的步骤(参考
Readme文档):./configure: 检查安装环境,生成makefilemake: 生成.o和可执行文件sudo make install: 将必要的资源cp到系统指定的目录下
- 最好查看
readme查看安装方法 - 如果无法连接可以把
/usr/local/lib路径加入到/etc/ld.so.conf中 - 注意
/usr/local/lib是用户级的目录,安装的库都会放在这一个目录下,几个库目录的区别: https://blog.csdn.net/chengfenglee/article/details/113964247 .a表示静态库.so表示动态库
Libevent封装的框架思想
- 一般对于一个事件的监听设置方式如下(对于普通事件):
- 创建
event_base(event_base_new) - 创建事件:
event(event_new(base , fd , what , cb , arg)) - 将事件添加到
base上 (event_add(event , timeval)) - 循环监听事件满足 (
event_base_dispatch(base)) - 释放
event_base(event_base_free(base))
- 创建
event_base可以使用event_base_new函数,函数原型和使用方式如下:
// 函数原型:
struct event_base* event_base_new(void);
// 使用方式
struct event_base* event_base = event_base_new();
- 释放
event_base使用event_base_free函数,函数原型和使用方法如下: - 创建事件可以使用
event_new()函数,如果需要创建带缓冲区的事件,可以使用bufferevent_socket_new()函数,函数原型如下:
struct event* event_new(struct event_base* base , evutil_socket_t fd , short what , event_callback_fn cb , void* arg);
- 添加事件可以使用
event_add函数,函数原型如下:
int event_add(struct event& ev , const struct timeval* tv);
- 循环监听函数可以使用 ,
event_base_dispatch函数,函数原型如下:
int event_base_dispatch(struct event_base* base);
Libevent库例程分析
- 选取
sample中的hello-world.c进行分析 - 注意编译使用
libevent库需要使用-l event连接动态库,此时编译器默认包含头文件的路径中就包含了安装库的路径,所以不用指定包含头文件的路径 - 头文件在
/usr/local/include中,一般来说安装的库或者软件一般都在/usr/local目录下,这一个目录下存放着库文件头文件等 Libevent库: 基于事件的异步通信模型(主要依赖于回调机制)
框架中不常用的函数
- 启动循环使用:
event_base_dispatch(struct event_base* base)函数(相当于普通的利用IO多路复用中的循环)- 参数:
event_base_new函数的返回值- 成功返回
0, 失败返回-1
- 只有
event_new中指定了EV_PERSIST才可以触发,否则触发一次,就会跳出循环,通常这样:EV_WRITE | EV_PERSIST)或者EV_READ|EV_PERSIST
- 参数:
- 其他循环:
- 在指定时间之后停止循环:
int event_base_loopexit(struct event_base* base , const struct timeval *tv) - 立刻跳出循环:
int event_base_loopbreak(struct event_base* base)
- 在指定时间之后停止循环:
- 查看支持那些多路
IO:cosnt char** event_get_supported_methods(void) - 查看当前使用的多路
IO:const char* event_base_get_method(const struct event_base* base) - 查看
fork之后子进程使用的event_base:int event_reinit(struct event_base* base)使用该函数之后,父创建的base才可以在子进程中生效(子进程复制父进程中的base,需要调用这一个函数才可以使得子进程中的base生效) - 注意头文件:
<event2/event.h>
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/socket.h>
#include<event2/event.h>
int main()
{
// 演示不常用函数
// 表示创建一个新的 struct_event_base
struct event_base* base = event_base_new();
const char** buf = event_get_supported_methods();
int i = 0;
while(buf[i] != NULL){
printf("%s \n" , buf[i]);
i ++;
}
const char* now = event_base_get_method(base);
printf("%s \n" , now);
}
创建事件
- 作用: 创建事件
- 函数原型:
struct event* event_new(struct event_base* base , evutil_socket_t fd , short what , event_callback_fn cb , void* arg);
- 参数:
base: 表示struct event_base*对象fd: 表示需要监听事件对应的套接字的文件描述符what: 表示监听的事件类型,比如 读 写 异常,可以取得的值如下:EV_READ一次读事件EV_WRITE一次写事件EV_PERSIST表示持久化EV_ET表示边缘触发
event_call_fn cb: 表示事件发生之后的回调函数(以一旦事件满足监听条件就会调用这一个回调函数)- 回调函数:
typedef void(*event_callback_fn)(evuntil_socket_t fd , short , void*);
arg: 表示回调函数的参数- 返回值:
- 成功创建的事件对象
事件操作
event_add
- 作用: 添加事件到
base上 - 函数原型:
int event_add(struct event* ev , const struct timeval* tv);
- 参数:
ev:event_new()函数返回的事件对象tv: 为NULL,不会超时,意思为: 一直等到事件被触发,回调函数就会被调用(阻塞),如果为非0,等待期间事件没有被触发,时间到了,回调函数依然会被调用(定时触发)
event_free
- 作用: 释放事件
- 函数原型:
int event_free(struct event* ev);
- 返回值:
- 成功:
0 - 失败:
-1
- 成功:
event_del(一般不使用)
- 作用: 将事件从
base上面拿下来 - 函数原型:
int event_del(struct event* ev);
ev:event_new()函数返回的事件
使用fifo的读写
- 使用
Libevent完成fifo的读写: - 注意事件的含义,比如
EV_READ以及epoll中描述事件的符号都是表示文件可以怎么样,比如文件中有数据就表示可以读,文件有写的权限就表示可以写 - 比如利用
libevent库监听fifo的读事件:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<sys/socket.h>
#include<event2/event.h>
#include <sys/types.h>
#include<fcntl.h>
#include <sys/stat.h>
#include<ctype.h>
#define FIFO_NAME "myfifo"
void sys_exit(const char* msg)
{
perror(msg);
exit(1);
}
void read_from_fifo(int fd , short whar , void* arg)
{
char buf[BUFSIZ];
int ret = read(fd , buf , sizeof(buf));
if(ret == 0){
perror("the fifo is closed !");
} else if(ret == -1){
perror("read from fifo failed !");
} else if(ret > 0){
for(int j = 0 ; j < ret ; j ++){
buf[j] = toupper(buf[j]);
}
write(STDOUT_FILENO , buf , ret);
}
}
int main()
{
// 1. 首先创建有名管道
unlink(FIFO_NAME);
mkfifo(FIFO_NAME , 0644);
// 2. 打开管道,获取文件描述符
int fd = open(FIFO_NAME , O_RDONLY | O_NONBLOCK);
if(fd == -1) sys_exit("open the file failed !!!");
// 3. 创建 event_base 对象
struct event_base* base = event_base_new();
// 4. 创建事件对象
struct event* event = event_new(base , fd , EV_READ | EV_PERSIST , read_from_fifo , NULL);
// 5. 添加事件到 base上
event_add(event , NULL); // 表示阻塞
// 6. 启动事件循环
event_base_dispatch(base); // 底层调用 epoll 执行事件循环
// 释放资源
event_free(event);
event_base_free(base);
close(fd);
}
- 利用
libevent库监听fifo的写事件:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/socket.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<event2/event.h>
#include<fcntl.h>
#define FIFO_NAME "myfifo"
char buf[BUFSIZ];
void sys_exit(const char* msg)
{
perror(msg);
exit(1);
}
void write_to_fifo(int fd , short what , void* arg)
{
// 写入到缓冲区中
scanf("%s" , buf);
write(fd , buf , strlen(buf));
memset(buf , '\0' , sizeof(buf));
}
int main()
{
// 1. 首先打开
int fd = open(FIFO_NAME , O_WRONLY);
if(fd == -1){
sys_exit("open the file failed !");
}
// 2. 创建 event_base对象
struct event_base* base = event_base_new();
// 3. 创建事件对象
struct event* ev = event_new(base , fd , EV_WRITE | EV_PERSIST , write_to_fifo , NULL);
// 4. 插入事件
event_add(ev , NULL);
// 5. 事件循环
event_base_dispatch(base);
// 6. 释放资源
event_free(ev);
event_base_free(base);
close(fd);
}
- 注意由于
libevent库都是基于epoll+ET模式 +void* ptr实现的epoll反应堆,所以读取文件必须使用非阻塞模式(前面有提到) - 注意管道中的数据只是可以单向流动,半全双工
- 梳理脉络顺序:
- 首先获取文件描述符号
- 创建
event_base对象:event_base_new方法 - 创建事件对象:
event_new(base , fd , what , cb , arg) - 插入事件:
event_add(event , NULL) - 事件循环:
event_base_dispatch(base) - 最后进行资源的释放:
event_base_free,event_free,close
事件的未决和非未决
- 未决: 有资格被处理,但是还没有被处理
- 非未决: 没有资格处理
- 事件状态的转移:

bufferevent
- 用于套接字通信,可以用于网络,带有缓冲区
bufferevent特性
- 头文件:
<event2/bufferevent.h> - 原理:
bufferevent有两个缓冲区: 也是队列实现,读走没,先进先出- 读: 有数据 --> 读回调函数被调用 --> 使用
bufferevent_read()--> 读数据 --> 处理核心业务逻辑 --> 可以选择写回去 - 写: 使用
bufferevent_write()--> 向写缓冲中写数据 --> 该缓冲区中有数据自动写出 --> 写完,回调函数被调用(作用很小)(注意不是在写的回调函数中调用这一个方法)
- 读: 有数据 --> 读回调函数被调用 --> 使用
- 注意缓冲区的作用: https://aceld.gitbooks.io/libevent/content/7_bufferevent.html
- 对于写缓冲: 当有数据需要写入的时候,首先把数据写入到输入缓冲区,到了一定的时候就会刷新
- 对于读缓冲: 当需要从事件中读取数据的时候,首先从读缓冲中读取数据(有一个数据被放入读缓冲的时机)
bufferevent的相关操作
- 使用
bufferevent监听事件的读写行为的方式如下(基本和event一样,基本上没有用):- 获取文件描述符
- 创建
event_base对象 - 创建
bufferevent对象 - 将
bufferevent对象挂载到event_base中使用event_add - 启动事件循环监听
- 释放资源
bufferevent_socket_new函数
- 作用: 创建
bufferevent对象(fd可以使用一般方式获取或者可以通过bufferevent_new_bind函数中回调函数的参数获取) - 函数原型:
struct bufferevent* bufferevent_socket_new(struct event_base* base , evutil_socket_t fd , enum bufferevent_options options);
- 函数参数:
base: 表示event_base对象fd: 跟fd绑定的文件描述符,类比(event_new())options:BEV_OPT_CLOSE_ON_FREE只用这一个就可以了(释放bufferevent的时候关闭底层传输接端口,这将要关闭底层套接字,释放底层的bufferevent等)
- 返回值: 返回一个成功创建的
bufferevent事件对象,包含文件描述符
bufferevent_free函数
- 作用: 释放
bufferevent对象 - 函数原型:
void bufferevent_free(bufferevent* ev);
- 参数: 表示
event对象 - 返回值: 无
给bufferevent对象设置回调
-
libevent库中都是通过回调函数的方法设置回调,对比event -
bufferevent_setcb函数
-
作用: 给
bufferevent对象设置回调函数 -
注意
bufferevent_socket_new函数用于初始化bufferevent并且绑定文件描述符,同时结合buffer_setcb设置回调函数,这两个函数共同完成event_new函数的作用 -
函数原型:
void bufferevent_setcb(struct bufferevent* bufev , bufferevent_data_cb readcb , bufferevent_data_cb writecb , bufferevent_event_cb eventcb , void* cbarg);
- 参数:
bufev: 表示bufferevent对象readcb: 表示设置bufferevent读缓冲对应回调函数(read_cb(bufferevent_read()读取数据))writecb: 设置bufferevent写缓冲,对应回调write_cb()-- 作用就是给调用者发送成功写通知,可以设置为NULLeventcb: 表示事件回调,如果不想要拿到状态或者异常,也可以传递(NULL)cbarg: 表示回调函数的参数
readcb对应的回调函数:
typedef void(*bufferevent_data_cb)(struct bufferevent* bev , void* ctx);
// 读回调函数中需要调用 bufferevent_read 函数进行书籍的读取
- 读取和写入缓冲区的函数:
// 通常在 读回调函数中代替 read()函数
// 表示从缓冲区中读取数据,相当于底层向缓冲区中写入数据,外界进行读取(其实这里就是指的socket中的缓冲区,外界需要读取,那么就需要放数据到读缓冲中)
size_t bufferevent_read(struct bufferevent* bufev , void* data , size_t size);
// 需要从缓冲区中拿出数据,所以需要设置数据类型未 const char*,此时需要从写缓冲中拿出数据进行刷新,从数据源中拿出数据所以数据不可以被修改(注意写回调函数表示这一个函数把数据写入到写缓冲区之后,自动把写缓冲区中的数据同步到对方的socket指向的文件中)
int bufferevent_write(struct bufferevent* bufev , const void* data , sizet_t size);
typedef void(*bufferevent_event_cb)(struct bufferevent* bev , short events , void* ctx);
events: 不同的标志位,代表不同的事件:EV_EVENT_READING: 读取操作时发生某事件,具体是那一种事件还需要看其他的标志BEV_EVENT_WRITING: 写入操作的时候发生某一个事件,具体是那一种事件请看其他情况BEV_EVENT_ERROR: 操作时发生错误,关于错误的更多信息,请调用EVUTIL_SOCKET_ERROR()BEV_EVENT_TIMEOUT: 发生超时BEV_EVENT_EOF: 遇到文件结束指令BEV_EVENT_CONNECTED: 请求的连接过程已经完成,实现客户端可用
- 表示遇到异常的时候的处理方式(作用就是捕捉异常)
缓冲区的开启和关闭
- 缓冲区存在的好处: 可以实现半关闭,可以实现三次握手,四次挥手
- 默认: 新建的
bufferevent写缓冲是enable的,读缓冲是disable的 - 可以使用
bufferevent_enable启动缓冲区,函数原型如下:
// 通常使用这一个函数启动bufferevent的read缓冲
void bufferevent_enable(struct bufferevent* bufev , short events); // 启动缓冲区
- 可以使用
buffer_disable函数关闭缓冲,函数原型如下:
void bufferevent_disable(struct bufferevent* bufev , short events); // 禁止使用
events可取值:EV_READEV_WRITEEV_READ | EV_WRITE
- 还可以使用
bufferevent_get_enabled函数获取禁用状态:
// 获取缓冲区的禁用状态,需要使用 & 进行辅助
short bufferevent_get_enabled(struct bufferevent* bufev);
利用bufferevent实现TCP通信
客户端和服务端通信流程
bufferevent_socket_connect函数
- 作用: 类似于
Socket编程中的connect函数,用于连接服务器端 - 函数原型:
int bufferevent_socket_connect(struct bufferevent* bev , struct sockaddr* address , int addrlen);
- 参数:
bev: 表示bufferevent函数(利用buffer_socket_new和buffer_set_cb创建)address: 相当于服务器端的IP + portaddrlen: 表示地址的长度
evconnlistener_new函数
- 作用: 创建一个
evconnlistener对象(其实本身没有什么用)
evconnlistener_new_bind函数(很重要)
- 作用: 相当于
socket,listen,bind,accept这几个函数的作用 - 函数原型如下:
struct evconnlistener* evconnlistener_new_bind(
struct event_base* base,
evconnlistener_cb cb,
void* ptr,
unsigned flags,
int backlog,
const struct sockaddr* sa,
int socklen
)
- 参数说明:
base: 表示event_base对象cb: 监听回调函数,接受连接之后,用户需要做的操作flags: 可以识别的标志:LEV_OPT_CLOSE_ON_FREE: 释放bufferevent的时候关闭底层传输接口,这将会关闭底层套接字,释放底层bufferevent等LEV_OPT_REUSEABLE: 端口复用,可以使用|
backlog: 表示最大连接数量sa: 表示服务器的IP + portsocklen: 表示sa的大小
- 返回值:
eventconnlistener对象(表示事件监听器) - 回调函数类型:
typedef void (*evconnlistener_cb)(struct evconnlistener *listener,
evutil_socket_t sock, struct sockaddr *addr, int len, void *ptr);
- 参数:
listener: 表示evconnlistener对象sock: 表示套接字fd号addr: 表示地址结构len: 表示addr的大小ptr: 表示创建evconnlistener是用户传递进入的参数,可以当成函数的参数
- 回调函数不用自己调用,由框架自动调用,其中可以完成读写操作
服务器端TCP通信实现流程
- 步骤分析:
-
利用
event_base_new函数创建event_base对象 -
创建服务器连接监听器(
evconnlistener_new_bind()) -
在
evconnlistener_new_bind绑定的回调函数中处理接受连接之后的事情 -
回调函数被调用,说明有一个客户端连接上来了,会得到一个新的
cfd,用于和客户端进行通信(读,写) -
使用
bufferevent_socket_new创建一个新的bufferevent对象,将fd封装到这一个对象中(回调函数中需要做的事情) -
使用
buffer_setcb设置回调函数 -
设置
bufferevent的读写缓冲区开启或者关闭 -
接受发送数据
bufferevent_read(),bufferevent_write() -
启动循环监听
-
释放资源
-
服务器端的代码实现(其中
read_cb和write_cb函数是bufferevent_setcb中的回调函数,并且listen_call_back是bufferevent_socekt_bind函数的回调函数,用于监听listenfd:(联连接事件)
-
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<fcntl.h>
#include<event2/bufferevent.h>
#include<event2/event.h>
#include <event2/listener.h>
#include<sys/socket.h>
#include<ctype.h>
#define SERV_PORT 10086
char buf[BUFSIZ];
void read_cb(struct bufferevent* bev , void* ctx)
{
// 调用读函数 bufferevent_read 函数,表示从读缓冲中读取数据
int n = bufferevent_read(bev , buf , sizeof(buf));
// 开始读取信息
for(int i = 0 ; i < n ; i ++){
buf[i] = toupper(buf[i]);
}
// 写回去,表示向写缓冲中写出数据,自动发送消息
bufferevent_write(bev , buf , n);
}
void write_cb(struct bufferevent* bev , void* ctx)
{
printf("Successfully write message to client !\n");
}
// 设置回调函数
void listen_call_back(struct evconnlistener* listener , evutil_socket_t sock , struct sockaddr* addr , int len , void* ptr)
{
printf("client comes !!!\n");
// 利用 sock 绑定读写回调函数
struct bufferevent* bufferevent = bufferevent_socket_new((struct event_base*)ptr , sock , BEV_OPT_CLOSE_ON_FREE);
// 进行回调函数的绑定
// 打开缓冲区
bufferevent_enable(bufferevent , EV_READ | EV_WRITE);
bufferevent_setcb(bufferevent , read_cb , write_cb , NULL , NULL);
}
int main()
{
// 1. 首先创建 event_base
struct event_base* base = event_base_new();
// 2. 利用evconnlistener_new_bind 函数进行数据对象的绑定
// 2.1 初始化地址结构
struct sockaddr_in server_addr;
memset(&server_addr , 0 , sizeof(server_addr));
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERV_PORT);
struct evconnlistener* listener = evconnlistener_new_bind(base , listen_call_back , base , LEV_OPT_CLOSE_ON_FREE | LEV_OPT_REUSEABLE , 128 ,
(struct sockaddr*)&server_addr , sizeof(server_addr));
// 事件循环
event_base_dispatch(base);
// 释放资源
event_base_free(base);
evconnlistener_free(listener);
}
- 还是需要数理流程:
- 首先创建
event_base对象 - 创建
server_addr对象并且使用evconnlistener_new_bind方法进行地址和端口的绑定以及lfd回调函数的绑定(注意把base当成参数传入,创建套接字的时候需要) - 回调函数中调用
buffervent_socket_new创建bufferevent对象 - 调用
bufferevent_setcb方法设置读写回调函数 - 利用
bufferevent_enable函数使能读写缓冲区 - 读回调函数中处理相关的逻辑,比如利用
bufferevent_read读取数据,利用bufferevent_write写出数据到写缓冲中,数据自动同步到客户端的socket中 - 设置读回调函数(没有什么用处)
- 调用事件循环(
event_base_dispatch) - 释放资源
- 首先创建
客户端代码实现
- 代码实现如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<event2/bufferevent.h>
#include<event2/listener.h>
#include<sys/socket.h>
#define SERV_PORT 10086
char buf[BUFSIZ];
void read_cb(struct bufferevent* event , void* ctx)
{
// 读取数据
int n = bufferevent_read(event , buf , sizeof(buf));
write(STDOUT_FILENO , buf , n);
}
void write_cb(struct bufferevent* event , void* ctx)
{
printf("receive data from server !\n");
}
void read_terminal(evutil_socket_t fd , short what , void* ptr)
{
int len = read(fd , buf , sizeof(buf));
bufferevent_write((struct bufferevent*)ptr , buf , len + 1);
}
int main()
{
// 1. 首先创建 event_base 对象
struct event_base* base = event_base_new();
// 2. 利用 bufferevent_socket_new 创建
// 获取 socket
int sock = socket(AF_INET , SOCK_STREAM , 0);
struct bufferevent* bev = bufferevent_socket_new(base , sock , BEV_OPT_CLOSE_ON_FREE);
// 3. 利用 bufferevent_socket_connect 连接服务器
struct sockaddr_in server_addr;
memset(&server_addr , 0 , sizeof(server_addr));
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERV_PORT);
bufferevent_socket_connect(bev , (struct sockaddr*)&server_addr , sizeof(server_addr));
// 4. 利用 bufferevent_setcb 设置回调函数
bufferevent_enable(bev , EV_READ);
bufferevent_setcb(bev , read_cb , write_cb , NULL , NULL);
// 设置另外的回调函数
struct event* ev = event_new(base , STDIN_FILENO , EV_READ | EV_PERSIST , read_terminal , bev);
event_add(ev , NULL);
// 设置事件循环
event_base_dispatch(base);
// 释放数据
event_base_free(base);
event_free(ev);
close(sock);
}
- 注意: 不要再读回调中首先调用
bufferevent_write函数,否则容易引发报错 - 梳理流程:
- 首先利用
event_base_new创建event_base - 利用
socket获取fd,利用bufferevent_socket_new获取bufferevent对象 - 利用
bufferevent_socket_connect连接客户端(底层应该做了事件绑定) - 利用
bufferevent_setcb设置各种回调函数 - 利用
event_base_dispatch进行事件回调 - 最后释放各种资源
- 总结一下:
libevent库基于事件驱动,可以对于各种事件的各种行为进行监听,对于网络套接字的读写事件,可以监听普通事件,所以对于各种事件使用libevent库处理十分方便 - 比如可以使用监听标准输入输出读写的方式来进行监听读写事件
高并发服务器
- 高并法服务器分析:

多进程并发服务器
分析
- 一个服务器进程中,首先利用
socket()创建一个lfd,当有客户端尝试连接的时候,这一个lfd就会结合accept函数创建一个cfd,利用这一个cfd和服务器端进行通信,并且之后来了更多的客户端尝试连接,lfd也只有一个,而是不断创建cfd - 实现思路分析:
socket()创建,监听套接字lfdBind()绑定地址结构struct sockaddr_inListen()- 循环利用
accept进行接受,接受之后fork()子进程 - 子进程处理业务逻辑(注意子进程中需要关闭用于建立连接的套接字)
- 父进程继续监听客户端的连接,同时关闭用于和客户端进行通信的套接字
- 父进程可以注册捕捉信号函数从而回收子进程
实现
#include "wrap.h"
#include<ctype.h>
#include<signal.h>
#include<sys/wait.h>
#define SERVER_PORT 10086
// 利用信号进行子进程的回收
void resource_handler(int signal)
{
// 循环进行子进程的回收
int n ;
while((n = waitpid(-1 , NULL , 0)) != -1){
// 进行挥手
printf("child whose pid is %d is resouced ! \n" , n);
}
}
int main()
{
// 利用进程实现的并发服务器
// 1. 利用 Socket 获得 lfd
int lfd , cfd;
int pid;
char buf[BUFSIZ] , client_IP[BUFSIZ]; // 表示读写使用的缓冲区
lfd = Socket(AF_INET , SOCK_STREAM , 0);
// 2. 利用 bind 绑定 IP 和 port
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(SERVER_PORT);
Bind(lfd , (struct sockaddr*)&addr , sizeof(addr));
// 3. 利用 Listen 设置最大监听数量
Listen(lfd , 128);
// 4. 循环使用 accept 进行接受
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
// 进行信号的屏蔽
sigset_t sig;
sigemptyset(&sig);
sigaddset(&sig , SIGCHLD);
sigprocmask(SIG_BLOCK , &sig , NULL);
printf("等待客户端连接 ... \n");
while(1){
cfd = Accept(lfd , (struct sockaddr*)& client_addr , &client_addr_len);
// fork函数调用
pid = fork();
// 开始判断操作
if(pid == 0){
// 子进程
printf("连接到客户端== addr: %s , port: %d \n" , inet_ntop(AF_INET , (void*)&(client_addr.sin_addr.s_addr) , client_IP , client_addr_len) , ntohs(client_addr.sin_port));
while(1){
// 读取信息
int n = read(cfd , buf , sizeof(buf));
// 进行大小写转换
if(n > 0){
for(int i = 0 ; i < n ; i ++){
buf[i] = toupper(buf[i]);
}
// 写回去
write(cfd , buf , n);
} else if (n == 0){
break;
} else if(n == -1){
perror("read from socket failed !");
exit(1);
}
}
close(cfd);
} else if(pid > 0){
// 父进程
// 注册行为
struct sigaction act;
act.sa_handler = resource_handler;
act.sa_flags = 0;
sigemptyset(&act.sa_mask);
sigaction(SIGCHLD , &act , NULL);
// 取消阻塞
sigset_t cancel_sig;
sigemptyset(&cancel_sig);
sigaddset(&cancel_sig , SIGCHLD);
sigprocmask(SIG_UNBLOCK , &cancel_sig , NULL);
close(cfd);
continue;
}
}
close(lfd);
}
多线程并发服务器
- 分析:
-
Socket()创建套接字 -
Bind() -
Listen() -
接受请求,同时创建子线程
-
同时调用
pthread_detact分离子线程让子线程被系统回收 -
如果还是需要使用
pthread_join进行线程的回收,就可以创建一个子线程来回收其他的子线程注意这里线程之前共享文件描述符表(其实线程就是栈和寄存器的集合),所以如果在任何一个线程中关闭某一个文件描述符号都会都是之后的负责读写的线程受到影响
-
实现
- 多线程变成服务器实现:
- 为什么这里不可以使用值传递的方式进行参数传递,这是由于
void*只会占用8个字节,但是需要的结构体大小比较大
#include "wrap.h"
#include<pthread.h>
#include<ctype.h>
#define SREVER_PORT 18001
#define MAX_SIZE 128
struct client_info{
struct sockaddr_in client_addr;
int conn_fd;
};
struct client_info clients[256]; // 记录客户端的信息
pthread_t thread_to_resource[128];
char client_Buf[BUFSIZ];
void* client_handler(void* arg)
{
struct client_info* client_addr_info = (struct client_info*)arg;
char buf[BUFSIZ];
printf("连接到客户端: %s:%d \n" , inet_ntop(AF_INET , (void*)&(client_addr_info -> client_addr.sin_addr.s_addr), client_Buf , sizeof(client_Buf)) , ntohs(client_addr_info -> client_addr.sin_port));
int n;
while(1){
// 接受数据
n = read(client_addr_info -> conn_fd , buf , sizeof(buf));
if(n == -1){
perror("read from socket failed !");
pthread_exit(NULL);
} else if(n > 0){
for(int i = 0 ; i < n ; i ++){
buf[i] = toupper(buf[i]);
}
write(client_addr_info -> conn_fd , buf , n);
} else if (n == 0){
break;
}
}
close(client_addr_info -> conn_fd);
return NULL;
}
// 回收线程
void* thread_handler(void* arg)
{
int i = 0;
int wpid;
while(1){
if(thread_to_resource[i] != 0){
wpid = pthread_join(thread_to_resource[i] , NULL);
printf("Successfully resource thread pid = %d \n" , thread_to_resource[i]);
thread_to_resource[i] = 0;
}
i = (i + 1) % MAX_SIZE;
}
return NULL;
}
int main()
{
pthread_t pid;
int lfd , cfd;
// 1. 利用 Socket 获取 lfd
lfd = Socket(AF_INET , SOCK_STREAM , 0);
// 2. 利用 Bind 进行 IP 地址和 port 的绑定
struct sockaddr_in server_addr;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SREVER_PORT);
server_addr.sin_family = AF_INET;
Bind(lfd , (struct sockaddr*)& server_addr , sizeof(server_addr));
// 3. 利用 Listen 设置最大监听数量
Listen(lfd , 128);
// 4. 利用 Accept 函数循环接受结果
int i = 0;
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
while(1){
// 封装信息
cfd = Accept(lfd , (struct sockaddr*)&client_addr , &client_addr_len);
clients[i].client_addr = client_addr;
clients[i].conn_fd = cfd;
// 创建子线程
pthread_create(&pid , NULL , client_handler , (void*)&clients[i]);
thread_to_resource[i] = pid; // 进行回收
if(i == 0){
// 开启回收线程
pthread_create(&pid , NULL , thread_handler , NULL);
pthread_detach(pid);
}
i ++;
}
return 0;
}
read函数的返回值
read函数的返回值:> 0实际读取到的字符= 0已经读取到了结果-1需要进一步判断errno的值:errno = EAGAIN or errno = EWOULDBLOCK: 设置了非阻塞法嗯时读,没有数据到到errno = EINTR慢速系统调用,中断errno = ECONNRESET表示连接被重置,需要重新建立连接errno = 其他情况发生异常
多路IO转接服务器(多路IO复用)
- 客户端和服务器端建立连接的三种方式:
- 阻塞(比如调用
Accept函数阻塞等待客户端申请与服务器端建立连接) - 非阻塞式忙轮询:相当于服务器端过一段时间监听一下客户端的状态,等待客户端的连接
- 响应式(也叫做多路
IO转接): 表示客户端主动和服务器端建立连接,服务器不用等待客户端
- 阻塞(比如调用
- 之后的
select,poll还有epoll都是使用响应式的方式 - 响应式的实现方式(
select):
- 分析以下服务器端和客户端利用
select建立连接的过程:- 首先
server服务器调用Socket函数和Bind还有Listen函数绑定对应的参数之后把得到的listenfd交给select - 当有客户端需要连接服务器的时候,首先利用
select的listenfd建立连接 - 当有客户端和
select连接的时候,此时select会通知server,此时server服务器就会调用Accept函数获取connfd之后转交给select和客户端进行数据的交换
- 首先
select 函数
- 作用: 完成多路
IO转接 - 头文件:
#include <sys/select.h> - 函数原型如下:
int select(int nfds, fd_set *_Nullable restrict readfds,
fd_set *_Nullable restrict writefds,
fd_set *_Nullable restrict exceptfds,
struct timeval *_Nullable restrict timeout);
- 参数:
nfds: 表示select管理的最大的一个文件描述符的最大值+ 1(底层会利用循环遍历文件描述符)readfds,writefds,exceptfds都是传入传出参数timeout: 表示等待时长
- 类型:
fd_set表示一种集合(本质就是一个位图),readfds,writefds,exceptfds表示三种不同的事件,反别表示读事件,写事件和异常事件,意思就是监听某一个文件集合(比如readfds = 4 5 writefds = 5 6 exceptfds = 7 8表示监听4号和5号的读事件,监听5号和6号的写事件,还有7号和8号的异常事件) - 但是由于这三个参数都是传入传出参数,传入的意义: 需要监听相应事件的文件描述符号集合,传出的意义: 被监听的文件描述符号集合中发生了相应事件的文件描述符组成的集合
timeout: 表示过期事件,如果传入一个NULL表示阻塞状态,0表示非阻塞状态(轮询状态)- 返回值:
- 成功返回三个结合中的文件描述符号的总个数,失败返回
-1设置errorno(0有可能是在文件描述符的状态改变之前超出过期时间)
- 成功返回三个结合中的文件描述符号的总个数,失败返回
对于fd_set的操作函数
- 作用: 操作
fd_set(本质上就是位图) - 函数原型:
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
FD_CLR: 表示把某一个fd置为0(表示把某一个fd从监听列表中去除,应用场景比如客户端关闭套接字(read返回值为0))FD_ISSET: 表示判断fd是否在某一个位图中FD_SET: 表示添加fd到这一个位图中FD_ZERO: 表示把位图中的为都置为0- 总结一下
select函数的参数:nfds: 监听到的所有文件描述符中,最大的文件描述符readfds: 读文件描述符监听集合 传入传出参数writefds: 写文件描述符监听集合 传入传出参数,一般设置为NULLexceptfds: 异常文件描述符监听集合 传入传出结合NULLtimeout:> 0: 设置监听超时时长NULL: 阻塞监听0: 非阻塞监听,轮询
- 返回值:
> 0: 所有监听集合(3个)中,满足对应事件的总数0: (超出过期时间)没有满足条件的文件描述符-1: 表示发生异常
select 实现多路IO转接思路
- 思路分析:
- 利用
socket()创建listenfd - 调用
bind()绑定IP + port - 调用
listen()设置最大连接数量 - 创建读监听集合
FD_ZERO(&rset)清空读监听集合FD_SET(lfd , &set)把listenfd添加到集合中- 调用
select监听文件描述符集合(readfd)对应的事件(过程中rset会发生改变只会得到发生了对应事件的文件描述符号,所以需要使用allset记录所有的文件描述符号) - 判断文件描述符号监听列表中是否存在
listenfd - 如果存在
listenfd,那么就需要把调用accept得到cfd,同时可以把cfd添加到集合中 - 循环遍历得到发生了读取事件的文件描述符,向发生了读文件描述符号(表示可读)中读出数据同时进行业务操作写回去即可(其实真实的网络应用场景中,还是需要效仿
epoll反应堆模型,判断是否可读)
- 利用
- 可以设置一个变量专门用于记录文件描述符号的最大值,可以不断更新最大文件描述符
- 利用
select实现多路IO转接:
#include "wrap.h"
#include<sys/select.h>
#include<ctype.h>
#define SERVER_PORT 10086
int main()
{
// 利用 select 实现 IO 多路转接
// 1. 利用 Socket 获取 lfd
int lfd , cfd , n;
lfd = Socket(AF_INET , SOCK_STREAM , 0);
// 2. 利用 Bind 绑定 端口和 IP
struct sockaddr_in server_addr;
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVER_PORT);
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
Bind(lfd , (struct sockaddr*)&server_addr , sizeof(server_addr));
// 3. 利用 Listen 设置最大连接数量
Listen(lfd , 128);
// 4. 交给 select 管理 lfd
int max_fd = lfd; // 表示最大的文件描述符号
fd_set rset , allset; // allset 用于记录所有需要监听的文件描述符号,rset作为函数参数
FD_ZERO(&allset);
FD_SET(lfd , &allset);
int ret; // 记录 accept结果
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
char buf[BUFSIZ] , client_IP[BUFSIZ];
printf("等待客户端连接... \n");
while(1){ // 循环监听
rset = allset; // 每一次赋值
ret = select(max_fd + 1 , &rset , NULL , NULL , NULL);
// 开始判断
if(ret > 0){
if(FD_ISSET(lfd , &rset)){
// 表示监听到客户端连接
cfd = Accept(lfd , (struct sockaddr*)&client_addr , &client_addr_len);
if(cfd > max_fd) max_fd = cfd;
// 记录最大的文件描述符号个数
// 打印信息
printf("连接到客户端: %s:%d \n" , inet_ntop(AF_INET , (void*)&(client_addr.sin_addr.s_addr) , client_IP , client_addr_len) , ntohs(client_addr.sin_port));
FD_SET(cfd , &allset);
if(--ret == 0){
continue; // 表示此时 lfd 还是可以读取所以需要继续执行后面的操作,后面的for循环可以不用操作
}
}
// 开始判断其他文件描述符号
for(int i = lfd + 1 ; i <= max_fd ; i ++){
if(FD_ISSET(i , &rset)){
// 表示监听到事件
n = read(i , buf , sizeof(buf));
if(n > 0){
for(int j = 0 ; j < n ; j ++){
buf[j] = toupper(buf[j]);
}
write(i , buf , n);
} else if(n == 0){ // 表示客户端关闭
close(i);
FD_CLR(i , &allset);
}
}
}
} else if(ret == -1){
perror("select failed !");
exit(1);
}
}
close(lfd);
}
select优缺点
- 缺点:
- 如果文件描述符的跨度比较大就会导致使用轮询的方式会浪费比较多的时间
- 监听上限受到文件描述符最大值的限定
- 检验满足条件的
id,自己添加业务逻辑提高小,提高了编码难度
- 优点:
- 唯一一个可以跨平台的多路
IO转接方式
- 唯一一个可以跨平台的多路
- 可以自定义数组(如果可以使用
vector更好)来改善select轮询的缺点 - 小知识点:
FD_SETSIZE表示文件描述符最大值,就是1024 - 改进代码如下:
#include"wrap.h"
#include<sys/select.h>
#include<ctype.h>
#define SERVER_PORT 10088
int main()
{
// 使用 select 完成多路 IO 转接
int lfd ,cfd , max_fd , maxi = -1 , sockfd;
int clients[FD_SETSIZE]; // 表示最大长度 1024
for(int i = 0 ; i < FD_SETSIZE ; i ++){
clients[i] = -1;
}
lfd = Socket(AF_INET , SOCK_STREAM , 0);
struct sockaddr_in server_addr;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVER_PORT);
Bind(lfd , (struct sockaddr*)&server_addr , sizeof(server_addr));
Listen(lfd , 128);
fd_set rset , allset; // 分别记录读的文件描述符号和所有的文件描述符
FD_ZERO(&allset);
FD_SET(lfd , &allset);
max_fd = lfd;
int ret;
char buf[BUFSIZ] , client_IP[BUFSIZ];
struct sockaddr_in client_addr;
socklen_t client_addr_len;
while(1){
rset = allset;
ret = select(max_fd + 1 , &rset , NULL , NULL, NULL); // 表示阻塞
if(ret > 0){
// 有信号发生改变
if(FD_ISSET(lfd , &rset)){
cfd = Accept(lfd , (struct sockaddr*)&client_addr , &client_addr_len);
printf("客户端连接: %s:%d \n" ,inet_ntop(AF_INET , (void*)&(client_addr.sin_addr.s_addr) , buf , sizeof(buf)) , ntohs(client_addr.sin_port));
if(cfd > max_fd){
max_fd = cfd;
}
// 加入到集合中
FD_SET(cfd , &allset);
// 此时可以进行初始化
int i;
for(i = 0 ; i <= FD_SETSIZE ; i ++){
if(clients[i] < 0){
clients[i] = cfd;
break;
}
}
if(i > maxi){
maxi = i; // 此时就可以记录最大值了
}
if(--ret == 0){
continue; // 表示只有 lfd 变化
}
}
// for(int i = lfd + 1 ; i <= max_fd ; i ++){
// if(FD_ISSET(i , &rset)){
// // 进行操作
// ret = read(i , buf , sizeof(buf));
// if(ret == 0){
// close(i);
// FD_CLR(i , &allset); // 表示结束了
// } else if(ret > 0){
// for(int j = 0 ; j < ret ; j ++){
// buf[j] = toupper(buf[j]);
// }
// write(i , buf , ret);
// }
// }
// }
// 开始循环读取 clients[i]
for(int j = 0 ; j <= maxi ; j ++){
if((sockfd = clients[j]) < 0){
continue;
}
// 进行下一步判断
if(FD_ISSET(sockfd , &rset)){
int n = read(sockfd , buf , sizeof(buf));
if(n == 0){
clients[j] = -1;
close(clients[j]);
FD_CLR(clients[j] , &allset);
} else if(n > 0){
for(int k = 0 ; k < n ; k ++){
buf[k] = toupper(buf[k]);
}
write(clients[j] , buf , n);
}
if(--ret == 0){
break; // 表示此时 lfd 没有发生变化此时只有一个 cfd 发生了变化那么处理完这一个cfd就可以了
}
}
}
} else if(ret == -1){
perror("select failed !");
exit(1);
}
}
}
- 注意为什么上面还是需要判断
ret这是由于文件描述符号处理之后检查是否还有没有处理的文件描述符,如果没有直接就可以退出了
poll函数
- 作用: 完成多路
IO转接(多路IO复用) - 头文件:
<poll.h> - 函数原型:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
- 其中
struct pollfd结构体如下:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
- 上面的成员分别表示:
fd表示需要监听的文件描述符events表示事件类型(可以传入POLLIN,POLLOUT,POLLERR)revents表示传出的事件类型(参数和上面一样)(传入的时候可以给0, 如果满足对应事件,返回非0(也就是上面的三种宏定义))
- 参数:
fds: 监听的文件描述符数组nfds: 表示监听数组的实际有效的监听个数timeout: 表示超时时长(单位就是毫秒):-1表示阻塞等待0表示不会阻塞线程,直接返回> 0表示指定等待的毫秒数,如果当前系统事件精度不够毫秒,就向上取值
- 返回值:
- 返回满足对应监听事件的文件描述符总个数
poll函数的工作过程
- 和
select函数的工作原理一模一样,不同的就是监听事件的初始化方式不同,在poll函数中需要定义一个数组来存放监听函数,存放完成之后循环读取并且从数组中取出监听元素即可,相当于select版本加上了一个数组 - 初始化过程如下:

利用poll函数实现多路IO转接
- 小知识:
INET_ADDRSTRLEN的大小就是16 - 其实
poll就是加上了数组的select(突破了文件描述符上限) read函数的返回值:> 0实际读取到的字符= 0已经读取到了结果-1需要进一步判断errno的值 :errno = EAGAIN or errno = EWOULDBLOCK: 设置了非阻塞法嗯时读,没有数据到到errno = EINTR慢速系统调用,中断errno = ECONNRSET表示连接重置,需要关闭连接
#include "wrap.h"
#include <poll.h>
#include<ctype.h>
#define SERVER_PORT 10089
int main()
{
// 利用 poll 函数实现多路IO转接
int lfd , cfd , count = 1 , maxi , ret , sockfd;
struct pollfd pollfds[1024];
lfd = Socket(AF_INET , SOCK_STREAM , 0);
struct sockaddr_in server_addr;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVER_PORT);
Bind(lfd , (struct sockaddr*)&server_addr , sizeof(server_addr));
Listen(lfd , 128);
// 进行 pollfds 的初始化
for(int i = 0 ; i < 1024 ; i ++){
pollfds[i].fd = -1;
}
// 初始化
pollfds[0].fd = lfd;
pollfds[0].events = POLLIN;
pollfds[0].revents = 0; // 初始化为 0
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
char buf[BUFSIZ] , client_IP[BUFSIZ];
while(1){
// 调用 poll函数
ret = poll(pollfds , count , -1);
// 首先判断 lfd 的事件
if(pollfds[0].revents & POLLIN){
// 此时就可以 Accept 了
cfd = Accept(lfd , (struct sockaddr*)&client_addr , &client_addr_len);
printf("客户端连接: %s:%d \n" , inet_ntop(AF_INET , (void*)&(client_addr.sin_addr.s_addr),client_IP, sizeof(client_IP)) , ntohs(client_addr.sin_port));
// 找到可以插入的位置
int i;
for(i = 0 ; i < 1024 ; i ++){
if(pollfds[i].fd < 0){
pollfds[i].fd = cfd;
pollfds[i].events = POLLIN;
pollfds[i].revents = 0;
break;
}
}
if(i > maxi){
maxi = i;
}
count ++;
if(--ret == 0){
continue;
}
}
// 开始进行一个遍历
for(int j = 0 ; j <= maxi ; j ++){
if((sockfd = pollfds[j].fd) < 0){
continue;
}
if(pollfds[j].revents & POLLIN){
// 此时就可以进行响应的操作了
int n = read(sockfd , buf , sizeof(buf));
if(n > 0){
// 进行相应的操作
for(int k = 0 ; k < n ; k ++){
buf[k] = toupper(buf[k]);
}
write(sockfd , buf ,n);
} else if(n == 0){
// 关闭
pollfds[j].fd = -1;
} else if(n == -1){
if(errno == ECONNRESET){
// 表示连接被重置
pollfds[j].fd = -1;
close(sockfd);
}
}
if(--ret == 0){
break; // 处理完毕
}
}
}
}
}
poll的优缺点
- 优点:
- 自带数组结构,可以把监听事件集合和返回事件集合分离
- 可以突破监听上限
- 缺点:
- 不可以跨平台,只能在
Linux中使用 - 无法直接定位直接满足监听事件的文件描述符,需要使用轮询的方式定位
- 不可以跨平台,只能在
突破1024文件描述符设置
- 利用:
cat /proc/sys/fs/file-max命令可以查看当前计算机可以打开的文件数量 ulimit -a可以查看当前用户下的进程,默认打开文件描述符的个数,缺省为1024(默认)- 修改
/etc/security/limits.conf文件 - 填写
soft和hard的值即可:
* soft nofile 3000 // 默认值
* hard nofile 20000 // 修改值上限
注意只有poll和epoll可以突破1024文件描述符上限,select函数不可以
epoll相关函数
epoll_create
- 作用: 打开一个
epoll文件描述符(epoll本质其实就是一个红黑树) - 函数原型:
int epoll_create(int size);
- 参数:
size: 创建的红黑树的监听节点数量(但是仅仅时对于内核的一个建议,并不是强制的)- 返回值:
- 成功的话返回一个指向红黑树根节点的文件描述符
- 失败返回
-1
epoll_ctl函数
- 作用: 控制红黑树
- 函数原型:
int epoll_ctl(int epfd, int op, int fd,
struct epoll_event *_Nullable event);
struct epoll_event结构体如下:
struct epoll_event {
uint32_t events; /* 事件 */
epoll_data_t data; /* 用到的数据变量 */
};
epoll_data_t如下:- 联合体的概念可以参考: https://blog.csdn.net/mooneve/article/details/92703036
union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
};
typedef union epoll_data epoll_data_t;
- 参数:
epfd:epoll对应的文件描述符号op: 表示对于红黑树的操作类型,可取值如下:EPOLL_CTL_ADD添加fd到监听红黑树EPOLL_CTL_MOD修改fd在监听红黑树上的监听事件EPOLL_CTL_DEL将fd从监听红黑树上摘下来(取消监听)
event(就只是一个结构体而已): 用于描述事件,成员如下:events: 可取值为EPOLLIN,EPOLLOUT,EPOLLERR等data: 是一个联合体:fd: 表示对应监听事件的fdvoid* pstrunit32_t(不用)uint64_t(不用)
- 返回值:
- 成功返回
0 - 失败返回
-1设置errno
- 成功返回
epoll_wait函数
- 作用: 阻塞监听
- 函数原型:
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
- 参数:
epfd: 表示epoll的文件描述符events: 数组,传出参数(需要监听的文件描述符号可以使用epoll_ctl指定),传出的都是满足条件的(监听到事件的)maxevents: 表示数组元素的总个数,类似于read函数中buf的长度timeout:-1阻塞0非阻塞> 0设置超时事件
- 返回值:
> 0满足监听的总个数(循环的遍历上限(数组中的都是满足条件的个数))0没有fd满足监听事件-1表示错误情况
利用epoll实现多路IO复用
- 实现方式如下:
- 注意
epoll_ctl中需要传入的结构体充当传入传出参数,所以需要指定文件描述符
#include "wrap.h"
#include<ctype.h>
#include<sys/epoll.h>
#define SERVER_PORT 10090
int main()
{
int lfd , cfd , epollfd , ret , sockfd;
struct epoll_event ep_events[BUFSIZ]; // 就是一个传出参数
char buf[BUFSIZ] , client_IP[BUFSIZ];
lfd = Socket(AF_INET , SOCK_STREAM , 0);
struct sockaddr_in server_addr;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVER_PORT);
Bind(lfd , (struct sockaddr*)&server_addr , sizeof(server_addr));
Listen(lfd , 128);
// 获取 epollfd
epollfd = epoll_create(BUFSIZ);
// 把 lfd 添加到 epoll中
struct epoll_event ep_event;
ep_event.events = EPOLLIN;
ep_event.data.fd = lfd;
epoll_ctl(epollfd , EPOLL_CTL_ADD , lfd , &ep_event);
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
printf("等待客户端连接 ...\n");
while(1){
ret = epoll_wait(epollfd , ep_events , BUFSIZ , -1);
if(ret > 0){
// 首先判断 ep_events
for(int i = 0 ; i < ret ; i ++){
// 如果是 lfd
if((sockfd = ep_events[i].data.fd) == lfd ){
// 调用 Accept函数
cfd = Accept(lfd , (struct sockaddr*)&client_addr , &client_addr_len);
printf("连接到客户端: %s:%d \n" , inet_ntop(AF_INET , (void*)&(client_addr.sin_addr.s_addr) , client_IP , sizeof(client_IP)) , ntohs(client_addr.sin_port));
// 添加到 epoll
ep_event.events = EPOLLIN;
ep_event.data.fd = cfd;
epoll_ctl(epollfd , EPOLL_CTL_ADD , cfd , &ep_event);
} else {
// 业务逻辑操作
int n = read(sockfd , buf , sizeof(buf));
if(n > 0){
for(int j = 0 ; j < n ; j ++){
buf[j] = toupper(buf[j]);
}
write(sockfd , buf , n);
} else if(n == 0){
// 关闭
close(sockfd);
epoll_ctl(epollfd , EPOLL_CTL_DEL , sockfd , NULL);
} else if(n == -1){
perror("read from socket failed !");
if(errno == ECONNRESET){
close(sockfd);
epoll_ctl(epollfd , EPOLL_CTL_DEL , sockfd , NULL);
}
}
}
}
}
}
}
select和poll的增强版本,它可以显著提高,它可以显著提高在大量并发连接中只有少量活跃的情况下系统CPU利用率,这是由于它会复用文件描述符集合来传递结果而不是迫使开发者每一次等待事件之前都必须重新准备需要被侦听的文件描述符集合,另外一点原因就是在获取事件的时候,它无需遍历整个被侦听的描述符表,只需要遍历那些被内核IO一部唤醒而加入Ready队列的文件描述符号表集合即可
epoll中事件模型
epoll中的事件模型:ET模型:- 边沿触发
LT模型(默认):- 水平触发
- 边沿触发: 缓冲区中剩余的数据不会导致
epoll_wait触发 - 水平触发: 缓冲区中剩余的数据会导致
epoll_wait触发 - 设置边沿触发(
ET模式的方式: 在结构体的实现设置的时候设置event = 事件类型 | EPOLLET) - 注意使用
epoll是监视文件描述符,所有不一定需要监控socket,还可以监听其他文件描述符 - 演示代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/epoll.h>
#include<fcntl.h>
#define MAX_LINE 10
int main()
{
// 验证 epoll 的 ET 模式
int pfds[2];
pipe(pfds);
char buf[MAX_LINE], ch = 'a';
struct epoll_event ep_events[MAX_LINE];
int pid = fork();
if(pid == 0){
// 子进程
close(pfds[0]);
while(1){
int i ;
for(i = 0 ; i < MAX_LINE / 2 ; i ++){
buf[i] = ch;
}
buf[MAX_LINE / 2 - 1] = '\n';
ch ++;
for( ; i < MAX_LINE ; i ++){
buf[i] = ch;
}
buf[MAX_LINE - 1] = '\n';
ch ++;
write(pfds[1] , buf , MAX_LINE);
sleep(5);
}
} else if (pid > 0){
// 父进程
close(pfds[1]);
int efd = epoll_create(MAX_LINE);
struct epoll_event ep_event;
ep_event.events = EPOLLIN;
// ep_event.events = EPOLLIN | EPOLLET;
ep_event.data.fd = pfds[0];
epoll_ctl(efd , EPOLL_CTL_ADD , pfds[0] ,&ep_event);
char read_buf[MAX_LINE];
while(1){
int ret = epoll_wait(efd , ep_events , MAX_LINE , -1);
if(ret > 0){
int n = read(pfds[0] , read_buf , MAX_LINE / 2);
write(STDOUT_FILENO , read_buf , n);
}
}
}
}
网络中的ET和LT模式
- 性质还是和上面一样
- 设置方式:
struct epoll_event ep_event;
ep_event.events = EPOLLIN | EPOLLET;
ep_event.data.fd = connfd;
epoll的ET非阻塞模式
LT: 是缺省的工作方式,同时支持block和no-block,这一种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对于这一个就绪的fd进行IO操作,如果不进行任何操作,内核还是会继续通知你的,所以这一种模式编程出现错误可能性比较小,传统的select/poll都是这一种模型的代表ET: 是高速工作方式,只是支持no-block socket,在这种模式中,对描述符从未就绪变为就绪时,内核通过epoll告诉你,然后它会假设你知道文件描述符已经就绪,并且不会在为那个文件描述符发送更多的就绪通知,请注意,如果一直不对于这一个fd做IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知- 注意如果
ET使用阻塞模式,那么比如如果读取套接字的时候读取的字节个数小于指定的字节个数,此时由于不会自动触发epoll_wait函数就会不断阻塞等待,由于read阻塞所以无法到达epoll_wait,所以就会处于一个死循环的状态(但是ET必须设置非阻塞模式) - 可以使用
fcntl函数设置非阻塞 - 比如设置非阻塞状态:
flag = fcntl(connfd , F_GETFL);
flag |= O_NOBLOCK;
fcntl(connfd , F_SETFL , flag);
epoll的实践:
struct epoll_event event;
event.events = EPOLLIN | EPOLLET;
event.data.fd = cfd;
epoll_ctl(efd , EPOLL_CTL_ADD , cfd , &event);
flag = fcntl(cfd , F_GETFL);
flag |= O_NOBLOCK;
fcntl(cfd , F_SETFL , flag);
epoll特点
- 优点:
- 高效,可以突破
1024限制
- 高效,可以突破
- 缺点:
- 不可跨平台,
Linux
- 不可跨平台,
对比ET和LT
ET模式: 应用于只用读取文件的一部分内容LT模式: 应用于需要读取文件的全部部分
epoll反应堆模型
epoll反应堆模型的大体流程如下:
- 利用
epoll ET模式 + 非阻塞 +void* ptr - 由于
epoll_data是一个联合体,所以不可以有两个共存的成员,利用void* ptr可以携带fd和回调函数,比如定义一个结构体,结构体的成员中有回调函数和文件描述符 epoll反应堆中不但需要监听读事件还需要监听写事件epoll反应堆中的main逻辑:- 利用
epoll_wait初始化 - 绑定端口,
IP等 - ...
- 判断读写操作,调用相应的回调函数
- 利用
- 小知识: 宏定义:
__func__表示函数名称 lfd和cfd回调函数的绑定: 在initlistensocket函数中做了初始化lfd的工作,另外还把lfd绑定了回调函数acceptconn函数,并且把lfd放在了数组最后一个参数的位置(这一个回调函数在读取的时候就会被调用)- 在
acceptconn函数调用accept函数生成cfd并且为cfd绑定了回调函数(recvdata()) eventset函数和eventadd函数:eventset函数: 设置回调函数(lfd-->acceptconn,cfd-->recvdata())eventadd函数中:- 将一个
fd添加到红黑树中,监听红黑树,设置监听read事件,还是监听写事件
- 将一个
recv函数相当于网络编程中的read函数send函数相当于网络编程中的write函数epoll_wait调用之后,如果是读实现,那么就会回调读的的回调函数,这一个回调函数中完成的事情就是首先把数据读取到结构体的缓冲区中,并且把该节点从epoll中摘除,并且绑定读事件,如果再次触发读事件,那么就会触发读的回调函数,读的回调函数中首先回写到对应的函数中并且把该fd从红黑书中摘下来,并且重新绑定写事件即可,注意改变结构体的状态- 检测超时的机制方式就是不断检验超时超过
60s的文件描述符号并且把这一个关闭即可 - 这里为什么回调函数的第三个参数还是结构体本身,这是由于在绑定回调函数的时候,回调函数中还需要这个参数本身来绑定其他的回调函数
epoll补充内容
- 可以使用
man epoll可以查看epoll相关的例程 epoll反应堆中的读写回调判断其实判断了两次,就是验证此时传出的是读实现并且需要监听的就是读函数,可以自己查看源代码
ctags
- 利用
ctags ./* -R可以生成tags文件 - 之后可以进行如下操作:
ctrl + ]光标放置在调用函数上,跳转到函数定义位置ctrl + t返回跳转位置之前ctrl + o屏幕左边列出未见了列表,再次关闭F4右边列出函数列表
线程池
- 线程池中的各种组件如下:

线程池模型原理
- 每一次进行线程的创建和线程的销毁的开销比较大,所以可以使用线程池的方式
- 线程池只是一个虚拟的概念,其实并不存在这样一个概念,可以理解成线程的聚集之处,可以利用条件变量进行线程池的阻塞(这里的条件变量可以设置为任务队列不为
NULL,当条件变量阻塞结束的时候就可以取出线程处理任务了) - 线程池的参数包含初始线程的数量,最大线程的数量还有忙碌线程的数量以及活跃线程的数量,当忙碌线程的数量逐渐增加的时候,就可以对于线程池进行扩容,当忙碌的线程数量比较小的时候,就可以对于线程池进行缩小容量的操作
- 另外需要维护一个管理者线程,这一个管理者线程对于线程池中的线程进行一系列的操作(包含扩容缩容等)
线程池描述结构体
- 线程池描述结构体如下:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<pthread.h>
// 任务队列中的任务
typedef struct threadpool_task_t{
void* (*function)(void*); // 表示任务函数
void* arg; // 表示参数
}threadpool_task_t;
// 线程池描述结构体
struct threadpool_t {
pthread_mutex_t lock; // 用于锁住结构体本身
pthread_mutex_t thread_counter; // 记录忙碌状态下的线程个数的锁
pthread_cond_t queue_not_full; // 当任务队列为满的时候,添加到任务队列中的线程阻塞,等待这一个条件变量(阻塞服务器) 反面就是满足条件
pthread_cond_t queue_not_empty; // 当任务队列不为空的时候,通知等待任务的线程(阻塞线程池中的线程) 反面就是满足条件
pthread_t* threads; // 存放线程池中每一个线程的tid,数组
pthread_t adjust_tid; // 存放管理线程 tid
threadpool_task_t* task_queue; // 任务队列(数组首地址)
int min_thr_num; // 线程池最小线程数量
int max_thr_num; // 线程池最大线程数量
int live_thr_num; // 当前存活状态线程个数
int busy_thr_num; // 忙状态的线程个数
int wait_exit_thr_num; // 需要销毁的线程个数
int queue_front; // task_queue 队头下标(环形队列)
int queue_rear; // task_queue 队尾下标
int queue_size; // task_queue 队列中的实际任务数量
int queue_max_size; // task_queue 中可以容纳的任务数上限
int shutdown; // 标志位,线程池使用状态,true或者false
};
- 使用线程池的方法:
- 首先调用创建线程池的方法创建线程池
- 之后调用把任务交给线程池
- 最后调用销毁线程池的方法销毁线程池
- 一个小的知识点,可以使用
do...while(0)替代goto,可以直接break出去
创建线程池
- 创建线程池结构体指针
- 初始化线程池结构体(
N个成员变量) - 创建
N个任务线程 - 创建
1个管理线程 - 失败的时候,销毁开辟的所有空间
回调函数
- 进入子线程回调函数
- 接受参数,把
void* arg-->pool 结构体 - 加锁 -->
lock--> 整个结构体的锁 - 判断条件变量 -->
wait
管理者线程
- 进入管理者线程回调函数
- 接受参数:
void* arg-->pool结构体 - 加锁 -->
lock--> 整个结构体锁 - 获取管理线程池需要使用的变量 ,
task_num,live_num,busy_num - 根据既定算法,使用上述三个变量,判断是否应该创建,销毁线程池中指定步长的线程
threadpool_add函数
- 作用: 添加任务到任务队列中
- 初始化任务队列结构体成员,回调函数
function,arg - 利用环形队列机制,实现添加任务,借助队尾指针移动实现(环形队列,你懂得)
- 唤醒阻塞在条件变量上的线程
- 解锁
子线程处理任务
- 在
pthread_cond_wait函数管理的区域中 - 获取任务处理回调函数和参数
- 利用环形队列机制,实现处理任务,借助队头指针移动实现
- 环形阻塞在环境变量上的
server - 解锁
- 加锁
- 修改忙线程数量++
- 解锁
- 执行处理任务的线程
- 加锁
- 该忙线程 --
- 解锁
threadpool_destory函数
- 首先把线程池设置为关闭状态
- 销毁管理者线程
- 之后唤醒所有线程(可以使用
pthread_cond_brocast方法虽然唤醒所有线程但是只有一个线程可以拿到锁,拿到锁的线程由于条件不满足就会执行退出函数从而退出)
管理者线程
- 根据默认的步长进行创建线程和销毁线程:
- 创建线程就可以使用
pthread_create函数进行线程的创建(回调任务线程函数) - 销毁线程还是可以使用
pthread_cond_brocast唤醒线程执行线程退出函数
UDP协议
TCP通信和UDP通信各自的优缺点
TCP: 面向连接的,可靠数据包传输(对于不稳定的网络层,采取完全弥补的通信方式,丢包重传,但是还是可能有丢包风险)- 优点: 稳定
- 数据流量稳定,速度稳定,顺序
- 缺点:
- 传输速度满,传输的效率比较低,开销比较大
- 使用场景: 数据的完整型要求比较高,不追求效率,大文件传输,文件传递
- 优点: 稳定
UDP: 无连接,不可靠的数据包传输(对于完全不稳定的网络层,采取完全不弥补的通信方式,默认还原网络状况)- 优点: 传输速度比较快,效率比较高,开销小
- 缺点: 不稳定,数据流量,速度,顺序
- 使用场景: 对于时效性要求比较高的场合,稳定性其次(比如游戏,视频会议等)
- 其实可以在应用层数据校验协议,弥补
udp的不足
UDP通信客户端和服务器端流程
- 由于没有连接,所以不需要
accept和connect函数,同时也不需要连接数 - 注意
recv和send智能用于TCP通信 server:- 创建
socket(),lfd = Socket(AF_INET , SOCK_DGRAM(表示报式协议),0) bind()listen()可以省略- 不使用
read函数,使用recvfrom替换 - 不使用
write函数,替换成sendto函数 - 最后关闭:
close()
- 创建
client:socket()lfd = Socket(AF_INET , SOCK_DGRAM , 0)sendto(服务器的地址结构,结构体大小)函数recvfrom()- 写到屏幕上
close()
recvfrom函数
- 作用: 从指定的
IP地址的某一个端口接受数据 - 函数原型:
ssize_t recvfrom(int sockfd, void buf[restrict .len], size_t len,
int flags,
struct sockaddr *_Nullable restrict src_addr,
socklen_t *_Nullable restrict addrlen);
- 参数:
sockfd:Socket函数的返回值buf: 缓冲区len: 缓冲区大小flags: 可以传递0表示读的作用src_addr: 数据源的地址结构(传出参数)addrlen: 数据源地址结构的大小(传入传出参数)
- 返回值:
- 接收到的字节数量,错误返回
-1(errno),0表示队端关闭
- 接收到的字节数量,错误返回
sendto函数
- 作用: 从指定的
IP地址的某一个端口发送数据 - 函数原型:
ssize_t sendto(int sockfd, const void buf[.len], size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
- 参数:
sockfd:Socket函数的返回值buf: 存储数据的缓冲区len: 缓冲区容量flags: 可以传递0表示写的作用dest_addr: 传入参数,表示目标的地址结构addrlen: 地址结构长度
- 返回值:
- 成功返回: 成功写出数据字节数量,失败返回
-1
- 成功返回: 成功写出数据字节数量,失败返回
- 客户端:
#include "wrap.h"
#define SERVER_PORT 10086
#define CLIENT_PORT 10089
int main()
{
// 1. Socket()函数
int lfd , ret;
lfd = Socket(AF_INET , SOCK_DGRAM , 0);
// 2. 准备服务器端地址
struct sockaddr_in server_addr;
inet_pton(AF_INET , "127.0.0.1" , &server_addr.sin_addr);
server_addr.sin_port = htons(SERVER_PORT);
server_addr.sin_family = AF_INET;
// Bind(lfd , &server_addr , sizeof(server_addr));
char client_IP[BUFSIZ];
printf("server:%s:%d \n" , inet_ntop(AF_INET , (void*)&(server_addr.sin_addr.s_addr) , client_IP , sizeof(server_addr)) , ntohs(server_addr.sin_port));
struct sockaddr_in client_addr;
client_addr.sin_addr.s_addr = htonl(INADDR_ANY);
client_addr.sin_family = AF_INET;
client_addr.sin_port = htons(CLIENT_PORT);
Bind(lfd , (struct sockaddr*)&client_addr , sizeof(client_addr));
// 3. 开始写数据并且监听
char buf[BUFSIZ];
while(1){
scanf("%s" , buf);
sendto(lfd , buf , strlen(buf) , 0 , (struct sockaddr*)&server_addr , sizeof(server_addr));
// 回收结果
ret = recvfrom(lfd , buf , sizeof(buf) , 0 , NULL , 0);
if(ret == -1){
perror("read from server failed !");
exit(1);
} else if(ret > 0){
write(STDOUT_FILENO , buf , ret);
}
}
close(lfd);
}
- 服务器端:
#include "wrap.h"
#include<ctype.h>
#define SERVER_PORT 10086
int main()
{
// 1. 获取 Socket
int lfd , ret;
lfd = Socket(AF_INET , SOCK_DGRAM , 0);
// 2. 利用 Bind绑定地址结构
struct sockaddr_in server_addr;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERVER_PORT);
server_addr.sin_family = AF_INET;
Bind(lfd , (struct sockaddr*)&server_addr , sizeof(server_addr));
// 3. 利用 Listen设置最大监听数量,当然也可以不用设置
// Listen(lfd , MAX_CONNECT);
// 4. 循环调用接受函数接受
char buf[BUFSIZ] , client_IP[BUFSIZ];
struct sockaddr_in client_addr;
socklen_t client_addr_len;
while(1){
ret = recvfrom(lfd , buf , sizeof(buf) , 0 , (struct sockaddr*)&client_addr , &client_addr_len);
if(ret == -1){
perror("recv from client failed !");
}
printf("ret = %d \n" , ret);
printf("client: %s:%d \n" , inet_ntop(AF_INET , (void*)&(client_addr.sin_addr.s_addr) , client_IP , sizeof(buf)) , ntohs(client_addr.sin_port));
for(int i = 0 ; i < ret ; i ++){
buf[i] = toupper(buf[i]);
}
printf("%s",buf);
// 写回去
ret = sendto(lfd , buf , ret , 0 , (struct sockaddr*)&client_addr , sizeof(client_addr));
if(ret == -1){
perror("send to client failed !");
}
}
close(lfd);
}
本地套接字
本地套接字和网络套接字比较
IPC(进程之间的通信方式):pipe,fifo,mmap,信号,本地套接字(domain)(CS模型)- 本地套接字和网络套接字不同之处:
socket()参数(AF_UNIX/AF)LOCAL , SOCK_STREAM / SOCK_DGRAM , )bind()使用的地址结构改变,sockaddr_in --> sockaddr_un
- 初始化方式:
struct sockaddr_un srv_addr;
srv_addr.sun_family = AF_UNIX;
strcpy(srv_addr.sun_path , "路径");
len = 2(表示头部的地址类型) + strlen(srv_addr.sun_path); // 由于字符串的大小不同,所以需要注意
- 可以使用函数求解结构体中的成员相对于结构体的首地址的偏移量(这一个函数挺好用的):
len = offsetof(struct sockaddr_un , sun_path) + strlen(un.sun_path);
- 为了保证
bind可以成功,会创建一个socket,因此保证bind成功,通常在我们bind之前,需要使用ulink(srv.socket)使得他创建新的 - 套接字文件是伪文件,不占用磁盘空间
offsetof函数原型如下:
size_t offsetof(type, member);
- 客户端不依赖隐式地址绑定,并且应该在通信建立连接的过程中,创建并且初始化
2个套接字文件 - 服务器端代码如下:
#include "wrap.h"
#include<ctype.h>
#include <sys/un.h>
#define SERV_SOCKET "serv.socket"
int main()
{
// 客户端通信
int lfd , cfd , ret ,len;
// 1. 利用 Socket 获取 lfd
lfd = Socket(AF_UNIX , SOCK_STREAM , 0);
// 2. 利用 Bind 绑定地址结构
struct sockaddr_un server_addr;
bzero(&server_addr , sizeof(server_addr)); // 表示清空地址空间
server_addr.sun_family = AF_UNIX;
strcpy(server_addr.sun_path , SERV_SOCKET);
len = offsetof(struct sockaddr_un , sun_path) + strlen(server_addr.sun_path);
unlink(SERV_SOCKET);
Bind(lfd , (struct sockaddr*)&server_addr , len);
Listen(lfd , 20);
// 3. 利用 Accpet 进行接受
char buf[BUFSIZ];
struct sockaddr_un client_addr;
len = sizeof(client_addr);
cfd = Accept(lfd , (struct sockaddr*)&(client_addr) , (socklen_t*)&len);
while(1){
printf("cfd = %d \n" , cfd);
if(cfd == -1){
perror("Accept failed !");
}
ret = read(cfd , buf , sizeof(buf));
printf("ret = %d \n" , ret);
if(ret == -1){
perror("read from cfd failed !");
} else if(ret == 0){
perror("cfd closed !");
close(cfd);
} else if(ret > 0){
for(int i = 0 ; i < ret ; i ++){
buf[i] = toupper(buf[i]);
}
printf("%s\n" , buf);
write(cfd , buf , ret);
}
}
close(lfd);
}
- 客户端代码:
#include "wrap.h"
#include <stddef.h>
#include <sys/un.h>
#define SERV_SOCKET "serv.socket"
#define CLIE_SOCKET "clie.socket"
int main()
{
// 1. 利用 Listen 获取 cfd
int cfd , lfd , ret;
cfd = Socket(AF_UNIX , SOCK_STREAM , 0);
// 2. 利用 Bind 绑定地址
struct sockaddr_un client_addr , server_addr;
bzero(&client_addr , sizeof(client_addr));
bzero(&server_addr , sizeof(server_addr));
client_addr.sun_family = AF_UNIX;
server_addr.sun_family = AF_UNIX;
strcpy(client_addr.sun_path , CLIE_SOCKET);
strcpy(server_addr.sun_path , SERV_SOCKET);
int client_addr_len = offsetof(struct sockaddr_un , sun_path) + strlen(client_addr.sun_path);
int server_addr_len = offsetof(struct sockaddr_un , sun_path) + strlen(server_addr.sun_path);
unlink(CLIE_SOCKET);
Bind(cfd , (struct sockaddr*)&client_addr , client_addr_len);
char buf[BUFSIZ];
Connect(cfd , (struct sockaddr*)&server_addr , server_addr_len);
while(1){
scanf("%s" , buf);
write(cfd , buf , strlen(buf));
ret = read(cfd , buf , sizeof(buf));
if(ret > 0){
write(STDOUT_FILENO , buf , ret);
}
}
}
- 注意所有的长度都需要使用
offsetof(结构名,属性名) + strlen(成员字符串) - 注意如果只是需要一对一的连接,把
Accpet函数写在循环外面,否则就会阻塞连接(多进程多线程情况下写在里面可以)
这一篇笔记对于计算机网络的描述非常模糊,具体可以参考==<<计算机网络自顶向下方法>>==
网络基础
协议
协议的概念
- 协议就是一种规则,传输和发送数据时都需要遵循对应的协议(数据传输的规则)
- 常见协议:
- 传输层:
TCP/UDP协议 - 应用层:
HTTP协议,FTP协议 ,sshnfstelnet - 网络层:
IP协议,ICMP协议,IGMP协议 - 网络接口层: 常见的协议有
ARP协议,RARP协议,以太网帧协议
- 传输层:
分层模型
OSI七层模型: "物,数,网,传,会,表,应":- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
TCP/IP四层模型:- 应用层
- 传输层
- 网络层
- 网络接口层
- 对应关系如下:

通信过程
- 对于信息的封装过程是从上层到下层的,就是 应用层 -> 传输层 -> 网络层 -> 网络接口层
- 注意数据如果没有封装的话,就不可以在网络中传递
- 传输过程如下:

- 比如两台计算机通过
TCP/IP协议通信的过程如下:
网络链路层
以太网帧
- 以太网帧的格式:

- 源地址就是值得本地网卡的硬件地址(也成为
MAC地址),一般出场之后就会分配,全球唯一地址(可以使用ifconfig) 查看 - 此时不知道目的主机的
MAC地址
ARP协议
ARP协议: 根据IP地址获取到mac地址ARP协议获取mac地址的方式和其数据格式:
- 注意以太网帧利用
ARP协议获取到MAC地址 - 比如一种可能的
ARP数据格式如下: - 总结一下过程: 首先以太网通过
ARP协议获取到目标主机的MAC地址,之后通过目的主机的MAC地址封装以太网数据帧进行数据传递,利用ARP协议的过程如下,首先把对方的MAC地址填写为ff:ff:ff:ff:ff:ff并且指定对方的IP地址,当传递到目标IP地址的机器的时候,对方就会发送一个ARP应答信号,利用这一个应答信号就可以获取到对方机器的MAC地址 APR协议解释如下:
- 举例如下:

网络层
IP协议
IP段协议格式如下:
- 版本:
IPV4IPV6 TTL:time to live表示数据包的最大的跳转上限次数,每经过一个路由节点,该值-1,每一次经过一个路由节点,该值-1,减少为0的时候,就会将这一个数据包丢弃- 源
IP:32位4个字节192.168.59.132表示点分十进制,但是需要转换成二进制才可以查看 - 目的
IP:32位4个字节
传输层
TCP协议
TCP数据报格式:
IP地址和端口号:IP地址: 可以在网络环境中,唯一表示一台主机- 端口号: 可以网络的一台主机上,唯一表示一个进程
IP地址+端口号: 可以在网络环境中,唯一表示一个进程
UDP:16位源端口号16位目的端口号
IP协议:16位源端口号16位目的端口号32位序号32位确认序号6个标志位16位窗口大小
CS模型/BS模型
CS模型:Client-Server模型BS模型:Browser-Server模型
| 特点 | C/S | B/S |
|---|---|---|
| 优点 | 缓存大量数据,协议选择灵活,速度快,程序的更新比较便捷,只用更新客户端 | 安全性比较高,跨平台,开发工作量比较小 |
| 缺点 | 安全性,跨平台麻烦 | 不可以缓存大量数据,严格遵循http协议 |
TCP通信模型
TCP 通信时序
- 也就是
TCP的三次握手,四次挥手
三次握手
- 三次握手的过程(内核自己完成):
- 注意上述中的数字表示发送的总共字节数量(编号)(括号里面的就是这一次发送的数据的字节数量)
- 但是不一定每一次就发送一次数据,而是可以一次发送多条数据,服务器端可以使用一次确认的方式来向客户端发送
ACK信号
四次挥手
- 四次挥手过程:
- 注意发送
ACK并不是发送数据,没有携带数据 - 四次握手的关键就是半关闭
- 为什么最后一次还是可以发送
ACK,这是由于半关闭只是关闭了写缓冲,但是没有关闭建立的连接,连接还是存在,只要不用缓冲区就可以发送数据了
滑动窗口
win标志位就是表示滑动窗口的大小- 滑动窗口工作原理:
- 滑动窗口的作用: 防止数据丢失(防止数据丢失)
- 客户端和服务器端的缓冲区都维护者一个滑动窗口,每一次服务器端发送数据的时候或者客户端发送数据的时候,都会利用
WIN标志位发送滑动窗口的大小,对方通过滑动窗口的大小判断发送数据的时机,如果滑动窗口的空间不足就会暂时停止发送数据
总结
- 三次握手:
- 主动方发起连接请求端,发送
SYN标志位,请求建立连接,携带数据包包号,数据字节数(0),滑动窗口大小 - 被请求连接请求端,发送
ACK标志位,同时携带SYN标志位,携带数据包包号,数据字节数(0),滑动窗口大小 - 主动发起连接请求端,发送
ACK标志位,应答服务器连接请求,携带数据包包号
- 主动方发起连接请求端,发送
- 四次挥手:
- 主动请求结束连接端,发送
FIN标志位,请求关闭连接,携带数据包号,数据字节数(0) - 被动关闭连接请求端,应答
ACK标志位 (半关闭完成) - 被动干部安必请求端发送
FIN标志位 - 主动关闭连接请求端发送
ACK标志位 (关闭完成)
- 主动请求结束连接端,发送
- 滑动窗口: 标志着本端口的缓冲区大小,防止数据发生覆盖
TCP 状态转移
TCP状态转义图如下:- 可以使用
netstat来查看 端口号和TCP连接建立状态
主动发起连接状态
- 注意如下的主动方或者被动方并不一定就是指的客户端还是服务器端,而是主动发送信号和被动接受信息的一方
- 主动发起连接状态时的状态转移如下:
- 也就是状态转移图中的:
CLOSE+SYN--->SYN_SENDSYN_SEND+SYN ACK--->ESTABLELISHED
主动关闭连接状态
- 主动关闭连接状态转移图:
- 转移状态就是图中的:
ESTABLISHED+FIN-->FIN WAIT1FIN WAIT1+ACK-->FIN WAIT2(半关闭)FIN WAIT2+FIN ACK-->TIME WAITTIME WAIT+Timeout-->CLOSED - 可以使用
netstat -anp命令查看连接建立状态 - 注意为什么之前频繁出现端口占用问题,这是由于如果时服务器端首先关闭,那么就会导致此时服务器端口处于
TIME WAIT状态,而不是CLOSE状态,所以再次启动服务器就会发生端口占用的情况
被动接受连接状态
- 被动端接受连接状态示意图:
- 状态转移途径:
CLOSED-->LISTENLISTEN+SYN ACK-->SYN_RCVDSYN_RCVD+ACK-->ESTABLISHED
被动关闭连接状态
- 被动段关闭连接状态示意图:
- 状态转移途径:
ESTABLISHED(数据通信状态) --> 接受FIN-->ESTABLISHED(数据通信状态) --> 发送ACK-->CLOSE WAIT(说明对端(主动关闭连接端)处于半关闭状态) --> 发送FIN-->LAST ACK--> 接受ACK-->CLOSE
2MSL时长存在的意义
- 作用: 保证最后一个
ACK可以被对端接受(等待期间,对端没有受到我发送的ACK,对端就会再一次发送FIN请求) - 注意
2MSL时长发生于主动关闭连接请求一段,同时TIME_WAIT也是只有主动关闭连接的一端才有的状态 - 总结:
- 主要就是可以根据退出状态结合
netstat -anp命令来判断错误出现的位置,之后可以使用tldr命令查看命令的用途比较直观
- 主要就是可以根据退出状态结合
其他状态
- 也就是其他的异常情况下的状态
半关闭
- 需要重点记忆的几个状态如下:
ESTABLISHED,FIN_WAIT2CLOSE_WAITTIME_WAIT(2MSL)
- 半关闭:
FIN_WAIT2,可以使用close函数完成半关闭,也可以使用shutdown函数 shutdown函数的函数原型如下,可以用于关闭读端或者写端,可以指定关闭套接字中的读端或者写端
int shutdown(int sockfd, int how);
how:SHUT_RD: 表示关闭读端SHUT_WR: 表示关闭写端SHUT_RDWR: 表示关闭读写
- 注意
shutdown和close关闭的区别: 对于多个文件描述符引用的文件,利用shutdown会导致所有文件描述符都关闭,但是close只会关闭其中的一个文件描述符
客户端服务器端通信流程
Socket编程API
转换函数
- 用于本地端口和
IP地址和网络中的端口和IP地址的转换函数:
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
- 其中
IP地址是32为无符号的整型变量,端口号是16位无符号的整型变量 - 用于网络的
IP地址和点分十进制的转换函数:
const char *inet_ntop(int af, const void *restrict src,
char dst[restrict .size], socklen_t size);
int inet_pton(int af, const char *restrict src, void *restrict dst);
- 前者用于将
32位的IP地址转换为点分十进制的,后者用于将点分十进制的IP地址转换为网络中可用的IP地址
通信过程中使用的API
Socket函数: 用于获取某一个sockfd,这一个sockfd也就是监听文件描述符号:
int socket(int domain, int type, int protocol);
Bind函数: 用于将端口号和IP地址绑定到某一个给定的fd上面
int bind(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);
- 其中需要的
struct sockaddr_in结构体(其中可以使用INADDR_ANY)获取到本机任意有效的IP地址:
struct sockaddr_in {
sa_family_t sin_family; /* AF_INET */
in_port_t sin_port; /* Port number */
struct in_addr sin_addr; /* IPv4 address */
};
Listen函数: 用于绑定最大等待连接队列中的最大元素个数
int listen(int sockfd, int backlog);
Accept函数: 用于连接到客户端,获取connfd
int accept(int sockfd, struct sockaddr *_Nullable restrict addr,
socklen_t *_Nullable restrict addrlen);
Connect函数: 用于向服务器端发送连接请求:
int connect(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);
例程
介绍
WebSocket协议以及,WebSocket协议在golang中的使用方法
由于传统的 HTTP1.1 虽然支持长连接,但是连接只能由客户端发起,如果客户端需要实时接受到客户端发送过来的数据就需要建立一条比较长的 http 连接,之后不断轮询这一条 http 连接从而获取消息,这很大程度上消费了带宽资源
WebSocket 协议基于 Http协议,是由 HTTP 协议进行等级提升得到的,进行提升交换的报文也是使用 HTTP 报文, WebSocket报文的结构如下:
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-------+-+-------------+-------------------------------+ |F|R|R|R| opcode|M| Payload len | Extended payload length | |I|S|S|S| (4) |A| (7) | (16/64) | |N|V|V|V| |S| | (if payload len==126/127) | | |1|2|3| |K| | | +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - + | Extended payload length continued, if payload len == 127 | + - - - - - - - - - - - - - - - +-------------------------------+ | |Masking-key, if MASK set to 1 | +-------------------------------+-------------------------------+ | Masking-key (continued) | Payload Data | +-------------------------------- - - - - - - - - - - - - - - - + : Payload Data continued ... : + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + | Payload Data continued ... | +---------------------------------------------------------------+
go 中使用 WebSocket
这里需要使用第三方库: github.com/gorilla/websocket
WebSocket的使用方法(实际上websocket就是http协议的升级,只是用到协议的提升):
- 首先利用
websocekt.Upgrader得到升级连接的需要使用的对象,注意可以设置同源可以访问也就是解决跨域问题 - 之后通过这一个对象的
Upgrade方法获取连接对象 - 循环从连接对象中读取连接
package main
import (
"fmt"
"github.com/gin-gonic/gin" "github.com/gorilla/websocket" "net/http" "time")
type User struct {
Name string `json:"name"`
Age int `json:"age"`
Description string `json:"description"`
}
func WebSocketJson(g *gin.Context) {
wsUpgrader := websocket.Upgrader{
HandshakeTimeout: time.Second * 10,
ReadBufferSize: 1024,
WriteBufferSize: 1024,
CheckOrigin: func(r *http.Request) bool {
return true
},
}
ws, err := wsUpgrader.Upgrade(g.Writer, g.Request, nil)
if err != nil {
fmt.Println("[Error] failed to get a connection!")
panic(err)
}
for {
messageType, p, err := ws.ReadMessage()
if err != nil {
break
}
if messageType == websocket.TextMessage {
err = ws.WriteJSON(User{
Name: string(p),
Age: 18,
Description: string(p) + "很厉害!!!!",
})
if err != nil {
fmt.Println("Json handler failed!")
panic(err)
}
}
}
}
func main() {
r := gin.Default()
r.GET("/json", WebSocketJson)
r.Run(":8080")
}
- gin框架: 是一个golang的一个web开发框架 >参考: https://gin-gonic.com/docs/
gin框架的引入
- 代理设置: 可以直接在创建工程中的environment选项中设置: GOPROXY=https://goproxy.cn.direct
- 可以利用postman端口调试工具给后端发送请求
- 下载gin依赖的方法如下:
:::color1 go get -u github.com/gin-gonic/gin // 直接利用go get下载依赖
:::
gin框架的展示和基本使用
- gin框架中的helloworld代码,其实就是演示创建路由使用路由的过程
package main
import (
"github.com/gin-gonic/gin"
)
func main() {
// 用于演示gin框架的基本操作
// 利用gin编写一个接口
// 创建一个默认路由,路由其实就是相当于一个访问地址,访问这个地址时可以根据请求的对象做出相应的行为
router := gin.Default()
// 绑定路由规则和路由函数,就是访问这个路由时就会使用这一个函数进行处理
router.GET("/index", func(context *gin.Context) {
context.String(200, "hello world")
})
// 其实服务器监听,服务器会把服务运行在 localhost的某一个端口中,还可以利用终端通过curl命令访问这个端口
// curl http://localhost:8080/index , 127.0.0.1
router.Run("localhost:8080") // localhost:8080
// 也可以使用原生http服务的方式启动
// http.ListenAndServe("8080", router)
}
gin框架响应数据
响应字符串和json格式的字符串
- 响应字符串使用 string方法
- 响应json使用JSON方法,
- json可以响应如下数据
- 结构体的实例对象: 利用 (*gin context)JSON(状态码,对象名)
- 响应map集合 利用(*gin context)JSON(状态码,map集合名称)
- 直接响应数据 : 利用(*gin context).JSON(状态码,gin.H{键值对}
- 代码演示:
package main
import (
"github.com/gin-gonic/gin"
)
func _string(c *gin.Context) {
c.String(200, "hello gin")
}
func _json(c *gin.Context) {
type UserDemo struct { // 可以利用 json标签指定变成json之后的key值变化
Name string `json:"user_name"`
Age int `json:"age"`
password string `json:"-"` // 用于忽略响应的结果,其实就是忽略转化为json
}
user := UserDemo{
Name: "zhangsan",
Age: 12,
password: "123456",
}
// json响应map
userMap := map[string]string{
"username": "hello",
"passworld": "111",
}
c.JSON(200, userMap) // 就是可以把对象变成json格式的字符串,其实后面就是一个对象
// 直接响应json,相当于可以响应一个结构体,直接利用gin.H方法响应json
c.JSON(200, gin.H{"username": "张三", "age": 23})
}
func main() {
// 用于演示响应 json格式的数据
router := gin.Default()
//router.GET("/", func(c *gin.Context) {
// // 响应一个字符串
// // 动态码演示
// /*
// 200 响应成功 , 还可以利用枚举列出响应状态码
// 404 找不到资源
//
// */
// // c.String(http.StatusOK, "hello gin")
// // 响应一个json
//
//})
router.GET("/", _string)
router.GET("/json", _json) // 一个页面只可以请求一个数据
router.Run(":80")
}
响应xml格式和yaml
- xml和yaml,json的格式如下:
- 代码演示:
func _xml(c *gin.Context) {
c.XML(200, gin.H{"username": "张三", "age": 23, "httpStatus": http.StatusOK})
}
// 响应yaml格式的代码
func _yaml(c *gin.Context) {
c.YAML(200, gin.H{"username": "张三", "age": 23, "httpStatus": http.StatusOK})
}
响应html
- 响应html,利用HTML方法,但是需要加载资源文件,利用loadHtmlGlobal方法进行文件的加载
- 但是可以进行类似声明式渲染的功能,利用 {{ .变量名 }}的方法进行声明式渲染
- 代码演示:
// 响应html文件
func _html(c *gin.Context) {
// 其实不可以传递一个结构体,但是可以利用gin.H方法传递结构体
c.HTML(200, "index.html", gin.H{"username": "张三"}) // 响应回去
}
func main() {
// 用于演示响应 json格式的数据
router := gin.Default()
// 注意引入html一定需要引入全局html
router.LoadHTMLGlob("../template/*") // 加载所有文件
//router.GET("/", func(c *gin.Context) {
// // 响应一个字符串
// // 动态码演示
// /*
// 200 响应成功 , 还可以利用枚举列出响应状态码
// 404 找不到资源
//
// */
// // c.String(http.StatusOK, "hello gin")
// // 响应一个json
//
//})
router.GET("/", _string)
router.GET("/json", _json) // 一个页面只可以请求一个数据
router.GET("/xml", _xml)
router.GET("/yaml", _yaml)
router.GET("/html", _html)
router.Run(":80")
}
- html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>响应html</title>
</head>
<body>
<h1>响应了html,你好 {{ .username }}</h1>
</body>
</html>
- 结果演示
文件响应
- 文件只用配置访问时使用的url和文件的路径就可以了,利用StaticFile配置静态资源,利用StaticFs配置打个文件
- 注意golang中还是有相对路径的(为什么我的结果和视频中的结果不同)(当前路径就是项目所在的路径,其实就是项目的根目录)
- 代码演示:
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
router := gin.Default()
// golang中还是有相对路径的,配置单个文件的方式,可以利用这种方法进行访问
// golang中的相对路径指的就是main包所在的路径,这里main所在的路径要得到相对路径只用
// 利用 .. 退回上面一级目录
router.StaticFile("/pic", "../static/img.png") // 前面一个参数就是访问的路径
router.StaticFS("/static", http.Dir("./static/static/*"))
router.Run(":80")
}
- 文件目录结构
重定向
- 其实就是访问一个地址时,自动跳转到另外一个地方中
package main
import "github.com/gin-gonic/gin"
// 前面加上_表示 私有方法
func _redict(c *gin.Context) { // 表示一个私有方法
// 301 表示原来的地址已经迁移了,服务器没有缓存了,一个是永久重定向,一个是临时重定向
// 可以使用 c.Redirect(201,"/html")
c.Redirect(201, "https://www.baidu.com")
}
func main() {
// 用于演示响应重定向
router := gin.Default()
router.GET("/baidu", _redict)
router.Run(":80")
}
请求
query参数
- query参数就表示访问某一个资源时,url之后的一个键值对参数
- 可以利用query方法获取单个参数,可以利用queryArray方法获取多个参数
- 代码演示
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func _query(c *gin.Context) {
// 得到的参数就是请求url之后的键值对参数
user := c.Query("user")
// 其实可以利用 c.getquery方法进行操作
fmt.Println(user)
// 可以拿到多个同名参数
fmt.Println(c.QueryArray("user"))
}
func main() {
router := gin.Default()
router.GET("/query", _query)
router.Run(":80")
}
动态参数(param参数)
- 什么是动态参数就是同一个请求地址之后带上不同的参数,比如请求的url可以写成 /static/:username/:password,请求时之后的参数就可以通过url之后的参数名称获取到,访问时直接利用变量替代:username和:password即可
- 代码演示如下:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func _param(c *gin.Context) {
// 动态参数,路径可以变化,除了路径参数之外的其他参数都可以
// 注意先后顺序,如果访问都会走到,谁先走到谁先匹配
fmt.Println(c.Param("userid"))
fmt.Println(c.Param("bookid"))
}
func _query(c *gin.Context) {
// 得到的参数就是请求url之后的键值对参数
user := c.Query("user")
// 其实可以利用 c.getquery方法进行操作
fmt.Println(user)
// 可以拿到多个同名参数
fmt.Println(c.QueryArray("user"))
}
func main() {
router := gin.Default()
router.GET("/query", _query)
router.GET("/param/:userid", _param)
router.GET("/param/:userid/:bookid", _param)
router.Run(":80")
}
表单参数
- 表单就是前端中的表单,其中可以利用postman发送表单信息,其实就是利用postman中的body进行发送,之后就可以利用headers查看发送的参数
- 注意postForm函数可以接受的参数有很多,比如 可以接受 www-form-urlencoded 和 form表单参数
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func _form(c *gin.Context) {
// 表单参数必须利用post请求
// 可以接受 www-form-urlencoded 和 form表单参数
fmt.Println(c.PostForm("name"))
// 接收多个参数的方法
fmt.Println(c.PostFormArray("username"))
// 如果用户没有传入尺寸就可以设置一个默认值,query也是有一个默认值的
fmt.Println(c.DefaultPostForm("addr", "湖北省"))
forms, err := c.MultipartForm() // 用于接收文件和其他所有参数,最后传出来的就是利用键值对构建的一个数组
fmt.Println(forms, err)
}
func main() {
router := gin.Default()
router.POST("/form", _form)
router.Run("localhost:80")
}
原始参数GetRawData
- 其实就得到各种请求的数据,可以用于处理请求体和请求头
- 请求体中不同参数的表现形式:
- json : 直接打印得到的就是一个unicode码值,但是需要利用string进行强转,另外可以利用json库中的uhamral函数 进行强制类型转换,但是需要传一个结构体承装结果,注意postman中发送请求的方式,直接利用body中的raw书写结构体发送请求
- www参数: 表现形式就是一串 unicode码值
- 表单参数,string强转之后得到的就是一个表单的具象化
- 代码演示:
package main
import (
"encoding/json"
"fmt"
"github.com/gin-gonic/gin"
)
func _form(c *gin.Context) {
// 表单参数必须利用post请求
// 可以接受 www-form-urlencoded 和 form表单参数
fmt.Println(c.PostForm("name"))
// 接收多个参数的方法
fmt.Println(c.PostFormArray("username"))
// 如果用户没有传入尺寸就可以设置一个默认值,query也是有一个默认值的
fmt.Println(c.DefaultPostForm("addr", "湖北省"))
forms, err := c.MultipartForm() // 用于接收文件和其他所有参数,最后传出来的就是利用键值对构建的一个数组
fmt.Println(forms, err)
}
// 原始参数
func _raw(c *gin.Context) {
// 接收到的是请求体中的参数
// 但是不同的参数的处理方式不同,比如www参数是用unicode编码写出的
// 表单时直接列出的
// fmt.Println(c.GetRawData()) // 其实得到的就是参数的一个unicode值
body, _ := c.GetRawData()
//fmt.Println(string(body))
// 获取请求头
contentType := c.GetHeader("content-Type")
switch contentType {
case "application/json":
// 如果是json数据开始解析数据
type User struct {
Name string `json:"name"`
Age int `json:"age"`
}
// 相当于一个匿名结构体
// 解析json字符串的方法利用结构体承装转换之后的对象
var user User
err := json.Unmarshal(body, &user)
if err != nil {
fmt.Println(err.Error())
}
fmt.Println(user)
}
fmt.Println(contentType)
}
func main() {
router := gin.Default()
router.POST("/form", _form)
router.POST("/raw", _raw)
router.Run("localhost:80")
}
四大请求方式
- Restful风格是网络应用中就是资源定位和资源操作的风格,不是协议也不是标准
GET
- 其实就是从服务器中取出资源
POST
- 在服务器端创建一个资源
PUT
- 在服务器中更新资源(客户端提供完整资源数据)
PATCH
- 在服务器中更新资源(客户端提供需要修改的资源)
DELETE
- 从服务器中删除资源
各种资源的演示(实例相关)
// 文件资源为例
// GET /articles 返回一个文件列表
// GET /articles/:id 返回一个文章详情
// POST /articles 添加一遍文章
// PUT /articles 修改一篇文章
// DELETE /articles/:id 删除某一篇文章(客户端提供一个删除的id)
利用各种请求方式进行文章操作(仅仅正对于restful的操作)
package main
import (
"encoding/json"
"errors"
"fmt"
"github.com/gin-gonic/gin"
)
type Article struct {
Title string `json:"title"`
Context string `json:"context"` // 其实就是json字符串中的一个键值
}
type Response struct {
Code int `json:"code"`
Data any `json:"data"`
Msg string `json:"msg"`
}
// 提供增删改查的接口
func _getList(c *gin.Context) {
articleList := []Article{
{
Title: "GO语言入门",
Context: "go语言圣经",
},
{
Title: "java语言入门",
Context: "java从入门到进阶",
},
{
Title: "cpp语言入门",
Context: "cpp从入门到放弃",
},
}
//c.JSON(200, articleList)
c.JSON(200, Response{0, articleList, "传输成功"}) // 注意规范
}
// 文章详情页面
func _getDetail(c *gin.Context) {
// 获取param的参数
fmt.Println(c.Param("id"))
article := Article{
Title: "GO语言入门",
Context: "go语言圣经",
}
c.JSON(200, Response{0, article, "传输成功"})
}
// 处理json数据
func _bindJson(c *gin.Context, obj any) error {
// 首先获取json数据
data, err := c.GetRawData()
if err != nil {
return errors.New("解析失败")
}
json.Unmarshal(data, obj)
return nil
}
// 添加文章,接受前端的json数据
func _create(c *gin.Context) {
var article Article
err := _bindJson(c, &article)
if err != nil {
fmt.Println(err)
return
}
c.JSON(200, Response{0, article, "添加成功"})
}
// 编辑文章逻辑
func _update(c *gin.Context) {
fmt.Println(c.Param("id"))
// 根据id进行修改数据
var article Article
err := _bindJson(c, &article)
if err != nil {
fmt.Println(err)
return
}
c.JSON(200, Response{0, article, "修改成功"})
}
func _delete(c *gin.Context) {
// 其实就是找到id,之后删除记录即可
fmt.Println(c.Param("id"))
c.JSON(200, Response{0, map[string]string{}, "删除成功"}) // 其中map其实就是一个空的映射
}
func main() {
router := gin.Default()
// 注册路由
router.GET("/articles", _getList) // 查看文章,其实就是后端向前端响应数据
router.GET("/articles/:id", _getDetail) // 查看文章详情
router.POST("/articles", _create) // 添加文章
router.PUT("/articles/:id", _update) // 更新文章
router.DELETE("/articles/:id", _delete) // 删除文章,都是客户端发送参数,后端接收参数查询数据并且删除数据
router.Run(":80")
}
请求头相关
请求头参数获取
- 主要利用GetHeader方法或者c.Request.Header对象中的一个Get方法或者直接利用键值对的形式传递参数
- 但是GetHeader,Get虽然不区分大小写,但是只可以 取出一个参数
- 直接利用键值对可以取出多个参数
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"strings"
)
func main() {
// 请求头参数相关
router := gin.Default()
router.GET("/", func(c *gin.Context) {
// 首先如何拿到请求头
// 请求头: 首字母大小写不区分,单词和单词之间使用 - 连接
// 使用Get方法或者是GetHeader方法就可以不用区分大小写,但是只可以获取第一个对象
// 如果使用map的取值方式,注意大小写即可
fmt.Println(c.GetHeader("User-Agent"))
// 获取请求体中的全部数据,返回的参数就是一个键值对
fmt.Println(c.Request.Header["User-Agent"]) // Header 其实就是一个普通的映射 map[string][]string
fmt.Println(c.Request.Header.Get("User-Agent")) // 利用这一种方式之可以拿到第一个参数,不可以拿到其他同名参数
c.JSON(200, gin.H{"msg": "成功"})
// 自定义请求使用Get方法还是可以不用区分大小写
fmt.Println(c.Request.Header.Get("Token"))
})
// 判断登录用户类型
router.GET("/index", func(c *gin.Context) {
userAgent := c.GetHeader("User-Agent")
// 可以利用正则表达式单独匹配
// 或者字符串的包含匹配
if strings.Contains(userAgent, "python") {
c.JSON(0, gin.H{"data": "这是响应给爬虫的数据"})
return
}
c.JSON(0, gin.H{"data": "这是响应给用户的数据"})
})
router.Run(":80")
}
响应头相关
- 重点就是利用Header方法设置参数的名称 Header(字段名称,值),主要利用这个方法设置Content-Type的值,用于指定传输文件的类型
- 代码演示:
// 设置响应头
router.GET("/res", func(c *gin.Context) {
// 设置响应头
c.Header("Hello", "发现我了吗")
// 利用Header方法一般是用于设置Content-type,就是相应的内容
c.Header("Content-Type", "application/json;charset=utf-8")
c.JSON(200, gin.H{"Msg": "看一下响应头中有没有token"})
})
bind参数绑定
- gin框架中的一个bind可以很方便的把前端传递过来的数据和结构体进行参数绑定,以及参数校验
- 使用这个功能时,需要为结构体中的成员加上一个Tag: json(之前用于指定一个json中结构体中个字段对应的名称),form,url,xml,yaml(其实就是类似于一个gorm标签)
- 基本使用Shouldbind
利用shouldbingJson方法绑定参数到结构体中
package main
import "github.com/gin-gonic/gin"
// 结构体
type UserInfo struct {
Name string `json:"name" form:"name"` // 注意之后的字段
Age int `json:"age" form:"age"`
Gender string `json:"gender" form:"gender"`
}
func _bind(c *gin.Context) {
var userinfo UserInfo
err := c.ShouldBindJSON(&userinfo)
if err != nil {
c.JSON(200, gin.H{"msg": "错误出现了"})
return
}
// 响应原始数据
c.JSON(200, userinfo)
}
func main() {
// 用于参数绑定,绑定查询参数
router := gin.Default()
router.POST("/bind", _bind) // 利用post用于添加数据,但是get方法只是可以传递键值对参数
router.POST("/query", func(c *gin.Context) {
var userinfo UserInfo
err := c.ShouldBindQuery(&userinfo)
if err != nil {
c.JSON(200, gin.H{"Msg": "出错啦"}) // 注意利用gin.H传递json对象
return
}
c.JSON(200, userinfo)
})
router.Run(":80")
}
利用shouldBindQuery查询字段是否错误,并加以检验
- 注意用以检验的字段所在的位置和类型,可以检验字段,此时参数的类型就是键值对参数类型:
- 代码演示,注意添加form表单标签指定相关的属性
router.POST("/query", func(c *gin.Context) {
var userinfo UserInfo
err := c.ShouldBindQuery(&userinfo)
if err != nil {
c.JSON(200, gin.H{"Msg": "出错啦"}) // 注意利用gin.H传递json对象
return
}
c.JSON(200, userinfo)
})
利用shouldBIndUri进行绑定动态参数
- 其实上面不同的方法就是针对于不同携带参数请求方式进行参数与结构体之间的绑定,这里演示利用uri携带参数获取参数并且绑定结构体的方法
- 注意tag为uri
- uri携带参数的方式(/uri/id/username/age):
- 代码演示:
router.POST("/uri/:name/:age/:gender", func(c *gin.Context) {
var userinfo UserInfo
err := c.ShouldBindUri(&userinfo)
if err != nil {
c.JSON(200, gin.H{"Msg": "出错啦"}) // 注意利用gin.H传递json对象
return
}
c.JSON(200, userinfo)
})
如何绑定formdate或者www-form-urlencode参数
- 直接利用 shouldbind方法从响应头 开始寻找,找到表单之后开始赋值
- 代码演示:
router.POST("/form", func(c *gin.Context) {
var userinfo UserInfo
// 这个方法回从请求头开始寻找,寻找之后可以可以找到form表单并且获取数据
// 一定有一个类型限制,必须限制类型
err := c.ShouldBind(&userinfo)
if err != nil {
c.JSON(200, gin.H{"Msg": "出错啦"}) // 注意利用gin.H传递json对象
return
}
c.JSON(200, userinfo)
})
gin验证器
常用验证器
:::info required : 必填字段 比如 binding:"required" // 多个条件连接使用 , 分隔开
min: 最小长度: 比如 binding:"min=4"
max: 最大长度
len :指定长度
eq: 等于
ne : 不等于
gt:"大于"
gte:"大于等于"
lt:"小于"
lte:"小于等于"
eqfield:等于其他字段的值 "binding:eqfield=ConfirmPassword",后面是结构体中的字段
nefied:不等于其他字段的值
-:"忽略字段 binding:"-"
:::
- 通过错误类型就可以直接通过验证器确定错误,采取响应的措施
- 代码演示:
package main
import "github.com/gin-gonic/gin"
type UserInfo struct {
Name string `json:"name" binding:"min=4,max=6,required,"` // 可以通过在后面加上限制条件进行条件过滤,都需要填写在binding字段之后
Age int `json:"age"`
PassWord string `json:"password"`
RePassWord string `json:"re_password" binding:"eqfield=Password"` // 确认密码
}
func main() {
router := gin.Default()
router.POST("/", func(c *gin.Context) {
var user UserInfo
err := c.ShouldBindJSON(&user)
if err != nil {
// 字段不可以为空,但是可以传递
c.JSON(200, gin.H{"msg": err.Error()})
return // 可以返回一个error
// 这里返回结果利用err.Error就可以进行类型校验
}
c.JSON(200, gin.H{"msg": "成功", "obj": user})
})
router.Run(":80")
}
gin内置验证器
字符串操作
:::info
字符串操作:
contains: 包含
exclude: 不包含
startwith:以什么开头
endwith:以什么结尾
:::
数组操作
:::info 数组操作:
dive 对于数组中每一个元素进行验证
比如 required dive min=1 startwith=like
:::
网络验证
:::info ip : 表示ip地址
url : 表示url验证
uri: 表示uri验证
注意uri就是url的之后的一部分,类似于访问路径
:::
日期验证
:::info datetime: 指定日期的格式 datetime=2006 01-02 15:04:05
:::
- 利用标签进行验证过程演示
package main
import "github.com/gin-gonic/gin"
type SignInfo struct {
/**
字符串操作:
contains: 包含
exclude: 不包含
startwith:以什么开头
endwith:以什么结尾
*/
Name string `json:"name" binding:"contains=f"` // 用户名 contains验证表示必须包含某一个信息,利用excluede可以表示不包含
Age int `json:"age"`
Gender string `json:"gender" binding:"oneof=man woman"` // 一个枚举验证器,列出所有可能的值
LikeList []string `json:"like_list" binding:"required,dive,startwith=like"` // 之后表示对于每一个对象进行操作
IP string `json:"ip" binding:"ip"`
Url string `json:"url" binding:"url"` // url其实就是指一个地址
Uri string `json:"ur}" binding:"uri"` // url其实就是指一个地址 uri是url的子集
// 日期验证
Date string `json:"data" binding:"datetime=2006-01-02 15:04:05"` // 1月2日3时4分5秒
}
func main() {
router := gin.Default()
router.POST("/", func(c *gin.Context) {
var user SignInfo
err := c.ShouldBindJSON(&user)
if err != nil {
c.JSON(200, err.Error())
return
}
c.JSON(200, user)
})
router.Run(":80")
}
gin验证器自定义错误信息
- 基本操作就是利用标签中的属性 msg指定报错信息,但是难点就是根据报错信息获取到msg的一个值,这里需要利用反射进行获取
- 代码演示如下:
package main
import (
"github.com/gin-gonic/gin"
"github.com/go-playground/validator/v10"
"reflect"
)
func GetValidMsg(err error, obj any) string {
getObj := reflect.TypeOf(obj)
// 将error接口断言称具体类型
if errs, ok := err.(validator.ValidationErrors); ok {
// 之后err 就是一个切片应为多次有错误
for _, e := range errs {
// 循环获取每一错误信息
// 根据报错字段获取信息
if f, exits := getObj.Elem().FieldByName(e.Field()); exits {
msg := f.Tag.Get("msg")
return msg
} // 根据报错名获取字段
}
}
return err.Error()
}
func main() {
// 用于演示自定义错误信息
router := gin.Default()
router.POST("/", func(c *gin.Context) {
type User struct {
Name string `json:"name" binding:"required" msg:"用户名校正失败"`
Age int `json:"age" binding:"required" msg:"年龄校验失败"`
}
var user User
err := c.ShouldBindJSON(&user)
if err != nil {
res := GetValidMsg(err, &user)
c.JSON(200, res)
return
}
c.JSON(200, user)
})
router.Run(":80")
}
自定义验证器
- 其实就是自定义一个验证器,代码中使用了Validator方法不知道是什么意思
- 代码演示:
package main
import (
"github.com/gin-gonic/gin"
"github.com/gin-gonic/gin/binding"
"github.com/go-playground/validator/v10"
_ "github.com/go-playground/validator/v10"
"reflect"
_ "reflect"
)
type User struct {
Name string `json:"name" binding:"required,sign" msg:"用户名校正失败"`
Age int `json:"age" binding:"required" msg:"年龄校验失败"`
}
func signValid(f1 validator.FieldLevel) bool {
// 这里就可以用于定义一个验证器了
nameList := []string{
"张三", "李四", "王五",
}
name := f1.Field().Interface().(string) // 类型断言
for _, namestr := range nameList {
if name == namestr {
return false
}
}
return true
}
func GetValidMsg(err error, obj any) string {
getObj := reflect.TypeOf(obj)
// 将error接口断言称具体类型
if errs, ok := err.(validator.ValidationErrors); ok {
// 之后err 就是一个切片应为多次有错误
for _, e := range errs {
// 循环获取每一错误信息
// 根据报错字段获取信息
if f, exits := getObj.Elem().FieldByName(e.Field()); exits {
msg := f.Tag.Get("msg")
return msg
} // 根据报错名获取字段
}
}
return err.Error()
}
func main() {
// 用于演示自定义错误信息
router := gin.Default()
if v, ok := binding.Validator.Engine().(*validator.Validate); ok {
v.RegisterValidation("sign", signValid)
}
router.POST("/", func(c *gin.Context) {
var user User
err := c.ShouldBindJSON(&user)
if err != nil {
res := GetValidMsg(err, &user)
c.JSON(200, res)
return
}
c.JSON(200, user)
})
router.Run(":80")
}
gin中文件上传和文件下载
- 利用postman发送请求传递文件的方法,传递文件不可以使用其他格式,之可以使用form表单格式,直接选择上传信息的类型,之后选择文件即可
- 服务端可以使用 : FormFile方法进行文件的接受
- 以下是上传文件之后本地保存文件的三种方法
利用SaveUploadedFile方法
- 代码演示:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func main() {
router := gin.Default()
router.POST("/upload", func(c *gin.Context) {
file, _ := c.FormFile("file")
// 获取文件之后的操作
fmt.Println(file.Size / 1024)
fmt.Println(file.Filename) // 这就是文件名和文件大小
// 这里的路径就是指的是当前工程的一个路径,这个工程就是upload
// 演示服务端保存文件的几种方式
// 1. 直接利用SavaUploadedFile函数保存文件
c.SaveUploadedFile(file, "./ginDemo1/uploads/hell.jpg") // 指定保存文件的路径,这里保存文件的路径就是这个目录
c.JSON(200, gin.H{"msg": "上传"})
})
// 为什么选择post方法,因为post方法用于向服务器提交文件
router.Run(":801")
}
利用io操作(os和is库进行文件的操作)
- 代码演示:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"io"
)
func main() {
router := gin.Default()
router.POST("/upload", func(c *gin.Context) {
file, _ := c.FormFile("file")
// 第二种方法保存文件
readerFile, _ := file.Open()
data, _ := io.ReadAll(readerFile)
fmt.Println(string(data))
// 这样的话就和io操作就可以实现对于文件的操作了
c.JSON(200, gin.H{"msg": "上传"})
})
// 为什么选择post方法,因为post方法用于向服务器提交文件
router.Run(":801")
}
还是利用io操作,创建输出流对象,之后利用io中的copy方法进行操作
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"io"
"os"
)
func main() {
router := gin.Default()
router.POST("/upload", func(c *gin.Context) {
file, _ := c.FormFile("file")
// 第三种方式, 直接利用Create和Copy方法
readFile, _ := file.Open()
writerFile, _ := os.Create("./uploads/h.png")
defer writerFile.Close()
n, _ := io.Copy(writerFile, readFile) // 直接利用输入输出流的方式进行文件的读取
fmt.Println(n)
c.JSON(200, gin.H{"msg": "上传"})
})
// 为什么选择post方法,因为post方法用于向服务器提交文件
router.Run(":801")
}
多文件上传
- 通过MutipartForm方法获取一个表单,表单中,表单参数中有一个file属性,这个对象中有文件组成的集合,通过操作承装文件的集合就可以操作文件了
- 代码演示如下:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"io"
"os"
)
func main() {
router := gin.Default()
router.POST("/upload", func(c *gin.Context) {
file, _ := c.FormFile("file")
// 第三种方式, 直接利用Create和Copy方法
readFile, _ := file.Open()
writerFile, _ := os.Create("./uploads/h.png")
defer writerFile.Close()
n, _ := io.Copy(writerFile, readFile) // 直接利用输入输出流的方式进行文件的读取
fmt.Println(n)
c.JSON(200, gin.H{"msg": "上传"})
})
router.POST("/uploads", func(c *gin.Context) {
form, _ := c.MultipartForm() // 接受多个文件
files := form.File["upload[]"] // 后去的其实是一个map集合,后面就是请求时表单中key的值
for _, file := range files {
c.SaveUploadedFile(file, "./uploads/"+file.Filename)
}
c.JSON(200, gin.H{"msg": fmt.Sprintf("成功上传%d个文件", len(files))})
})
// 为什么选择post方法,因为post方法用于向服务器提交文件
router.Run(":801")
}
gin中间件和路由
- Gin框架允许开发者在处理请求的过程中加入用户自己的钩子函数,这个钩子函数就叫做中间件,中间件适合于访问一些公共的业务逻辑比如登录认证,权限校验等,比如访问一个网页时无论访问什么路径都需要登录,此时就需要为所有的路径的处理函数进行一个统一中间件(用于校验是否登录)
- Gin中的中间件必须是一个gin.HandlerFunc类型的
单个路由中间件
- 其实每一个请求函数之后的一个函数参数就是一个中间件,中间件的执行顺序就是从前到后,但是遇到Abort函数 之后就会退出了
- 代码演示如下:
func main() {
// 用于演示中间件,单个路由中间件
router := gin.Default()
// 其实get函数的第二个参数是一个切片可以填写多个函数
// 只需要参数是一个c *gin.Context就说明可以是一个中间件
// 顺序就是从前往后
// 其实就是前面一个函数执行完了之后就可以执行后面一个函数了
// 可以利用abort函数阻止函数的继续执行
// abort之后的中间件就不会再走了
router.GET("/", func(c *gin.Context) {
c.JSON(200, gin.H{"msg": "第1次返回"})
}, func(c *gin.Context) {
c.JSON(200, gin.H{"msg": "第2次返回"})
}, func(c *gin.Context) {
c.JSON(200, gin.H{"msg": "第3次返回,还想要更多次数的返回吗?"})
c.Abort() // 停止 函数的执行
}, func(c *gin.Context) {
c.JSON(200, gin.H{"msg": "应该没有看到我吧"})
})
// 演示双路由中间件
//router.GET("/", f1, index, f2) // 看一下路由的顺序
router.Run(":80")
}
多个路由中间件
- 就是几个中间件的执行顺序和加入next函数之间的关系,代码演示如下:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func f1(c *gin.Context) {
fmt.Println("f1 in ......")
c.Next()
fmt.Println("f1 out ......")
}
func index(c *gin.Context) {
fmt.Println("index in ......")
c.Next()
fmt.Println("index out ......")
}
func f2(c *gin.Context) {
fmt.Println("f2 in ......")
c.Next()
fmt.Println("f2 out ......")
}
func main() {
// 用于演示中间件,单个路由中间件
router := gin.Default()
// 其实get函数的第二个参数是一个切片可以填写多个函数
// 只需要参数是一个c *gin.Context就说明可以是一个中间件
// 顺序就是从前往后
// 其实就是前面一个函数执行完了之后就可以执行后面一个函数了
// 可以利用abort函数阻止函数的继续执行
// abort之后的中间件就不会再走了
//router.GET("/", func(c *gin.Context) {
// c.JSON(200, gin.H{"msg": "第1次返回"})
//}, func(c *gin.Context) {
// c.JSON(200, gin.H{"msg": "第2次返回"})
//}, func(c *gin.Context) {
// c.JSON(200, gin.H{"msg": "第3次返回,还想要更多次数的返回吗?"})
// c.Abort() // 停止 函数的执行
//}, func(c *gin.Context) {
// c.JSON(200, gin.H{"msg": "应该没有看到我吧"})
//})
// 演示双路由中间件
router.GET("/", f1, index, f2) // 看一下路由的顺序
router.Run(":80")
}
- 运行结果:
- 运行结果分析: 首先next函数可以把原来的中间件分为多段,不同中间件的执行顺序就是next之前的首先执行(请求中间件),next函数之后的后执行(响应中间件),拦截函数就是一样(执行顺序: 从前往后执行请求中间件,从后往前执行相应中间件)
- 细节就是如果c.Abort()函数在第一个中间件的next函数的后面就相当于没有执行什么了(abort函数不会阻止当前中间件的执行),其实相当于递归函数的执行
- 画图分析:
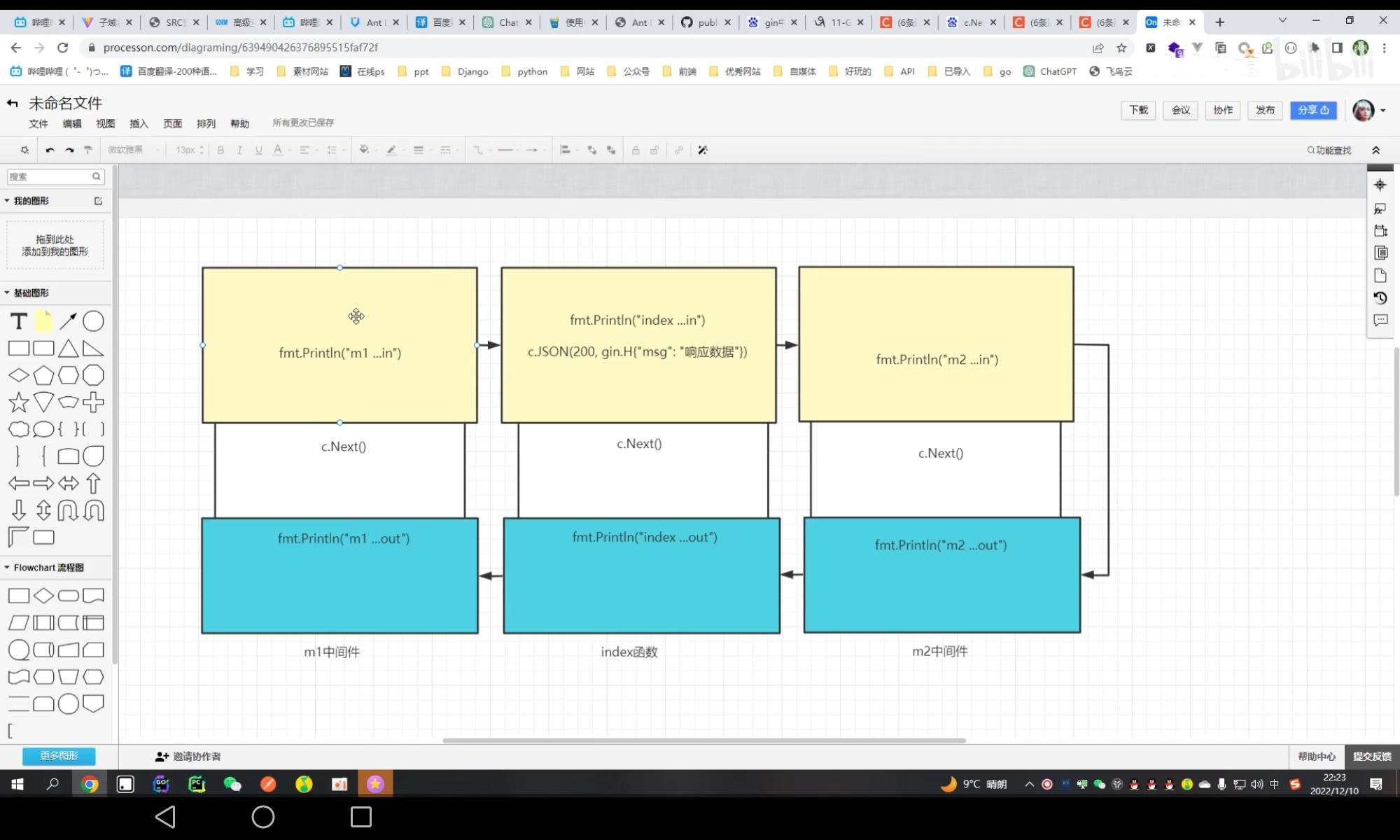
全局注册中间件
- 只用利用router.User函数就可以完成中间件的全局注册了,并且每一个中间件执行完了之前都会执行一遍全局中间件
- 全局中间件就相当于普通的中间件,执行顺序有绑定时间决定
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func f3(c *gin.Context) {
fmt.Println("全局中间件f3执行了")
c.Next()
fmt.Println("全局中间件f3执行结束了")
}
func f4(c *gin.Context) {
fmt.Println("全局中间件f4执行了")
c.Next()
fmt.Println("全局中间件f4结束了")
}
func main() {
// 用于演示全局注册中间件
router := gin.Default()
router.Use(f3,f4) // 这样就注册了全局中间件,全局中间就是
router.GET("/m1", func(c *gin.Context) {
fmt.Println("m1执行了")
c.Next()
fmt.Println("m1执行结束了")
})
router.Run(":80")
}
- 结果演示:
中间件传参
- 相当于一个全局应用域名,可以利用Set方式设置键值对,利用Get方法获得键值对
- 细节: 需要如果传递的参数不可以直接使用(比如结构体),就可以进行类型断言之后使用
- 代码演示:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
type User struct {
Name string
Age int
}
func f5(c *gin.Context) {
// 用于获取数据
fmt.Println("%p", c)
c.Set("user", User{
Name: "张三",
Age: 12,
})
}
func main() {
// 中间件传递数据
router := gin.Default()
router.Use(f5)
router.GET("/", func(c *gin.Context) {
// 获取变量
user, ok := c.Get("user")
// 类型断言
realUser, ok := user.(User)
fmt.Println("%p", c)
fmt.Println(realUser, ok)
})
router.Run(":80")
}
- 运行结果演示:

路由分组
- 就是根据路由控制的功能给路由分组,每一个组的路由执行的任务不同,分组的方法 api = router.Group,并且api之后还可以继续分组来表示不同的业务逻辑
- 细节: 用户访问时访问的路径前面还要加上api或者其他数据,利用api.GET()指定请之后的操作
- 代码演示:
package main
import "github.com/gin-gonic/gin"
// 定义需要使用的函数
type UserInfo struct {
Name string `json:"name"`
Age int `json:"age"`
}
type Article struct {
Title string `json:"title"`
Content string `json:"content"`
}
// 定义一个返回值
type Response struct {
Code int `json:"code"`
Data any `json:"data"`
Msg string `json:"msg"`
}
// 定义路由分组的操作
func UserList(c *gin.Context) {
c.JSON(200, Response{
Code: 0,
Data: []UserInfo{
{
Name: "张三",
Age: 12,
},
{
Name: "李四",
Age: 18,
},
},
Msg: "响应成功",
})
}
func ArticleList(c *gin.Context) {
c.JSON(200, Response{
Code: 0,
Data: []Article{
{
Title: "java",
Content: "java从入门到放弃",
},
{
Title: "python",
Content: "python从入门到放弃",
},
},
Msg: "响应成功",
})
}
func UserControl(api *gin.RouterGroup) {
// 定义一些操作用户的方法
usermanager := api.Group("user")
{
// 定义一个路由方法
usermanager.GET("/users", UserList)
}
}
func ArticleControl(api *gin.RouterGroup) {
// 定义一个操作文章的方法
articles := api.Group("article")
{
// 定义一个操作文章的方法
articles.GET("/articles", ArticleList)
}
}
func main() {
router := gin.Default()
api := router.Group("api") // 返回的就是一个路由组
UserControl(api)
ArticleControl(api)
router.Run(":80")
}
路由分组注册中间件
注意事项如下:
1. 首先注意注册全局中间件的方法: 直接在注册得到的路由组之后利用use方法就可以得到了想要的一个独属于这一个分组的路由中间件了
2. 注意注册的中间件只在这一个组中生效,中间件具有传递的作用,只要归属于这个组的其他组都可以使用这一个中间件
3. 另外 就是带上括号的中间件了,这一类中间件其实必须需要 返回一个gin.Handlefunc,也就是一个不到括号的中间件(匿名函数),好处 时可以使用闭包
代码演示:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
type Res struct {
Code int `json:"code"`
Data any `json:"data"`
Msg string `json:"msg"`
}
// 用户数据
type Userinfo struct {
Name string `json:"name"`
Age int `json:"age"`
}
// 返回一个列表,下划线开头的函数表示可以忽略这个函数可以重复定义
func _UserList(c *gin.Context) {
c.JSON(200, Res{
Code: 0,
Data: []Userinfo{
{
Name: "张三",
Age: 12,
},
{
Name: "李四",
Age: 18,
},
{
Name: "王五",
Age: 32,
},
},
Msg: "响应成功",
})
}
// 定义一个函数进行用户管理
func _Usercontrol(router *gin.RouterGroup) {
usermanager := router.Group("users")
// 注册全局中间件
usermanager.Use(Middleware("响应失败啦 ......"))
{
usermanager.GET("/user", _UserList)
}
}
func _TestMiddle(c *gin.Context) {
fmt.Println("测试中间件执行了")
}
// 开始定义一个全局中间件
func Middleware(msg string) gin.HandlerFunc {
// 这就是中间件的返回值
return func(c *gin.Context) {
// 首先拿到token
token := c.GetHeader("token") // Header函数的作用时设置响应头
if token == "1234" {
// 向后面响应
c.Next()
return
}
c.JSON(200, gin.H{"msg": msg})
c.Abort()
}
}
// 中间件
func main() {
// 演示给分组之后的路由注册中间件
// 中间件的注册方式
// 只需要分组时创建中间件该组中的中间件就可以使用了
// 另外就是中间件的另外一种写法 直接利用 middleware() 但是需要返回一个 gin.HandlerFunc
router := gin.Default()
api := router.Group("api")
api.Use(_TestMiddle)
_Usercontrol(api)
// 另外如果不使用中间件的情况
api.GET("/not", func(c *gin.Context) {
c.JSON(200, gin.H{"msg": "你居然不回走用户管理"})
})
router.Run(":80")
}
gin.Default()函数
- gin.Default的底层调用了gin.New()函数,同时New函数绑定了Logger()函数和Recovery()函数,分别用于日志的打印和信息回滚,但是如果利用New()函数需要自己设置日志的打印方式
- 底层代码演示:
日志
- 使用日志的原因:
- 记录用户操作,方便猜测用户行为
- 记录bug的位置
gin自带的日志系统
首先进行路由的重定向
- 路由默认是打印在控制台上比如:

- 可以自己创建一个文件,把路由文件的打印方向重定向到新的一个文件中,设置的代码如下(在 gin.Defalut之前加上重定向打印日志的功能)
file, _ := os.Create("gin.log")
gin.DefaultWriter = io.MultiWriter(file) // 这就是默认打印的重定向
- 结果演示:
自定义路由打印的格式的方法
- 直接操作路由打印的方法,是否类似于一个方法重写?,直接重定义另外一个方法,设置打印格式,代码演示如下:
package main
import (
"github.com/gin-gonic/gin"
"io"
"log"
"os"
)
func main() {
// 用于演示gin自带的日志系统
// 自定义路由的格式
gin.DebugPrintRouteFunc = func(httpMethod, absolutePath, handlerName string, nuHandlers int) {
log.Printf("[ loser ] %v %v %s %d", httpMethod, absolutePath, handlerName, nuHandlers)
}
file, _ := os.Create("gin.log")
gin.DefaultWriter = io.MultiWriter(file) // 这就是默认打印的重定向
router := gin.Default()
// 配置参数打印日志到文件系统
router.GET("/index", func(c *gin.Context) {
c.JSON(200, gin.H{"msg": "响应成功"})
}) // 日志会默认打印到控制台中
router.Run(":80")
}
- 结果演示:
自定义打印结果演示
- 自定义打印结果其实就是重新定义一个一个日志的打印方式,使得日志打印更加直观
- 此时需要把原来的Debug模式改为ReleseMode模式从而更好地打印日志
- 颜色的分析: 首先打印颜色,之后打印状态码,最后打印颜色即可
- 代码演示如下:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func main() {
// 用于演示gin自带的日志系统
// 自定义路由的格式
//gin.DebugPrintRouteFunc = func(httpMethod, absolutePath, handlerName string, nuHandlers int) {
// log.Printf("[ loser ] %v %v %s %d", httpMethod, absolutePath, handlerName, nuHandlers)
//}
//file, _ := os.Create("gin.log")
//gin.DefaultWriter = io.MultiWriter(file) // 这就是默认打印的重定向
// 设置模式不为调试模式
gin.SetMode(gin.ReleaseMode)
router := gin.New()
router.Use(gin.LoggerWithFormatter(func(params gin.LogFormatterParams) string {
// 自定以一个打印日志
return fmt.Sprintf(
"[FENG] %s|%s %d %s| %s %s %s %s\n",
params.TimeStamp.Format("2006-01-02 15:04:05"),
params.StatusCodeColor(), params.StatusCode, params.ResetColor(),
params.MethodColor(), params.Method, params.ResetColor(), // 用于输出颜色
params.Path,
)
}))
// 配置参数打印日志到文件系统
router.GET("/index", func(c *gin.Context) {
c.JSON(200, gin.H{"msg": "响应成功"})
}) // 日志会默认打印到控制台中
fmt.Println(router.Routes()) // 上面的函数其实就是回调函数
router.Run(":80")
}
- 结果演示:
查看路由:
- 就是利用router.routers()函数就可以获取日志组成的集合了
日志框架Logrus
引入方式
:::info go get github.com/sirupsen/logrus
:::
基本使用
- 可以打印出来同等级的日志信息 (Error Warnln Infof Debug Println),但是需要注意低于默认等级的日志信息就不会被打印出来
- 可以利用GetLevel获取日志等级,可以利用SetLevel设置日志等级
- 代码演示:
package main
import (
"fmt"
"github.com/sirupsen/logrus"
)
func main() {
// 演示Logrus功能
logrus.SetLevel(logrus.WarnLevel) // 设置打印等级,只有warn等级和error等级的日志才会输出
// 日志的等级基本和生产环境相似
logrus.Error("出错信息")
logrus.Warnln("警告")
logrus.Infof("信息")
logrus.Debug("调试信息")
logrus.Println("打印日志信息")
// 如果等级比Infof小的话就不会输出了
fmt.Println(logrus.GetLevel())
}
给日志信息设置特定的字段名称(参数)
- 可以利用Logrus.WithField方法设置参数,同时可以使用Log.WithFields()方法设置参数,但是注意后面一个方法需要的一个参数就是 logrus.fields{}
- 代码演示:
package main
import (
"github.com/sirupsen/logrus"
"time"
)
func main() {
// 可以指定每一条日志的信息,可以使用键值对表示
log := logrus.WithField("func", "app").WithField("time", time.Now())
log.Error("出错啦 ......")
// 还可以使用创建对象的方法定义一个数据
log1 := logrus.WithFields(logrus.Fields{
"user_id": "111",
"ip": "192.168.0.233",
})
log1.Error("log1出错啦")
}
- 运行结果演示:

显示特定格式
- 设置格式为json格式,可以直接利用logurs.SetFormatter( logrus.JSONFormatter{})
- 设置颜色和时间戳使用在TextFormatter中打开 响应的配置信息即可,并且不同的等级的颜色不同
- 颜色的设置可以使用 ASCI转义字符,如果像颜色这样的顺次定义的概念可以使用枚举 const集合,可以结合枚举结合打印函数进行输出(定义一个函数,传递相应的枚举名称就可以输出对应的颜色即可)
- 代码演示如下:
package main
import (
"github.com/sirupsen/logrus"
"time"
)
func main() {
// 可以指定每一条日志的信息,可以使用键值对表示
// 指定格式为json
logrus.SetFormatter(&logrus.JSONFormatter{}) // 得到的就是一个json格式的数据
logrus.SetFormatter(&logrus.TextFormatter{
ForceColors: true, // 设置颜色的方法,每一中等级的颜色可以不一样
FullTimestamp: true, // 设置时间戳格式
TimestampFormat: "2006-01-02 15:04:05", // 设置时间输出格式
})
log := logrus.WithField("func", "app").WithField("time", time.Now())
log.Error("出错啦 ......")
log.Warnln("警告 ......")
log.Debug("调试 ......")
log.Infof("重要信息 ......")
// 还可以使用创建对象的方法定义一个数据
log1 := logrus.WithFields(logrus.Fields{
"user_id": "111",
"ip": "192.168.0.233",
})
log1.Error("log1出错啦")
}
- 结果演示

自定义日志格式
输出日志信息到文件中
- 设置文件输出的位置的方法主要就是使用Setoutput方法,之后的参数就是重定向之后的位置,可以是文件输入流io,也可以是标准输出流 stdout
- 代码如下:
package main
import (
"github.com/sirupsen/logrus"
"io"
"os"
)
func main() {
// 日志重定向到文件中,注意路径的选择
file, _ := os.OpenFile("/info.log", os.O_CREATE|os.O_APPEND, 0666) // 用于指定文件的权限和读写
//logrus.SetOutput(file)
// 同时设置日志的方向为文件和控制台
logrus.SetOutput(io.MultiWriter(file, os.Stdout)) // 标准输出流和文件中都有日志啦,这一支持可变参数
// 开始输出
logrus.Error("出错啦")
logrus.Warnln("警告啦")
// ln结尾的就是自动换行
logrus.Infof("重要信息")
}
- 结果演示:
自定义输出格式
- 看一下前面定义格式的方法,这里需要定义自己的formatter格式,这里就是利用一个结构体定义一个formatter,这一个结构体需要实现Format方法才可以被使用,Format方法中的一个参数就是entry,相当于当前操作的对象,具体操作如下,返回值必须是一个字节数组
- 显示行号只需要从entry中取出行号对象即可 entry.Caller.File和entry.Caller.Line
- 另外注意空结构体中可以承装对象,盛装的对象可以用于自定义信息的显示
- 代码演示 :
package main
import (
"bytes"
"fmt"
"github.com/sirupsen/logrus"
"path"
)
const (
CBlack = iota
CRed
CGreen
CYellow
CBlue
CPurple
CCyan
CGray
)
type MyFormatter struct {
// 首先设置颜色
prefix string
fomatter string
}
// 重写Formatter方法
func (f MyFormatter) Format(entry *logrus.Entry) ([]byte, error) {
// 设置颜色,entry表示当前对象
var color int
switch entry.Level {
case logrus.ErrorLevel:
color = CRed
case logrus.WarnLevel:
color = CYellow
case logrus.InfoLevel:
color = CGreen
case logrus.DebugLevel:
color = CPurple
default:
color = CGray
}
// 设置缓冲区
var b *bytes.Buffer
if entry.Buffer == nil {
// 初始化
b = &bytes.Buffer{}
} else {
b = entry.Buffer
}
// 设置时间格式
format := entry.Time.Format(f.fomatter)
// 设置文件的行号等信息
// entry中的信息挺全的
finVal := fmt.Sprintf("%s %d", path.Base(entry.Caller.File), entry.Caller.Line) // 设置行号的显示
// 设置路径
fmt.Fprintf(b, "[%s] \033[3%dm[%s]\033[0m [%s] %s %s\n", f.prefix, color, entry.Level, format, entry.Message, finVal)
return b.Bytes(), nil
}
func main() {
// 还是需要利用setFormatter方法定义格式
// 开启行号显示
logrus.SetReportCaller(true)
logrus.SetLevel(logrus.DebugLevel)
logrus.SetFormatter(&MyFormatter{prefix: "GORM", fomatter: "2006-01-02 15:04:05"})
logrus.Error("出错啦")
logrus.Debug("调试啦")
logrus.Infof("信息来啦")
logrus.Warnln("警告")
}
- 结果演示:

Hook机制
- Hook机制,通过初始化时为logrus添加hook,logrus可以实现各种拓展功能
- Hook其实就是一个接口,接口中的属性包含功能覆盖的字段和entry对象
- 实现的Levels方法返回的就是一个类型切片,这个类型切片中可以定义需要操作的类型,Fire函数就是对已经选择的类型进行操作的函数
- 代码演示如下:
package main
import (
"fmt"
"github.com/sirupsen/logrus"
"os"
)
type MyHook struct {
}
// 注意事项方法 Levels 和 Fire
func (MyHook) Levels() []logrus.Level {
// 设置生效范围
return []logrus.Level{logrus.ErrorLevel}
}
func (MyHook) Fire(entry *logrus.Entry) error {
// 定义打印信息时的行为
fmt.Println(entry.Level)
// 还可以设置属性
//entry.Data["app"] = "hello"
// 实现把错误日志写入到文件中
file, _ := os.OpenFile("error.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666)
line, _ := entry.String()
file.Write([]byte(line)) // 写入信息到文件中
return nil
}
func main() {
logrus.AddHook(&MyHook{})
logrus.Warnln("警告")
logrus.Error("错误")
}
日志分割
日志时间分割
待定
gin框架集成logrus
注意参考: Mysql多表查询总结
gorm官方文档 特别需要注意的是注意关联模式和预加载模式,这一部分需要查看官方文档
关联模式
- 关联模式一般就是指的各种不同对象在数据库表之间的关系,包含一对一,一对多和多对多的关系,一般来说利用
Create方法插入对象的时候就会自动插入和这一个对象关联的对象到数据库表中,同时gorm中提供了各种更新关联,删除关联数据还有查询关联数据的方法(依赖于Association方法),这里讨论的关联模式主要是通过外键实现的
预加载
Preload: 主要用于预先加载关联的数据Joins: 利用left join来关联数据- 但是这两者都只可以用于一对一关系的情况下
一对一
go数据库表实例对象的定义:
type Sin_a struct {
Aid int `gorm:"primary_key;AUTO_INCREMENT;column:aid"`
Name string `gorm:"column:name"`
Age int `gorm:"column:age"`
Sb Sin_b `gorm:"foreignkey:A_id"`
}
type Sin_b struct {
Bid int `gorm:"primary_key;AUTO_INCREMENT;column:bid"`
Password string `gorm:"column:password"`
Birthday string `gorm:"column:birthday"`
A_id int `gorm:"column:a_id"`
}
func (s Sin_a) TableName() string {
return "sin_a"
}
func (s Sin_b) TableName() string {
return "sin_b"
}
- 相关的
CURD操作
func Add() {
// 添加数据
sa := Sin_a{
Name: "Andy",
Age: 30,
Sb: Sin_b{
Password: "12345",
Birthday: "1990-10-10",
},
}
err := DB.Create(&sa).Error
if err != nil {
fmt.Println("create failed !")
}
}
func Update() {
// 更新数据,只可分开更新
sa := Sin_a{
Aid: 4,
Name: "Andkkk",
Age: 50,
}
// 首先更新 sa err := DB.Updates(&sa).Error
if err != nil {
fmt.Println("update failed !")
}
// 之后可以更新 sb err = DB.Model(&Sin_b{}).Where("a_id = ?", sa.Aid).Updates(map[string]interface{}{
"password": "2222",
"birthday": "1990-10-21",
}).Error
if err != nil {
fmt.Println("update failed !")
}
}
func Query() {
var sa Sin_a
// Preload中写结构体关联字段的名称
err := DB.Debug().Preload("Sb").Find(&sa, "aid = ?", 2)
if err != nil {
fmt.Println(err.Error)
}
fmt.Println(sa)
}
// 利用 Query2 进行查询
func Query2() {
var sa Sin_a
err := DB.Debug().Joins("Sb").Find(&sa, "aid = ?", 3).Error
if err != nil {
fmt.Println(err)
}
fmt.Println(sa)
}
// 删除数据
func Delete() {
err := DB.Debug().Delete(&Sin_a{}, "aid = ?", 4)
if err != nil {
fmt.Println(err)
}
}
- 注意使用预加载模式的时候,
Preload和Joins的参数是被关联的结构体的对象名称,这里就是Sb一定要注意这一点!,另外更新操作可以直接对于另外一张表进行操作,也可以使用Association关联模式进行操作 - 注意利用
Preload和Joins产生的sql语句的区别:
-- Preload
-- 首先进行预加载,之后进行查询
SELECT * FROM `sin_b` WHERE `sin_b`.`a_id` = 2
SELECT * FROM `sin_a` WHERE aid = 2
-- Joins
-- 只会使用一条sql语句,效率更高
SELECT `sin_a`.`aid`,`sin_a`.`name`,`sin_a`.`age`,`Sb`.`bid` AS `Sb__bid`,`Sb`.`password` AS `Sb__password`,`Sb`.`birthday` AS `Sb__birthday`,`Sb`.`a_id` AS `Sb__a_id` FROM `sin_a` LEFT JOIN `sin_b` `Sb` ON `sin_a`.`aid` = `Sb`.`a_id` WHERE aid = 3
- 一对一关系中更新数据,最好还时使用分开更新的方式,也就是首先更新主表中的数据,之后利用
DB.Model(&Sin_b{}).Where("a_id = ?",aid).Updates(数据)的方法进行数据的更新,Association主要用于一对多关系的更新
一对多
- 结构体的建立:
type Many_a struct {
Aid int `gorm:"column:aid;primaryKey;AutoIncrement"`
Name string `gorm:"column:name"`
Age int `gorm:"column:age"`
Mbs []Many_b `gorm:"foreignKey:A_id"`
}
type Many_b struct {
Bid int `gorm:"column:bid;primaryKey;AutoIncrement"`
ClassName string `gorm:"column:classname"`
A_id int `gorm:"column:a_id;"`
}
func (ma Many_a) TableName() string {
return "many_a"
}
func (mb Many_b) TableName() string {
return "many_b"
}
- 对于一对多关系的增删改查的方式:
func Query_Preload() {
// 利用 Preload 进行查询
var ma Many_a
err := DB.Debug().Preload("Mbs").Where("aid = ?", 1).Find(&ma).Error
if err != nil {
fmt.Println(err)
}
fmt.Println(ma)
}
// 底层通过反射机制拿到结构体,的那是不可以对于切片使用反射
//
// func Query_Joins() {
// // 利用 Joins 进行查询
// var ma Many_a
// err := DB.Debug().Joins("Mbs").Where("aid = ?", 2).Find(&ma).Error
// if err != nil {
// fmt.Println(err)
// }
// fmt.Println(ma)
// }
func Create_Many() {
// 增加数据
// 直接增加即可
// 注意此时外键和主键都不用写
mb := Many_b{
ClassName: "大学物理",
}
ma := Many_a{
Name: "赵六",
Age: 22,
Mbs: []Many_b{mb},
}
err := DB.Debug().Create(&ma).Error
if err != nil {
fmt.Println(err)
}
}
// 同时更新多个字段使用 Updates , 更新单个字段使用 Update,更新关联值使用Association方法
func Update_Many() {
// 更新数据
// 可以使用 Association 进行更新,这里可以演示 Append 操作,当然还有很多其他的操作
ma := Many_a{
Aid: 4,
Name: "赵七",
}
err := DB.Debug().Updates(&ma).Error
err = DB.Debug().Model(&ma).Association("Mbs").Append(&Many_b{
ClassName: "复变函数与积分变化",
})
if err != nil {
fmt.Println(err)
}
}
// 删除操作,但是有外键的情况下不允许删除
func Delete_Many() {
err := DB.Debug().Where("aid = ?", 1).Delete(&Many_a{})
if err != nil {
fmt.Println(err)
}
}
- 注意此时由于
Joins底层使用反射机制获取到结构体中所有的值和标签,所以对于切片来说,无法利用反射获取到所有值,所以不可以使用Joins方法进行查询操作 - 更新单个值使用
Update,更新多个值使用Updates,更新关联值使用Association(可以进行Append,Count等操作),利用Save操作表示没有数据就创建数据,有数据就更新数据但是不可以与Model一起使用Associatoin执行的时候的SQL语句:
UPDATE `many_a` SET `name`='赵七' WHERE `aid` = 4
INSERT INTO `many_b` (`classname`,`a_id`) VALUES ('复变函数与积分变化',4) ON DUPLICATE KEY UPDATE `a_id`=VALU)
多对多关系
- 建立结构体(注意使用
JoinForeignKey和JoinReferenceKey来指定中间表中的外键名称,否则使用默认的外键名称):
// 注意建立中间表的结构
// 建立中间表之后 joinForeignKey 表示连接到中间表的外键,JoinReferences 表示参照中间表的参考字段
type MM_a struct {
Aid int `gorm:"column:aid;primaryKey;AutoIncrement"`
Name string `gorm:"column:name"`
Age int `gorm:"column:age"`
Mbs []MM_b `gorm:"many2many:many2many;joinForeignKey:A_id;JoinReferences:B_id"`
}
type MM_b struct {
Bid int `gorm:"column:bid;primaryKey;AutoIncrement"`
ClassName string `gorm:"column:classname"`
Mas []MM_a `gorm:"many2many:many2many;joinForeignKey:B_id;JoinReferences:A_id"`
}
type M2M struct {
Cid int `gorm:"column:cid;primaryKey;AutoIncrement"`
A_id int `gorm:"column:a_id"`
B_id int `gorm:"column:b_id"`
}
func (m2m M2M) TableName() string {
return "many2many"
}
func (ma MM_a) TableName() string {
return "mm_a"
}
func (mb MM_b) TableName() string {
return "mm_b"
}
CRUD方法:
// 还是需要按照需要进行查询
func Query_Many2Many() {
var ma MM_a
err := DB.Debug().Preload("Mbs").Find(&ma, 1).Error
var mb MM_b
err = DB.Debug().Preload("Mas").Find(&mb, 1).Error
if err != nil {
fmt.Println(err)
}
fmt.Println(ma)
fmt.Println(mb)
}
// 更新数据,还是需要根据关联进行更新
func Create_Many2Many() {
mb := MM_b{
ClassName: "c7",
}
ma := MM_a{
Name: "小明",
Age: 23,
Mbs: []MM_b{mb},
}
err := DB.Debug().Create(&ma).Error
if err != nil {
fmt.Println(err)
}
}
func Update_Many2Many() {
// 首先更新 MM_a ma := MM_a{
Aid: 2,
Name: "z111",
Age: 33,
}
err := DB.Debug().Updates(&ma).Error
if err != nil {
fmt.Println(err)
}
// 更新后面的表,直接更新即可
// 如果想要更新
err = DB.Debug().Model(&MM_b{}).Where("classname = ?", "c5").Update("classname", "c55").Error
if err != nil {
fmt.Println(err)
}
}
func Update2_Many2Many() {
// 利用 Association 进行添加
ma := MM_a{Aid: 5}
var mb MM_b
err := DB.Debug().Model(&MM_b{}).Where("classname = ?", "c4").Find(&mb).Error
err = DB.Debug().Model(&ma).Association("Mbs").Append(&mb)
if err != nil {
fmt.Println(err)
}
}
func Delete_Many2Many() {
err := DB.Debug().Delete(&MM_a{Aid: 2}).Error
if err != nil {
fmt.Println(err)
}
}
总结: 在多表关系的
CURD中,注意关联模式和预加载:Preload首先会把另外一张表的关联值查询得到Joins底层使用反射机制进行left joins进行查询,所以只可以用于一对一的情况Association用于一对多和多对多的关系,主要用于更新一个结构体中的关联的另外的一个结构体数据(更新,替换或者插入等操作)
- 各种不同情况下的更新策略:
- 一对一关系: 更新是分别更新两个表的数据,也就是利用
Model定位不同的表 - 一对多关系: 首先更新单张表,之后利用
Association更新关联的表(必要的时候可以首先查询) - 多对多关系: 同上(但是注意中间表的定制化!!!)
- 一对一关系: 更新是分别更新两个表的数据,也就是利用
前言
ORM
- orm是一种对象关系映射,它解决了对象和关系型数据库之间的数据交互内容,简单来说就是利用一个类来表示一张表,类中的属性表示表中的字段,使用操作对象的方法操作数据库与自己手动编写sql相比,优势更加明显,但是自动生成sql语句还是会对性能有一些影响,一般比较复杂的数据库还是需要自己编写sql语句
下载gorm框架并且连接数据库
下载gorm框架的依赖
go get gorm.io/driver/mysql // 下载mysql的驱动
go get gorm.io/gorm // 下载gorm框架
go get github.com/jinzhu/gorm // 另外一个up主的方法,最好利用上面一个方法导入mysql的驱动
- 下载完成之后的go mod
连接数据库的操作
- 具体方法: 利用gorm.Open方法连接数据库
- 细节: 注意参数的设置 “用户名:密码@tcp(ip:port)数据库名称/charset=utf8&parseTime=True&loc=Local ,还需要导入mysql的驱动 github.com/jinzhu/gorm/dialects/mysql
- 代码演示如下:
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql" // 加载mysql的驱动,前面加上一个_表示忽略内容
)
func main() {
// 1. 连接数据库 test_jdbc
// Open的参数,需要出入两个信息:
// 参数1: 需要连接的数据库
// 参数2: 指的是数据库的设置信息,利用键值对的形式传参: 用户名:密码@tcp(ip:port/数据库名称)?charset=utf8&parseTime=True&loc=Local
// charset指定使用的字符集
// parseTime表示处理time.Time类型
// loc = local表示设置本地时区 注意使用的open函数第一个参数为 dialect
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
// db的类型是一个指针,具体作用是之后再说
if err != nil {
fmt.Println("数据库连接失败")
panic(err) // 利用panic可以结合错误终止程序
}
defer db.Close() // 注意利用演示函数释放空间
}
创建表,删除表,判断表是否存在
- 利用 db.CreateTable(&结构体{})方法创建表 利用db.Table(表名).CreateTable(&结构体{}) 创建表
- 利用db.dropTable(&结构体{})删除默认创建的表 db.dropTable(表名)删除表
- 利用db.HasTable(&结构体{})查看是否存在利用默认创建的表,利用db.HasTable(表名)通过表名判断是否有删除的表
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql" // 加载mysql的驱动,前面加上一个_表示忽略内容
)
// 定义一个结构体进行映射
type User struct {
Name string
Age int
}
func main() {
// 1. 连接数据库 test_jdbc
// Open的参数,需要出入两个信息:
// 参数1: 需要连接的数据库
// 参数2: 指的是数据库的设置信息,利用键值对的形式传参: 用户名:密码@tcp(ip:port/数据库名称)?charset=utf8&parseTime=True&loc=Local
// charset指定使用的字符集
// parseTime表示处理time.Time类型
// loc = local表示设置本地时区 注意使用的open函数第一个参数为 dialect
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
// db的类型是一个指针,具体作用是之后再说
if err != nil {
fmt.Println("数据库连接失败")
panic(err) // 利用panic可以结合错误终止程序
}
defer db.Close() // 注意利用演示函数释放空间
// 创建一个表
// 通常情况下,创建的表名就是结构体的复数形式,但是小写
db.CreateTable(&User{}) // 利用对象映射出一个表,名称都是默认的
// 自己指定表的名称,利用Table方法指定表名
db.Table("myusers").CreateTable(&User{}) // 感觉提供对象用于反射
// 删除表名
db.DropTable(&User{}) // 删除一个表,但是只可以删除利用原始名称创建的一张表
// 通过名称删除表
db.DropTable("myusers") // mysql中都是小写的
flags1 := db.HasTable(&User{}) // 判断是否有第一种方式创建的表
fmt.Println(flags1)
flags2 := db.HasTable("myusers") // 通过名称判断
fmt.Println(flags2)
}
数据库的增删改查
- 首先创建一个结构体对象 var myUser User
- 增加数据 db.Create(&User{Name:"张三",Age:19})
- 查询数据 db.First(&myUser,"age = ?" ,19) // 利用占位符提供的条件
- 修改数据 必须在得到数据之后进行修改: db.Model(&myUser).Update("字段名称",修改之后的值)
- 删除数据 还是在查询之后 进行: db.Delete(&myUser) // 其实就是删除对应查询到的字段,无论是删除还是更新,首先要得到需要操作的一行数据(其实就是查询这一行记录)
// 数据库的增删改查方法
// 增加:
db.Create(&User{Name: "张三", Age: 18})
// 查询数据
var myUser User
db.First(&myUser, "age = ?", 18)
fmt.Println(myUser)
// 更新数据
// 首先查询之后更新
db.Model(&myUser).Update("age", 23)
db.Model(&myUser).Update("name", "李四")
// 删除数据
// 还是需要先查询之后删除
db.Delete(&myUser)
对于表名的阐述:
模型名和表名的映射规则
模型名和表名的映射规则如下:
- 如果模型名没有驼峰命名,那么模型名就是 小写+复数形式 (user -> users)
- 如果模型名有驼峰命名,那么表名就是变成小写之后大写字段前面加上_ (UserInfo -> user_info)
- 如果有连续的大写和驼峰命名,就会将大写变为小写在驼峰的头部加上 _ (DBUSerInfo -> db_user_info)
自定义表名
- 需要自定义表名只用重写TableName方法就可以了,毕竟go语言中实现接口只用实现其中方法就可以了
type User struct {
Name string
Age int
}
func (user *User) TableName() string {
return "test_user_name"
}
gorm.Mobel匿名字段
- 作用: 其实就是默认给自己的表添加另外四个字段,就是添加gorm.model字段之后默认添加了四个字段: ID,CreateAt,UpdatedAt,DeletedAt字段
- ID : 主键自增长
- CreateAt: 用于记录存储记录的创建时间
- UpdatedAt: 用于存储记录的修改时间
- DeletedAt: 用于记录删除记录的时间
type User struct {
Name string
Age int
gorm.Model
}
结构体标签gorm
- gorm标签的作用: 给表中的字段添加索引和各种约束,以及指定初始值
- 语法:
gorm:"条件1;条件2;待设置的属性:属性值 - 代码演示如下:
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
type Student struct {
// 其实就是 利用`gorm:"约束1;约束2;约束3;索引:索引名称;长度:长度值"
// 和gin框架中的json标签的作用类似
StuID int `gorm:"primary_key;AUTO_INCREMENT"` // 设置主键,自增
Name string `gorm:"not null"`
Age int `gorm:"index:name_index"` // 创建索引时可以添加一个名字,只用利用 : 指定索引名称即可
Email string `gorm:"unique_index"` // 创建唯一索引
Sex string `gorm:"unique;column:gender;size:10"` // 添加一个唯一约束,同时利用column:指定列名,利用size设置默认长度
Desc string `gorm:"-"` // 表示直接在数据库中忽略
classID string `gorm:"type:int"` // 定义一个类型
}
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
fmt.Println("数据库连接失败")
panic(err)
}
defer db.Close()
db.CreateTable(&Student{})
}
gorm框架中各种表之间的映射关系
一对一映射
- 其实就是一个表对应一张表,并且是一一对应的,就是利用外键关联别人的主键,并且这个外键也是唯一的
- 方式1: 类中指定字段和外键名称,但是需要规范外键名称
- 方式2: 利用gorm标签 gorm:"ForeignKey:外键字段名;AssociationForeKey:UserId" 后面一个需要规范命名
- 注意的规范就是: 需要关联的对象实例 需要关联的对象类型名 'gorm:"ForeignKey:需要关联的外键(其实就是需要关联对象中的一个键);AossicationForeignKey:自己的一个字段名称" // 这样的话 ForeignKey就是关联了AssociationForeignKey了
代码演示
-- 结构体
package main
type User struct {
id int `gorm:"primary_key;AUTO_INCREMENT"`
Name string
Age string
// 关联写下面一个字段,指定关系不在同一个表示包含关系
IID int
}
type UserInfo struct {
InfoID int `gorm:"primary_key;AUTO_INCREMENT"`
Pic string
Address string
Email string
// 关联关系
User User `gorm:"ForeignKey:IID;AssociationForeignKey:InfoID"` // 注意之后的字段名称的写法
// 含义就是外键是其他表中关联的键,但是关联的外键就是自己的键
// 我感觉突然明白了外键名称和外键字段名称之间的关系
// 指定外键,只用在关联关系之后指定外键
// UserID int // 相当于创建一个字段作为外键,其实并没有强制加入外键,只是建立了关联关系
// 如果用上面的方法定义名称一定要是 表名 + 主键名
}
-- 建表
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 创建表,注意两个表都要创建并且两个表部分顺序
db.CreateTable(&User{})
db.CreateTable(&UserInfo{})
// 建立关联关系
}
一对多
- 一个表对应另外一个表中的多个字段,就是外键不一定有唯一约束或者主键约束
- 首先创建两个结构体,把作为一的一个结构体的中的一个成员写成另外一个对应多的结构体组成的数组,另外利用gorm标签添加外键约束即可
- 代码演示如下:
package main
type Author struct {
AID int `gorm:"primary_key;AUTO_INCREMENT"`
Name string
Age int
Sex string
// 关联关系
Article []Article `gorm:"ForeignKey:AuId;AssociationForeignKey:AID"` // 建立外键约束
}
type Article struct {
ArdId int
Title string
Content string
Desc string // 表示结构
// 设置外键: 如上
/**
创建之后字段不会显示,而是默认就会添加一个外键约束,用于多表查询
*/
AuId int // 这就是外键,基本和上面的方法一致,一般外键和主键不一样
}
多对多
- 类似学生和课程表之间的关系,需要一张中间表进行操作,中间表的中两个外键分别关联两张表
- 常见过程基本和一对多类似,但是需要改变后面的gorm标签,把gorm标签改为多表的情况,同时必须添加主键约束作为中间表的字段 (gorm:"many2many:Student2Course)
- 注意此时创建关联的方式: 直接利用标签进行创建,但是因为中间表中的两个字段都是两个表中的主键,所以应该设置主键自增 gorm:"many2many:Student2Course"
- 此时查询的操作在学生表中进行可以
- 代码演示:
package main
// 学生表
type Student struct {
SId int `gorm:"primary_key;AUTO_INCREMENT"` // 此时一定需要指定主键,否则就不会生成一个表
SNo int
Name string
Sex string
Age int
// 开始关联一个表
Course []Course `gorm:"many2many:Student2Course"` // 其实就是一对多的外键约束改成了一个标签约束
}
// 课程表
type Course struct {
CId int `gorm:"primary_key;AUTO_INCREMENT"`
CName string
TeacherName string
Room string
}
- 结果演示
与映射关系有关的各种表的操作
与一对一关系有关的操作
添加关联操作
- 总结以下其实就是初始化其中一个实例对象,就是其中有一个成员是两外一个结构体的哪一个对象
- 总结一下外键创建方法,gorm标签中,外键名称就是另外一个表中你要关联的字段,association后面的就是本表中的字段,其实三种关联方式大同小异
- 直接初始化一个对象,利用create方法create(&struct)即可得对应效果
- 代码演示如下
// 结构体创建
package main
type User struct {
id int `gorm:"primary_key;AUTO_INCREMENT"`
Name string
Age int
// 关联写下面一个字段,指定关系不在同一个表示包含关系
IID int // 最为外键
}
type UserInfo struct {
InfoID int `gorm:"primary_key;AUTO_INCREMENT"`
Pic string
Address string
Email string
// 关联关系
User User `gorm:"ForeignKey:IID;AssociationForeignKey:InfoId"` // 注意之后的字段名称的写法,其实就是给原来的外键起别名 // 我感觉突然明白了外键名称和外键字段名称之间的关系
// 动一下脑子想一下,外键要关联的对象是什么
// 指定外键,只用在关联关系之后指定外键
// UserID int // 相当于创建一个字段作为外键,其实并没有强制加入外键,只是建立了关联关系
// 如果用上面的方法定义名称一定要是 表名 + 主键名
}
// 具体操作
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 创建表
db.CreateTable(&User{})
db.CreateTable(&UserInfo{})
// 对于一对一映射的操作: 关联添加数据
userInfo := UserInfo{
Pic: "/upload/hello.png",
Address: "湖北武汉",
Email: "111222",
User: User{
Age: 18,
Name: "张三",
},
}
// 开始添加数据
db.Create(&userInfo) // 创建即可,注意接口的妙用,直接添加一个数据就可以添加数据
}
查询数据
- 其实查询数据的逻辑就是首先利用Id查到主键,之后利用主键作为外键查询数据
- 注意首先查询主键的操作必不可少,之后查询外键的操作依赖于 查询逐渐的操作
- 主键: db.First(&myUser,条件,占位符) 外键 db.Model(&userInfo).Asscation("关联的结构体名").Find(&userInof.User)
- 利用Debug查看原生sql
- 代码演示:
package main
/**
查询方式:
1. 首先查询主键
db.First(&userinfo,条件)
db.Model(&userinfo).Association("User").Find(&userinfo.User)
2. 利用preload方法进行查询
db.PreLoad("User").First(&userinfo,"条件")
3. 利用Related查询
// 首先查询主键
db.First(&useinfo,条件)
db.Model(&userinfo).Relate(&user,"User")
*/
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 创建表
/*db.CreateTable(&User{})
db.CreateTable(&UserInfo{})*/
//// 对于一对一映射的操作: 关联添加数据
//userInfo := UserInfo{
// Pic: "/upload/hello.png",
// Address: "湖北武汉",
// Email: "111222",
// User: User{
// Age: 18,
// Name: "张三",
// },
//}
//// 开始添加数据
//db.Create(&userInfo) // 创建即可,注意接口的妙用,直接添加一个数据就可以添加数据
// 查询操作
// 关联关系再UserInfo中,所以查询也要在UserInfo中
var userInfo UserInfo
db.Debug().First(&userInfo, "info_id = ?", 1)
// 如果执行上面操作得不到User信息
fmt.Println(userInfo)
// 如果得到User,就要执行下面的信息,注意两个都需要执行,利用Debug可以找到对应的sql语句
db.Debug().Model(&userInfo).Association("User").Find(&userInfo.User) // 其实就是查询得到的字段应该存储到哪里
fmt.Println(userInfo)
}
利用preLoad查询
- 就是利用preLoad提前 加载 db.Debug().preLoad("User").Find(&userInfo,条件,占位符号)
- 但是原理还是两个sql
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 利用preLoad函数进行一次查询
var userInfo elemType.UserInfo
db.Debug().Preload("User").Find(&userInfo, "info_id = ?", 1)
fmt.Println(userInfo)
}
利用Related函数查询
- 其实就是构建一个新的User把信息 单独存入到这个对象中
- 首先还是要得到userInfo对象,之后 db.First(&userInfo).Related(&user,"User")
- 代码演示:
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 利用relate方法进行查询
var userInfo elemType.UserInfo
db.First(&userInfo,"info_id = ?",1)
var user elemType.User
// 其实就是构建一个新的容器
// 但是可以把这个字段单独存储
// 通过userInfo模型查出来的User字段信息放入到新的user容器中
db.Model(&userInfo).Related(&user,"User");
}
关联更新
- 还是利用model指定操作对象,之后利用Update方法进行操作
- 代码演示
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 演示关联更新操作
// 1. 首先查询数据
var userInfo elemType.UserInfo
db.Preloads("User").First(&userInfo, "info_id = ?", 1)
fmt.Println(userInfo)
// 先查询之后更新
db.Model(&userInfo.User).Update("age", 12) // 其实就是进行一个关联更新
fmt.Println(userInfo)
}
关联删除操作
- 首先明白关联的市值就是在一个结构体中定义另外一个变量,这一个变量就可以用于更新删除操作,其实 struct1.struct2就是一个结构体
- 利用deleted方法删除
- 代码演示
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 演示删除操作
var userinfo elemType.UserInfo
db.Preload("User").Find(&userinfo, "info_id = ?", 1)
// 开始删除
// 可以根据userinfo模型删除User记录
db.Delete(&userinfo.User) // 但是userinfo中的信息没有被删除
// 如果要删除全部 就可以之间删除
db.Delete(&userinfo)
}
一对多的表的操作
关联添加
- 前面结构体的创建是错误的
- 结构体的创建和添加字段的代码如下
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 用于演示关联添加操作
// 一个作者对象多个关系,操作作者表即可
author := elemType.Author{
Name: "张三",
Age: 30,
Sex: "男",
Article: []elemType.Article{
{
Title: "hello world",
Content: "你好 世界",
Desc: "没有", // 关联外键
},
{
Title: "hello css",
Content: "你好 css",
Desc: "有", // 关联外键
},
},
}
db.Create(&author)
}
-- 结构体
package elemType
type Author struct {
AID int `gorm:"primary_key;AUTO_INCREMENT"`
Name string
Age int
Sex string
// 关联关系
Article []Article `gorm:"ForeignKey:AuId;AssociationForeignKey:AID"` // 建立外键约束
}
type Article struct {
ArId int
Title string
Content string
Desc string // 表示结构
// 设置外键:
AuId int
}
关联查询
- 基本和一对多关系一致,至少Assciation方法和PreLoad方法一致,Related方法唯一不同就是关联对象不同,这里关联的就是一个切片
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 用于演示一对多查询操作
// Association方式
// 必须操作Author
//var author elemType.Author
//db.First(&author,"a_id = ?",1)
//fmt.Println(author)
//db.Model(&author).Association("Article").Find(&author.Article)
//fmt.Println(author)
// 利用PreLoad方式查询
//var author elemType.Author
//db.Preloads("Article").Find(&author,"a_id = ?",1)
// 利用Related方法进行查询
var author elemType.Author
var articles []elemType.Article
// 首先查询
db.First(&author, "a_id = ?", 1)
// 唯一不同点就是这里用一个切片接收信息
db.Model(&author).Related(&articles, "Article") // 唯一不同就是使用切片接受
fmt.Println(author)
fmt.Println(articles)
}
关联更新
- 基本操作和上面一致,但是需要利用where条件限定(db.Model(操作对象).Where(条件).Update(字段名,新的值)
- 代码演示
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 首先查询之后更新
var author elemType.Author
db.Preload("Article").Find(&author,"a_id = ?",1)
// 如果直接利用update操作,关联操作就会全部显现
//db.Model(&author.Article).Update("title","java从入门到精通")
// 必须加上一个更新操作
// 需要加上一个条件进行限定,利用where限定
db.Model(&author.Article).Where("ar_id = ?",1).Update("title","python机器学习")
}
关联删除
- 还是基本和上面一致,但是一对多的模型,为了筛选出需要删除的模型,必须利用where函数过滤
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 首先查询之后更新
var author elemType.Author
db.Preload("Article").Find(&author, "a_id = ?", 1)
// 查询之后删除
db.Where("ar_di = ?", 2).Delete(&author.Article)
}
多对多
关联添加
- 还是一样的原- 则,关联关系在哪一个表中,就要创建那一个表的对象,直接创建
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 关联添加操作,关系在哪一个表中就要操作哪一个结构体
stu := elemType.Student{
SNo: 1002,
Name: "张三",
Sex: "女",
Age: 18,
Course: []elemType.Course{
{
CName: "python",
TeacherName: "hello",
Room: "s111",
},
{
CName: "java",
TeacherName: "olleh",
Room: "s111",
},
},
}
db.Create(&stu)
}
查询,更新,删除操作
- 基本和上面一致
- 代码演示
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 查询操作
var stu elemType.Student
// 1. Association方法
db.First(&stu, "s_id = ?", 1)
db.Model(&stu).Association("Course").Find(&stu.Course)
fmt.Println(stu)
// 2. 利用preLoad方法
db.Preload("Course").Find(&stu,"s_id = ?",1)
fmt.Println(stu)
//// 3. 利用Related方法
var course elemType.Course
db.Related(&course,"Course").Find(&stu.Course)
// 更新操作
// 1. 查询
db.Preload("Course").Find(&stu, "s_id = ?", 1)
db.Model(&stu.Course).Where("c_id = ?", 1).Update("c_name", "golang")
// 2. 删除
db.Preload("Course").Find(&stu, "s_id = ?", 1)
db.Where("c_id = ?", 1).Delete(&stu.Course)
}
gorm中的常见方法
First,FirstOrCreate,Last,Take,Find方法
- 都是用于查询的方法但是查询的方式和结果不同,看名字应该知道
- 细节: golang中结构体中成员的私有或者公有化其实就是通过大小写字母确定的,一定要知道这一点
- Find可以查询出多个方法
- 代码演示:
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// First方法 sql SELECT * FROM `users` WHERE `users`.`user_id` = 1 AND ((user_id = 1)) ORDER BY `users`.`user_id` ASC LIMIT 1
var userinfo elemType.UserInfo
db.Debug().First(&userinfo, 1) // 后面就是主键,前面就是承装的对象
fmt.Println(userinfo)
var user elemType.User
db.Debug().First(&user, 1)
fmt.Println(user)
// 利用Where方法
db.Debug().Where("user_id = ?", 1).First(&user) // 也可以
// 注意成员的共有和私有化
// FirstOrCreate 如果有这个记录就会查询否则就会创建
user1 := elemType.User{
UserId: 1,
Age: 19,
Name: "小明",
IID: 1,
}
db.FirstOrCreate(&user, user1) // 后面就是一个默认值,前面还是一个容器
fmt.Println(user)
// First方法 sql SELECT * FROM `users` WHERE `users`.`user_id` = 1 AND ((user_id = 1)) ORDER BY `users`.`user_id` ASC LIMIT 1
// Last方法,first中查询是升序查询,但是last是降序查询 sql
db.Debug().Last(&user, 1)
// Take方法: 没有进行排序 sql SELECT * FROM `users` WHERE `users`.`user_id` = 1 AND ((`users`.`user_id` = 1)) LIMIT 1
db.Debug().Take(&user, 1)
fmt.Println(user)
// Find方法 按照条件进行查询,但是可以查询出多个记录,参数可以传递一个切片
user_id_arr := []int{1, 2} // 后面其实就是一个条件切片
db.Debug().Find(&user, user_id_arr)
fmt.Println(user)
}
Where和Select函数
- Where用法: 其实就是限定条件,可以把条件写在前面,使用占位符,可以使用模糊匹配和区间匹配(Between,like,in)
- Select用法: 其实就是指定需要查询出来的字段名称
- 代码演示如下
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 演示Where方法
user := []elemType.User{}
user_arr_id := []int{1, 2}
db.Where("user_id in (?)", user_arr_id).Find(&user)
// 演示利用Select方法进行筛选
// 其实就相当于需要查询出来的条件,其他条件不会被查出来
db.Select("name,age").Where("user_id in (?)", user_arr_id).Find(&user)
fmt.Println(user)
}
- 运行结果演示

Create和Save方法
- 作用基本相同,都是用于插入数据,都只可以插入一次数据,不可以批量插入数据
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 演示create方法,只是可以插入单条记录
user := elemType.User{
Name: "李四",
Age: 24,
IID: 1,
}
db.Create(&user)
// 演示Save方法,还是完成添加数据的操作
users := elemType.User{
Name: "赵六",
Age: 12,
IID: 1,
}
db.Save(&users)
}
Update函数
- 查询方式多种多样,可以直接进行链式操作,也可以利用model进行操纵
- 注意interface{}类型相当于一个泛型,相当于java中的Object,空接口就是一个泛型
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 演示Update函数
// 首先查询之后更新
var user elemType.User
db.Where("user_id = ?", 1).First(&user)
// 1. 通过Model进行操作,指定操作对象
db.Model(&user).Update("age", 22)
fmt.Println(user) // 注意user也会发生改变
// 2. 直接在查询之后操作
db.Where("user_id = ?", 2).First(&user).Update("name", "bob")
// 3. 还是直接在查询之后操作,但是可以利用结构体传入多个字段
db.Where("user_id = ?", 1).First(&user).Update(elemType.User{
Name: "小李",
Age: 10,
})
// 4. 通过插入键值对的方法
db.Where("user_id = ?", 2).First(&user).Update(map[string]interface{}{
"age": 21,
"name": "小花", // 其实后面的一个接口就相当于一个泛型,相当于一个Object对象
})
}
)
Delete函数
- 两种方法进行删除操作
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 演示Delete函数
// 1. 首先查询之后删除
var user elemType.User
db.Where("user_id = ?",1).First(&user)
db.Delete(&user)
// 2. 直接利用条件删除
db.Where("user_id = ?",2).Delete(&user)
}
Not,Or,Order函数
- Not: 用于排除条件
- Or: 用于条件连接
- Order: 用于对结果进行排序
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 演示Not函数 , 其实就是找出不满足条件的记录
var user elemType.User
db.Where("user_id = ?", 1).First(&user)
var users []elemType.User
db.Not("user_id = ?", 1).Find(&users)
fmt.Println(users)
// not中加上多个条件,含义就是找出不满足name=赵六,age=22的全部记录
db.Not(elemType.User{
Name: "赵六",
Age: 22,
}).Find(&users)
fmt.Println(users)
// 演示Or方法,其实就是条件的连接
db.Where("user_id = ?", 1).Or("user_id = ? ", 3).Find(&users)
fmt.Println(users)
// 演示Order方法进行查询,其实就是进行升序后者降序按操作
db.Not("user_id = ?", 1).Order("age asc").Find(&users)
fmt.Println(users)
}
Limit,Offset,Scan方法
- limit和offset用于限定范围,scan用于结构体扫描
- 代码演示
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 演示limit函数,用于限定查询所得记录的条数
var users []elemType.User
db.Not("user_id = ?", 1).Find(&users)
fmt.Println(users)
db.Not("user_id = ?", 1).Limit(2).Find(&users)
fmt.Println(users)
// 演示Offset函数,需要和limit函数一起使用,用于指定查询起点,从0开始
db.Not("user_id = ?", 1).Offset(1).Limit(2).Find(&users)
fmt.Println(users)
// Scan方法,将结果扫描到另外一个结构 体中,扫描的必须是一致的
type UserDemo struct {
Name string
Age int
}
var userdemo UserDemo
var user elemType.User
db.Where("user_id = ?", 1).Find(&user).Scan(&userdemo)
fmt.Println(user)
fmt.Println(userdemo)
}
- 结果演示
Count,GROUP,Having方法
- 基本和原生sql中的操作一致,含义一致
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 用于演示Count方法,进行计数
var users []elemType.User
// 定义一个变量接受结果,好像gorm框架中变量接受都需要定义一个结构体
var count int
db.Find(&users).Count(&count)
fmt.Println(users)
fmt.Println(count)
// 一定要学会利用结构体接受数据,但是一定要注意结构体名和筛选出元素和结构体中元素的区别
type GroupDemo struct {
Age int
Count int
}
var group_date GroupDemo
// 用于演示group函数进行查询,基本和原生sql中的操作一致
db.Select("age,count(*) as Count").Group("age").Find(&users).Scan(&group_date)
fmt.Println(users)
fmt.Println(group_date)
// Having: 用于分组之后的条件过滤
db.Select("age,count(*) as Count").Group("age").Having("age > ?", 18).Find(&users).Scan(&group_date)
fmt.Println(users)
fmt.Println(group_date)
}
左连接,右连接
- 首先回顾一下左连接和右连接的区别: 其实就是关联的两张表中有一些数据没有相互对应关系(其实就是没有在另外一张表中的映射关系),查询时选择性查询数据(有一张表的数据中的记录不全)
- 利用Joins方法结合原生sql进行操作即可
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 用于演示左连接和右连接
// 利用Joins方法进行操作
// 常常利用Select方法和Scan方法定义一个新的结构体用于承装需要查询出来的字段,利用Scan方法进行扫描
// 其实Joins方法中的条件就是sql中的条件
var users []elemType.User
db.Joins("left join user_infos on users.i_id = user_infos.info_id").Find(&users)
fmt.Println(users)
}
LogMode方法
- 用于开启debug模式 ,展示 对应的sql语句
- 代码演示
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 开启打印日志
db.LogMode(true) // 其实就是默认加上debug模式
// 用于演示左连接和右连接
// 利用Joins方法进行操作
// 常常利用Select方法和Scan方法定义一个新的结构体用于承装需要查询出来的字段,利用Scan方法进行扫描
// 其实Joins方法中的条件就是sql中的条件
var users []elemType.User
db.Joins("left join user_infos on users.i_id = user_infos.info_id").Find(&users)
fmt.Println(users)
}
原生sql操作
- 操作的原生sql利用row函数指定
- 删除,更新修改的原生sql利用exec演示
- 代码演示:
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"gomod/elemType"
)
func main() {
// 连接数据库 "mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=True&loc=Local"
db, err := gorm.Open("mysql", "root:808453@tcp(localhost:3306)/test_jdbc?charset=utf8&parseTime=true&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 开启打印日志
db.LogMode(true) // 其实就是默认加上debug模式
// 演示利用原生sql进行操作,就是利用Raw方法进行操作
var users []elemType.User
db.Raw("select* from users").Find(&users)
fmt.Println(users)
// 增加,更新,修改操作
db.Exec("insert into users (age,name) values (?,?)", 23, "小丽")
db.Exec("delete from users where user_id = ?", 1)
db.Exec("update users set name = ? where user_id = ?", "明天", 2)
}
日志操作(之后学完gin框架之后补充)
- 日志的作用:
- 记录用户操作的审计日志
- 快速定位问题的根源
- 追踪程序执行的过程
- 追踪数据的变化
- 追踪数据统计和性能分析
- 采集运行环境数据
- 第三方日志框架: logrus 框架
引入方式
1. 理解模板类型推导
理解下列几种情况下的模板类型推导方式
考虑如下模板:
template<typename T>
void f(ParamType param);
f(expr);
1. ParamType 是一个指针或者引用,但是不是通用引用
- 此时,模板类型推导的具体规则如下:
- 如果
expr类型是一个引用类型,忽略引用部分 - 然后使用
expr的类型与ParamType进行匹配来决定T具体例子交换如下:
- 如果
template<typename T>
void f(const T& param);
int x = 29;
const int cx = x;
const int& rx = x;
f(x); // T -> int PType -> const int&
f(cx); // T -> int PType -> const int&
f(rx); // T -> int PType -> const int& (忽略 rx 的引用性质)
指针也是一样的:
template<typename T>
void f(T* param);
int x = 27;
const int* px = &x;
f(x); // T -> int PType -> int*
f(px); // 忽略指针: T -> const int PType -> const int*
2. ParamType 是一个通用引用
通用引用也就是
T&&
- 判断规则如下:
- 如果
expr为左值,T和ParamType都会被推导为左值引用(唯一一种被推导成引用的) - 如果
expr为右值,使用正常的推导规则(规则一,忽略引用直接推导)
- 如果
举例如下:
template<typename T>
void f(T&& param);
int x = 27;
const int cx = x;
const int& rx = cx;
f(x); // x 为左值 , T -> int& PType -> int&
f(cx); // cx 为左值, T -> const int& , PType -> const int&
f(rx); // rx为左值 , T -> const int& , PType -> const int&
f(27); // 右值 , T -> int , PType -> int&&
3. ParamType既不是指针也不是引用
也就是传递值的形式处理,模板如下:
template<typename T>
void f(T param);
- 推导规则:
- 如果
expr的类型为一个引用,就忽略引用部分 - 如果忽略
expr的引用性之后,expr是一个const,那么就需要再次忽略const
- 如果
- 例子如下:
int x=27; //如之前一样
const int cx=x; //如之前一样
const int & rx=cx; //如之前一样
f(x); //T和param的类型都是int
f(cx); //T和param的类型都是int
f(rx); //T和param的类型都是int
总是记住使用值传递的时候传递的都是拷贝值,如果传递一个指针传递的也就是指针指向的地址(可以把指针看作一个记录地址的变量),所以对于如下推导:
template<typename T>
void f(T param); //仍然以传值的方式处理param
const char* const ptr = //ptr是一个常量指针,指向常量对象
"Fun with pointers";
f(ptr); //传递const char * const类型的实参
拷贝的是 ptr 指向的地址,这一个地址指向的数字是不可以变化的,但是拷贝之后的变量本身可以变化,所以推导得到的类型为 const int*
4. 数组实参和函数实参
- 记住规律即可:
T为值,那么推导得到的类型就是指针(对于数组来说就是const T *),对于函数而言就是函数指针T为引用T&, 那么就会推导得到const int& []和(...)(&)(...)
2. 理解auto类型推导
理解
auto类型推导和模板类型推导基本一样即可,另外注意不同之处再与多与初始化列表的推导
- 利用模板推导的方法来进行
auto类型推导,此时auto可以看成T, 类型说明符可以看成PType,也就是如下等效方法:
auto x = 10;
// 可以等效为
template<typename T>
void func(T x);
const auto& a = x;
// 可以等效为:
template<typename T>
void func(const T& a); // const int&
举例如下:
auto x = 27; //情景三(x既不是指针也不是引用)
const auto cx = x; //情景三(cx也一样)
const auto & rx=cx; //情景一(rx是非通用引用)
auto&& uref1 = x; //x是int左值,
//所以uref1类型为int&
auto&& uref2 = cx; //cx是const int左值,
//所以uref2类型为const int&
auto&& uref3 = 27; //27是int右值,
//所以uref3类型为int&&
对于数组或者函数也是一样的:
const char name[] = //name的类型是const char[13]
"R. N. Briggs";
auto arr1 = name; //arr1的类型是const char*
auto& arr2 = name; //arr2的类型是const char (&)[13]
void someFunc(int, double); //someFunc是一个函数,
//类型为void(int, double)
auto func1 = someFunc; //func1的类型是void (*)(int, double)
auto& func2 = someFunc; //func2的类型是void (&)(int, double)
- 但是不同之处在与对于初始化列表的推导,对于
auto而言,推导方式如下:
auto x1 = 27; //类型是int,值是27
auto x2(27); //同上
auto x3 = { 27 }; //类型是std::initializer_list<int>,
//值是{ 27 }
auto x4{ 27 }; //同上
- 但是对于模板而言:
auto x = { 11, 23, 9 }; //x的类型是std::initializer_list<int>
template<typename T> //带有与x的声明等价的
void f(T param); //形参声明的模板
f({ 11, 23, 9 }); //错误!不能推导出T
template<typename T>
void f(std::initializer_list<T> initList);
f({ 11, 23, 9 }); //T被推导为int,initList的类型为
//std::initializer_list<int>
- 最后一点,在
C++14中允许使用auto作为函数的返回值,但是类型推导的方式不是根据auto而是根据模板的规则来的,所以如下的例子是错误的:
auto createInitList()
{
return { 1, 2, 3 }; //错误!不能推导{ 1, 2, 3 }的类型
}
std::vector<int> v;
…
auto resetV =
[&v](const auto& newValue){ v = newValue; }; //C++14
…
resetV({ 1, 2, 3 }); //错误!不能推导{ 1, 2, 3 }的类型
3. 理解 decltype
把
decltype的作用理解为得到变量的类型即可
- 首先关注
decltype的默认作用,举例如下:
const int i = 0; //decltype(i)是const int
bool f(const Widget& w); //decltype(w)是const Widget&
//decltype(f)是bool(const Widget&)
struct Point{
int x,y; //decltype(Point::x)是int
}; //decltype(Point::y)是int
Widget w; //decltype(w)是Widget
if (f(w))… //decltype(f(w))是bool
template<typename T> //std::vector的简化版本
class vector{
public:
…
T& operator[](std::size_t index);
…
};
vector<int> v; //decltype(v)是vector<int>
…
if (v[0] == 0)… //decltype(v[0])是int&
- 同时
delctype的一个比较重要的作用就是当函数模板的返回值与形式参数有关的时候可以利用delctype进行返回值的类型推导:
template<typename Container, typename Index> //可以工作,
auto authAndAccess(Container& c, Index i) //但是需要改良
->decltype(c[i])
{
authenticateUser();
return c[i];
}
同时对于lambda表达式也可以进行相应的推导
- 同时在
C++14中,由于直接使用auto进行推导会去除引用(第三种情况),所以需要使用delctype进行类型推导,也就是可以使用decltype(auto)进行类型推导,表示进行类型推导但是使用delctype的方式进行推导 - 对于需要使用右值引用的情况,还是需要使用
decltype(auto)进行推导:
template<typename Container, typename Index> //最终的C++14版本
decltype(auto)
authAndAccess(Container&& c, Index i)
{
authenticateUser();
return std::forward<Container>(c)[i];
}
- 总结:
decltype总是不加修改的产生变量或者表达式的类型- 对于
T类型的不是单纯的变量名的左值表达时,dectype总是推导为T&(比如c[index]等) C++14中的decltype(auto), 就像auto一样,推导出类型,但是它使用decltype的规则进行推导
4. 学会查看类型推导的结果
- 利用
IDE编辑器查看 - 编译器诊断(报错)
- 利用
std::typeid().name查看变量类型名称(之可以显示类型,没有修改修饰符号) - 使用第三方库
1. 优先考虑 auto而不是非显示类型声明
使用
auto的优点有如下几点
1. 防止没有初始化的变量
auto声明的变量必须要初始化,否则就会报错,避免了不明确行为:
int x1; //潜在的未初始化的变量
auto x2; //错误!必须要初始化
auto x3 = 0; //没问题,x已经定义了
2. 替代复杂类型名称
- 比如对于闭包类型的书写,如果没有
auto就会十分复杂:
// 没有 auto
std::function<bool(const std::unique_ptr<Widget> &,
const std::unique_ptr<Widget> &)>
derefUPLess = [](const std::unique_ptr<Widget> &p1,
const std::unique_ptr<Widget> &p2)
{ return *p1 < *p2; };
// C++ 11 中使用 auto
auto derefUPLess = [](const std::unique_ptr<Widget> &p1,
const std::unique_ptr<Widget> &p2)
{ return *p1 < *p2; };
// C++ 14 中使用 auto
auto derefLess = //C++14版本
[](const auto& p1, //被任何像指针一样的东西
const auto& p2) //指向的值的比较函数
{ return *p1 < *p2; };
3. 不确定的类型可以使用 auto 推导
- 比如各种容器的迭代器或者函数的返回值可以使用
auto推导,例子如下:
std::unordered_map<std::string, int> m;
…
// X 错误, 元素类型为 std::pair<const std::string , int>
for(const std::pair<std::string, int>& p : m)
{
… //用p做一些事
}
// 使用 auto
for(const auto& p : m)
{
… //如之前一样
}
2. auto推导若非己愿,使用显式类型初始化惯用方法
主要是两种情况: 不要使用
auto推导代理类的类型,显式链类型推导强制使用auto推导出想要的结果
1. 不要使用auto推导代理类型
- 考虑如下代码:
// 不使用 auto
Widget w;
…
bool highPriority = features(w)[5]; //w高优先级吗?
…
processWidget(w, highPriority); //根据它的优先级处理w
// 使用 auto
Widget w;
…
auto highPriority = features(w)[5]; //w高优先级吗?
…
processWidget(w, highPriority); //根据它的优先级处理w
- 实际上对于
vector<bool>类型,operator[]并不会返回一个T&类型,而是返回一个内部类的类型std::vector<bool>reference, 这一个对象中包含指向word的指针,但是在临时对象被销毁的时候空间会被释放,造成为定义行为,所以不可以使用auto
2. 使用显式类型转换和auto来推导类型
- 利用显式类型转换和
auto可以清晰表现自己想要什么,如下:
auto ep = static_cast<float>(calEpsilon());
1. 区别使用() 和 {} 创建对象
注意
{}的优点和缺点以及使用时机
1. {}可以统一初始化方法
- 比如对于自定义对象,初始化和赋值的区别如下:
Widget w1; //调用默认构造函数
Widget w2 = w1; //不是赋值运算,调用拷贝构造函数
w1 = w2; //是赋值运算,调用拷贝赋值运算符(copy operator=)
- 同时注意利用
{}不会造成数据类型的变窄,但是利用()可能造成类型的变窄
2. {}倾向于调用 initializer_list 为参数的初始化函数
- 比如如下代码不可以通过编译:
class Widget {
public:
Widget(int i, bool b); //同之前一样
Widget(int i, double d); //同之前一样
Widget(std::initializer_list<bool> il); //现在元素类型为bool
… //没有隐式转换函数
};
Widget w{10, 5.0}; //错误!要求变窄转换
总结:
- 花括号是使用最广泛的初始化语法,可以防止变窄转换,并且可以防止把初始化解析为函数声明(只要像函数声明一定会别解析为函数声明)
- 在构造函数重载决议中,编译器会尽最大的努力将括号初始化和初始化列表参数匹配即使不正确
- 对于数据类型
std::vector来说两种初始化方式不太一样
2. 优先考虑 nullptr 而不是 0 和 NULL
- 不使用
0和NULL的原因是可能既不是指针类型也不是整型类型,比如如下例子:
void f(int); //三个f的重载函数
void f(bool);
void f(void*);
f(0); //调用f(int)而不是f(void*)
f(NULL); //可能不会被编译,一般来说调用f(int),
//绝对不会调用f(void*)
- 如果没有确定的类型(也就是只是根据
0或者NULL进行类型推导,推导出来的结果一定不是指针),在模板中这种问题比较明显:
template<typename FuncType,
typename MuxType,
typename PtrType>
decltype(auto) lockAndCall(FuncType func, //C++14
MuxType& mutex,
PtrType ptr)
{
MuxGuard g(mutex);
return func(ptr);
}
auto result1 = lockAndCall(f1, f1m, 0); //错误!
auto result2 = lockAndCall(f2, f2m, NULL); //错误!
auto result3 = lockAndCall(f3, f3m, nullptr); //没问题
3. 优先考虑别名声明而非 typedef
1. typedef 不支持模板化,但是别名支持
- 比如同时声明一个复杂类型:
// 使用别名声明
template<typename T>
using MyAllocList = std::list<T,MyAlloc<T>>;
MyAllocList<Widget> lw;
// 使用 typedef
template<typename T>
struct MyAllocList {
typedef std::list<T,MyAlloc<T>> type; // type 表示类型
};
// 使用模板类
typename MyAllocList<Widget>::type lw;
2. C++14 中提供了类型转换的别名
C++14中提供的类型转换的别名与C++11中类型转换的别名的对应关系如下:
std::remove_const<T>::type //C++11: const T → T
std::remove_const_t<T> //C++14 等价形式
std::remove_reference<T>::type //C++11: T&/T&& → T
std::remove_reference_t<T> //C++14 等价形式
std::add_lvalue_reference<T>::type //C++11: T → T&
std::add_lvalue_reference_t<T> //C++14 等价形式
4. 优先考虑限域enum而非未限域enum
- 非限域枚举:
enum Color {
White,
Red,
Yellow
};
- 限域枚举:
enum class Color {
White,
Red,
Yellow,
};
- 限域枚举的优点:
- 不会污染命名空间
- 不会发生类型转换
- 可以前置声明,枚举改变不需要重新编译整个文件
- 可以指定类型
enum class Color : int {
White,
Red,
Yellow
};
并且枚举类需要进行类型转换才可以当成整型变量使用
5. 优先考虑deleted函数而非使用未定义的私有声明
- 注意
deleted函数的作用就是代替C++98中如果不想要使用某一个函数就需要把这一个函数设置为私有函数并且不做实现(这样外界函数无法调用,并且友元函数由于无实现链接错误页无法调用) deleted函数的作用如下:- 可以禁止调用某一些类自动生成的函数(比如赋值运算符号和拷贝构造函数)
- 可以禁止使用某些类型作为重载函数的入参
- 可以排除模板函数的参数的各种情况
class Widget {
public:
…
template<typename T>
void processPointer(T* ptr)
{ … }
…
};
template<> //还是public,
void Widget::processPointer<void>(void*) = delete; //但是已经被删除了
bool isLucky(int number); //原始版本
bool isLucky(char) = delete; //拒绝char
bool isLucky(bool) = delete; //拒绝bool
bool isLucky(double) = delete; //拒绝float和double
6. 使用 override声明重写函数
引用限定符号
- 作用: 根据调用这一个函数的
this指针的类型来判断应该时用那一个函数,是函数重载的条件之一:
class Widget {
public:
…
void doWork() &; //只有*this为左值的时候才能被调用
void doWork() &&; //只有*this为右值的时候才能被调用
};
…
Widget makeWidget(); //工厂函数(返回右值)
Widget w; //普通对象(左值)
…
w.doWork(); //调用被左值引用限定修饰的Widget::doWork版本
//(即Widget::doWork &)
makeWidget().doWork(); //调用被右值引用限定修饰的Widget::doWork版本
//(即Widget::doWork &&)
final 和 override
final: 修饰函数标识函数不可以被重写,修饰类标识类不可以别继承override: 可以修饰重写函数,防止不满足重写规则
7. 优先考虑 const_iterator而非iterator
const_iterator相当于指向常量的指针,可以防止容器内的数据被改变,所以推荐使用,但是在C++11之前获取到const_iterator比较困难,C++11中引入了成员函数cbegin , cend可以直接获取到const_iteator,同时C++14中有提供了自由函数cbegin() 和 cend()可以直接对于容器进行操作获取到const_iterator- 总结:
- 优先考虑
const_iterator而非iterator - 最大程度通用的代码中考虑非成员函数版本的
begin , end , cbegin , cend函数等
- 优先考虑
8. 如果函数不抛出异常请使用noexcept
- 如果确定函数不会抛出异常(前置条件强制满足)那么就可以把函数声明为
noexcept,这一个标记的优点如下:- 与
non-noexcept函数相比便于优化 - 对于移动语义,
swap和内存释放函数和析构函数非常有用(比如swap函数是否抛出异常依赖于自己定义的swap是否抛出异常)
- 与
- 在
C++98和C++11中不抛出异常的函数定义如下:
int f(int x) throw(); //C++98风格,没有来自f的异常
int f(int x) noexcept; //C++11风格,没有来自f的异常
- 另外注意:
noexcept是函数接口的一部分,意味着调用者可能依赖它- 大多数函数是异常中立的
9. 尽可能使用constexpr
constexpr与const的区别
- 对于
constexpr修饰的变量,它的值都是编译期可知道的,但是const修饰的变量可能是运行时期可知的,所以利用constexpr可以作为函数模板参数等,举例说明:
// constexpr 修饰
int sz; //non-constexpr变量
…
constexpr auto arraySize1 = sz; //错误!sz的值在
//编译期不可知
std::array<int, sz> data1; //错误!一样的问题
constexpr auto arraySize2 = 10; //没问题,10是
//编译期可知常量
std::array<int, arraySize2> data2; //没问题, arraySize2是constexpr
// const修饰
int sz; //和之前一样
…
const auto arraySize = sz; //没问题,arraySize是sz的const复制
std::array<int, arraySize> data; //错误,arraySize值在编译期不可知
constexpr函数
constexpr函数的特点如下:- 如果实参是编译时期可确定的,此时
constexpr的结果就是编译时期计算的 - 当一个
constexpr被一个或者多个编译时期不可知的值调用的时候,它就像普通函数一样,运行时计算结果
- 如果实参是编译时期可确定的,此时
C++11中利用constexpr修饰的函数之可以有不超过一行语句,但是在C++14中放开了标准- 所以根据这一个特性,
constexpr修饰的函数可以作为编译时期可知道的量处理 - 总结:
constexpr对象是const,被编译时期可知的值初始化- 传递编译时期可知的值的时候,
const expr可以产出编译时期可知的结果 constexpr对象和函数的使用范围比较广阔constexpr是对象和函数接口的一部分
10. 让const成员函数线程安全
const成员函数中不可以改变非mutable修饰的成员变量,所以在并发访问的时候一般的语义就是返回已经计算好的成员变量,所以需要让const成员函数是线程安全的,这样可以防止其中的成员变量被重复计算- 总结:
- 确保
const成员函数线程安全,除非你确定他们永远都不会再并发上下文中使用 - 使用
std::atomic变量可能比互斥量提供更好的性能,但是它只适合操作单个变量或者年内村位置
- 确保
11. 理解特殊成员函数的生成
C++11中新加入的成员函数如下:
class Widget {
public:
…
Widget(Widget&& rhs); //移动构造函数
Widget& operator=(Widget&& rhs); //移动赋值运算符
…
};
分别是移动构造函数和移动赋值运算符号
C++11中各种特殊成员函数生成规则总结如下:- 拷贝构造函数仅仅当类没有显式声明拷贝构造函数才会自动生成,并且如果用户声明了移动操作,拷贝构造函数就是
delete(这是由于对于C++98中的各种对象都是不可以移动的,所以在std::move中进行的依然是拷贝操作) , 拷贝赋值运算符好仅仅当类中没有显式声明赋值运算符的时候才会自动升成,并且如果用于声明了移动操作,那么拷贝运算符就是delete, 当用户声明了析构函数,拷贝操作的自动生成就已经被飞起了 - 移动操作仅仅当类没有显式声明移动操作,拷贝操作,析构函数才自动生成
- 拷贝构造函数仅仅当类没有显式声明拷贝构造函数才会自动生成,并且如果用户声明了移动操作,拷贝构造函数就是
1. 对于独占资源所使用std::unique_ptr
- 使用智能指针,如果是独占资源首选
std::unique_ptr,优点如下:- 可以自定义删除器
- 可以很容易转换为
shared_ptr - 存在两种形式:
std::unique_ptr<T>和std::unique_ptr<T[]>
- 补充一个小知识点: 子类需要初始化父类,也就是必须要调用父类的构造函数
2. 对于共享资源使用std::shared_ptr
- 首先对于
shared_ptr内存布局如下: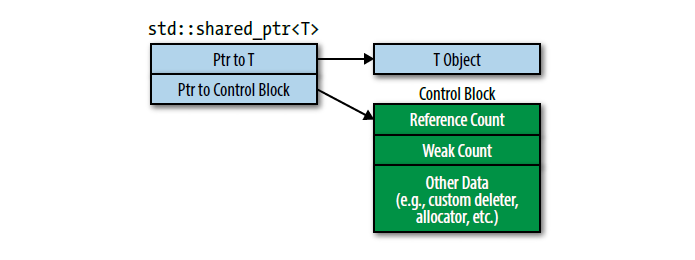
- 所以不要时用同一个原始对象创建
shared_ptr会导致内存重复释放,最好使用拷贝构造,赋值运算等方式创建shared_ptr reset方法的作用:- 释放
shared_ptr - 重新设置管理对象
- 释放
make_shared: 可以创建一个控制块,不用担心调用对象的时候存在其他控制块- 如果想要在类中返回包装了
this指针的shared_ptr,需要继承模板了enable_shared_from_this,调用其中的shared_from_this
class Person: public enable_shared_from_this<Person> {
public:
int* age;
Person(int age): age(new int(age)) {}
Person() {}
Person(const Person& p) {
/*this -> age = p.age;*/
this -> age = new int(*(p.age));
}
~Person() {
cout << "person析构函数执行了" << endl;
if(age != nullptr) {
delete age;
age = nullptr;
}
}
shared_ptr<Person> get_this() {
return shared_from_this();
}
};
3. 当std::shared_ptr可能悬空的时候使用std::weak_ptr
- 这里介绍了
weak_ptr的两个作用:- 管理
shared_ptr,根据shared_ptr是否悬空创建对象(其中的lock方法是并发安全的) - 解决
shared_ptr的循环引用问题
- 管理
- 解决循环引用问题的方法如下:
 指针使用
指针使用weak_ptr即可 - 总结:
- 用
std::weak_ptr替代可能会悬空的std::shared_ptr。 std::weak_ptr的潜在使用场景包括:缓存、观察者列表、打破std::shared_ptr环状结构。
- 用
4. 优先考虑使用std::make_unique和std::make_shared,而非直接使用new
make_shared是C++11的特性,make_unique是C++14的特性- 实现方法都是利用完美转发把参数转发给构造函数使用,比如
make_unique的一种实现方式如下:
template<typename T,typename... Ts>
std::unique_ptr<T> make_unique(Ts&&... params)
{
return unique_ptr<T>(new T(std::forward<Ts>(params)...));
}
使用 make 函数减少重复代码片段
- 比如使用
make和new创建智能指针的代码片段如下:
auto upw1(std::make_unique<Widget>()); //使用make函数
std::unique_ptr<Widget> upw2(new Widget); //不使用make函数
auto spw1(std::make_shared<Widget>()); //使用make函数
std::shared_ptr<Widget> spw2(new Widget); //不使用make函数
减少了泛型的书写次数
保证了异常安全
- 对于如下代码:
processWidget(std::shared_ptr<Widget>(new Widget), //潜在的资源泄漏!
computePriority());
- 执行顺序如下:
- 分配内存空间
- 智能指针指向内存空间
- 执行计算权重的函数
- 这三个步骤可能顺序不确定,所以可能造成内存泄漏
减少了内存分配次数
- 利用
new首先分配堆区内存,之后分配控制块内存 - 利用
make控制块内存和堆区内存同时分配
make的缺点
-
不可以自定义删除器
-
花括号无法使用完美转发
-
创建的对象比较大的时候,由于
weak_ptr的存在,可能导致释放对象和释放控制块的事件出现延迟(但是利用make同时释放对象和控制块) -
总结:
- 和直接使用
new相比,make函数消除了代码重复,提高了异常安全性。对于std::make_shared和std::allocate_shared,生成的代码更小更快。 - 不适合使用
make函数的情况包括需要指定自定义删除器和希望用花括号初始化。 - 对于
std::shared_ptrs,其他不建议使用make函数的情况包括(1)有自定义内存管理的类;(2)特别关注内存的系统,非常大的对象,以及std::weak_ptrs比对应的std::shared_ptrs活得更久。
- 和直接使用
5. 当使用 Pimpl惯用法,请实现文件中定义特殊成员函数
Pimpl惯用法
- 为了降低源代码之间的依赖关系,可以使用
Pimpl惯用法,这一种方法类似于接口,使用方法如下:
class Widget //仍然在“widget.h”中
{
public:
Widget();
~Widget(); //析构函数在后面会分析
…
private:
struct Impl; //声明一个 实现结构体
Impl *pImpl; //以及指向它的指针
};
#include "widget.h" //以下代码均在实现文件“widget.cpp”里
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { //含有之前在Widget中的数据成员的
std::string name; //Widget::Impl类型的定义
std::vector<double> data;
Gadget g1,g2,g3;
};
Widget::Widget() //为此Widget对象分配数据成员
: pImpl(new Impl)
{}
Widget::~Widget() //销毁数据成员
{ delete pImpl; }
但是在使用的时候一定需要注意,如果使用unique_ptr 来管理对象的时候一定需要定义类中的各种特殊成员函数,否则就会导致不完成的数据类型(声明但是没有定义)
- 总结:
- Pimpl惯用法通过减少在类实现和类使用者之间的编译依赖来减少编译时间。
- 对于
std::unique_ptr类型的pImpl指针,需要在头文件的类里声明特殊的成员函数,但是在实现文件里面来实现他们。即使是编译器自动生成的代码可以工作,也要这么做。 - 以上的建议只适用于
std::unique_ptr,不适用于std::shared_ptr
移动语义: 移动语义使编译器有可能用廉价的移动操作来代替昂贵的拷贝操作。正如拷贝构造函数和拷贝赋值操作符给了你控制拷贝语义的权力,移动构造函数和移动赋值操作符也给了你控制移动语义的权力。移动语义也允许创建只可移动(move-only)的类型,例如
std::unique_ptr,std::future和std::thread。
完美转发: 完美转发使接收任意数量实参的函数模板成为可能,它可以将实参转发到其他的函数,使目标函数接收到的实参与被传递给转发函数的实参保持一致。
右值引用就是这两个概念之间的联合剂,注意在如下的讨论中,函数的形式参数永远都是左值,即使类型是一个右值引用,比如:
void f(Widget&& w);
其中,w的类型虽然是一个右值引用,但是本身是一个左值
1. 理解 std::move 和 std::forward
- 首先一定需要明确
std::move和std::forward的作用,两者的作用如下:std::move执行到右值的无条件的转换,但就自身而言,它不移动任何东西。std::forward只有当它的参数被绑定到一个右值时,才将参数转换为右值。std::move和std::forward在运行期什么也不做。
std::move的一种简单的实现方式如下:
template<typename T> //在std命名空间
typename remove_reference<T>::type&&
move(T&& param)
{
using ReturnType = //别名声明,见条款9
typename remove_reference<T>::type&&;
return static_cast<ReturnType>(param);
}
-
使用的注意事项:
- 不要再希望能移动对象的时候声明他们为
const,否则对于const对象的移动请求可能会转换为拷贝操作 std::move不仅可以移动任何东西,还可以保证执行转换的对象可以被移动
- 不要再希望能移动对象的时候声明他们为
-
std::forward的一种简单的实现方式如下:
template<typename T>
T&& forward(typename std::remove_reference<T>::type&& t) noexcept {
static_assert(!std::is_lvalue_reference<T>::value, "bad forward call");
return static_cast<T&&>(t);
}
从上面的实现可以简单,之后当传入的参数为右值引用类型的时候(依赖于模板参数T才会完成右值的转化,其中std::is_lvalue_reference<T>判断传入的模板参数是否是左值引用
- 比如一种
std::forward的使用案例如下:
void process(const Widget& lvalArg); //处理左值
void process(Widget&& rvalArg); //处理右值
template<typename T> //用以转发param到process的模板
void logAndProcess(T&& param)
{
auto now = //获取现在时间
std::chrono::system_clock::now();
makeLogEntry("Calling 'process'", now);
process(std::forward<T>(param));
}
2. 区分通用引用和右值引用
- 首先搞清楚通用引用和右值引用之间的关系:
- 通用引用: 用于类型推导,如果类型为左值,那么就推导为左值引用,如果类型为右值,那么就是右值引用
- 右值引用: 一种引用类型,标识数据为右值
- 总结:
- 如果一个函数模板形参的类型为
T&&,并且T需要被推导得知,或者如果一个对象被声明为auto&&,这个形参或者对象就是一个通用引用。 - 如果类型声明的形式不是标准的
type&&,或者如果类型推导没有发生,那么type&&代表一个右值引用。 - 通用引用,如果它被右值初始化,就会对应地成为右值引用;如果它被左值初始化,就会成为左值引用。
- 如果一个函数模板形参的类型为
3. 对于右值引用使用 std::move,通用引用使用 std::forward
- 最后一次使用的时候,如果是右值引用使用
std::move,在通用引用上面使用std::forward,这是由于对于通用引用来说,可以根据传入的模板参数来确定返回的是一个左值引用还是一个右值引用,从而确定拷贝或者移动操作 - 对于按值返回的函数返回的右值引用和通用引用,执行相同的的操作
- 如果局部对象可以被返回值优化消除(
RVO),不要使用std::move或者std::forward,另外不要返回局部对象的引用(利用std::move也是一样的)
4. 避免在通用引用上重载
- 比较少使用,总结如下:
- 对通用引用形参的函数进行重载,通用引用函数的调用机会几乎总会比你期望的多得多。
- 完美转发构造函数是糟糕的实现,因为对于non-
const左值,它们比拷贝构造函数而更匹配,而且会劫持派生类对于基类的拷贝和移动构造函数的调用。
5. 熟悉通用引用重载的替代方法
- 使用情况比较少,可以使用传递值或者使用
tag dispatch的方法,也就是根据类型进行操作的分发(这里可以使用std::enable_if模板进行定义),总结如下:- 通用引用和重载的组合替代方案包括使用不同的函数名,通过lvalue-reference-to-
const传递形参,按值传递形参,使用_tag dispatch_。 - 通过
std::enable_if约束模板,允许组合通用引用和重载使用,但它也控制了编译器在哪种条件下才使用通用引用重载。 - 通用引用参数通常具有高效率的优势,但是可用性就值得斟酌。
- 通用引用和重载的组合替代方案包括使用不同的函数名,通过lvalue-reference-to-
6. 理解引用折叠
- 其实通用引用可以理解为一种引用的重叠形式,也就是其实本来就没有通用引用这一种引用类型,而是左值引用或者右值引用的重叠形式,具体的重叠形式包括: 左值的左值 , 右值的右值 , 左值的右值 , 右值的左值,形式如下:
T& & -> 左值
T&& && -> 右值
T& && -> 左值
T&& & -> 右值
规定: 只要是左值引用最后就可以的到左值引用,只要是右值引用最终就可以得到右边的值,所以利用通用引用这一个特性,可以简单实现std::forward函数,实现方式如下:
template<typename T> //在std命名空间
T&& forward(typename
remove_reference<T>::type& param)
{
return static_cast<T&&>(param);
}
所以调用关系和得到的结果如下:
std::forward<Person>(p); // Person&& 右值
std::forward<Person&>(p); // Person& && 左值
std::forward<Person&&>(p); // Person&& && 右值
- 总结:
- 引用折叠发生在四种情况下:模板实例化,
auto类型推导,typedef与别名声明的创建和使用,decltype。 - 当编译器在引用折叠环境中生成了引用的引用时,结果就是单个引用。有左值引用折叠结果就是左值引用,否则就是右值引用。
- 通用引用就是在特定上下文的右值引用,上下文是通过类型推导区分左值还是右值,并且发生引用折叠的那些地方。
- 引用折叠发生在四种情况下:模板实例化,
7. 假定移动操作不存在,成本高,未被使用
- 比如在
std::array或者对于不可以移动的对象,可能移动操作不一定比复制操作更快,比如C++11中的移动语义在如下几种情况下可能没有优势:- 没有移动操作: 要移动的对象没有提供移动操作,所以移动的写法也会变成复制操作
- 移动不会更快,要移动的对象提供的移动操作并不比复制速度更快
- 移动不可用: 进行移动的上下文要求移动操作不会抛出异常,但是该操作没有被声明为
noexcept - 源对象为左值,除了极少数情况之外,只有右值可以作为移动操作的来源
8. 熟悉完美转发失败的情况
- 首先了解什么叫做完美转发失败,也就是利用相同的参数调用转发函数和目标函数得到的结果不一样,也就是对于如下转发函数:
template<typename T>
void fwd(T&&... t) {
f(std::forward<T>(t));
}
- 最终两种情况的调用方式得到不同的结果:
f(t);
fwd(t);
- 错误情况总结如下:
- 当模板类型推导失败或者推导出错误类型,完美转发会失败。
- 导致完美转发失败的实参种类有花括号初始化,作为空指针的
0或者NULL,仅有声明的整型static const数据成员,模板和重载函数的名字,位域。
闭包(enclosure)是_lambda_创建的运行时对象。依赖捕获模式,闭包持有被捕获数据的副本或者引用。在上面的
std::find_if调用中,闭包是作为第三个实参在运行时传递给std::find_if的对象。 闭包类(closure class)是从中实例化闭包的类。每个_lambda_都会使编译器生成唯一的闭包类。_lambda_中的语句成为其闭包类的成员函数中的可执行指令。
lambda表达式的语法形式如下:
[capture](params) opt -> ret {body;};
- 其中:
capture表示捕获列表params表示参数列表opt表示函数选项(比如mutable表示可以修改按值传递进来的拷贝,exception指定函数抛出的异常,可以使用throw)ret: 返回值类型body: 函数体
捕获列表
-
捕获列表使用方法如下:
- [] - 不捕捉任何变量
- [
&] 捕获外部作用域中所有变量, 并作为引用在函数体内使用 (按引用捕获) - [
=] 捕获外部作用域中所有变量, 并作为副本在函数体内使用 (按值捕获) - 拷贝的副本在匿名函数体内部是只读的
- [=, &foo] - 按值捕获外部作用域中所有变量, 并按照引用捕获外部变量 foo
- [bar] - 按值捕获 bar 变量, 同时不捕获其他变量
- [&bar] - 按引用捕获 bar 变量, 同时不捕获其他变量
- [this] - 捕获当前类中的this指针 让lambda表达式拥有和当前类成员函数同样的访问权限 如果已经使用了 & 或者 =, 默认添加此选项
-
其实
lambda表达时本质上就是一个包含operator()方法的类,是一个仿函数
1. 避免使用默认捕获模式
- 默认捕获模式表示按照值捕获或者按照引用捕获
- 如果按照引用捕获,比如对于局部变量按照引用捕获,脱离作用域之后就回到时局部变量的空间被释放了,那么此时可能导致悬空引用
- 默认的按照值捕获的对于悬空指针比较敏感(比如
this指针),并且对于static变量可以引用但是无法捕获,会让人误导以为lambda是独立的想法
2. 使用初始化捕获来移动对象到闭包中
- 初始化捕获的是
C++14特性,可以对于lambda作用域里面的变量进行操作并且移动到生成的闭包类中,但是可以使用C++11中的std::bind函数模拟初始化捕获 C++14中的实现方式如下:
auto func = [pw = std::make_unique<Widget>()] //同之前一样
{ return pw->isValidated() //在闭包中创建pw
&& pw->isArchived(); };
C++11中利用std::bind的实现方式如下:
auto func = std::bind(
[](const std::unique_ptr<Widget>& pw)
{ return pw->isValidated()
&& pw->isArchived(); },
std::make_unique<Widget>()
);
3. 对 auto&& 形参使用 decltype以std::forward它们
C++14新特性: 可以在lambda的形参中使用auto关键字,例子如下:
auto f = [](auto x){ return func(normalize(x)); };
- 对应的闭包类型如下:
class SomeCompilerGeneratedClassName {
public:
template<typename T> //auto返回类型见条款3
auto operator()(T x) const
{ return func(normalize(x)); }
… //其他闭包类功能
};
- 从而可以使用
auto&& + decltype来实现完美转发,方式如下:
auto f =
[](auto&&... params)
{
return
func(normalize(std::forward<decltype(params)>(params)...));
};
4. 考虑lambda而非std::bind
- 利用
lambda表达式实现一个功能比利用std::bind实现一个功能更加简便并且直观,比如同样实现两个数字的大小比较,两种方式的实现方法如下:
// std::bind 实现
auto betweenB =
std::bind(std::logical_and<bool>(), //C++11版本
std::bind(std::less_equal<int>(), lowVal, _1),
std::bind(std::less_equal<int>(), _1, highVal));
// lambda表达式实现
auto betweenL = //C++11版本
[lowVal, highVal]
(int val)
{ return lowVal <= val && val <= highVal; };
- 总结如下:
- 与使用
std::bind相比,_lambda_更易读,更具表达力并且可能更高效。 - 只有在C++11中,
std::bind可能对实现移动捕获或绑定带有模板化函数调用运算符的对象时会很有用。
- 与使用
1. 对于移动成本低总是被拷贝的可拷贝形参,考虑按值传递
- 总结:
- 对于可拷贝,移动开销低,而且无条件被拷贝的形参,按值传递效率基本与按引用传递效率一致,而且易于实现,还生成更少的目标代码。
- 通过构造拷贝形参可能比通过赋值拷贝形参开销大的多。
- 按值传递会引起切片问题,所说不适合基类形参类型。
2. 考虑使用置入代替插入
- 注意使用插入和置入的区别,前者需要传递完整的对象,后者之需要传递构造函数的参数即可,并且不会创建临时对象(
push_back和emplace_back) - 总结:
- 原则上,置入函数有时会比插入函数高效,并且不会更差。
- 实际上,当以下条件满足时,置入函数更快:(1)值被构造到容器中,而不是直接赋值;(2)传入的类型与容器的元素类型不一致;(3)容器不拒绝已经存在的重复值。
- 置入函数可能执行插入函数拒绝的类型转换。
std::function和std::bind
std::function用于绑定可调用对象,包含如下类型:lambda表达式- 仿函数
- 静态成员函数
- 类成员函数指针和类成员指针
std::bind可以把参数绑定道可调用对象上面- 利用
std::bind绑定类成员函数的方法如下:
#include <iostream>
#include <functional>
using namespace std;
class Test
{
public:
void output(int x, int y)
{
cout << "x: " << x << ", y: " << y << endl;
}
int m_number = 100;
};
int main(void)
{
Test t;
// 绑定类成员函数
function<void(int, int)> f1 =
bind(&Test::output, &t, placeholders::_1, placeholders::_2);
// 绑定类成员变量(公共)
function<int&(void)> f2 = bind(&Test::m_number, &t);
// 调用
f1(520, 1314);
f2() = 2333;
cout << "t.m_number: " << t.m_number << endl;
return 0;
}
本章重点介绍了
TCP/IP协议族中的各种协议,比如ARP协议,ICMP协议,DNS协议,同时展示了使用tcpdump进行通信过程中的抓包方法,同时还介绍了arp和host命令的使用方法,这里使用知识点的方式来记录这一章节的内容
-
TCP/IP协议族体系结构和主要协议,分别介绍了应用层,传输层,网络层还有数据链路层
-
数据链路层: 实现网卡接口的网络驱动程序,让数据在物理媒介上传输,同时隐藏底层物理网络的电气特性,重要协议比如
ARP协议和RARP协议,作用都是实现IP协议和物理地址(MAC地址)之间的转换 , 这里可以粗略的把数据链路层的作用概括为把IP地址转换为物理地址 -
网络层: 作用是完成数据包的选路和转发(其实分为控制平面和数据平面,依赖于控制平面的算法来实现选路和负载均衡等功能) , 最核心的协议就是
IP协议,同时典型的协议还有ICMP协议,ICMP协议的格式如下,注意ICMP协议需要IP协议的支持,也就是需要利用IP协议进行包装,ICMP协议的格式如下: 其中类型表示报文的作用(反映差错还是重定向) , 代码表示细分条件
其中类型表示报文的作用(反映差错还是重定向) , 代码表示细分条件 -
传输层: 为主机之间提供端到端的通信,典型协议比如
TCP协议和UDP协议,各个层级之间的关系如下: 传输层的协议说明:
传输层的协议说明:TCP协议: 提供可靠传输,面向连接的基于流的服务,TCP的读写缓冲区都存在于内核空间中从而使得读写更加快捷,同时内核中页存储者许多TCP的其他的状态比如连接状态信息等,并且会保存发送的数据(滑动窗口)UDP协议: 提供无连接的,不可靠的,基于数据报的服务,可以理解为只是单独发送一次,UDP在内核中的缓冲区在发送数据之后就会把数据丢弃,不会保存数据
-
应用层: 利用传输层协议提供的服务,处理应用程序的逻辑,应用层协议如下(可以通过查看
/etc/services文件查看知名的应用层协议):ping程序,底层使用ICMP协议telnet协议: 远程登录协议ssh协议DNS协议,域名解析协议
-
以太网帧的封装过程:
TCP报文段的封装过程: 发送
发送TCP报文的过程如下:- 首先把数据从用户空间复制到内核空间的
TCP发送缓冲区中 - 之后把缓冲区中的数据和
TCP头部信息封装成IP数据报中的数据 - 利用
IP报文头部信息和报文信息封装以太网帧,利用物理媒介传递数据报 以太网帧的格式如下:
- 首先把数据从用户空间复制到内核空间的
-
分用: 表示底层的协议封装的数据报中需要包含使用的上层协议,比如以太网中需要包含上一层使用的协议(
ARP还是IP协议),根据协议来确定需要报数据交给内核中的哪一个模块 -
ARP协议 , 作用: 把IP地址转换为物理地址,ARP报文结构如下:
ARP协议的工作过程:- 首先利用自己的以太网地址(
MAC地址)和IP地址来构建数据报报 - 之后广播数据报(把目的端以太网地址使用
ff:ff:ff:ff:ff:ff) 即可 - 目的主机接收到信息之后改变操作并且把自己的
IP地址填充到数据报中发送回去
- 首先利用自己的以太网地址(
-
ARP高速缓存,存储着最近经常访问的主机的IP地址到物理地址的映射关系,可以使用如下命令查看ARP缓存和删除缓存
arp -a # 查看高速缓存
arp -d IP # 删除对应的高速缓存
arp -s IP MAC # 添加对应的缓存项
- 可以使用
tcpdump命令进行通信过程中的抓包,参考: 利用tcpdump抓包 ,这里记录tcpdump的常用形式:
# tcpdump 命令的基本格式如下:
tcpdump options proto dir type
# options 选项,比如 -i interface
# proto 协议 比如 ip,ip6,tcp,udp,icmp等
# dir 数据流向 dst/src
# type 类型过滤器 net host 等
# 下面是对于 proto , dir , type 等类型的过滤器的说明
# dir -> 根据数据流向过滤
# type -> 根据种类过滤 比如 host(主机) port(端口) net(网段)
tcpdump src net 192.168.10.0/24
tcpdump src port 80 or 8880
tcpdump src portrange 80-8880
# 根据协议 proto 进行过滤
tcpdump icmp # 查看 icmp报文
tcpdump 'ip proto tcp'
tcpdump 'ip6 proto tcp' # 表示 ip6 中的 tcp
# 重要的选项
tcpdump -i interface 指定网卡
# 另外 tcpdump 中还包含条件组合的功能,此时如果出现特殊符号比如 () , 需要使用 () 保卫
tcpdump 'src 10.0.2.4 and (dst port 3389 or 22)'
# tcpdump 实战使用
tcpdump -i eth0 -ent '(dst 192.168.0.2 and src 192.168.0.10) or (dst 192.168.1.2 and src 192.168.1.3)'
# 利用 tcpdump 观察 DNS 通信过程,其中 -s 指定包的大小 , port domain 表示只是抓取使用域名服务的包
sudo tcpdump -i wlp0s20f3 -nt -s 500 port domain
DNS协议的工作原理:DNS的作用: 域名解析协议,DNS报文如下,具体的内容可以参考书籍P13-14: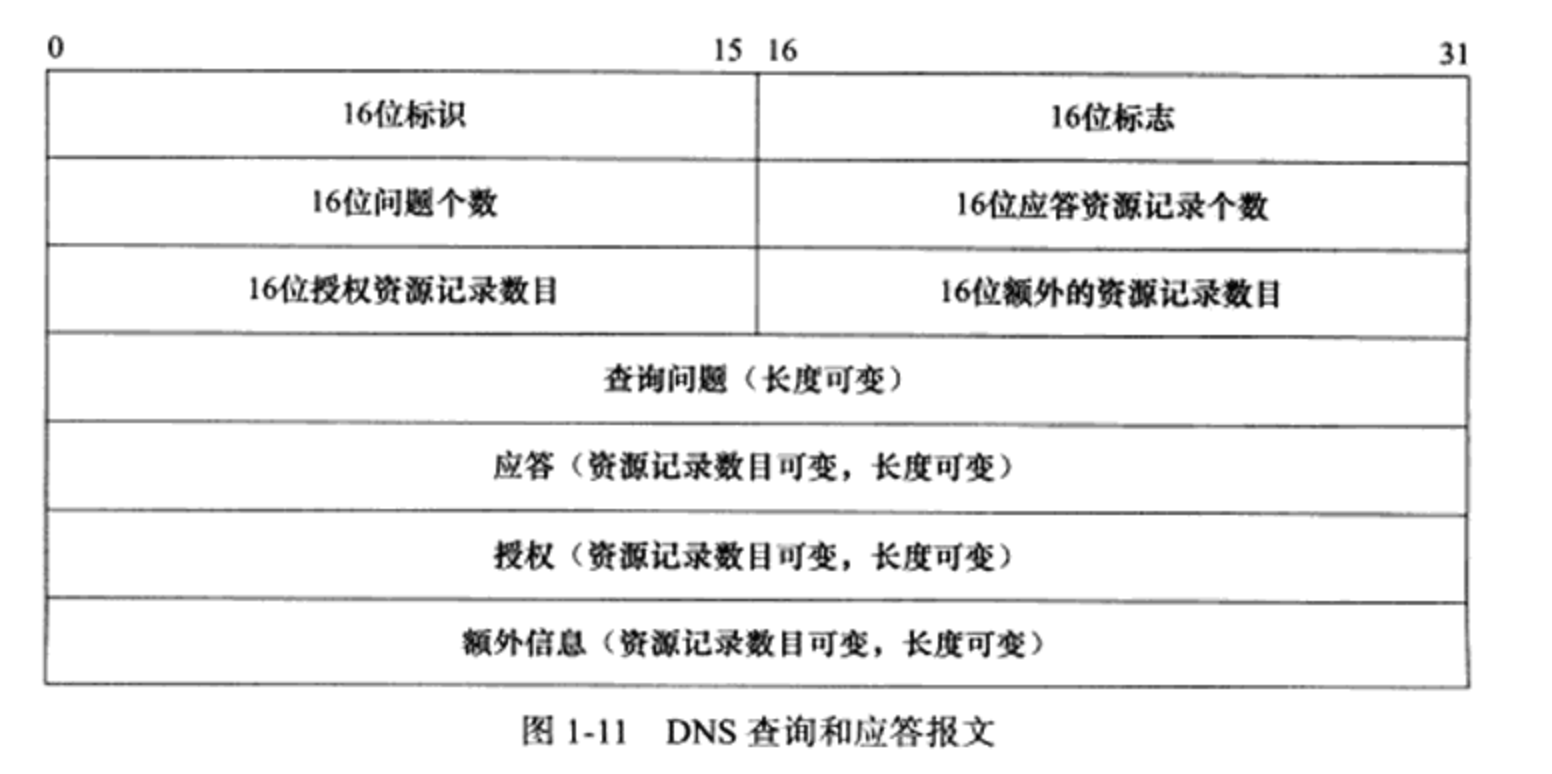
- 由于传输层,网络层数据链路层协议都是在
kernel中实现的,所以需要提供一组系统调用来供用于使用,socket就是这样一组系统调用 host用于利用DNS请求进行域名的查询,比如host -t A www.baidu.com其中,-t表示查询的记录类型
简单复习一下
Linux中的信号以及信号的捕捉和网络编程中常用的信号
- 发送信号可以使用
kill函数,函数原型如下:
int kill(pid_t pid, int sig);
其中pid的取值和发送目标进程的关系如下:
pid> 0 发送给PID为pid的进程pid= 0 发送给本进程组内其他进程pid= -1 发送给除了init进程之外的其他所有进程,需要有发送权限pid< 0 发送给所有的组ID=-pid的所有进程
- 信号处理方式(也就是信号处理函数),信号处理函数的定义如下:
typdef void(*__sighandler_t)(int)
除了自定义信号处理函数之外还有几种信号处理函数:
#define SIG_DFL ((__sighandler_t) 0) // 使用信号的默认处理方式
#define SIG_IGN ((__sighandler_t) 1) // 忽略信号
Linux信号,信号的种类很多,介绍一种常用的信号:SIGINT-> ctrl + C 中断进程SIGQUIT-> ctrl + \ 中断进程SIGKILL-> 终止进程,不可以被捕捉SIGUSR1,SIGUSR2-> 用户自定义信号SIGSEGV-> 段错误,非法访问内存SIGPIPE-> 向读端关闭的管道或者socket中写入数据SIGALRM-> 时钟定时信号SIGCHLD-> 子进程状态发生变化(可用于回收子进程)SIGTERM-> 终止进程SIGSTOP-> 暂停进程,不可以被忽略或者捕捉
- 中断系统调用: 进程执行阻塞系统调用的时候如何设置了某一个信号的信号捕捉函数并且接收到该信号,那么就会产生中断系统调用,并且对于默认行为为暂停进程的函数也会中断系统调用,并且
errno被设置为EINTR signal函数: 用于设置信号处理函数:
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
sigaction函数: 设置信号处理函数并且可以设置其他的行为(比如恢复中断系统调用等)
int sigaction(int signum,
const struct sigaction *_Nullable restrict act,
struct sigaction *_Nullable restrict oldact);
其中sigaction结构体如下:
struct sigaction {
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};
其中 sig_handler为信号处理方式,sa_mask为信号集掩码,可以使用 sigprocmask函数设置,sa_flags表示信号处理的选项,常见的选项如下:
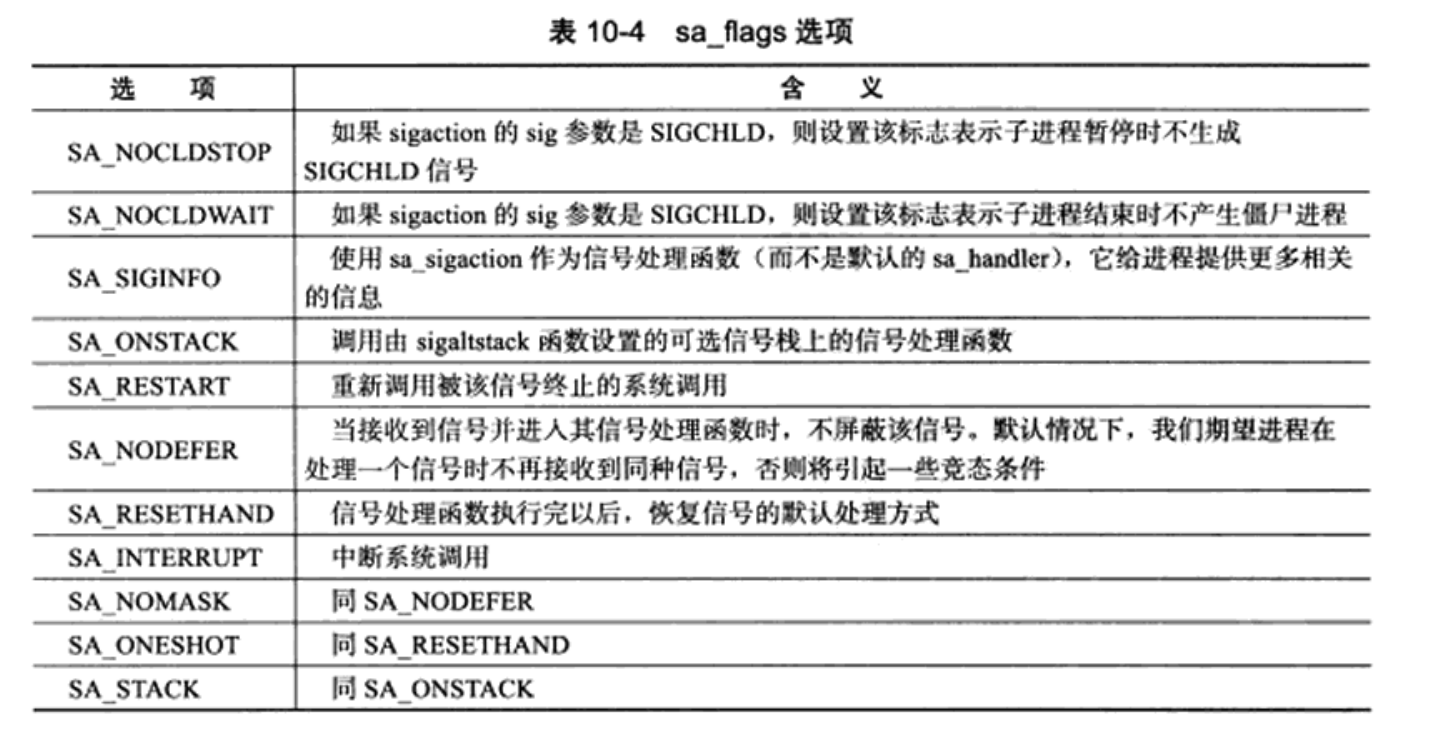 7. 信号集,信号集可以使用
7. 信号集,信号集可以使用 sigset_t 结构体表示,可以理解为一个位图,可以利用如下函数操作 sigset_t操作这一个结构体:
int sigemptyset(sigset_t *set);
int sigfillset(sigset_t *set);
int sigaddset(sigset_t *set, int signum);
int sigdelset(sigset_t *set, int signum);
int sigismember(const sigset_t *set, int signum);
- 设置信号掩码,使用
sigprocmask函数,函数原型如下:
int sigprocmask(int how, const sigset_t *_Nullable restrict set,
sigset_t *_Nullable restrict oldset);
how表示设置掩码的类型,set表示需要设置的信号集(需要使用上面的函数操作),oldset表示传出参数,传出之前的信号集,how可选选项如下:
SIG_BLOCK-> 设置屏蔽SIG_UNBLOCK-> 非屏蔽SIG_SETMASK-> 直接设置
- 被挂起的信号,当设置信号被屏蔽并且再一次接收到这一个信号的话就会导致信号被挂起,被挂起的信号当屏蔽区取消的时候就会被重新接收到,可以使用如下函数查看被挂起的信号:
int sigpending(sigset_t *set);
set为传出参数
10. 进程和线程与父进程和父线程的信号处理方式和屏蔽信号集的说明:
- 子进程和父进程有相同的屏蔽信号集和信号处理方式,同时子进程可以自定义自己的信号处理方式和屏蔽信号集,未决信号集一样
- 子线程和主线程有自己的信号处理方式,但是可以自定义自己的屏蔽信号集,当向该进程发送信号的时候会会遍历所有线程直到找到第一个不阻塞该信号的线程执行信号处理函数(使用
phtread_sigmask设置阻塞)
- 一种基于事件源的事件处理方案: 所有的信号都注册一个处理函数,在这一个处理函数中把捕捉到的事件发送到管道中,利用
IO多路复用监听管道,如果监听到发送的事件就可以判断发送的事件类型并且根据事件类型来确定处理方案,这是一种通用的基于事件源的处理方案, 可以见Github仓库中的代码 - 其他信号以及作用:
SIGHUP: 对于有控制终端的进程,挂起控制终端的时候就会触发这一个信号,对于没有控制终端的信号这一个信号可以当成一个控制信号使用,比如接收到这一个控制信号就会引起读取配置文件的操作行为SIGPIPE: 向读端关闭的管道或者socket中写入数据就会触发这一个信号,为了访问读端关闭引发程序退出,可以采取如下措施:- 设置
SIGPIPE的信号捕捉函数为SIG_IGN - 设置
send函数的选项中使用MSG_NOSIGNAL标志,同时检测errno为EPIPE从而检测管道是否关闭 - 或者检测
poll系统调用中的POLLHUP事件 SIGUSR: 用户自定义信号,可以用于检测带外数据或者作为特定事件的回调函数使用
- 注意
sigaction结构体中的sa_mask就是在信号处理过程中需要屏蔽的信号集,同时利用sigprocmask也可以设置屏蔽信号集,只不过利用sigprocmask设置的是整个进程的信号屏蔽集,总结: sigaction中的sa_mask设置信号处理过程中的信号屏蔽集sigprocmaks设置进程的信号屏蔽集
记录了
WebServer中三种定时器的实现方案,代码参考: https://github.com/xzwsloser/linux_webserver_base
- 定时器其实是指定时器时间,也就是在
WebServer中的三种事件之一(连接事件,IO事件,定时器事件),定时器事件需要利用特殊的容器管理,要求这些容器在规定的过期事件调用管理的某一个已经过期的定时器的回调函数完成相应的功能 - 基于升序链表的定时器: 把每一个定时器当成链表中的一个节点,并且按照过期事件的绝对值排列即可,心搏函数
tick根据当前事件确定满足不过期条件的最后一个定时器并且执行前面的定时器的回调函数从而完成定时事件 - 时间轮算法: 类似于环形队列 + 散列表的数据结构,环形队列的每一个槽位放一个链表,每一次利用头插法插入元素到链表并且通过节点的
rotation属性来判断是否到了定时器执行的时间,通过调节槽位的数量可以调节定时精度 - 时间堆算法: 按照过期时间的绝对值构成小根堆,每一次添加定时器就可以把定时器插入到堆中,每一次心搏函数启动的时候就可以不断的取堆顶端的元素并且执行回调函数
Libevent库基本编程方式:
Libevent库的核心组件: 其中各个组件的作用以及在
其中各个组件的作用以及在Libevent库中的实现如下:
Reactor: 用于管理各种事件,并且利用IO多路复用技术来实现事件的分发操作,比如把监听到的事件分发给绑定的事件处理,表现形式就是event_base对象,同时具有注册事件和删除事件的功能EventDemultiplexer: 相当于Reactor的底层的事件分发器把各个系统它中的IO多路复用封装成同一个接口给Reactor使用EventHandler: 事件处理器对象(其实可以成为事件对象),可以利用注册函数添加相应的回调函数和参数,在Libevent库中的实现就是event对象,包含三种event对象,分别为IO事件处理器,定时器事件处理器,信号处理函数等事件(核心就是event_new函数)ConcreteEventHandler: 具体的事件处理器对象
Libevent库各个组件之间的交互时序图:
如上就是
Libevent库中的各种基本组件以及之间的关系,关于其中更加详细的内容比如定时器的数据结构,Reactor用于管理各种事件处理器的数据结构等细节这里不做解释,之后阅读源代码的时候再看一下
主要讲解了进程之间通信的方法以及进程同步的方法也就是信号量,共享内存和消息队列
fork创建出来的子进程的特点:- 子进程与父进程之间相同的有堆栈指针,寄存器,
.text代码段 - 写时复制
- 原来的文件描述符号打开
- 信号处理方式不同
- 子进程与父进程之间相同的有堆栈指针,寄存器,
exec系统调用,不会关闭原来程序打开的文件描述符- 僵尸进程和孤儿进程:
- 僵尸进程: 父进程没有退出但是子进程退出,导致子进程的资源没有被释放
- 孤儿进程: 父进程退出但是子进程没有退出,此时子进程会被
init进程接管,等待子进程执行任务完毕之后回收子进程资源
- 一般可以使用
waitpid + SIGCHLD来回收子进程,比如:
static void handler_child(int sig) {
pid_t pid;
int stat;
while((pid = waitpid(-1 , &stat , WONHANG)) > 0) {
/* 处理子进程退出状态 */
}
}
信号量
类似于线程同步中的信号量,核心就是
PV操作
- 创建信号量集,或者获取到已经存在的信号量:
#include <sys/sem.h>
int semget(key_t key, int nsems, int semflg);
key: 信号量的唯一标识符号,通常可以设置为IPC_PRIVATEnsems: 信号集中信号量的个数,如果只是获取到信号量可以传入0sem_flags: 标识信号量的权限- 返回值就是信号量的标识值
- 对于信号量进行
PV操作:
#include <sys/sem.h>
int semop(int semid, struct sembuf *sops, size_t nsops);
// sembuf 成员
unsigned short sem_num; /* semaphore number */
short sem_op; /* semaphore operation */
short sem_flg; /* operation flags */
semid: 信号量标识符sops:sem_num: 信号量的编号sem_op: 信号量的操作数sem_flag:SEM_UNDO | SEM_NOWAIT都可以设置
nspos: 第二个操作数是一个数组,只是数组中的元素个数
- 设置信号量参数:
#include <sys/sem.h>
int semctl(int semid, int semnum, int op, ...);
semid: 信号集的标识符semnum: 被操作信号量在信号集中的编号op: 指向的命令,后面的省略参数就是命令的参数- 省略参数: 一般使用
union semun结构体来只是参数
共享内存
注意共享内存和
mmap的区别,共享内存相关的API返回创建的共享内存的文件描述符号,mmap可以把开辟的内存空间映射到进程的内存空间中,也就是可以直接使用指针来操作内存
- 创建共享内存:
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
key标识共享内存的唯一标识符号size指定共享内存的大小shmflg权限
- 把共享内存关联/取消关联到进程的地址空间中(类似于
mmap/munmap):
#include <sys/shm.h>
void *shmat(int shmid, const void *_Nullable shmaddr, int shmflg);
int shmdt(const void *shmaddr);
shmid: 共享内存的标识符号shmaddr: 传出参数,关联的指针,最好设置为NULL让他自己返回shmflg: 各种标志
- 控制共享内存的某些属性:
#include <sys/shm.h>
int shmctl(int shmid, int op, struct shmid_ds *buf);
shmid: 共享内存的标志op: 命令buf: 与设置相关
- 创建共享内存(类似于创建一个匿名文件):
#include <sys/mman.h>
#include <sys/stat.h> /* For mode constants */
#include <fcntl.h> /* For O_* constants */
int shm_open(const char *name, int oflag, mode_t mode);
int shm_unlink(const char *name);
- 和
open一样,第二个参数指定权限选项(比如O_RDONLY等)
消息队列
用于进程之间传递消息
- 创建消息队列:
#include <sys/msg.h>
int msgget(key_t key, int msgflg);
key: 消息队列的标识符号msgflg: 权限
- 发送消息:
#include <sys/msg.h>
int msgsnd(int msqid, const void msgp[.msgsz], size_t msgsz,
int msgflg);
ssize_t msgrcv(int msqid, void msgp[.msgsz], size_t msgsz, long msgtyp,int msgflg);
msqid: 消息队列标识符号msgp: 必须指向特殊的结构体需要体现消息类型和缓冲区大小msgsz: 消息长度msgflg: 设置是否阻塞等选项- 接受消息也是一样的
- 控制消息队列属性:
#include <sys/msg.h>
int msgctl(int msqid, int op, struct msqid_ds *buf);
感觉上面三种
IPC方式太老了不太重要
这里不介绍进程,信号量,条件变量,读写锁,互斥锁等组件的各种
API只是介绍一些基本问题
- 内核级线程: 有内核调度,用户级线程: 由调度器调度,根据内核级线程和用户级线程的比例可以分成三种模式: 完全由调度器调度(协程是吗???),完全由内核调度,或者两级调度
- 利用条件变量实现等待消费者模型的时候注意判断条件的时候使用
while不要使用if,这是由于最后唤醒条件变量的时候会开锁,所以可能条件又不满足了,就会发生竞争(也就是唤醒之后还是需要检查) - 每一个线程可以设置自己的信号掩码,但是所有线程的信号处理函数都是继承主线程的,同时可以通过
signal_wait函数处理信号
- 进程池和线程池的核心架构都是类似于预线程化,也就是把所有的进程/线程利用信号量或者锁卡在工作队列中即可,同时需要特定的选择算法挑选执行任务的进程/线程:
主要介绍
gdb调试
- 利用
gdb调试多进程: 可以使用attach pid的方法或者set follow-fork-mode parent/child的方法:
set follow-fork-mode parent/child设置追踪的进程set detach-on-fork on/off是否阻塞其他的进程,可以设置为oninfo inferiors显示正在运行的进程inferior n切换调试进程(好像没有用)
- 调试多线程:
info thread: 显示线程信息thread n: 改变调试线程set scheduler-locking on: 阻塞其他的线程
各种网络相关的工具
tcpdump抓包工具,可以参考 chapter1-TCP IP 协议族 注意使用这一个命令的格式lsof: 列出当前系统打开的文件描述符工具,常用命令如下:
-i显示socket文件描述符号,选项的使用方法:
$ lsof -i [46] [protocol][@hostname|ipaddr][:service|post]
-u: 显示用户启动的所有进程打开的所有文件描述符-c: 显示指定的命令打开的所有文件描述符-p: 显示指定进程打开的所有文件描述符(可以用于监听进程打开的文件描述符号)-t: 显示打开了目标文件描述符的进程的PID- 一般用于插件监听某一个端口的进程,或者检测打开某一个个文件的进程:
╰─$ lsof -i :10086
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
epoll_ser 19596 loser 3u IPv4 98693 0t0 TCP *:10086 (LISTEN)
nc: 可以充当服务器或者客户端
-i指定数据包传送的时间间隔-l: 以服务器的方式运行,指定监听的端口使用-p端口-p: 指定端口-s: 设置本地主机发送处的数据包的IP地址-C: 将\r\n作为结束符-u: 使用UDP协议-w: 没有检测输入就会退出-X: 指定代理方式-x: 指定代理服务器的IP和端口号-z: 扫描目标服务某一个端口是否开启
strace: 跟踪系统调用和信号,常用选项如下:
-c: 统计每一个系统调用的执行时间,执行次数和出错次数-f: 跟踪由fork调用生成的子进程-t: 在输出的每一行加上时间信息-e: 指定表达时,比如-e = signal就是跟踪信号的系统调用 显示如下:
strace: Process 22035 attached
restart_syscall(<... resuming interrupted read ...>) = ? ERESTART_RESTARTBLOCK (Interrupted by signal)
--- SIGINT {si_signo=SIGINT, si_code=SI_KERNEL} ---
+++ killed by SIGINT +++
netstat命令: 打印本地网卡接口的全部连接以及状态,路由表信息网卡信息等,选项如下:
-n: 使用IP地址标识主机-a: 显示结果中包含监听sockett: 仅仅显示tcp连接-r: 显示路由信息-i: 显示网卡接口的数据流量-p: 显示socket所属的进程的PID和名字 输出信息如下:
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:2017 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
vmstat: 输出各种资源的使用情况比如进程信息,内存使用,CPU使用率等小信息以及IO使用情况,具体选项如下:
-f显示系统启动以来执行的fork次数-s显示内存相关的统计信息以及多种系统活动的数量-d显示磁盘相关的统计信息-p显示磁盘分区的统计信息-S指定单位delay采用时间间隔count统计次数 显示信息如下:
procs -----------memory---------- ---swap-- -----io---- -system-- -------cpu-------
r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st gu
1 1 0 21983280 274416 7508224 0 0 534 323 2481 1 2 0 98 0 0 0
0 0 0 22019692 274448 7485988 0 0 0 86 975 1862 1 0 99 0 0 0
1 0 0 22034664 274464 7479256 0 0 0 31 816 1298 1 0 99 0 0 0
ifstat: 网络流量检测工具,常用选项包含:
-a检测系统的所有网卡接口-i指定网卡接口-t输出信息加上时间戳-b: 使用Kbit/s为单位delay: 采样时间间隔count: 采用次数 显示信息如下:
lo wlp0s20f3 br-1fd1af8b9846 docker0
KB/s in KB/s out KB/s in KB/s out KB/s in KB/s out KB/s in KB/s out
6.25 6.25 0.00 0.00 0.00 0.00 0.00 0.00
6.24 6.24 0.00 0.14 0.00 0.00 0.00 0.00
6.25 6.25 0.06 0.19 0.00 0.00 0.00 0.00
6.24 6.24 7.26 1.27 0.00 0.00 0.00 0.00
6.24 6.24 0.28 0.37 0.00 0.00 0.00 0.00
6.25 6.25 0.00 0.11 0.00 0.00 0.00 0.00
6.35 6.35 0.00 0.19 0.00 0.00 0.00 0.00
6.24 6.24 0.06 0.24 0.00 0.00 0.00 0.00
6.24 6.24 0.04 0.09 0.00 0.00 0.00 0.00
6.24 6.24 0.00 0.09 0.00 0.00 0.00 0.00
6.25 6.25 0.00 0.20 0.00 0.00 0.00 0.00
mpstat: 监视多处理器系统上每一个CPU调用情况,使用格式如下:
$ mpstat [-P {ALL}] [interval] [count]
-P可以指定监听的CPU编号,输出信息如下:
22时08分42秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
22时08分45秒 all 0.57 0.00 0.10 0.02 0.00 0.00 0.00 0.00 0.00 99.32
22时08分45秒 0 0.33 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.67
22时08分45秒 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
其中只需要关心:
%usr: 用户空间运行时间占比%sys: 运行在内核空间时间占比(不包含中断)%idle: 系统空闲时间占CPU运行时间
IP协议的特点: 无状态,无连接,不保证可靠数据传输,尽力交付的,本章从IP数据报的结构和路由来介绍IP协议IP数据报的结构如下: 下面解释一下几个比较关键的字段:
下面解释一下几个比较关键的字段:
- 版本号:
ipv4默认为4 - 头部长度
- 服务类型: 根据应用层服务的要求确定,类似于定制化服务
- 总长度
- 标识: 用于分片,同一个分片下所有的数据报的标识相同
- 协议: 报文中的上层协议
- 源端
IP地址 - 目的端
IP地址
- 版本号:
- 利用
tcpdump抓取ip数据报报文,方法如下:
sudo tcpdump -ntx -i lo port 端口号# lo 表示本地环路
IP分片,IP数据包的大小受到MTU的影响,比较大的IP数据报会被分成一些比较小的IP数据报,kernel中的IP模块可以利用IP数据报中的三个字段把数据报分片和成为数据包,也就是标识,标志位(用于标识最后一个数据报分片的位置) , 以及片偏移,并且对于比较大的报文可能分片之后会复制内容中上层协议报文的头部而不会复制内容IP路由过程,首先看kernel中IP模块的工作流程: 下面介绍几个比较重要的组成部分: 左边是数据报转发模块,一般来说是路由器的工作,另外一条线是处理发送给本机的报文
下面介绍几个比较重要的组成部分: 左边是数据报转发模块,一般来说是路由器的工作,另外一条线是处理发送给本机的报文
- 路由表: 记录着源
IP地址和目标IP地址的映射关系,在Linux下可以使用route命令查看和操作路由表
- 路由表: 记录着源
IP转发的过程:- 检查
TTL,看TTL是否为0 - 查看数据报的严格源路由选择,如果设置了这一个选项,那么就需要发送一个
ICMP源路由选择失败的报文给发送端 TTL减少1- 处理
IP头部信息 - 执行
IP分片操作
- 检查
ICMP重定向,重定向报文如下,上面的头部是ICMP报文的固定结构: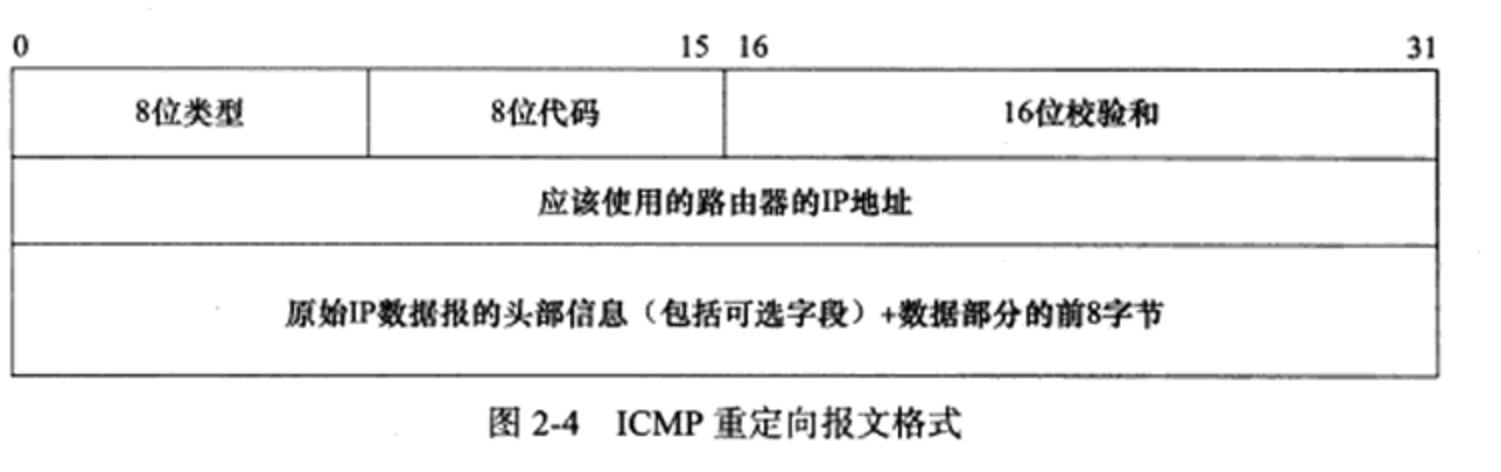
ipv6协议的头部(说明可以查看P27):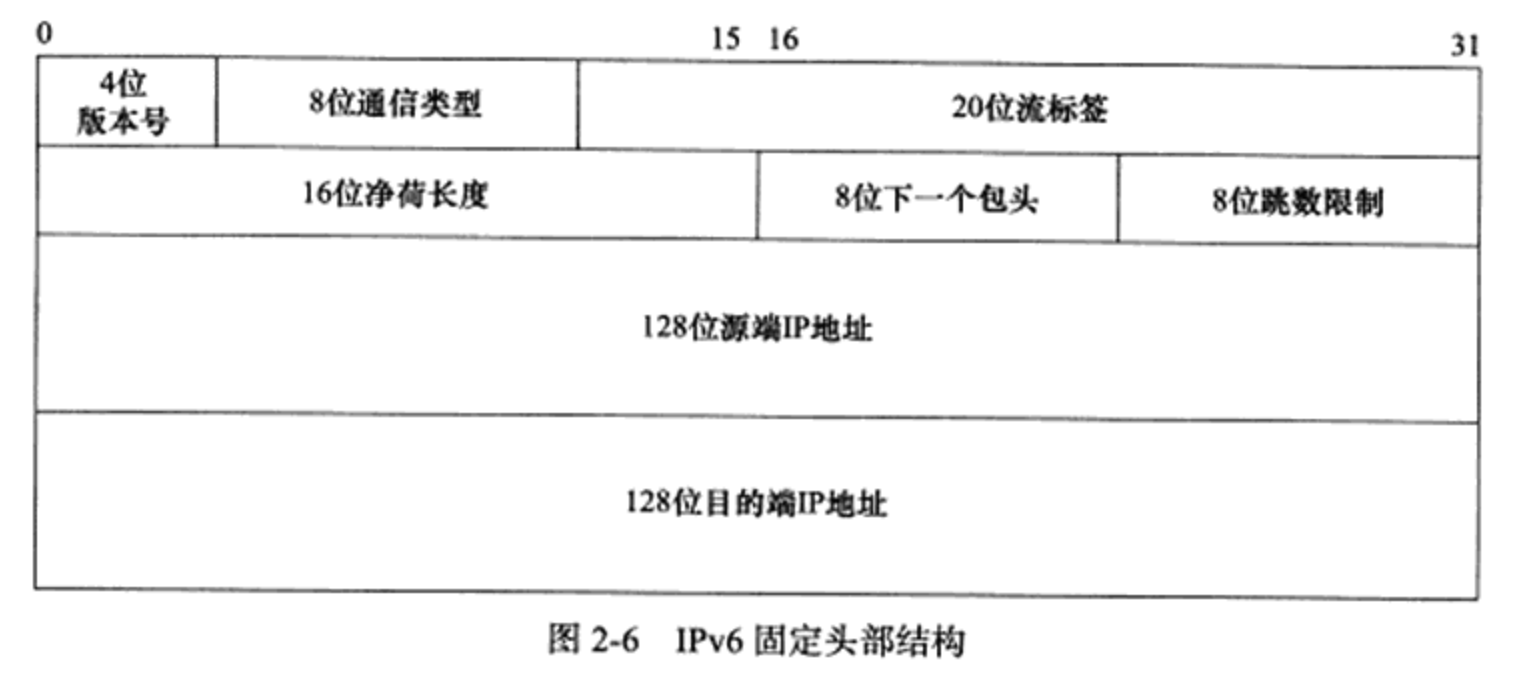
介绍
TCP服务的特点,TCP报文的结构,TCP的状态转移,TCP对于流的控制机制(TCP的拥塞控制)
TCP的特点: 可靠的,面向连接的传输层协议,TCP是一种基于数据流的协议,UDP是一种基于数据包的协议,两种的区别如下: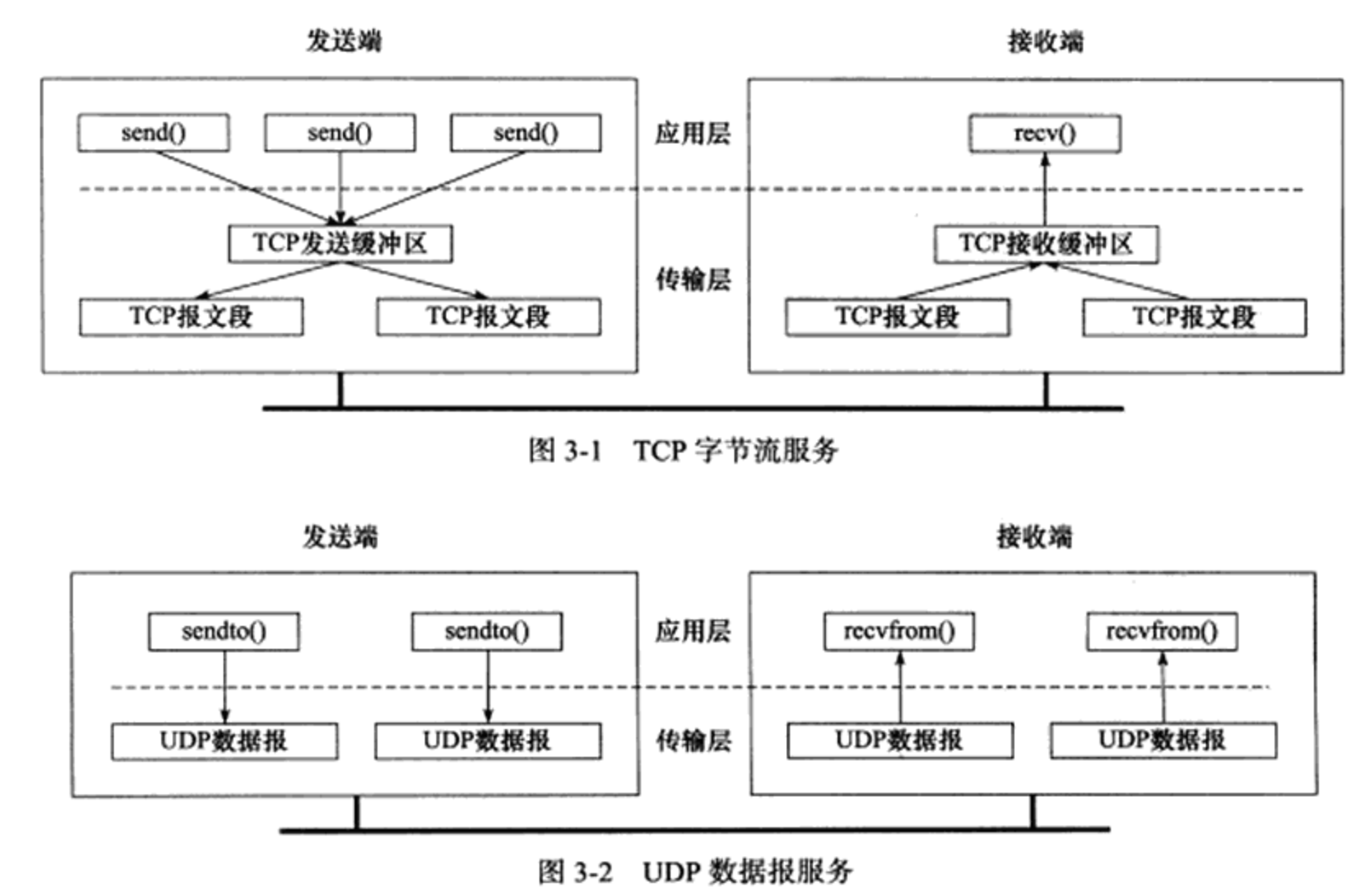
TCP头部结构如下: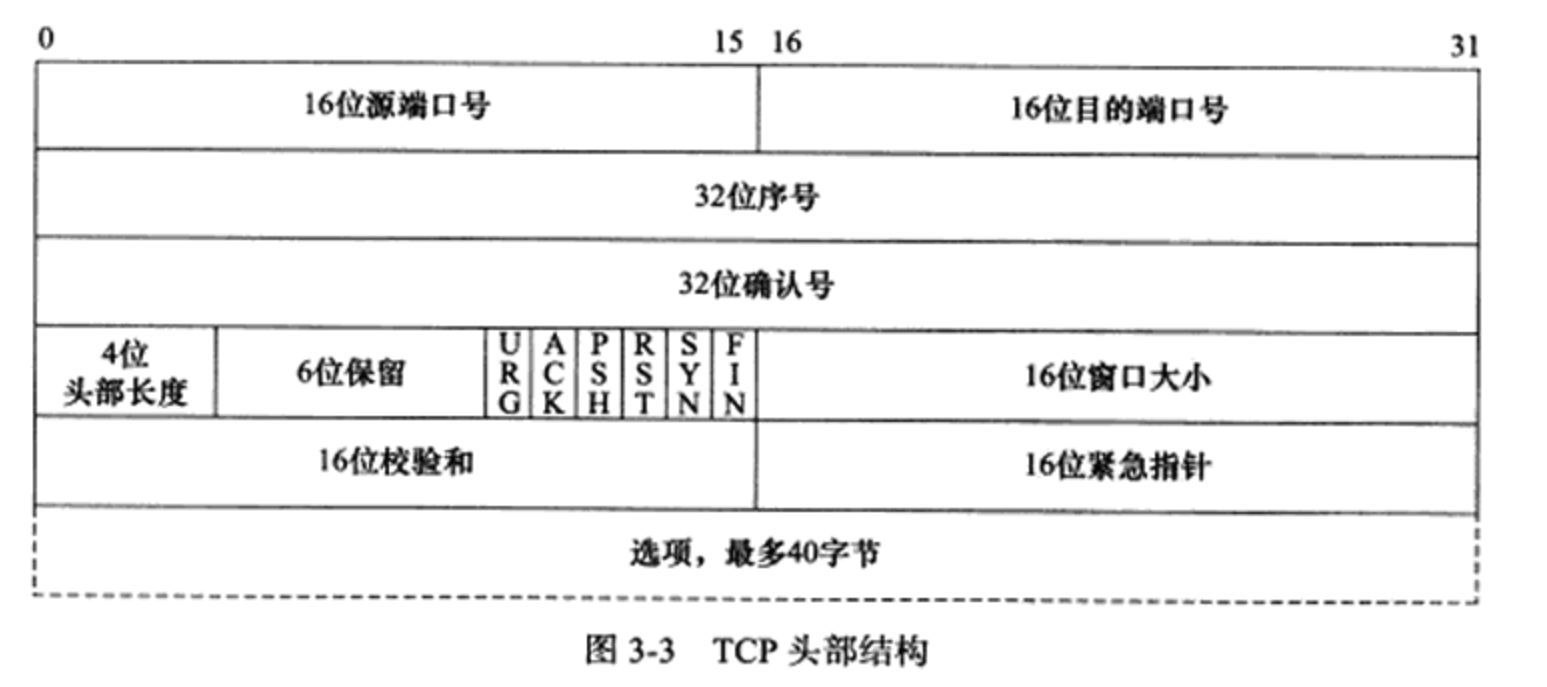 解释一下比较重要的几个数据:
解释一下比较重要的几个数据:
- 源头端口号: 对应发送数据的进程
- 目的段口号: 对应接受数据的进程
- 序号: 建立连接的时候分配一个初始的序号,之后传输的数据报的序号就是在当前字节流中的偏移量加上初始序号
- 确认号: 接收方发送给发送方的,发送方发送过来的序号加上
1就是确认号 - 头部长度
URG: 是否使用紧急指针,ACK: 确认报文,表示确认号是否有效,PSH: 表示高速接受方尽快处理缓冲区中的数据,RST: 复位连接,SYN: 建立连接,FIN: 表示结束连接- 窗口大小: 流量控制的一个手段,这里是指的
RWVD告诉接受缓冲区中的剩余容量 - 紧急指针: 一个偏移量,表示紧急数据的位置
TCP: 的头部选项,有很多作用并且格式相对来说比较固定,可以见P34TCP连接的建立和关闭,三次握手和四次挥手: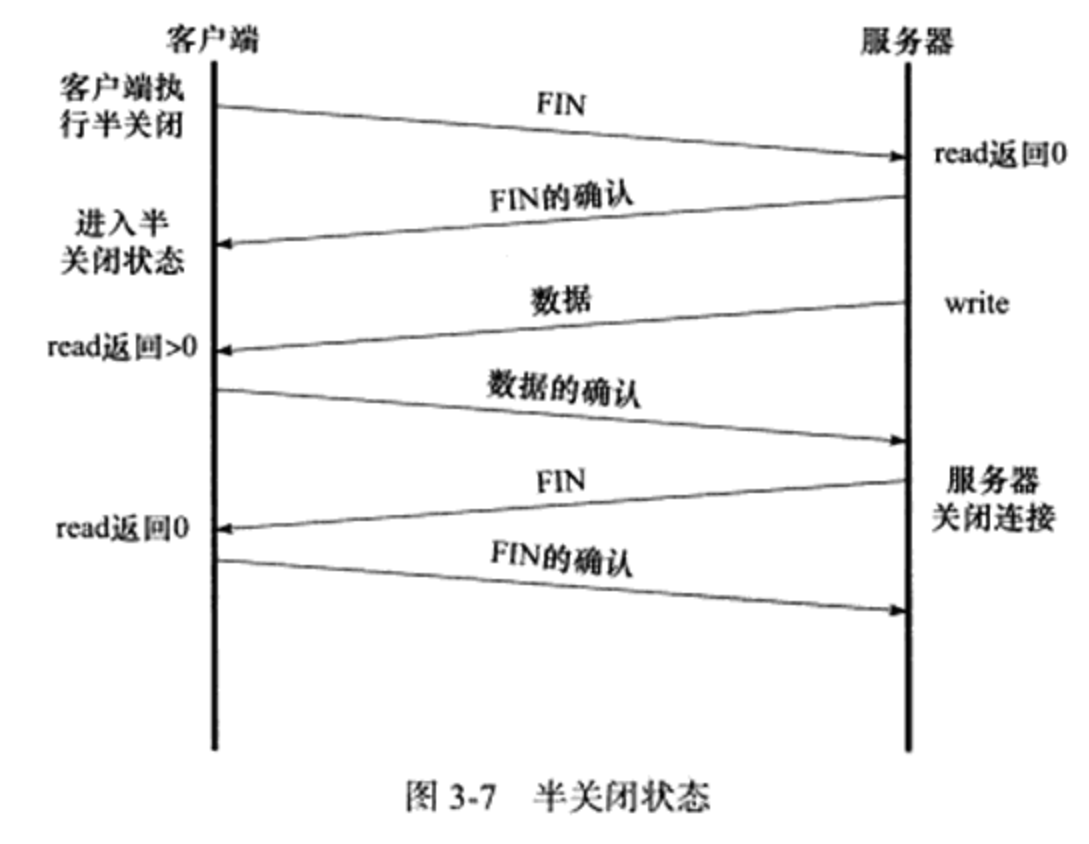
- 上图中,客户端接收到来自服务器端的
FIN之后就会进入半关闭状态,经过2MSL就会关闭连接,MSL表示TCP数据报存在的时间 - 如果由于网络原因可能发生
TCP的连接超时,连接超时就会导致重试,一般来说重试的时间由内核参数规定 TCP状态转移图,注意是TCP两端分别的状态转移图形,可以使用netstat命令查看TCP状态: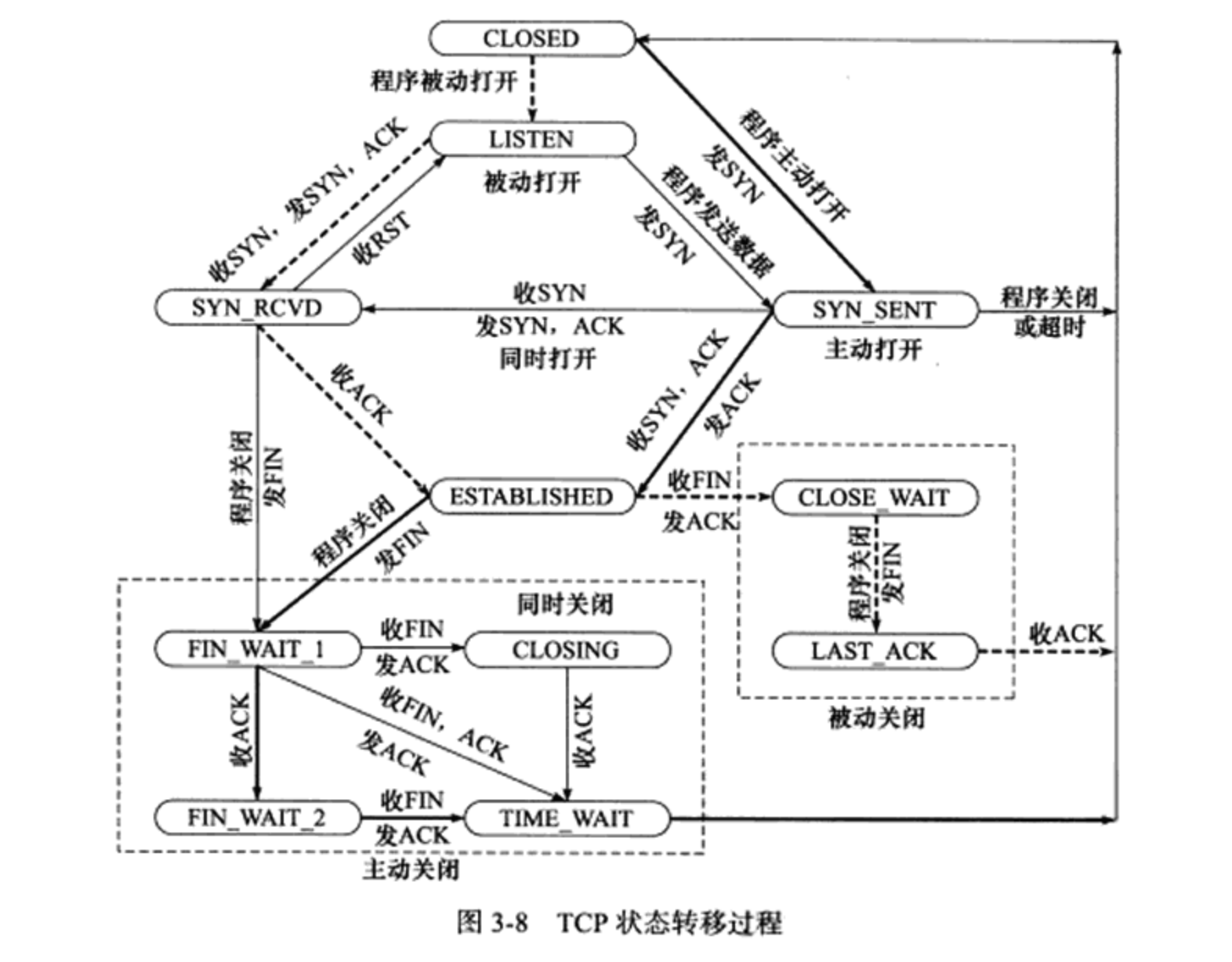
- 三次握手,四次挥手的过程中
TCP连接状态的变化如下: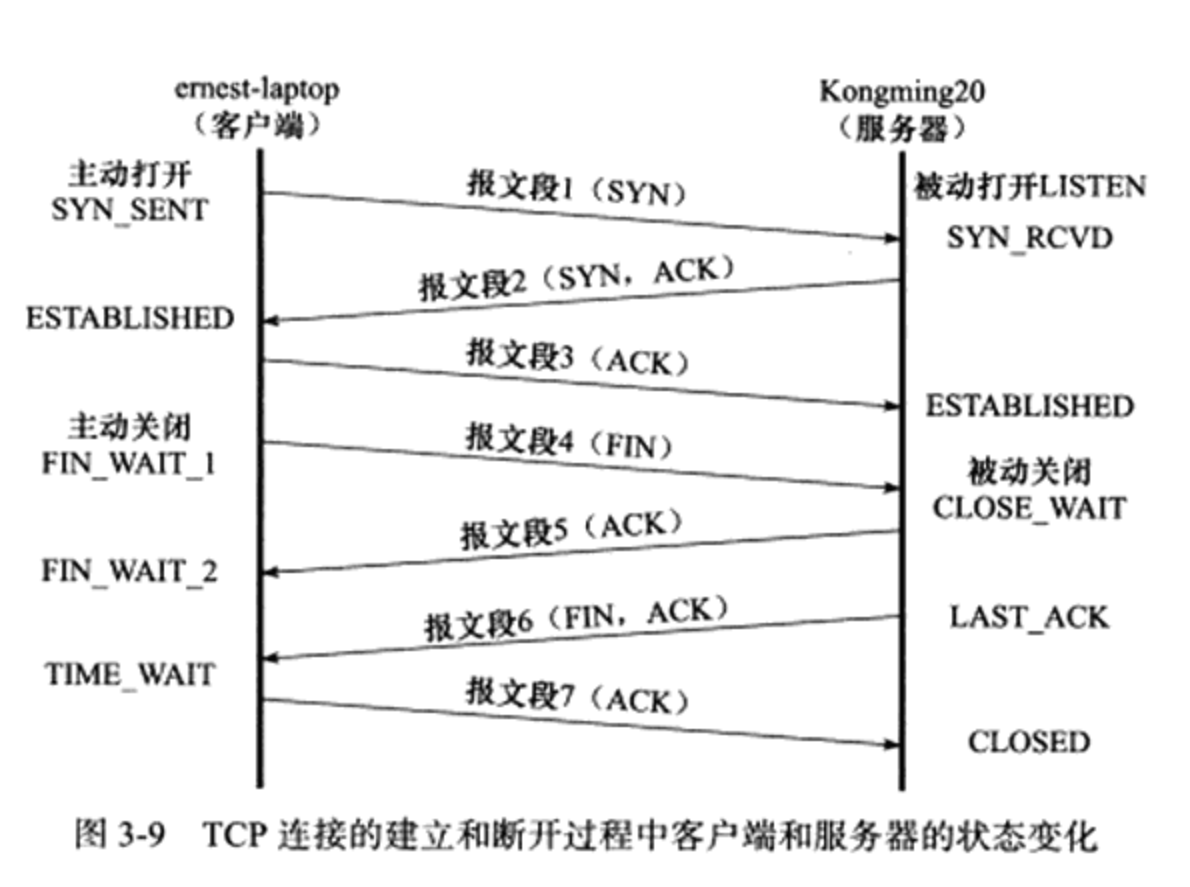
TIMEWAIT状态存在的作用: 可靠的终止TCP连接(接受所有迟到的数据报),保证让迟到的数据报有足够的时间被识别并且丢弃- 复位报文段出现的情景: 访问不存在的端口,异常终止连接,处理半打开连接(比较复杂)
TCP交互数据流: 发送的数据很少,接收方对于每一个数据报都会发送确认报文,TCP成块数据流: 一次发送大量数据,接收方批量进行数据的确认- 带外数据(也就是
TCP中的紧急数据) TCP的超时重传: 区分连接的超时重试,表示没有接收到数据报的确认需要之后的重传TCP拥塞控制: 最终需要控制 ->SWND(也就是一次发送的数据),需要依赖于RWND和CWND(拥塞窗口),根据拥塞窗口的大小来控制拥塞,最终关系:RWND = min(CWND , SWND)即可- 实现措施: 当没有发生拥塞的时候: 慢启动和拥塞避免, 真正发生拥塞的时候: 快速重传和快速恢复操作(详细的说明可以参考 《计算机网络:自顶向下方法》》)
第四章介绍
TCP/IP通信案例: 也就是访问Internent上面的Web服务器,但是我认为比较重要的部分就是访问DNS Server的过程,这一个过程中各种协议的使用在访问其他的服务器中也是一样的
DNS访问的过程: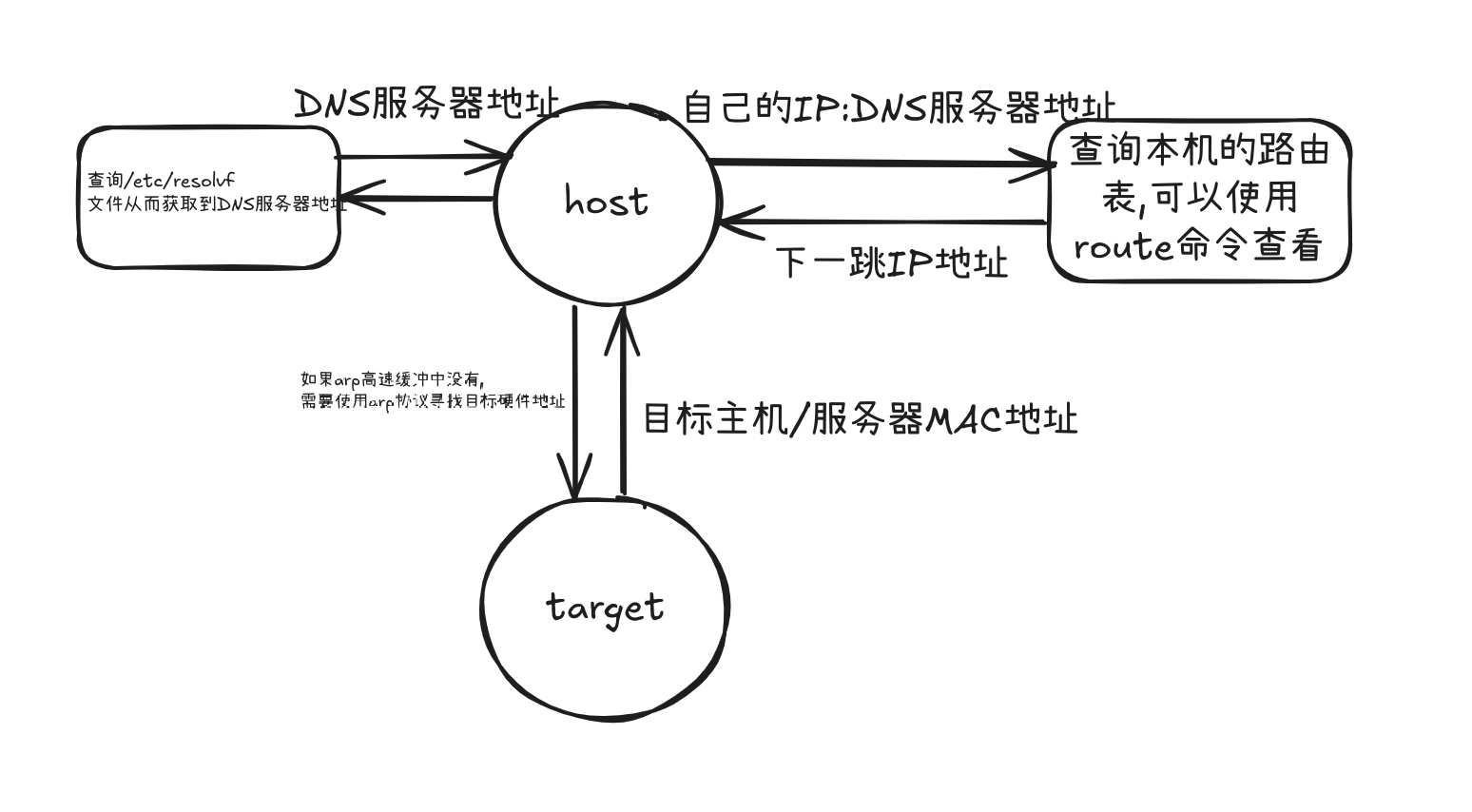
DNS地址存储在本机的/etc/resolv.conf目录中,如果没有就需要使用DNS协议解析主机地址,同时在/etc/hosts目录下存储着主机名和IP地址之间的映射关系,比如本机的/etc/hosts中的内容如下:
127.0.0.1 localhost
127.0.1.1 loser-XiaoXinPro-16-IRH8
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
重要的就那么几个,说几个注意点即可
- 利用
socket创建网络套接字的时候函数的第二个选项:type可以选择与宏定义:SOCK_NONBLOCK和SOCK_CLOEXEC选项进行相与操作,第一个参数表示设置套接字为非阻塞,后面一个选项表示fork子进程的时候关闭父进程中的套接字 listen函数的作用:可以设置内核监听队列的最大长度,如果长度超过最大队列长度就不会受理新的客户连接,backlog参数是指所有处理半连接状态(SYN_RCVD)和完全连接状态 (ESTABLELISHED)状态的连接accept函数的作用只是在内核监听队列中取出参数,并不会检查网络状态TCP协议中的数据读写函数如下,第三个选项可以根据自己的需要选择(P81)
ssize_t recv(int sockfd, void buf[.len], size_t len, int flags);
ssize_t send(int sockfd, const void buf[.len], size_t len, int flags);
UDP读写数据使用的函数如下(从下面的函数可见,UDP使用数据包的方式传递数据):
ssize_t recvfrom(int sockfd, void buf[restrict .len], size_t len,
int flags,
struct sockaddr *_Nullable restrict src_addr,
socklen_t *_Nullable restrict addrlen);
ssize_t sendto(int sockfd, const void buf[.len], size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
另外还用通用的读写函数,但是一些简单的需求可以使用上面的函数就够了 6. 可以使用如下函数来通过套接字来获取到绑定的地址结构体相关的信息(下面的参数都是传入传出参数):
#include<sys/socket.h>
int getsockname(int sockfd , struct sockaddr* address , socklen_t* address_len);
int getsockname(int sockfd , struct sockaddr* address , socklen_t* address_len);
- 可以利用如下两个函数来修改
socket相关的选项:
int getsockopt(int sockfd, int level, int optname,
void optval[restrict *.optlen],
socklen_t *restrict optlen);
int setsockopt(int sockfd, int level, int optname,
const void optval[.optlen],
socklen_t optlen);
比如可以利用下面一个函数修改TCP缓冲区的大小,或者可以修改为允许端口复用,可选选项如下:
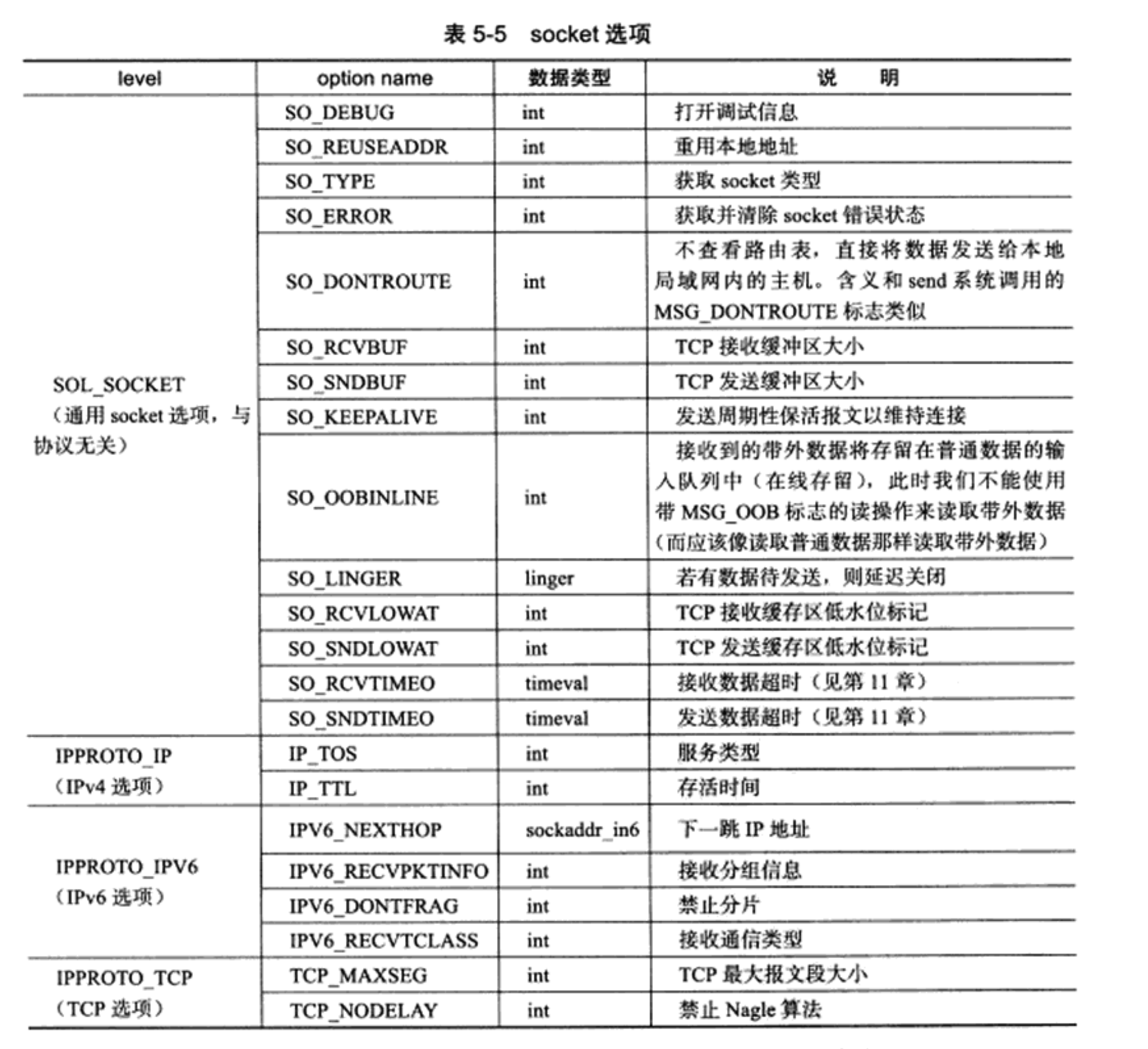 比如设置允许端口复用的方法如下:
比如设置允许端口复用的方法如下:
int setVal = 1;
setsockopt(sockfd , SOL_SOCKET , SO_REUSEADDR , &setVal , sizeof(setVal));
- 网络信息
API种类很多,大多都是基于DNS协议工作的,可以获取到主机名或者服务名(或者对应的端口),需要使用的时候查看 gethostbyname和gethostbyaddr通过主机名称或者主机地址来获取主机相关的信息(通过结构体struct hostent来获取)getserverbyname和getserverbyport通过服务名称或者服务端口获取服务相关的信息,结果存储在结构体:struct servant中getaddrinfo通过主机名称或者服务名称来获取到主机或者服务相关的信息,函数原型如下:
int getaddrinfo(const char *restrict node,
const char *restrict service,
const struct addrinfo *restrict hints,
struct addrinfo **restrict res);
返回结果是一个链表,链表中的节点存储这需要的数据:
struct addrinfo {
int ai_flags;
int ai_family;
int ai_socktype;
int ai_protocol;
socklen_t ai_addrlen;
struct sockaddr *ai_addr;
char *ai_canonname;
struct addrinfo *ai_next;
};
其中hints表示提示消息相当于过滤消息
12. getnameinfo通过 socket地址同时获取到主机名称和服务名称:
int getnameinfo(const struct sockaddr *restrict addr, socklen_t addrlen,
char host[_Nullable restrict .hostlen],
socklen_t hostlen,
char serv[_Nullable restrict .servlen],
socklen_t servlen,
int flags);
基本上没有用,这里指介绍比较重要的概念和函数
pipe: 创建匿名管道,用于进程之间通信dup2: 函数原型如下:
int dup2(int oldfd, int newfd);
作用: 相当于把 newfd对应的 inode表项复制给 oldfd,这样使得使用 oldfd的时候就像使用 newfd一样了
3. readv和 writev函数: 并文件描述符号写或者读到分散的内存中,没用
4. mmap和 munmap作用: 可以将文件映射到程序的内存中,后者可以删除这一种映射,可以用于进程进程之间的通信
void *mmap(void addr[.length], size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void addr[.length], size_t length);
最安全的做法就是: mmap(NULL , file_len , PROT_READ | PROT_WRITE , MAP_SHARED , 0) 即可
5. sendfile用于在两个文件描述符之间发送文件,使用零拷贝(也就是直接在内核中进行文件内容的拷贝),类似于的函数还有 splice
6. tee: 用于在两个管道之间进行内容的拷贝
7. fcntl函数: 用于改变或者读取文件的属性,函数原型如下,相对来说比较重要
#include <fcntl.h>
int fcntl(int fd, int op, ... /* arg */ );
其中fd表示文件描述符,op表示操作类型,之后的表示参数,其中操作类型的种类包含:
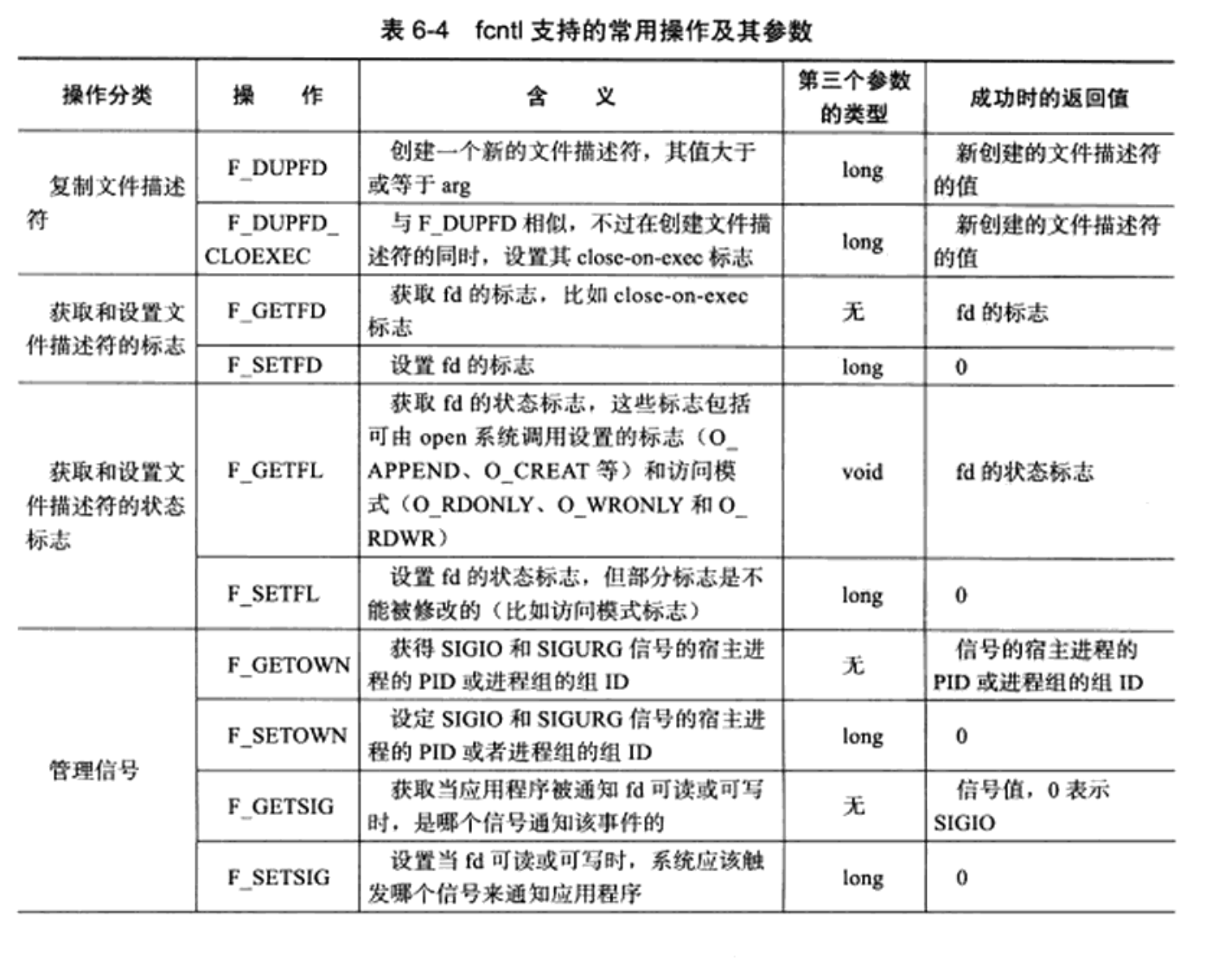

比如利用 fcntl函数设置文件属性为非阻塞的方式如下:
int setnobloking(int fd) {
int old_option = fcntl(fd , F_GETFL);
int new_option = old_option | O_NOBLOCK ;
fcntl(fd , F_SETFL , new_option);
return old_option;
}
这一个函数相对比较重要
8. 同时另外比较重要的IO函数还有: stat , lseek , open等函数,可以参考之前的笔记
int stat(const char *restrict pathname,
struct stat *restrict statbuf);
int open(const char *pathname, int flags, ...
/* mode_t mode */ );
off_t lseek(int fd, off_t offset, int whence);
ear主要还是补充了 Linux 中的一些基本知识
Linux日志系统,Linux中通过守护进程syslogd来管理日志,对于kernel,内核日志首先利用printk等函数把信息打印到内核的环形缓冲区中,之后环形缓冲区中的内容直接映射到/proc/kmsg文件中,对于用户态,使用函数syslog首先把日志打印到/dev/log文件中,之后由syslogd守护进程把文件同步到/var/log/*文件中,Linux的系统日志系统如下: 相关函数比如
相关函数比如 syslog和openlog函数- 用户信息:
UID,EUID,GID,EGID, 一个进程拥有两个用户ID:UID和EUID其中EUID的作用就是: 使得运行程序的用户用于有效用户的权限,比如su程序的EUID就是root, 所以su程序的用户可以使用有效用户root的权限,可以通过一些类的getXXX,setXXX函数来获取到进程的各种用户信息 - 进程组:
Linux下每一个进程都属于一个进程组,一个进程组中的组长进程的PID和进程组PGID相等 - 会话: 一些有关联的进程组形成一个会话,可以利用
setsid创建一个会话
#include<unistd.h>
pid_t setsid( void );
利用这一个函数创建新的会话的同时会产生如下效果:
- 调用进程会成为会话的首领,并且是最新会话中的唯一一个成员
- 新建一个进程组并且成为进程组的首领
- 调用进程将脱离终端
- 改变工作目录可以使用
chdir方法,改变根目录可以使用chroot方法(但是没有改变工作目录) - 服务器进程后台化(掌握后台化的方法): 步骤如下:
- 首先设置文件掩码,使得进程创建新的文件的时候文件的权限为
model & 0777 - 创建新的会话并且设置本进程为进程组的组长
- 关闭标准输入设备,标准输出设备和标准错误设备
- 关闭其他已经打开的文件描述并且蒋标准输入,标准输出和标准错误都重定向到
/dev/null文件中即可,直接使用open函数即可,此时就可以直接占用空出来的运算符 daemon.c
主要介绍服务器模型,服务器-客户端模型架构以及几种高效的时间处理模式,几种高效的并发模式以及一种程序的设计思想(也就是状态机的思想)
- 服务器的两种基本架构:
C/S架构,P2P架构,这里主要讨论C/S架构 - 服务器编程框架,基本架构如下:
IO处理单元 -> 逻辑单元(比如工作进程和线程等) -> 网络存储单元(可选)(比如数据库等),基本架构如下:
- 下面介绍几种
IO模式,大体分为 同步模式和异步模式,这两种模式的区别就是:- 同步模式: 把自己想象为客户端,利用同步的
IO处理模式得到的时间就是读就绪或和写就绪时间,具体的读写操作需要自己执行(可以理解为顺序执行) - 异步模式: 利用异步的
IO处理模式得到的是IO完成时间,实际的IO读写事件其实发生在后端/kernel中
- 同步模式: 把自己想象为客户端,利用同步的
- 下面介绍几种基于同步或者异步模式的
IO函数:- 同步模式:
- 阻塞
IO,比如不设置IO属性的网络套接字操作 IO多路复用: 比如select,poll,epoll- 信号驱动
IO, 也就是某一个文件的某一个事件通过触发信号的方式来调用信号处理函数从而完成IO操作
- 阻塞
- 异步模式:
- 异步的
IO模式当监听到读就绪或者写就绪的时候自己在内核中完成读写操作,比如Linux中的aio_read等函数
- 异步的
- 同步模式:
- 两种高效的事件处理模式(比如读事件,写事件等):
reactor: 一般用于同步模式: 这一种模式下,主进程的作用就是不断监听事件,并且把事件放入到请求队列中,之后子进程通过来处理事件并且同时把写事件页注册到IO多路复用函数中proactor: 一般用于异步模式: 这一种模式下,所有的读写操作都是由内核来完成,内核完成读写操作之后通过发送信号从而触发信号处理函数从而选择工作进程执行善后工作,工作进程也可以调用异步的IO函数让内核执行相应的操作- 模拟
proactor模式: 利用同步的方式来模拟proactor,其实就是主进程代替了内核的功能,也就是代替内核完成读写的操作 三种模式的基本架构如下(这里的IO多路复用函数使用epoll):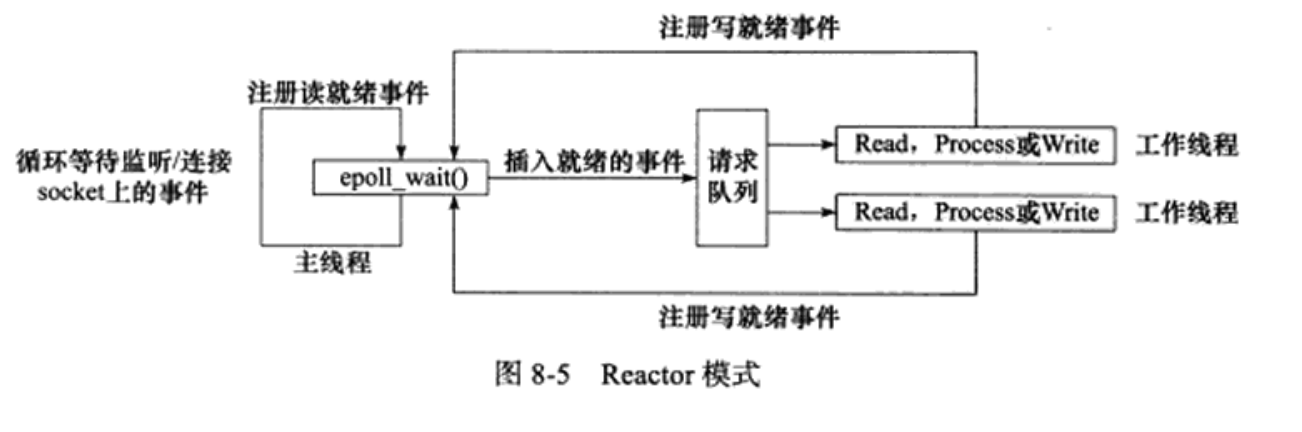
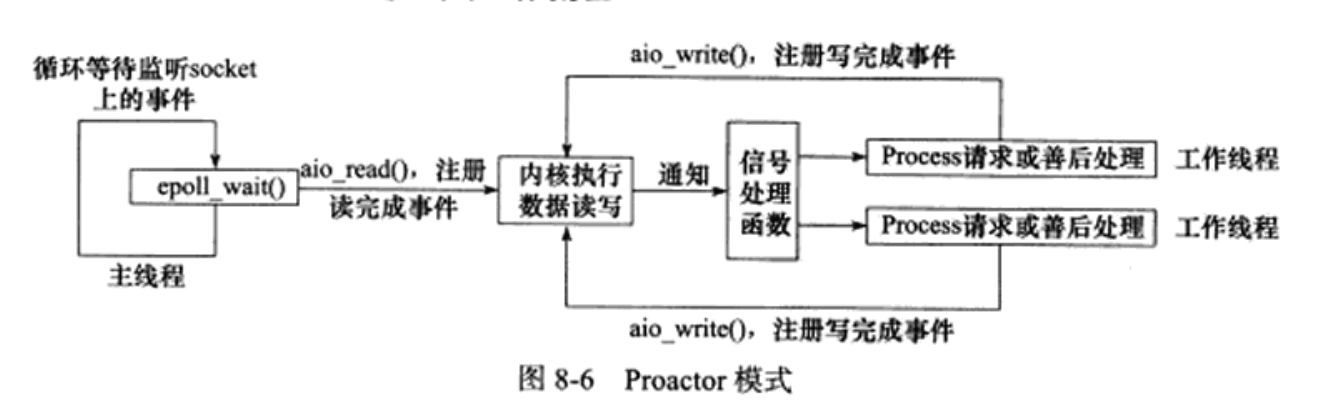
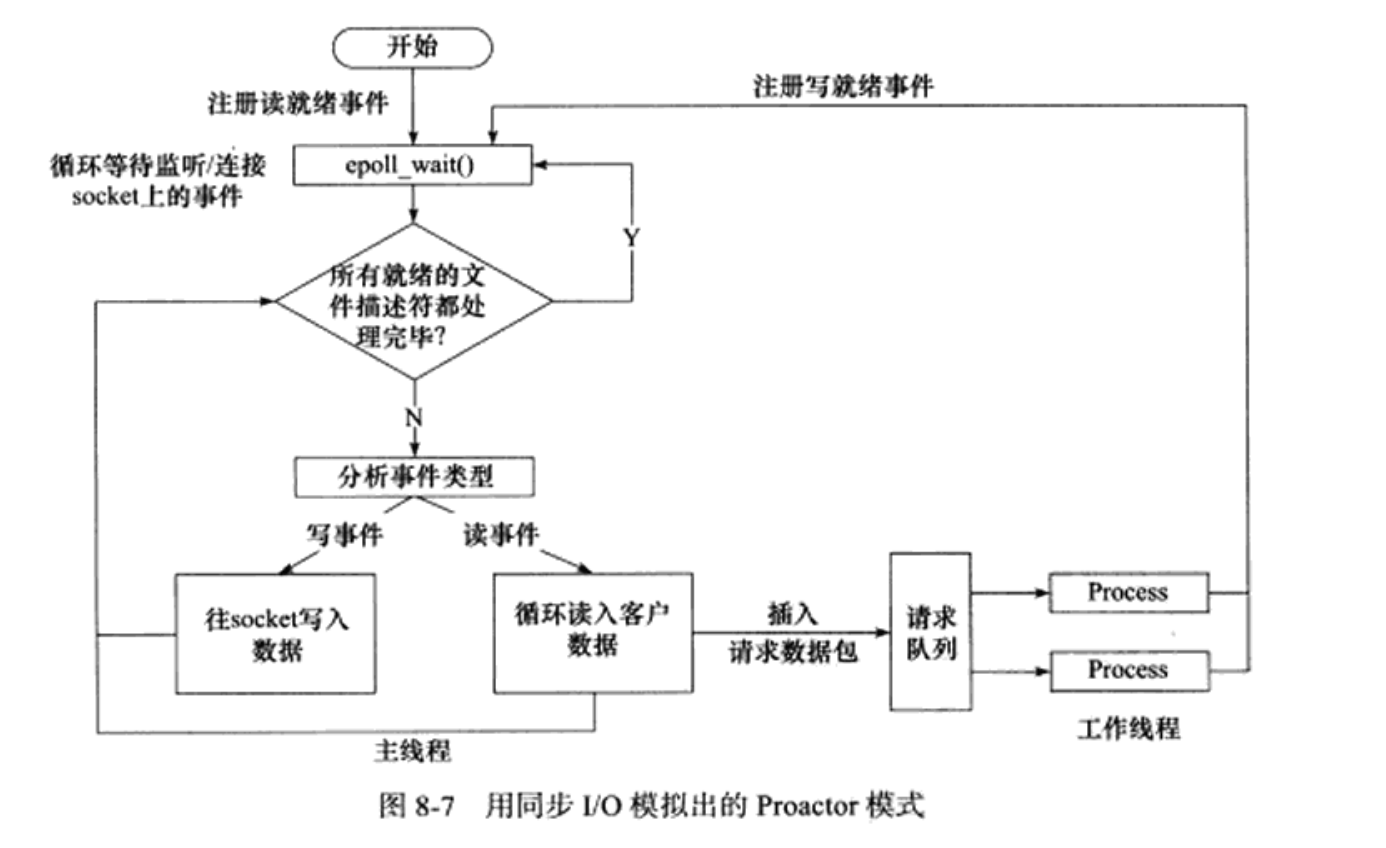
- 接下来介绍两种高效的并发模式:
- 半同步/半异步模式: 这里的同步是指程序中的代码是顺序执行的,异步是指的程序中的代码不是顺序执行的(比如信号的处理函数等)
- 领导者/追随者模式: 领导者负责监听的功能,当监听到事件就会处理事件从而转到
processing模式,领导者可以互换
- 半同步/半异步模式: 同步进程进行客户逻辑的处理,异步进程进行事件的监听,同时为了拓展监听的事件的数量可以使用半同步/半异步反应堆模式,整体的架构如下(感觉类似于
reactor,但是reactor侧重于事件,这里侧重于执行工作的线程和进程等资源)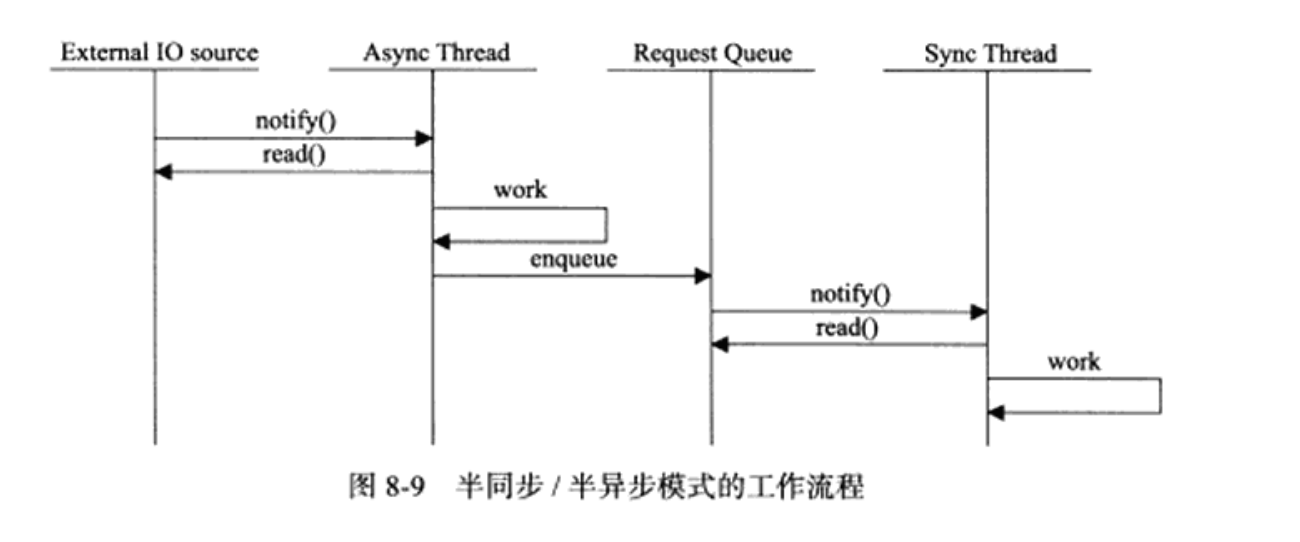
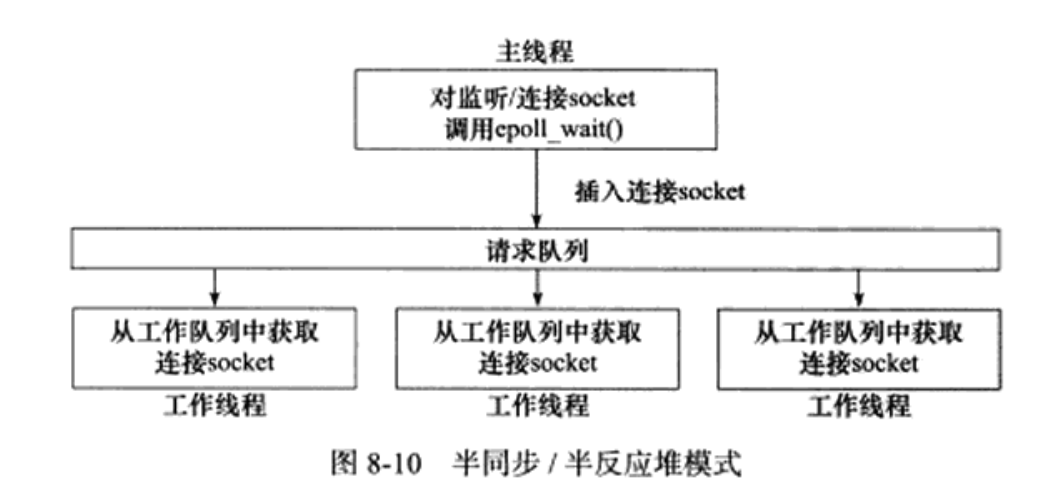
- 领导者追随者模式,明确几种组件: 句柄类,事件处理器,具体的事件处理器和线程集等,注意数据交换方式,下面为系统架构以及时序逻辑图:
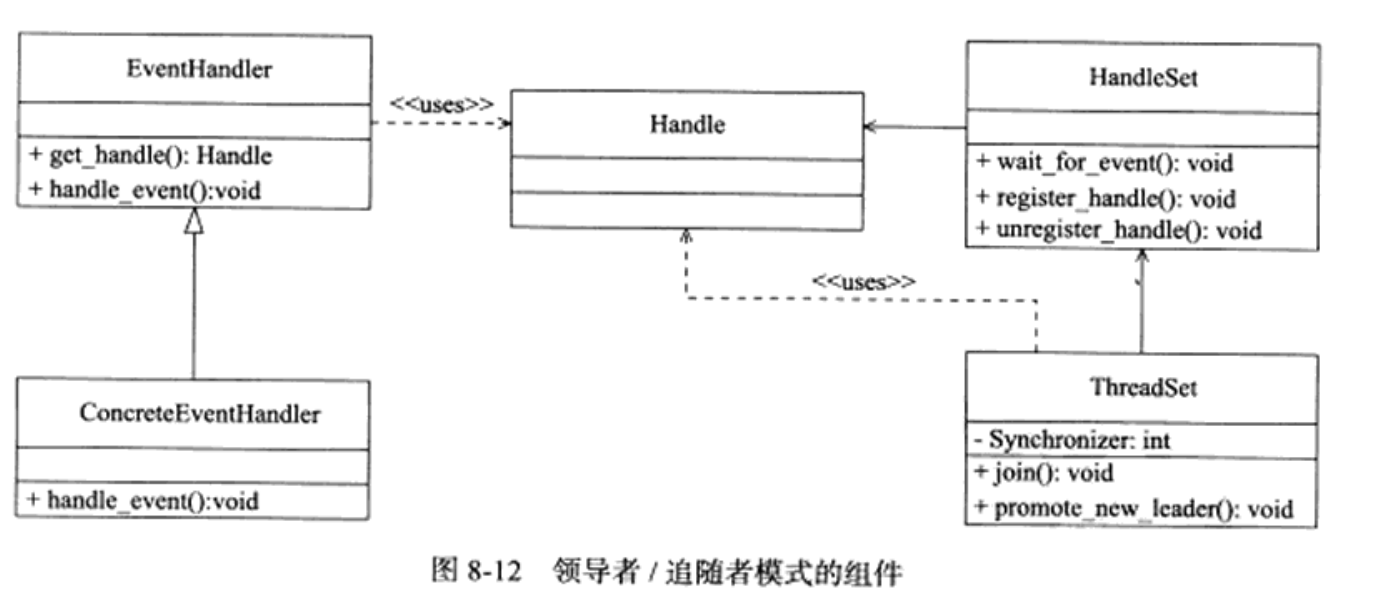
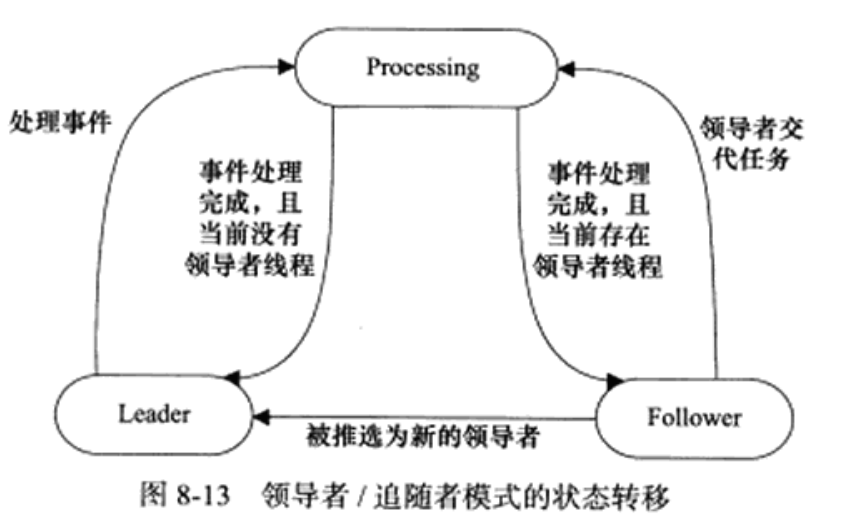
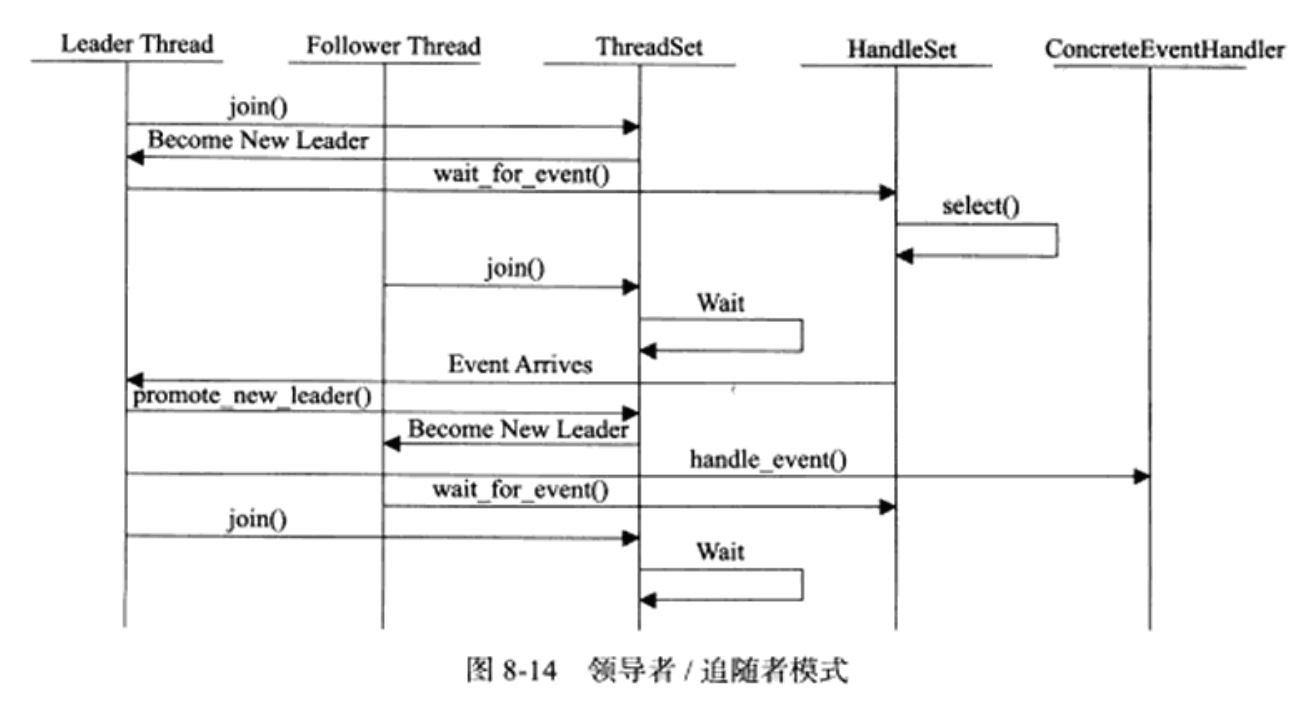
- 状态机: 当程序的状态进程发生转换的时候就可以使用状态机法来描述程序(比如可靠数据传递的实现(
TCP))的实现,一般难以用到 - 优化服务器的几种策略:
- 池化技术: 线程池,进程池等
- 计算密集型 -> 单线程,
IO密集型 -> 多线程(但是需要考虑上下文切换和锁) - 数据复制使用零拷贝(直接由内核进行拷贝即可)
主要介绍三种
IO多路复用函数:select,poll和epoll笔记相应的服务器实现方式,终点掌握IO多路复用解决的问题,注意IO多路复用是一种同时监听多个事件的方法,本章的所有代码我之后会上传到github仓库中
select系统调用,函数原型如下:
int select(int nfds, fd_set *_Nullable restrict readfds,
fd_set *_Nullable restrict writefds,
fd_set *_Nullable restrict exceptfds,
struct timeval *_Nullable restrict timeout);
解释一下其中的参数:
nfds: 最大的文件描述符号加上1readfds: 表示读取文件描述符号的集合,是一个结构体需要使用特定的函数操作writefds: 表示可以写的文件描述符的集合,同上exceptfds: 表示异常的文件描述符集合- 最后一项:
NULL-> 阻塞, 否则表示具体的事件单位 - 返回值: 三个文件描述符集合中准备好的文件描述符的个数
fd_set 结构体相关的操作函数如下:
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
下面解释一下具体的事件就绪行为:
- 可读:
- 内核接受缓冲区中的字节数量大于最低水位线(可以使用
setsockopt)函数设置 socket通信的对方关闭- 监听
socket上面有新的连接请求 socket上有未处理的错误,此时可以使用getsockopt函数清除错误- 可写:
- 内核发送缓冲区中的可用字节数量大于最大水位线(可以设置)
socket的写操作被关闭,对于写操作关闭的socket执行写操作会触发一个SIGPIPE信号socket使用非阻塞connect连接成功socket中有没有处理的错误- 异常:
- 接受到带外数据
poll系统调用,函数原型如下:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
参数解释:
fds: 表示准备好的文件描述符号数组nfds: 表示总共需要监听的文件描述符个数timeout: 超时事件,如果传入-1表示阻塞- 返回值: 也是准备好的文件描述符号个数
使用基本和
select一样
epoll系统调用,Linux中独有的系统调用,函数原型(使用如下三个函数完成epoll系统调用)如下:
int epoll_create(int size);
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
int epoll_ctl(int epfd, int op, int fd,
struct epoll_event *_Nullable event);
其中epoll_event结构体如下:
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
};
下面解释上面函数的含义:
epoll_create: 相当于创建内核文件注册表epoll_wait: 根据内核注册表中注册的监听事件来监听事件的活动epoll_ctl: 设置文件描述符号在监听过程中的属性,类似于poll中的设置fdset集合的函数
epoll中的LT模式和ET模式:
LT模式: 电平触发模式,只要接受区中有数据就会一致触发ET模式: 边沿触发模式,指由接受区中数据从无到有才会触发,这就要求文件描述符号必须是非阻塞的,应为如果设置为阻塞的(就是利用read读取数据的时候没有数据就会发生阻塞),这就导致没有数据的时候读取就会卡住,从而陷入死循环(可以使用fcntl函数设置文件描述符的阻塞属性) , 由于触发次数更少所以效率更高
- 三种
IO多路复用模式之间的对比如下: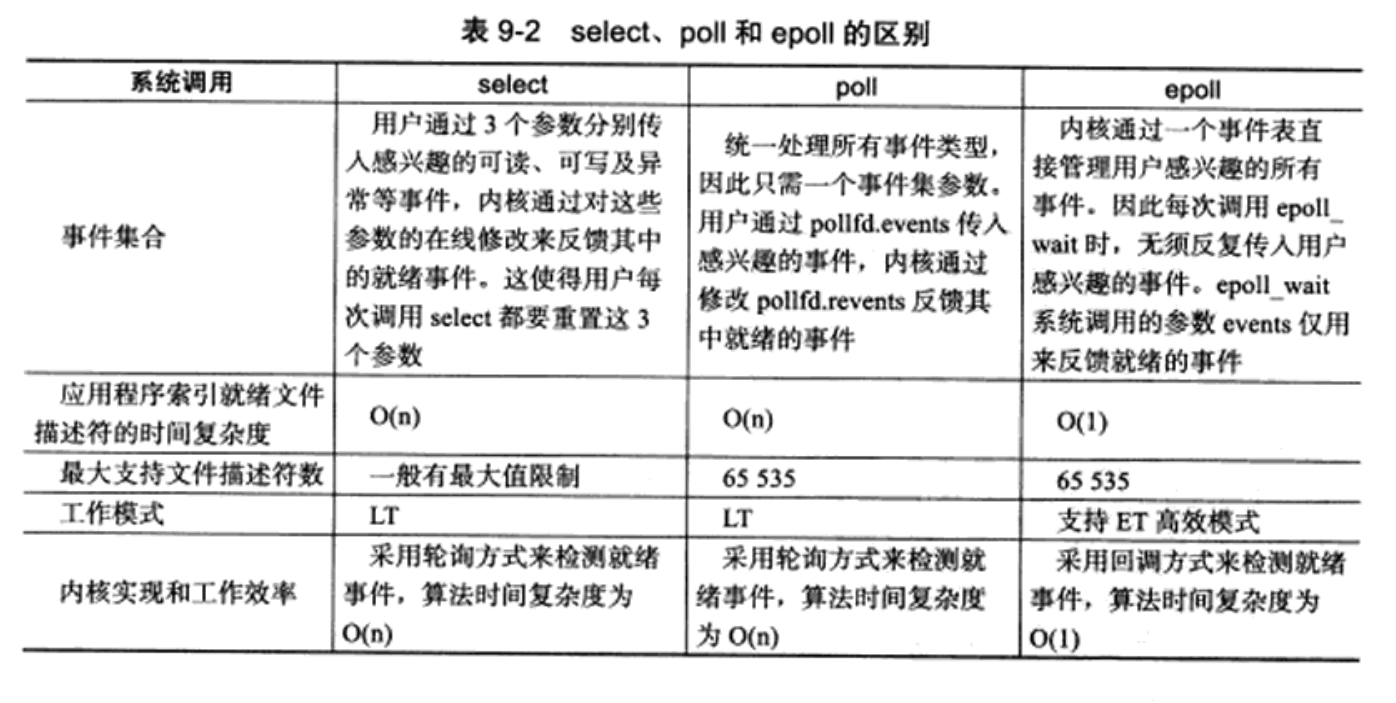
- 多路复用的应用: 总结就是监听各种文件描述符号发生的事件,不仅仅限制于网络套接字,比如:
- 非阻塞
connect的实现(可以参考P163面的原理) - 需要监听多路事件的情况
- 另外一种情况比如监听多路事件的超级服务:
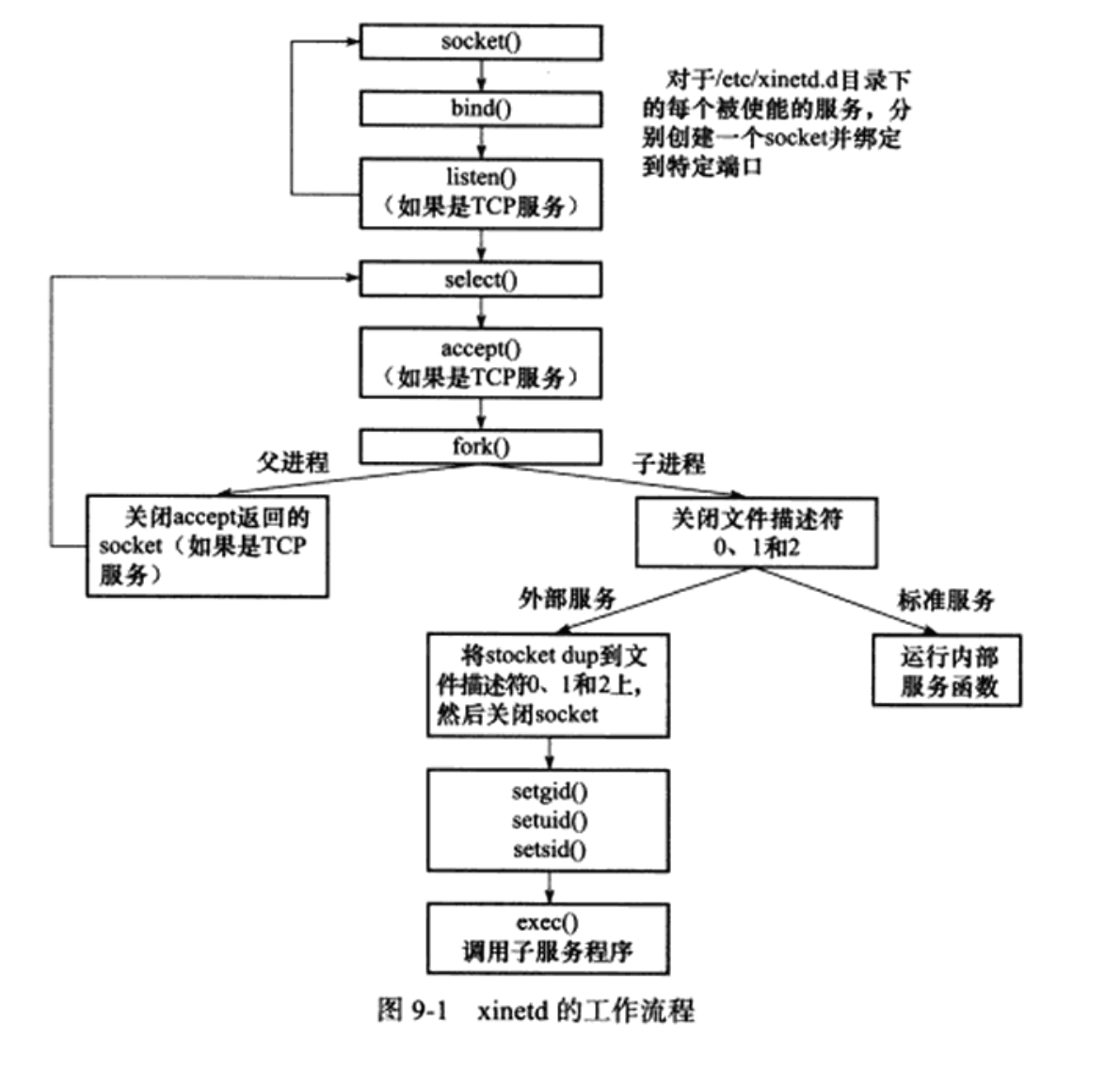
创建线程
- 也就是创建一个
thread对象,创建thread需要给这一个对象传递任务,并且需要传递任务的参数,对象创建完成之后就会开始执行任务了,实例程序如下:
/* 梦开始的地方: Hello Corrency! */
#include<iostream>
#include<thread>
void hello();
int main() {
std::thread t(hello);
t.join();
return 0;
}
void hello()
{
std::cout << "hello corrency world!" << std::endl;
}
当前环境支持并发线程数量
- 一般可以使用
std::thread::hardware_concurrency()可以获取到硬件支持的并发线程数量,是std::thread的静态成员函数 - 超线程技术: 一个核心上可以运行多个线程,可以并行完成更多任务
线程管理
启动线程
- 启动新线程, 利用
C++线程库启动线程就是构造std::thread对象,构造函数的参数是可调用对象以及相应的参数并且提供对应的移动构造函数:
thread t{ callable obj };
这里最好使用初始化列表声明,如果利用小括号声明可能使得语句被识别为函数的声明比如:
thread t{ Task() }
- 启动线程之后必须在线程对象的声明周期结束之前,也就是
thread::~thread调用之前,决定它的执行策略,是join还是detach,但是前提是线程对象是joinable的 - 执行策略为
detach的时候注意线程中使用的变量在其所在的函数退出的时候会被销毁造成指针悬空的问题 - 另外对于线程的异常处理,一定需要保证不要使得线程对象调用两次
join或者detach否则就会报错,正确的处理方法如下:
void f(){
int n = 0;
std::thread t{ func{n},10 };
try{
// todo.. 一些当前线程可能抛出异常的代码
f2();
t.join(); // try 最后一行调用 join()
}
catch (...){
t.join(); // 如果抛出异常,就在 这里调用 join()
}
}
RAII管理线程
RAII(资源获取即初始化): 构造函数申请资源,析构函数释放资源,让对象的生命周期和资源绑定,函数执行结束或者异常抛出的时候C++会自定调用对象的分析构函数,利用RAII管理的一般叫做XXX_guard对象,比如thread_guard的是实现方法如下:
class thread_guard{
std::thread& m_t;
public:
explicit thread_guard(std::thread& t) :m_t{ t } {}
~thread_guard(){
std::puts("析构"); // 打印日志 不用在乎
if (m_t.joinable()) { // 线程对象当前关联了活跃线程
m_t.join();
}
}
thread_guard(const thread_guard&) = delete;
thread_guard& operator=(const thread_guard&) = delete;
};
void f(){
int n = 0;
std::thread t{ func{n},10 };
thread_guard g(t);
f2(); // 可能抛出异常
}
参数的传递
- 向可调用对象传递参数,这些参数作为:
std::thread的构造参数即可,注意这些参数会赋值到新线程的内存空间中,即使函数中的参数是引用,实际依然是复制 ,所以如果需要传递引用可以使用标准库中的std::ref和std::cref,底层原理如下: https://blog.csdn.net/haokan123456789/article/details/138747950 - 传递值: 直接把参数放在
std::thread的构造函数中即可 - 传递引用: 使用
std::ref或者std::cref即可(注意如果函数需要传递引用,但是直接传递值的情况下,由于参数副本转换为右值表达时进行传递,但是左值表达时没有办法引用右值表达时,所以会产生编译错误)
void f(int, int& a) {
std::cout << &a << '\n';
}
int main() {
int n = 1;
std::cout << &n << '\n';
std::thread t { f, 3, std::ref(n) };
t.join();
}
- 利用成员函数指针作为调用对象,需要写成
&类名::非静态成员的形式,并且第一个参数需要传递&类对象(参考C++对象模型) , 甚至可以成员变量当成成员函数使用,可调用函数的类型为:function<类型&(void)>类型(这是std::function和std::bind) 的内容 - 传递只可以移动的对象可以使用
std::move - 同时创建
std::thread对象的函数可以和std::bind一起使用,比如::
std::thread t{ std::bind(&X::task_run,&x,std::ref(n)) };
- 同时注意如果传入的指针对象,那么一定需要注意如果在
f(参数)调用之前指向的对象已经被销毁了,那么此时就会造成悬空指针,从而出错,比如如下情况:
void f(const std::string&);
void test(){
char buffer[1024]{};
//todo.. code
std::thread t{ f,buffer };
t.detach();
}
解决方法: 使用join() ,或者提前把buffer 转换为 string 类型,比如string(buffer)
std::this_thread
std::this_thread命名空间中包含如下函数:yield: 建议实现重新调度各执行线程get_id: 返回当前线程id(提供一个线程的标识符号)sleep_for: 使当前线程停止执行指定时间sleep_until: 使当前线程执行停止到指定的时间点
yield的使用方法如下,使得线程在busy-loop的情况下交出CPU:
while(!isDone) {
std::this_thread::yield();
}
std::thread 转移所有权
thread对象是一种move-only的对象,只可以使用移动构造函数或者移动运算符号进行资源的转移,同时利用这一个特性,可以把函数返回的thread对象利用起来构建新的thread对象
std::thread f(){
std::thread t{ [] {} };
return t;
}
int main(){
std::thread rt = f();
rt.join();
}
C++20 的 std::jthread
-
std::jthread中相比于C++11中引入的std::thread,只是多了两个功能:RAII管理: 在析构的时候自动调用join()- 线程停止功能: 线程的取消/停止
-
提供了停止线程的方法,主要是提供了两种类型:
td::stop_source:这是一个可以发出停止请求的类型。当你调用stop_source的request_stop()方法时,它会设置内部的停止状态为“已请求停止”。 任何持有与这个stop_source关联的std::stop_token对象都能检查到这个停止请求。std::stop_token: 这是一个可以检查停止请求的类型。线程内部可以定期检查stop_token是否收到了停止请求。 通过调用stop_token.stop_requested(),线程可以检测到停止状态是否已被设置为“已请求停止”。
-
同时
std::jthread中提供三个成员函数进行线程停止:get_stop_source:返回与jthread对象关联的std::stop_source,允许从外部请求线程停止。get_stop_token:返回与jthread对象停止状态关联的std::stop_token,允许检查是否有停止请求。request_stop:请求线程停止。
主要解决多个线程在操作同一份共享数据时产生的线程安全问题
当某个表达式的求值写入某个内存位置,而另一求值读或修改同一内存位置时,称这些表达式冲突。拥有两个冲突的求值的程序就有数据竞争,除非
- 两个求值都在同一线程上,或者在同一信号处理函数中执行,或
- 两个冲突的求值都是原子操作(见
std::atomic),或 - 一个冲突的求值发生早于 另一个(见
std::memory_order) 下面介绍解决竞争导致的线程安全问题的方法
使用互斥量
std::mutex
std::mutex为互斥锁,可以用于保护共享数据,解决线程安全问题,使用举例如下:
#include<iostream>
#include<thread>
#include<mutex>
#include<vector>
using namespace std;
mutex m;
int main() {
auto f = [](int i) {
m.lock();
cout << "thread: " << this_thread::get_id() << " get: " << i << endl;
m.unlock();
};
vector<thread> threads;
for(int i = 0 ; i < 10 ; i ++) {
threads.emplace_back(f , i);
}
for(auto& t : threads) {
if(t.joinable()) {
t.join();
}
}
}
std::lock_guard
- 使用了
RAII思想,把互斥锁的解锁和对象的析构函数联系起来了 - 拥有两个构造函数:
explicit lock_guard(_Mutex& _Mtx) : _MyMutex(_Mtx) {
_MyMutex.lock();
}
lock_guard(_Mutex& _Mtx, adopt_lock_t) noexcept: _MyMutex(_Mtx) {} // construct but don't lock
- 上面一个构造函数在管理互斥锁之后会上锁,如果原来的互斥锁上锁了,就会形成死锁,后面一个需要提前上锁,离开
lock_guard作用域之后解锁
记录git中的常用命令和一些情况的解决方案
git branch
- 查看所有分支:
git branch -a
- 查看远程分支:
git branch -r
- 设置上游分支:
git branch --set-upstream-to=origin/feature-branch
- 删除分支,或者删除已经合并的分支:
git branch -D <branch-name> // 删除已经合并的分支
git branch -d <branch-name> // 强制删除分支
- 重命名分支:
git branch -m <new-branch-name>
- 重新设置上游分支:
git branch --unset-upstream
git branch -u origin/<new-branch-name>
git checkout
- 创建并且切换分支:
git checkout -b new-branch
git checkout -b feature-branch origin/feature-branch # 拉取远程分支,并且创建本地分支
git push
- 创建远程分支并且
push:
git push -u branch-name origin/branch-name
- 删除远程分支:
git push --delete <branch-name>
git stash
- 首先需要提交
git stash
- 重新恢复修改
git stash pop
git log和git reflog
- 查询没有删除的分支的提交:(结合
git reset --hard) 使用
git log
- 查询已经删除的分支的提交:(结合
git cherry-pick) 使用
git reflog
git cherry-pick
- 挑选特定的提交融合到本地分支(不会融合整个分支,只会融合特定的代码):
git cherry-pick <commit-hash>
git show
- 展示某一次提交的代码:
git show <commit-hash>
git merge
记录
p1: 切换到新的分支提交之后,切换到原来的分支并且删除之前的分支导致代码丢失
- 解决方法如下:
git reflog # 查看已经删除的分支的提交
git show <commit-hash> # 查看已经提交的代码
git cherry-pick <commit-hash> # 融合到本地分支
p2: 如何合并本地分支到远程分支(比如test)
- 合并的方法如下:
git checkout feat/ill_back
git fetch origin test
git merge origin master
git push origin feat/ill_back:test
Nginx的使用方式,参考: https://github.com/dunwu/nginx-tutorial
nginx基本命令
Nginx中的基本指令如下:
nginx -s stop 快速关闭Nginx,可能不保存相关信息,并迅速终止web服务。
nginx -s quit 平稳关闭Nginx,保存相关信息,有安排的结束web服务。
nginx -s reload 因改变了Nginx相关配置,需要重新加载配置而重载。
nginx -s reopen 重新打开日志文件。
nginx -c filename 为 Nginx 指定一个配置文件,来代替缺省的。
nginx -t 不运行,仅仅测试配置文件。nginx 将检查配置文件的语法的正确性,并尝试打开配置文件中所引用到的文件。
nginx -v 显示 nginx 的版本。
nginx -V 显示 nginx 的版本,编译器版本和配置参数。
注意入上的 reload 命令可以重新加载配置文件不需要每一次都重启 nginx服务器
nginx实战
设置 Http 反向代理
- 反向代理: 把外界的请求转发给内部网络的服务器同时又可以把请求返回给外界
conf/nginx.conf是默认的配置文件,当然也可以在conf.d/default.conf中写一部分内容
vimtutor
移动光标
h-> 左j-> 下k-> 上l-> 右
删除
- 指定的位置键入
x即可删除对应位置的字符
插入
i: 进入插入模式,在指定的字符前面插入内容A:在文章末尾插入元素o:在光标所在的一行的下行开启一个新行进入插入模式O: 在光标所在的上一行开启一个新行并且进入插入模式a: 在当前光标的后面插入R: 进入替换模式,可以把当前位置的字符进行替换
删除类命令
- 在指定的单词的首部键入
dw即可删除这一个单词,光标跳转到下一个字母的首部 d$从键入位置删除到行首部
更改类命令
- 在需要修改的位置的首字母的位置键入
ce,输入修改之后的值,即可完成修改 (注意进入了插入模式) c [number] motion比如c 4 w表示从当前位置开始向后面修改四个单词,c $表示修改到行末尾- 剪切操作可以使用
p使得删除的内容出现在光标的后面
定位和文件状态
- 在某一行键入
CTRL + G(长按ctrl,之后按g) 就会显示当前文件的状态以及所在的行号,之后可以进行任意的跳转,想要回到原来的位置只需要键入原来的行号并且按下G即可 G表示到文件末尾gg表示到文件开头
搜索类命令
/需要搜索的单词按下回车之后就可以进行搜索了,n表示搜索下一个,N表示搜索上一个?需要搜索的单词表示反向搜索ctrl + o回退到原来的位置,ctrl + I撤销回退:set hs可以高亮:set ic可以忽略大小写:set noic可以取消大小写
括号匹配
- 在括号的位置或者括号里面内容的位置键入:
%即可找到相匹配的括号位置
修改匹配字符串
- 修改方式:
/s/old/new对于某一个行,把这一行中的第一个old修改为new/s/old/new/g对于某一行,把这一行中的所有的old修改为new#,#/s/old/new/(g)表示修改两行之间的内容中的old为new%s/old/new/(g)对于整个文件中的所有内容进行匹配
执行外部命令
:!即可执行外部命令了,注意所有的:都必须使用回车结尾- 比如
:!rm TEST可以执行删除命令
保存文件
:w 文件名可以使用特定的文件名保留文件- 可以按住
v进入可视模式,之后选择一段文字,按下:,之后键入保存文件的命令(比如w TEST)即可把这一段文字保存为指定的文件
合并文件
:r 文件或者其他可以输入标准输出的东西就可以把之后显示的内容输出到当前光标的下一行
动作与数字结合
- 动作(
operator): 也就是复制删除等动作,比如y,dd等操作 - 移动(
motion): 移动比如利用h j k l进行移动 - 动作数字和移动可以结合,比如:
dw表示删除一个单词de表示删除到单词末尾d$表示删除到行末尾d2w表示删除两个单词
- 注意动作在移动之前
- 但是特殊字符比如
$等在移动动作之后(比如``)
撤销
- 撤销移动:
ctrl + o恢复到原来的位置:ctrl + I - 撤销上一步的修改:
u, 撤销整行的修改:U
操作符号
dd: 表示删除y: 表示复制p: 表示粘贴d + p可以完成剪切操作
帮助文档
:help即可- 自动补全功能:
CRTL + D
备忘录
跳转到函数定义处
ctrl + ]即可跳转到函数的定义处,同时利用crtl + o就可以回退了
基础部分
窗口,缓冲区,标签
- 每一个文本都是缓冲区的一个部分,都是在特有的缓冲区打开的
- 窗口是缓冲区上一层的视窗,查看文件的不同位置就需要窗口
- 标签就是窗口的集合,需要不同的窗口布局就需要使用标签
:vsplit表示水平分割屏幕,:diffsplit表示垂直分割屏幕crtl + w p j k l分别表示上下,下,上,右移动,左可以使用p(表示跳转)crlt + W c关闭当前窗口ctrl + W q关闭当前窗口:only仅仅保留当前分屏:hide关闭当前分屏
缓冲区的状态
- 利用
vim file命令启动vim,会使得文件的内容加载道缓冲区中,如果有一个已经载入的缓冲区,可以在vim中保存文件 - 如果键入
:e file2就会使得file2加入缓冲区,但是file1变成隐藏的缓冲区 :ls可以列出所有缓冲区,:ls!可以显示被放入缓冲区列表和没有放入列表的缓冲区,未命名的缓冲区是一种没有关联特定文件的缓冲区,可以使用:enew创建,添加一些文本可以保存着一个缓冲区中的内容:w /temp/foo
按键映射
- 可以使用
:map命令定义自己的快捷键,映射可以是递归的也可以是非递归的,递归的映射表示一个键完全替代了应外一个键,需要执行另外一个键的其他功能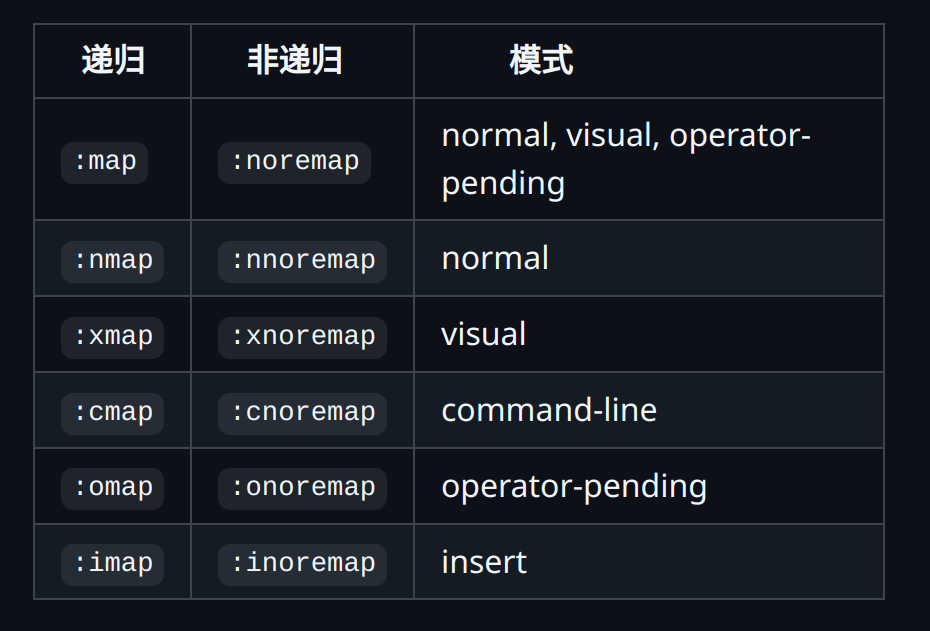
- 除非递归映射是必须的,一般都会使用非递归映射
- 映射前置键:
Leader是一个按键映射,默认为\
B 站Vim 教程补充
移动命令
{lineno}gg: 表示跳转到第lineno行Ctrl + u / Ctrl + b向上翻页Ctrl + d / Ctrl + f向下翻页zz/zt/zb: 光标位置设置为页中/页第一行/页最后一行
插入命令
s: 删除当前单词进入插入模式S: 删除当前行进入插入模式A: 在行末尾插入
移动命令补充
基于单词移动
e: 移动到下一个单词的末尾ge: 移动到上一个单词的末尾
基于搜索的移动
f{char}/t{char}跳转到下一个char字符出现的前面和后面;/,: 表示跳转到下一个ft搜索的位置,或者上一个F{char}/T{char}向前面搜索*类似于/{pattern}但是就是搜索光标下的单词
基于标记的搜索
m{mark}设置标记,比如mm撇号{mark}跳转到mark的位置- 内置标记:
撇号撇号: 跳转到上一个跳转的位置撇号.: 跳转到上一个修改的位置撇号.^: 跳转到上一个插入的位置
组合命令
Operator + Motion = Action
- 比如操作命令和移动命令可以同时使用,比如:
dwyw
- 同时操作命令重复表示作用于一行,比如:
yydd
{count}Action
- 利用
Action前面加上数量就可以实现多次操作,比如:3dw2yw
编辑命令
撤销命令
.: 重复上一次修改u: 撤销上一个修改Ctrl + r: 重新进行上一次修改
相对行号
:set relativenumber开启:set norelativenumber关闭
补充编辑命令
gu/gU/g~大小写转换和反转J连接上下两行Ctrl + x / Ctrl - a + number: 数字的增减可视模式 g Ctrl - a: 生成递增序列,非常好用(可以用于编辑行号)</>: 缩近
文本对象操作
文本对象就是一个文本片段 {textobj},表示方式如下:
i: 表示内部,不包含匹配符号a: 表示包含匹配符号 文本对象的类型如下:w单词 ,s句子 ,p段落(),[],{}匹配符 文本对象的构成方法:i / a+ 文本对象类型,比如iw , aw等 文本对象操作:{operator}{textobj}表示把操作放在文本对象上,比如:yi(diw注意,如果不清楚{textobj}的位置,利用可视觉模式v{textobj}看是否是自己需要的位置即可
寄存器与宏定义
寄存器用于保存各种操作,可以利用 :reg {register} 查看寄存器中的内容
寄存器 + Operator
- 利用
"{register}{Action}操作可以把操作的值放入到寄存器中,或者从寄存器中取值,比如:"add: 表示删除本行放在a中"ap: 表示把a中的内容粘贴到这一个位置来
- 默认寄存器如下:
": 默认寄存器%: 文件名称.: 上一次插入的内容:: 上一次执行的命令
宏定义(非常好用)
利用 q{register} 开始链录制宏,之后执行一系列普遍的的操作,利用 q 结束录制,之后利用 @{register} 就可以防止宏定义,同时 @@ 表示放置上一次放置的宏定义
同时可以考虑在宏定义中加入移动命令,从而使用 {count}@{register} 连续方式宏定义
命令模式
命令基本格式
Ex命令: :[range] {excommand} [args] 范围 + 命令 + 参数,默认操作行,同时也可以使用 [x] 作为寄存器:
- 比如
print,delete [x]
address 组合成为 range
1,3表示文件的1 - 3行. , .+4当前,当前向下四行 ,.表示当前行,注意包含当前行$-3,$: 最后四行,$表示最后一行%表示所有行< / >表示可视模式下选中范围的开头和结尾
行的复制移动和粘贴
:[range] copy {address}把range的内容复制到address后面:[range] move {address}把range中的内容移动到address后面:[address] pux [x]把x的内容粘贴到address后面0是虚拟的位置
批量操作 normal 命令
- 规则:
:[range] normal {commands}对于范围里面的行执行命令 - 技巧:
:range normal .执行上一次命令效果拔群:range normal @{register}可以结合宏定义来做
批量操作 global 命令
- 规则:
:[range] global/{pattern}/[cmd]可以对于包含pattern的行执行命令,注意normal命令也可以,比如可以使用:[range] global/{pattern}/normal {command},同时比如:% global/TODO/delete可以删除所有带有TODO的行
替换命令
:[range] s/{pattern}/{string}/[flags]把pattern替换为stringflags:g: 替换每一行的所有匹配位置i: 忽略大小写c: 替换前进行确认n: 计数而不是替换
- 比如:
%s/vim//gn
neovim配置以及基本使用(基于 LazyVim框架)
- 首先
LazyVim相关的配置文件结构如下:
├── init.lua
├── lazy-lock.json
├── lazyvim.json
├── LICENSE
├── lua
│ ├── config
│ │ ├── autocmds.lua
│ │ ├── keymaps.lua
│ │ ├── lazy.lua
│ │ └── options.lua
│ └── plugins
│ └── example.lua
├── README.md
└── stylua.toml
- 其中
init.lua用于加载各种插件的配置文件 lua/config中记录着各种配置:keymaps: 表示配置键位options: 表示配置编辑选项,比如是否开启相对行号
plugins用于安装各种插件,比如需要安装一个插件就可以在这一个文件夹下新建一个文件并且填入配置信息即可,同时也可以新建一个disable.lua来记录插件启用情况
LazyVim 基本使用技巧
参考: https://www.lazyvim.org/keymaps
快捷键和命令的设置
- 配置文件目录结构如下:
├── init.lua
├── lazy-lock.json
├── lazyvim.json
├── LICENSE
├── lua
│ ├── config
│ │ ├── autocmds.lua
│ │ ├── keymaps.lua
│ │ ├── lazy.lua
│ │ └── options.lua
│ └── plugins
│ └── example.lua
├── README.md
└── stylua.toml
- 修改键位: 修改
lua/config/keymaps.lua即可 - 修改选项: 修改
lua/config/options.lua即可
安装插件
- 一般来说,
LazyExtra中的额外插件就够使用了,所以可以使用:LazyExtra命令来安装额外插件 - 另外安装第三方插件需要在
lua/plugins文件夹下建立*.lua文件并且按照LazyVim要求的方式配置(还需要实践)
常用快捷键
Ctrl + h , j , k , l: 移动到上下左右的窗口位置Ctrl + left , right , up , down: 增大/减小窗口的长度或者宽度的大小Alt + j , k: 在任何模式下上下移动行/代码块Shift + h , l: 左右移动到旁边的标签页<leader>bd: 删除缓冲区<leader>bD: 删除缓冲区和窗口<leader>bo: 删除其他缓冲区<leader>ur: 清除高亮标记Ctrl + s: 保存文件<leader>K: 比如可以显示系统调用的文档,或者标准 C 库的文档gco , gcO: 在上面或者下面添加注释<leader>l: 启动插件管理栏- 各种
Toggle命令比较有意思,可以参考 文档,比如 <leader>ub: 切换背景<leader>uL: 切换相对行号的显示<leader>gb: 显示当前文件提交信息<leader>ft: 调出终端<leader>-: 在下面分割出来屏幕<leader>|: 子右边分割出来屏幕<leader>wd: (Windows Delete) 删除窗口<leader>uf: 是否取消保存时候自动不全[e , ]e: 进行错误的跳转
代码跳转
- 利用
ctags工具生成跳转标签,利用ctrl + [跳转到函数的实现位置 - 如果写对了头文件的路径就可以使用
gd可以进行实现找到定义,定义找到实现
LSP
- 可以使用
<leader>cl进入到LSP管理界面,或者使用:Mason也可以,找到需要的语言的LSP即可
buffer
<leader>bl删除左边的缓冲区<leader>bp是否钉住缓冲区<leader>bP删除没钉住的缓冲区<leader>br删除右边的缓冲区
fzf(很好用的搜索插件)
<leader><space>: 查找文件<leader>/类似于Grep查找关键词<leader>:命令历史<leader>fb: 查找缓冲区<leader>fc: 寻找配置文件<leader>ff: 和第一个一样<leader>fF: 工作目录查找,还是类似<leader>fg: 查找git文件<leader>fr: 查找最近的文件<leader>gc: 查看提交<leader>gs: 查看状态<leader>sg: 类似于上面的Grep,只不过是全局的<leader>sG: 当前工作目录寻找<leader>ss: 查找本文件中的符号,比如函数等<leader>sS: 查找工作空间中的类函数等<leader>sw: 还是和sg一样的<leader>uC: 切换主题,挺好玩的
grug-far(感觉比较好用)
<leader>sr匹配搜索到的单词
Mason
<leader>cm: 用于开启Mason,安装各种语言的自动提示
neo-tree
<leader> be打开当前文件夹<leader>e打开/关闭文件夹<leader>fe一样<leader>ge打开Git文件夹(没有追踪的)
noice(不知道有什么用)
<c-b>向后面滚动<c-f>向前面滚动<leader>sn添加注意事项
CopilotChat
<leader> aa打开聊天框<leader> ap指定行为感觉没用<leader> aq快速提问<leader> ax清除屏幕
可以参考: Mysql数据库基础篇
查询方式
- 无论对于那一种多表关系,都可以使用
inner join,left join,right join的方式对于多表中的关联数据进行查询,同时可以配合不同的条件对于各种情况进行查询,可以得到A,B之间的差集,交集,并集等(可以使用union关键字)
一对一关系
- 建表语句如下:
create table sin_a (
aid int primary key auto_increment,
name varchar(20) not null,
age int not null
) comment "tablea";
create table sin_b (
bid int primary key auto_increment,
password varchar(30) not null,
birthday date
) comment 'tableb';
alter table sin_b add a_id int;
-- 添加外键盘约束
alter table sin_b add constraint fore_a_id foreign key (a_id) references sin_a(aid);
-- 开始添加数据
insert into sin_a values (null , 'jim' , 12),(null,'bob',20),(null,'judy',30);
insert into sin_b values (null , '12345' , '2005-10-16' , 1), (null , '23456' , '2007-10-14' , 2) , (null , '3333' , '2008-10-12' , 3);
- 查询方式(分别利用
inner join,left join,right join进行查询)
-- inner join
select a.* , b.* from sin_a a inner join sin_b b on a.aid = b.a_id;
-- left join
select a.* , b.* from sin_a a left join sin_b b on a.aid = b.a_id;
-- right join
select a.* , b.* from sin_a a right join sin_b b on a.aid = b.a_id;
一对多关系
- 建表语句如下:
create table many_a (
aid int primary key auto_increment,
name varchar(20) not null,
age int not null
) comment 'one to many one';
create table many_b (
bid int primary key auto_increment,
classname varchar(20) not null,
a_id int,
foreign key (a_id) references many_a(aid)
) comment 'one to many many';
-- 添加数据
insert into many_a values (null , '张三' , 20) , (null , '李四' , 21) , (null , '王五' , 25);
insert into many_b values (null , '高等数学' , 1),(null,'电路理论',1),(null,'模拟电路',2),(null,'数字电路',2),(null,'操作系统',3),(null,'计算机网络' , 3);
- 查询语句:
-- 开始查询
-- inner join
select a.* , b.* from many_a a inner join many_b b on a.aid = b.a_id where a.name = '张三';
-- left join
select a.* , b.* from many_a a left join many_b b on a.aid = b.a_id where a.name = '李四';
-- right join
select a.* , b.* from many_a a right join many_b b on a.aid = b.a_id where a.name = '王五';
多对多关系
- 建表语句:
-- 多对多关系
-- 建立数据库表
create table mm_a (
aid int primary key auto_increment,
name varchar(30) not null,
age int not null
) comment 'many to many mm_a';
create table mm_b (
bid int primary key auto_increment,
classname varchar(30) not null
);
create table many2many (
cid int primary key auto_increment,
a_id int,
b_id int,
foreign key (a_id) references mm_a(aid),
foreign key (b_id) references mm_b(bid)
) comment '中间表';
insert into mm_a values (null , 'z1' , 10) , (null , 'z2' , 20) , (null , 'z3' , 30) , (null , 'z4' , 40) , (null , 'z5' , 50);
insert into mm_b values (null , 'c1') , (null , 'c2') , (null , 'c3') , (null , 'c4') , (null , 'c5') , (null , 'c6');
insert into many2many values (null , 1 , 2) , (null , 1 , 3) , (null , 2 , 5) , (null , 2 , 6) , (null , 3 , 3 ) , (null , 3 , 4) , (null , 4 , 4) , (null , 4 , 6) , (null , 5 , 5);
- 查询语句
-- 利用 inner join,看成了两个一对多
select a.*,b.* from mm_a a inner join many2many c on a.aid = c.a_id inner join mm_b b on b.bid = c.b_id;
-- 利用 left join
select a.*,b.* from mm_a a left join many2many c on c.a_id = a.aid left join mm_b b on c.b_id = b.bid;
-- 利用 right
select a.*,b.* from mm_a a right join many2many c on c.a_id = a.aid right join mm_b b on c.b_id = b.bid;
- 最后注意在删除或者更新数据的时候,关联这一个数据库表的数据库表的更新或者删除行为由外键约束规定,默认是
NO ACTION,当然可以改变,比如:
alter table table_name add constraint fore_key_name foreign key(外键字段) reference main_table(main_column) on update cascade on delete resirict
mysql的启动
- 命令行输入
services.msc - 命令行输入
net start mysql 80启动数据库,输入net stop mysql80关闭数据库 - 利用
docker进行部署:
sudo docker run --name mysql-test -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
mysql的客户端连接
- 直接利用客户端软件连接
- 命令行输入
mysql [ -h 服务器的IP地址] [-P 3306] -u root -p
SQL-DDL数据库操作语句
查询
- 查询所有数据库
show databases - 查询当前数据库
select database()
创建数据库
createa database [ if not exists ] 数据库名称 [ default charest 字符集] [collect 排序规则 ]
删除数据库
drop databases [ if exists ] 数据库名称
使用/切换数据库
use 数据库名称
对数据库中的表进行操作
查询数据库中的所有表结构
show tables
查询表的结构
1. desc 表名
查询指定的建表语句
create table 表名 (
字段1 字段1类型 [comment 字段1注释],
字段2 字段2类型 [comment 字段2注释],
字段3 字段3类型 [comment 字段3注释],
字段4 字段4类型 [comment 字段4注释],
... ...
) [comment 表注释]
DDL- 表操作中的数据类型
- 数值型: 常用的就是 int,其他的还有int的各种变式(tinyint,smallint,mediumint等),还有浮点数类型(float,double,decimal)
- 字符串类型: 常用的char和varchar(),但是注意都要指定长度(char(10)),另外还有blob二进制文本(应该可以用于存储图片),还有text(文本数据,应该可以存储简历等信息)
- 日期类型: 常用的就是Date(只表示年月日),time(只表示时分秒),datatime(都可以表示),timestamp(表示混合日期和时间戳)
DDL-表操作-修改表中数据
添加字段
alter table 表名 add 字段名 字段类型 [ comment 字段注释]
修改字段类型
alter table 表名 modify 字段名称 新数据类型(长度)
修改字段名和类型
alter table 表名 change 旧字段名称 新字段名称 类型(长度) [ comment 字段注释 ]
删除字段
+ alter table 表名 drop 字段名称
修改表名称
alter table 表名 rename to 新的表名<font style="background-color:#E7E9E8;"></font>
删除表
drop table [ if exists ] 表名 (其实就是完全删除表)truncate table 表名 (删除指定表并且重新创建该表,其实就是清空数据)
SQL-DML数据操作语句
添加数据(insert into 关键字和 values 关键字的使用)
给指定字段添加数据
- insert into 表名 (字段1,字段2,字段3 ... ...) values (值1,值2,值3 ... ... ) (其实就是变量的初始化)
给表中全部字段添加数据
- insert into 表名 values (值1,值2 ... ....)
批量添加数据
- insert into 表名 (字段名1,字段名2 ... ...) values (值1,值2 ... .... ) (值1,值2 ... ...) .... ...
- insert into 表名 values (值1,值2 ... ...) (值1,值2 ... ...)
注意事项简述:
字符串类型和日期类型在单引号中间
修改数据(update 关键字和 set关键字的使用)
修改数据
- update 表名 set 字段名1= 值1字段名2= 值2 ... ... [where 条件判断]
注意事项:
- 后面的条件没有表示修改所有数据,要修改特定的数据必须带上条件
删除数据(delete from 关键字的使用)
- delete from 表名 where 条件
注意事项
- delete相当于删除某一个数据(其实就是一行数据,但是不可以删除某一个字段的值,where条件不写表示删除所有的值
SQL-DQL数据库查询语句基础
:::warning
- 使用数据库查询语句其实就是对于关键字select的使用
- DQL中使用的语法结构(各种关键字)如下:
:::
select 字段列表
from 表名列表
where 条件列表
group by 分组字段列表
having 分组之后条件列表
order by 排序字段列表
limit 分页参数
基础查询
查询多个字段
- select 字段名1,字段名2,字段名3 ... from 表名
- select * from 表名
设置别名
- select 字段名1 [as 别名] ,字段名2 [as 别名] ... ... from 表名
去除重复记录
- select distinct 字段列表 from 表名
条件查询
- select 字段名1,字段名2 ...... from 表名 where 条件
条件种类的总结如下
- 常见的比较运算符号: 除了常用的 大于小于等,比较重要的还有 between ... and ... (最大值和最小值之间) in (列表) 在in后面的列表中选择一个 like 占位符号(非常重要,其实是模糊匹配,_匹配单个字符,%匹配多个字符),isnull 表示为null
- 逻辑运算符号:都知道的
聚合函数
- 作用: 把一列数据作为一个整体,进行纵向计算
- 常见的聚合函数如下
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
- 语法:select 聚合函数(字段 列表) from 表名 [ where 条件]
分组查询
语法
- select 字段列表 from 表名 [ where 条件] group by 分组字段名称 [ having 分组之后的过滤条件]
作用
- 一般是统计不同类别的人的一个情况,比如不同性别的人的人数 ,不同性别人的年龄的平均值
where 和 having的区别
- 执行时机不同: where是分组之后进行过滤,不满足where条件就不可参加分组,但是having在分组执行之后进行的
- 判断条件不同,where不可以对聚合函数进行操作,但是having可以
排序查询
语法
- select 字段列表 from 表名 order by 字段 排序方式1,字段2 排序方式2(可以进行多字段排序)
排序方式
- asc 升序(默认)
- desc 降序
注意事项
- 多字段排序时,只有当第一个字段相同时,才会根据第二个字段排序
分页查询
-
语法
- SELECT 字段列表 FROM 表名 LIMIT 起始索引,查询记录数;
-
注意:
- 起始索引从0开始,起始索引=(查询页码-1)*每页显示记录数
- 分页查询是数据库的方言,不同数据库实现不同,mysql中是LIMIT
- 如果查询的是第一页数据,起始索引可以省略,直接简写为limit 10;(与数组相同)
select * from employee limit 10;
select * from employee limit 10 ,10;
- 实例
select * from employee where age between 20 and 23;
select * from employee where age between 20 and 40 && name like '___' && gender='男'; -- ___就是匹配字符的符号
select gender ,count(*) from employee where age<60 group by gender; -- 注意逗号分割
select name,age,entrydate from employee where age<=35 order by age ,entrydate desc;
select * from employee where gender='男' && age between 20 and 40 order by age,entrydate limit 5;
DQL语句的执行顺序
- 上面的是编写顺序
- DQL语句的执行顺序 1. from 2. where 3. group by 4. having 5. select 6. order by 7. limit
DCL语言
-
用于管理数据库用户,控制数据库的访问权限
-
管理用户的语法:
-
查询用户
- USE mysql;(访问系统数据库mysql,查询表结构user得到用户)
- SELECT * FROM user;
-
创建用户
- CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
-
修改用户密码:
- ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
-
删除用户:
- DROP USER '用户名'@'主机名';
-
-
注意事项
- 主机名可以利用% 匹配
- 这类SQL语句开发人员利用的少,主要是DBA(数据库管理人员)使用
权限控制
- 权限的种类
| 权限 | 说明 |
|---|---|
| ALL,ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除表/数据库/视图 |
| CREATE | 创建数据库/表 |
-
权限控制语句的语法
-
查询权限:
- SHOW GRANTS FOR '用户名'@'主机名';
-
授予权限
- GRANTS 权限列表 ON 数据库名.表名(可以使用通配符) TO '用户名'@'主机名';
-
撤销权限
- REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
-
函数
- 函数是指一段可以直接被另一端程序调用的程序或者代码
- 常用的字符串函数:
| 函数 | 功能 |
|---|---|
| CONCAT(S1,S2..Sn) | 字符串拼接,将s1,s2...sn拼接成一个字符串 |
| LOWER(str) | 把字符串str全部转为小写 |
| UPPER(str) | 把字符串str全部转为大写 |
| LPAD(str,n,pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| RPAD(str,n,pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str,start,len) | 返回字符串str从start位置起的len个长度的字符串 |
数值函数
- 常见的数值函数:
| 函数 | 功能 |
|---|---|
| CEIL(X) | 向上取整 |
| FLOOR(X) | 向下取整 |
| MOD(x,y) | 返回x/y的模 |
| RAND() | 返回0-1之间的随机数 |
| ROUND(x,y) | 求参数x的四舍五入值,保留y位小数 |
日期函数
- 常见的日期函数
| 函数 | 功能 |
|---|---|
| CURDATE() | 返回当前日期值 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| YEAR(date) | 获取指定date的年份 |
| MONTH(date) | 获取指定date的日期 |
| DAY(date) | 获取指定date的日期 |
| DATE_ADD(date,INTERVAL expr type) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| DATEDEFF(date1,date2) | 返回起始时间date1和结束时间date2之间的天数 |
流程控制函数
- 流程控制函数可以实现条件筛选,从而提高语句的效率
- 常见的流程函数
| 函数 | 功能 |
|---|---|
| IF(value,t,f) | 如果value为true,则返回t,否则返回f |
| IFNULL(value1,value2) | 如果value1不为空,返回value1,否则返回value2 |
| CASE WHEN[val1] THEN[res1] ...ELSE[default] END | 如果val1为true,返回res1,... 否则返回default默认值 |
| CASE [expr] WHEN[val1] THEN[res1]...ELSE[default] END | 如果expr的值等于val1,返回res1,... 否则返回default默认值(expr的值就是表达式) |
约束
- 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据
- 目的: 保证数据库中的数据的正确性,有效性和完整性
- 分类:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制字段的数据不能为null | NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一的,不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识(比如用于区分每一个数据的id和区分每一个人的身份证号),要求非空且唯一 | PRIMARY KEY(后面加上关键字AUTO_INCREMENT使得主键自动增长) |
| 默认约束 | 保存数据时,如果没有指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束 | 保证字段值满足某一个规则 | CHECK |
| 外键约束 | 用来让两张表之间建立联系,保证数据的一致性和完整性 | FOREIGN KEY |
约束的使用
create table user1(
id int primary key auto_increment comment '表中的主键,自动增长' ,
name varchar(10) not null unique comment '姓名,不为空并且唯一',
age int check(age>=0&&age<=120) comment '年龄',
status char(1) default 1 comment '状态,默认为1',
gender char(1) comment '性别'
) comment '用户表';
- 细节: 约束的建立在评论之前,可以利用图形化界面常见约束
外键约束
- 概念:外键用来让两张表的数据之间建立联系,从而保证数据的一致性和完整性
- 比如一张表之中的外键就是另外一张表中的主键取值,有外键的表称为子表,被关联主键的表被称为主表
- 语法格式:
CREATE TABLE 表名(
字段名 数据类型,
...
[CONSTRAINT][外键名称] FOREIGN KEY(外键字段名) REFERENCES 主表 (主表列表)
);
-- 添加字段时添加外键约束
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY(外键字段名) REFRENCES 主表(主表列名)
- 删除外键: ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
外键约束中的删除和更新行为
- 删除/更新行为
| 行为 | 说明 |
|---|---|
| NO ACTION | 当在父表中删除或者更新对应数据时,首先检查是否有对应外键,如果有对应外键就不允许删除或者更新(于RESIRICT一致) |
| RESIRICT | 同上 |
| CASCADE(cascade) | 当在父表中删除数据时,首先检查是否有对应外键,如果有,就也删除对应外键,更新就同步更新 |
| SET NULL | 当在父表中删除对应记录时,首先检查该记录是否有对应值,如果有则设置子表中该外键的值为null(这就要求外键允许取值为null) |
| SET DEFAULT | 父表中有变更时,子表将外键列设置成一个默认的值(Innodb不支持) |
- 使用以上行为的语法: ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名(主表字段名) ON UPDATE CASCADE ON DELETE RESIRICT;
多表查询
多表关系
- 项目开发中,在进行数据库表结构设计时,会根据业务需求以及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本分为三种: 一对多 多对多 一对一
- 一对多: 比如部门于员工之间的关系,一个部门不只有一个员工,一个员工归属于一个部门,实现: 在多的一方(员工)建立外键,指向的一方的主键
- 多对多: 比如学生与课程之间的关系,一个学生可以选择多个课程,每个课程可以有多个学生 实现方式: 建立第三张中间表,中间表中至少包含两个外键,分别关联两方主键(从而反应出两个表中数据之间的关系)

- 一对一的关系: 多用于单表拆分,将一张表的基础字段放在一张表中,其他字段放在另外一张表中,以提高操作效率 实现: 在任意一方加入外键(userid),关联另外一方的主键,并且设置外键为唯一的unique
多表查询
-
对于具有多表关系的两张表,利用原来的查询语句就可以这样写 select * from 子表,父表; 但是得到的结果会产生笛卡尔积的现象(就是在数学中,两个集合A和B集合的所有组合情况(多表查询中要消除无效的笛卡尔积)),利用where条件使得互相连接的键值相同就可以消除笛卡尔积
-
多表查询中的连接查询:
-
内连接: 相当于查询A,B交集部分的数据
-
外连接:
- 左外连接: 相当于查询左表中的所有数据,以及两表交集部分的数据
- 右外连接: 查询右表中的所有数据,以及两张表交集部分的数据
-
自连接: 当前表与自身的连接查询,自连接必须使用表别名
-
内连接
-
查询交集部分
-
查询语法:
- 隐式内连接: SELECT 字段列表 FROM 表1,表2 WHERE 条件...;(条件中一般时外键与主键之间的关系)
- 显式内连接: SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件(连接条件基本和上面一致)...;
外连接
-
查询语法(可以通过取别名的方式完成简化):
- 左外连接: SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件...;(注意相当于查询左表中的所有数据,包含两表中的交集数据)
- 右外连接: SELECT 字段列表 FROM 表1 RIGHT [ OUTER] JOIN 表2 ON 条件...;(查询右表中的数据)
-
代码实现:

自连接
- 自连接查询语法 SELECT 字段列表 FROM 表A 别名 表A 别名B ON 条件 ...;
- 自连接查询可以式内连接也可以是外连接
- 应用场景: 查询的数据都在一张表中,并且表中的某些字段有对应关系(就是一张表中的两个字段之间的关系为关联关系)
- 查询时,把这一张表看成两张表
联合查询
- 对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集
- 语法:
SELECT 字段列表 FROM 表A ...
UNION [ALL]
SELECT 字段列表 FROM 表B ...;
- 上面满足结果A,下面结果满足结果B(去掉all可以去重)
- 注意点: 对于联合查询,多张表的列数必须保持一致,字段类型也要一致 union all 会将全部的数据直接合并在一起,union 会对和合并之后的数据去重
子查询
-
概念: SQL语句中嵌套的SELECT语句,称为嵌套查询,又称为子查询
-
比如 SELECT * FROM t1 WHERE column1=(SELECT column1 FROM t2);
-
子查询外部的语句可以是: INSERT/UPDATE/DELETE/SELECT中的任意一个
-
根据子查询的结果不同可以分为:
- 标量子查询:子查询的结果返回一个值
- 标子查询: 子查询的结果是一列
- 行子查询: 子查询的结果是一行
- 表子查询: 子查询的结果为多行多列
-
根据子查询的位置可以分为: WHERE之后的,FROM之后的,SELECT之后的
标量子查询
- 返回的是单个值,最为简单
- 常用的运算符: 就是各种算数运算符号
- 引用场景: 就是要查询的数据要经过几步才可以查到的情况就可以考虑使用标量子查询
- 代码实现:

- 注意子查询中的代码要包裹在小括号里面(括号中的才叫子查询)
列子查询(其实子查询返回的就是列,可以时多列)
- 就是指子查询的结果返回的是列
- 常用的操作符:IN,NOT IN,ANY,SOME,ALL
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围中,多选一 |
| NOT IN | 不在指定的集合范围中 |
| ANY | 子查询返回列表中,有任意一个满足条件即可 |
| SOME | 与ANY等同,使用SOME的地方可以使用ANY |
| ALL | 子查询返回列表的所有值多必须满足 |
- 引用场景

行子查询(其实就是某一个数据,最后的格式就是 行=行)
- 行子查询中子查询的结果子查询返回的是一行数据
- 常用的操作符号: =,<>,IN,NOT IN;
- 代码实现

表子查询
- 子查询返回的结果是多行多列
- 常用的操作符: IN
- 就是把待查询字段组成一个列表,再在子查询得到的列表中查询(表子查询就相当于是多个行子查询的综合)
- 应用场景: 就是多个行子查询的综合,并且子查询查到的结果包含多个字段和多行,子查询的结果可以作为一张新的表,再次进行多表查询
- 代码实现:

刷题总结
- 对于多表查询,一定要清除每一个表的连接关系,搞清楚每一张表通过内连接外连接或者子查询得到的新表中的字段名和数据值是多少
- 对于select函数,多表查询得到的可能是一张表,或者一个数据,或者一列数据,一定要根据得到数据的不同做相应的处理,比如得到数字就用它比较大小,得到一列就用来求品均值,得到一行就用来比较多个字段中数据的大小,得到一张表就用来做多表查询或者分组查询
- 还是子查询结果的运用,注意子查询中的变量与外部还是有关系的,可以把外部变量中有的性质作为得到子表的一个条件,从而得到想要的数据
- 子查询出现的位置可以是任意的,要根据子查询得到的结果确定
事务
- 事务是一组操作的集合,是一个不可分割的单位,事务会把所有的操作作为一个整体一起向系统提交或者撤销操作请求,就是这些请求要么同时成功,要么同时失败(比如银行转账)
- 进行事物处理的过程: 首先处理事务之前要开启事务,之后进行回滚事务(就是进行相应的操作),操作完成之后再提交事务
- 默认mysql的事务是自动提交的,也就是说,当执行一条DML语句时,mysql会立即隐式的提交事务
事务的操作
-
查看/设置事务的提交
- SELECT @@autocommit;(查看事务提交的方式,如果是1的话就是自动提交,如果不是1的话就是非自动提交)
- SET @@autocommit=0;// 设置提交方式为自动提交
-
提交事务
- COMMIT;
-
回滚事务
- ROLLBACK;
-
代码实现:
- 方式1:

- 方式1:
第二种提交事务的方式
-
开启事务:
- START TRANSACTION 或者 BEGIN;
-
提交事务:
- COMMIT;
-
回滚事务:
- ROLLBACK;
-
代码实现:

事务的四大特性(ACID)
- 原子性(Atomicity): 事务是不可分割的最小操作单元,要么全部成功,要么全部失败
- 一致性(Consistency): 事务完成时,必须使得所有的数据保持一致的状态(使得数据库中的变量满足原来的条件)
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行(不同事物,互相不影响)
- 持久性(Durability):事务一旦提交或者回滚,他对数据库中数据的改变就是永久的(变化就会持久化在磁盘中)
并发事务引发的问题
- 并发事务中的问题(就是两个事务同时进行时的问题)
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另外一个事务还没有提交的数据(结果就是读取事务读取的数据还没有更新就会被读取到)(就是一个事务读取到了第二个事务的没有提交的操作) |
| 不可重复读 | 一个事务先后读取到同一条记录,但两次读取到的数据不一样(原因就是两次查询之间有另一个事务又提交了修改操作)(就是同一条sql语句在一个事务中的结果不一样) |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,有发现这行数据已经存在了,好像出现了"幻影";(发生原因就是查询和插入数据的间隙时间中,又另外一个事务由提交了插入数据行的操作,所以在插入数据时会失败(本质就是主键冲突的问题))(就是会出现查数据时没有要插入的主键但是插入时会由报错,就是因为使用的事务隔离级别中不可重复读会失效但是幻读会产生)(串行化解决问题的关键就是阻塞一个事务的进行) |
解决并发事务重复读取的方法--事务的隔离级别
-
事务的四种隔离级别:
- Read uncommited: 可能出现脏读,不可重复读和幻读
- Read committed: 可能出现不可重复读和幻读
- Repeatable Read(默认): 可能出现幻读
- Serializable: 都可能会出现
-
从上向下,数据安全性降低,但是级别会逐渐升高
-
操作语法:
- 查看事务的隔离级别: SELECT @@TRANSACTION_ISOLATION
- 设置事务隔离级别: SET [SESSION(只有当前窗口可以使用)|GLOBAL(所有操作窗口多可以使用)] TRANSACTION ISOLATION LEVEL {READ UNCOMMITED READ COMMIT REPEATABLE READ SERIALIZABLE};
mysql在linux环境下的部署
- 首先可以下载mysql-server服务端(其实也可在官网找到对应的安装包进行安装,其实就是下载rpm包或者tar包,利用tar -zxvf进行解压,注意配置环境变量,首先解压到opt目录下 之后移动到bin目录下)
- 查看mysql服务状态 sudo service mysql status
- 启动mysql服务 sudo service mysql start
- 开始配置用户密码 alter user 'root'@'localhost' indentify with mysql_native_passworld by 'password'
- 启动mysql: mysql -u root -p 即可
- 利用quit就可以退出mysql服务啦
索引
索引的概念
索引是帮助mysql高效获取数据的数据结构(有序),在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构用某一种方式指向数据,这样就可以在这些数据结构中使用高级查找算法,这种数据结构就是索引(实际上是利用二叉树的数据结构),没有索引就会发生全表扫描(效率低下) ,利用索引可以提升查询效率
索引结构
mysql的结构根据不同的存储引擎,但是大致包含B+ Tree,Hash索引,R-tree(空间索引),Full-text(全文索引),但是InnoDB支持B+ Tree(一般都是B+ tree索引)
BTree
- 二叉树的弊端:顺序插入时会退化成一个链表,查询速率降低,并且数据较多时,层级比较深,检索速度慢
B树: 多路平衡查找树,根节点用于存放每一个区间的极大和 极小值,极大和极小值不断向下面分叉,就可以大大降低树的层次,比如利用4个key值就可以有5个指针
B树的构建方式: 根据度的不同根据插入数据的大小,就会发生树的裂变(中间元素向上裂变)
:::warning 分享一个特别好用数据结构可视化的网站: https://www.cs.usfca.edu/~galles/visualization/
:::
B+Tree
- 所有元素都会出现叶子节点,叶子节点会形成一个单链表,非叶子节点的元素都是索引的作用,其实就是向上裂变的过程中会在叶子节点中留下备份,所以这样的话就只用遍历单链表就可以找到对应元素了
- mysql中对于B+Tree进行了改进,把叶子节点的单向链表换成了循环双向链表
哈希索引
- 注意哈希索引只用于等值比较,不支持范围查询(between,<,>)
- 无法利用索引完成排序操作
- 查询效率高,通常只用一次检索就可以了,效率通常高于B+tree索引
索引种类(还是要关注索引的定义,是一种存储数据的结构)
| 分类(存储对象不同) | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 正对于表中主键创建的索引 | 默认自动创建,只可以有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键字,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
InnoDB存储引擎中,根据索引的存储方式,分为以下几种
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 | 将数据存储和索引放在一起了,索引结构的叶子节点保存了行信息 | 必须有并且 只可以有一个 |
| 二级索引 | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引的选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一索引作为聚集索引
- 如果不存在主键,也没有适合的唯一索引,就会自动生成一个rowid作为隐藏的聚集索引
查找方式:
- 一定要通过聚集索引才可以找对对象行信息
- 如果不是通过聚集索引对应的数据进行查询的话,就会首先查询二级索引(每一个字段对应了一个二级索引),通过二级索引找到对应的主键,拿到对应的主键之后再到聚集索引中查询(称为回调查询)
索引的操作语法
创建索引(create index关键字)
- create [unique|fulltext(其实就是索引的类型)] index index_name** on** table_name (index_col_name) (注意索引名称和字段名称不同),如果只为一个字段创建索引就是单列索引
查看索引(show关键字)
- show index from table_name
删除索引(drop index关键字)
- drop index index_name** from** table_name
-- 创建常规索引 注意索引名称的书写 idx_表名_字段名
create index idx_user_name on user(name);
-- 创建唯一索引
create unique index idx_user_phone on user(phone);
-- 创建联合索引(利用同一个索引关联多个字段)
create index idx_user_pro_age_sta on user(profession,age,status);
-- 查看数据表中的索引
show index from user;
-- 删除指定的索引
drop index idx_user_ema from user;
sql性能分析工具
sql性能分析
- sql执行频率: mysql客户端连接成功之后,通过show [session|global] status 命令就可以提供服务器状态信息,通过如下指令,可以查看当前数据库的insert update ,delete,select执行的频率:
:::warning show global status like 'Com_____' -- 7个字符
:::
查询结果演示:
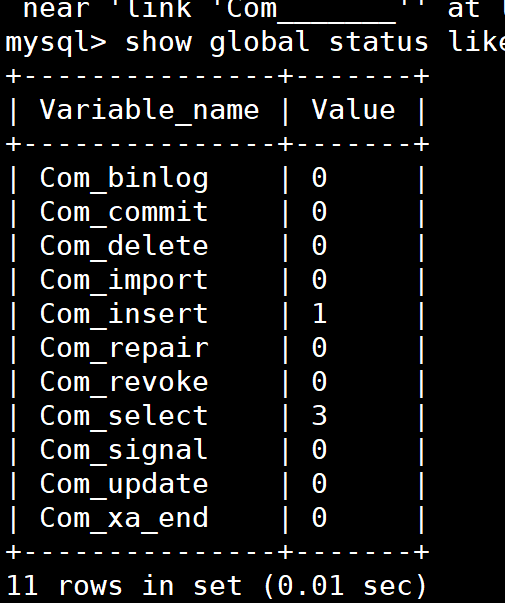
慢查询日志
- 慢查询日志记录了所有执行时间超过指定参数(long_query_time 默认为10秒) 的所有sql语句的日志,mysql的慢查询日志默认没有开启,需要在mysql的配置文件(/etc/my.cnf)中配置信息(但是ubuntu上好像不行):

- 利用 show variables like 'slow_query_log' 可以查看慢查询日志是否开启
profile详情
- show profiles可以在sql优化时帮助我们了解事件都耗费在哪里,利用have_profiling参数,可以看到当前Mysql是否支持profile操作,利用select @@have_profiliing 命令查看
- 默认profile没有 开启,需要利用 set profiling =1 指定开启状态
# 查看每一条sql的耗时基本情况
show profiles;
# 查看指定query_id 的sql语句的各个阶段耗时情况
show profile for query query_id;
# 查看指定的query_id的sql语句的cpu使用情况
show profile cpu for query query_id;
sql执行阶段的耗时:
sql占用cpu的情况:
explain执行计划
- explain 或者desc命令后去mysql如何执行select 语句的信息,包含select语句执行过程中如何连接和连接的顺序
:::warning
- 语法如下 (直接在select语句前面加上explain或者desc即可)
explain/desc select 字段列表 from 表名 where 条件
:::
- 执行计划示例:

各个字段的含义
- id : select 查询的序列号,表示查询中执行select子句或者操作表的顺序(id相同,执行顺序从上向下,id不同,执行顺序从下到上,值越大越先执行)(id可以相同,利用规则查看执行顺序)(说明id的大小代表优先级的大小)
- select_type: 表示select 的类型,常见的取值有simple(简单表,只有单表查询),primary(主查询,就是外层的查询),union(union中第二个或者后面的查询语句),subquery(select/where之后包含子查询)等
- type: 表示连接类型,性能由好到坏的连接类型有NULL(不用访问任何表的情况),System,const(使用唯一以索引进行查询),eq_ref,ref(使用非唯一索引),range,index(表示遍历了索引),all (决定优化是否成功)
- possible_key: 显示可能应用到这张表上的索引,一个或者多个
- key: 实际用到的索引,如果为null,就表示没有使用索引
- key_len: 表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失准确性的情况下,长度越短越好
- rows:Mysql认为必须执行查询的函数,在InnoDB存储引擎中,是一个估计值,可能并不准确
- filtered: 表示返回结果的行数占需要读取行数的百分比,值越大越好
- extra: 额外展示的字段(有时候也可以反应sql语句执行的效率)
索引的使用
验证索引优化情况的方法
- 在没有建立索引之前,执行如下sql语句,查看sql语句的耗时,建立索引之后再查询一遍
:::warning select * from tb_sku where sn = '100000003145001'; 只是一个例子,不是必须的
:::
- 建立索引之后还可以实验一次查看一下时间,执行时间会自动显示(加上id = 1/G可以分行展示)(create index idx_表名_字段名 on 表(字段)
索引的使用原则
最左前缀法则(针对联合索引,查询条件中不要跳过某一个中间的字段,否则就不会使用索引(或者跳过某一列查询失效))
- 如果索引了多列(联合索引),需要遵循最左前缀法则,最左前缀法则就是指查询从索引的最左列开始,并且不跳过索引中的列,如果跳跃了某一列,索引就会部分失效(后面的索引就会失效)
- 索引失效,基本和连接条件中各个条件的位置没有关系,只需要最左边的索引存在就可以了
范围查询
- 联合索引中,如果出现范围查询(> <),范围 查询右侧的索引就会失效
- 解决方法: 尽量使用 >= <= 等比较运算符号,此时右侧的索引就会失效
索引失效情况1
索引列运算
- 不要再索引上进行运算操作(就是用对应的字段进行查询),否则索引就会失效 (利用expain查看索引是否使用)
字符串不加单引号
- 字符串类型不加单引号,索引就会失效
模糊匹配
- 如果仅仅是尾部进行模糊匹配(比如 软件%),索引不会失效,如果是头部进行模糊匹配,索引就会失效
索引失效情况2
or连接的条件
- 用or 分割开的索引,如果or前面的条件中的字段有索引,但是后面的字段中没有索引,那么涉及的索引就都不会用到(其实利用or连接的条件中涉及到的两个字段都有索引索引才不会失效)
- 解决方法: 给没有索引的字段创建索引就可以了
数据分布影响
- 如果MySQL评估使用索引比全表更慢,就不会使用索引(比如所有数据都会满足,或者表中绝大多数满足条件,全表扫描就会快于索引)(如果返回的数据为绝大多数数据,就会返回全表扫描,如果返回的数据较少就会使用索引)
SQL提示
- SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些认为的提示来达到优化操作的目的
具体分类如下:
-- use index (使用索引)
-- explain select * from 表名 use index (索引名称) where 条件 例如
explain select * from tb_user use index (idx_user_pro) where profession = '软件工程';
-- ignore index (忽略索引)
-- explain select * from 表名 ignore index(索引名称) where prefession = '软件工程';
explain select * from tb_user ignore index (idx_user_pro) where profession = '软件工程';
-- force index(强制使用索引)
-- explain select * from 表名 froce index (索引名称) where 条件
explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';
覆盖索引
- 尽量使用覆盖索引(查询使用了索引,并且需要返回的字段,在这个索引中可以全部被找到),在该字段中已经全部可以找到了,减少了select *
- 这些差异会体现在extra中,如果extra中出现的信息不同,就说明查询效率降低
:::warning
extra中的补充内容 :
- using index condition: 查找使用了索引,但是需要回表查询(其实就是首先利用二级索引找到主键,之后再根据主键找到待展示的数据)
- using where;using index : 查找使用了索引,但是需要的数据都在索引中可以找到,所以不需要回表查询数据
:::
利用上述原则进行sql优化:
:::color4 对如下sql语句进行优化:
select id,username,password from user where username = 'zhangsan';
解决方案:覆盖索引的原则,应该为username和password建立联合索引
:::
前缀索引
前缀索引的概念:
- 当字符类型为字符串(varchar 或者 text等)时,有时候需要索引很长的字符串,这会使得索引变得很大,查询时回浪费大量的磁盘IO,影响查询效率,此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提升索引效率
前缀索引的创建语法:
- create index 字段名称(idx_表名_字段名缩写) on table_name(字段名(n)) // n表示提取几个字段名作为前缀
前缀长度:
- 可以根据索引的长度来决定,而选择性是指不重复的索引值(基数),和数据表中的记录总数的比值,索引选择性高则查询效率高,唯一索引的选择性是1,所以查询效率最好,求解公式如下(往往需要利用公式,需要综合考虑索引的体积和索引选择性):
:::success
- select count(distinct email) / count(*) from tb_user; -- 利用distinct就可以用于去重
- select count(distinct substring(email,1,5))/count(*) from tb_user;
:::
关于单列索引和联合索引的选择问题
- 单列索引和联合索引的定义不用多说
- 在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引,建议建立联合索引,而非单列索引
- 如何实验: 定义某一个字段,创建联合索引和单列索引,查看mysql使用了哪一个索引
- 注意创建联合索引时字段的所在的位置,再次查询时一定要满足最左前缀法则
索引的设计原则
:::color1
- 针对于数据量较大的数据库,并且查询比较繁忙的表建立索引
- 针对于常作为查询条件(where),排序条件(order by),分组(group by)操作的字段建立索引
- 尽量选择区分度高的索引建立字段(索引选择度高),尽量使用唯一索引,区分度越高,使用索引的效率就越高
- 如果是字符串类型的字段,字段的长度较长,可以根据索引体积和选择性建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,减少了回表查询,提高查询效率
- 要控制索引的数量,索引不是越多越好,索引越多,维护索引的代价越高,会影响增删改查的速度
- 如果索引列不可以存储NULL值,可以在创建表时加上非空约束,当优化器直到每一列是否包含NULL值时,它可以更好的确定哪一个所以更加有效进行用于查询
:::
Redis在工程中的应用可以参考项目: https://github.com/xzwsloser/heima-comment.git
Redis介绍
- Redis是一个键值对数据库,里面存储的就是一个一个又一个的字符串,其中键值可以是用户id,另外值可以是一个json字符串用于存储各种数据
NoSQL
- 表示非关系性数据库,比如sql(s表示结构化,其中的数据需要满足各种约束),但是NoSQL是非结构化的,字段约束没有那么强,存储的一个数据其实就似乎一个节点,每一个节点中可以形成一个图,并且结构改变对于NoSQL的影响较小
- 另外就是关系型和非关系型,关系型数据库其实就是不同表之间通过外键相互关联,但是NoSQL中没有关联,数据存储中可能会存在重复的现象
- 非SQL型的,没有固定语法对于数据进行查询,就是操作数据库没有固定的语法,但是语法较为简单
- 所有关系型数据库都满足事物的ACID特性,但是非关系型数据只是基本满足ACID特性
- NoSQL中的数据类型有: 键值类型(Redis),文档类型(MongoDB),列类型(Hbase)和Graph(Neo4j)类型
- SQL和NoSQL的详细比较和使用场景 :
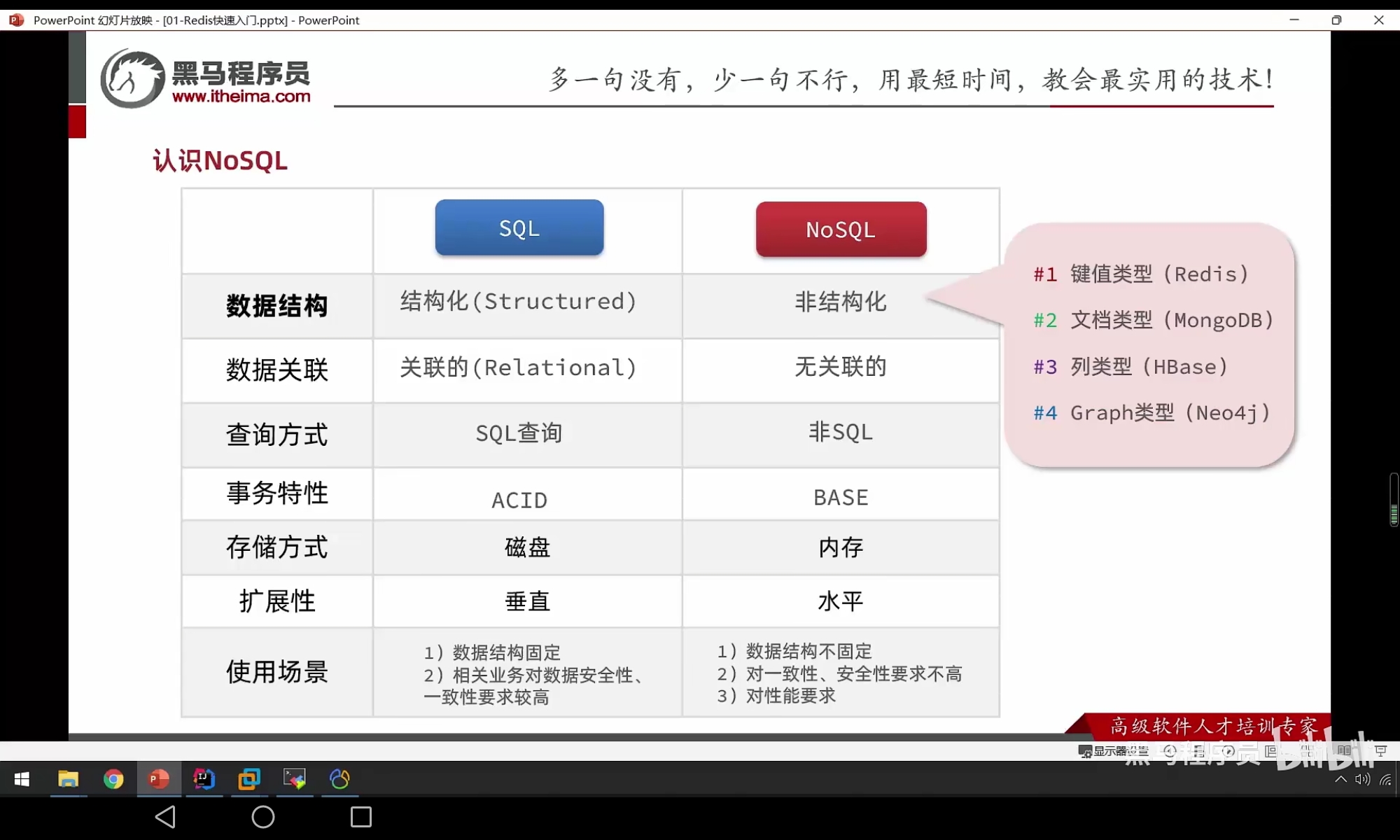
Redis是什么
Redis的各种特征
- 键值(key-value)型,value支持多种不同的数据类型,功能丰富
- 单线程,每一个命令具有原子性(不会产生线程安全的问题)
- 低延迟,速度快(基于内存(直接从内存中读取数据比 从磁盘中读取数据更快),IO多路复用,良好的编码习惯)
- 支持数据持久化(定期把数据从内存写入到磁盘中)
- 支持主从集群,分片集群
- 支持多语言客户端
redis在linux中的部署
- 具体安装步骤如下:
:::info sudo apt install -y gcc // 安装gcc的依赖
sudo mv redis7.2.4.tar.gz /usr/local/src/ // 移动到一个目录下,这一个目录通常用于安装软件(相当于windows的下载目录)
sudo tar -zxvf redis7.2.4.tar.gz // 注意前面的sudo
cd redis // 进入目录
sudo make && make install // 利用makefile编译
sudo chown -R ubuntu:ubuntu /usr/local // make失败的解决方案
cd /usr/local/bin // 查看是否安装成功
// 安装不成功就需要安装 pkg-config
sudo apt install -y pkg-config
// 另外可以利用 wget下载 安装包
:::
- 之后的配置信息如下(使得后台启动配置)
:::danger cp redis.conf redis.conf.bck // 拷贝一份文件
// 配置文件信息
bind 0.0.0.0 // 使得每一个都可以访问
daemon... yes// 配置守护进程
requirepass 密码
logfile 日志文件名称
// 其实还可以配置多个文件
// 最后就可以通过 redis-server 后台运行redis了
// 通过ps -ef 命令查看进程
利用 kill -9 进程号 终止进程
:::
- 配置开机自启动
:::success 首先添加配置文件
sudo vim /etc/systemd/system/redis.service
添加配置信息
。。。 。。。
启动
sudo systemctl daemon-reload
开启或者结束
sudo systemctl start/stop/status/enable redis 即可
// 设置开机自启动只用配置相关信息之后利用 enable启动服务即可
sudo systemctl enable redis
// 一定要注意 systemctl命令
:::
- 终于成功了
Redis客户端的运用
- redis的各种客户端
- 命令行客户端 ctl结尾的 (启动方式: redis-ctl [-h 地址 -p 端口号(6379) -a 密码] commands,成功之后的现象,其实也可以不用指定密码进入之后 就可以利用 AUTH指定密码啦:

- 图形化客户端: 开源地址: github.com/uglide/RedisDesktopManager,免费地址: github.com/lework/RedisDesktopManager-Windows/releses
图形化界面操作图像:
Redis数据结构介绍
- Redis是一个key-value的数据库,但是key一般是String类型的,但是value的类型多种多样,大致分为两类:
- 基本数据类型: String,Hash,List,Set,SortedSet
- 特殊数据类型:GEO,BitMap,HyperLog
- Redis的帮助文档(基本包含所有命令): https://redis.io/docs/latest/commands/
- 后者可以利用help命令查询命令:
Redis通用命令
- 官方文档中可以查看,同时可以利用命令行客户端查看
- 可以利用help 命令名 查看命令的使用方法
常见指定
- Keys : 用以匹配各种格式的键值数据,例如 keys name* ,由于命令查询效率较低并且容易阻塞服务所以在生产环境下一般少使用
- DEL: 删除指定的key值 例如 del name age ... ... ,可以删除多个字段,会有一个返回值代表删除了几个值
- Exists 判断一个key值是否存在 例如 : exists name,返回值就是 0 或者 1
- Expire: 给一个Key值设置一个有效期,目的就是只在一段时间内缓存数据,防止数据的数量过大 ,例如 expire key1
- TTL : 查看一个key值的有效期 语法: TTL 键的名称 ,利用TTL查询数据表示被删除 或者返回-1表示不会被删除
Redis各种数据类型常用命令
String类型常用命令
String类型的介绍
- String类型就是字符串类型,最简单那的存储类型,注意数据类型都是value的类型
- value是String类型,但是根据字符串的格式不同,又分为一下几种类型:
- string 普通字符串
- int 整数类型,可以进行相应的运算操纵
- float: 浮点类型,可以做运算操作
- 最大空间不会超过512m
常用命令如下
- SET: 向redis中添加一个或者修改一个已经存在的string类型的键值对
- GET: 根据Key值获取String类型的value值
- MSET: 批量添加键值对数据
- MGET: 根据多个键获取多个值
- INCR: 让一个整数的key值自增1
- INCRBY: 让一个整形的key值自增并且指定步长,例如 incrby num 2表示num自增2,值改为负数就可以自减啦
- INCRBYFLOAT: 让一个浮点数自增并且指定步长,但是对于整数使用这个指令就会把他变成浮点数
- SETNX: 添加一个键值对数据,前提是这一个 key不存在,否咋不执行,返回值 是是否成功,和set key value nx作用类似
- SETEX: 添加一个string类型的键值对并且指定有效期, 语法 setex key 有效期 value,和 set key value ex 有效期 相同
key的层级格式
- Redis中的key允许多个单词组成的层级结构,多个单词之间可以使用 : 分隔开,格式如下 : 项目名:业务名:类型:id , 比如 heima : user :id
- 如果value是一个java对象,就可以使用JSON可是的字符串存储数据,演示如下:
- 层级结构演示:
Hash类型
Hash类型结构介绍
- Hash类型也叫做散列,其value是一个无序字典(其实就是key值也是一个有一个键值对),相当于java中的hashmap
- key都是 string类型的,这里指的就是 value 就是 hash 类型的
- Hash结构演示:
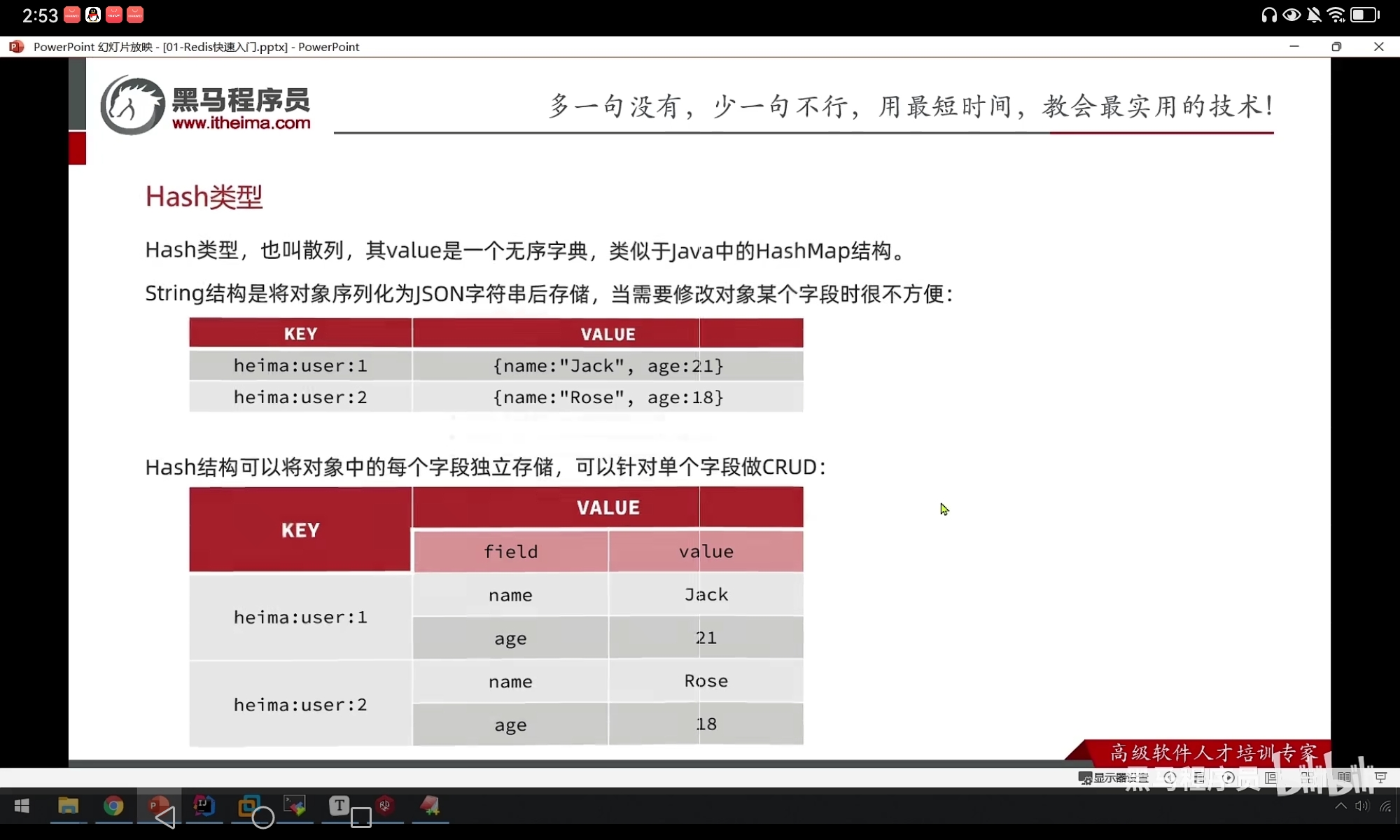
Hash类型中的常见命令
- HSET key field value : 表示添加或者修改hash类型的 key 的field值
- HGET key field : 获取一个hash类型的key的field值
- HMSET : 批量添加多个hash类型key的field值(但是每一次可以添加多个字段,但是为什么利用hset也可以)
- HMGET: 获取多个hash类型key的field值
- HGETALL : 获取一个key中记录的多个键值对的值
- HKEYS: 获取一个hash类型中key中的所有field
- HVALS: 获取一个hash类型的key中的所有value
- HINCRBY: 是一个hash类型的字段值自增并且指定步长(退回一级,就是填写以下field字段名即可)
- HSETNX : 添加一个hash类型的key的field值,前提是这一个field不存在(注意判断的额是每一个字段),否咋执行失败
List类型
List类型的介绍
- Redis中的List类型基本和java中的LinkedList类似,可以当成一个双向链表使用,既可以支持正向检索也可以支持反向检索
- List类型的特点基本和链表一致(有序,元素可以重复,插入和删除元素快,查询速度一般)
List中的常见命令
- LPUSH key element ... : 向链表 左侧插入一个或者多个元素(头插法),可以利用图形化界面查看数据顺序
- LPOP key: 移除并且返回列表左侧的第一个元素,没有就会返回 nil
- RPUSH key element ... : 向列表右侧插入一个或者多个元素(尾插法)
- RPOP key : 移除并且返回链表右侧的第一个元素(尾删法)
- LRANGE key start end : 返回一段角标范围内的所有元素
- BLPOP和BRPOP : 和LPOP和RPOP类似,只不过元素没有等待时间,而不是直接指定返回nil (没有元素就是等待一段时间,相当于一个阻塞队列) 语法 lpop 字段名称 等待时间
利用List模拟栈和队列的数据结构
- 利用链表模拟队列 : 出口和入口不在一边(其实就是一边使用 自己的push ,另外一边使用自己的pop)
- 利用链表模拟栈 : 出口和入口在在一边(只可以利用一边的push和pop方法)
- 利用链表模拟阻塞队列 : 基本和队列一致(入口和出口一致),同时取出元素使用BLpop和BRpop
Set类型
Set类型的介绍
- Redis中的set结构基本和java中的hashset类似,可以看作一个value为null的hashmap,因为是一个hash表,所以需要具备和hashset类似的特征(无序,元素不可以重复,查找元素的速度快,支持并集,差集和交集)
Set类型中的常见命令
- SADD key member ... : 向set中添加一个或者多个元素
- SREM key member ... : 移除set中的指定元素
- SCARD key : 返回set中的元素个数
- SISMEMBER key member : 判断一个元素是否存在于set集合中
- SMEMBERS : 获取set集合中的所有元素
- SINTER key1 key2...... : 求解key1 与 key2的交集
- SDIFF key1 key2 ...... : 求解 key1 和 key2的差集
- SUNION key1 key2 ... ... : 求解key1和key2的并集
SortedSet类型
SortedSet 介绍
- Redis中的SortedSet是一个可排序的set集合,和java中的Treeset类似,但是底层的数据结构相差较大,SortedSet中的每一个元素都带有一个score属性,可以基于score属性对于元素进行排序,但是底层是一个跳表(SkipList) 加上一个 hash表
- 特点:
- 可以排序
- 元素不可以重复
- 查询速度快
- 可以用于做排行榜等功能
SortedSet的常见命令
- ZADD key score member : 添加一个元素或者多个元素到sorted set集合,如果已经存在就会更新它的score值(就是member 对应的分数)
- ZREM key member : 删除一个sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member : 获取sorted set中的指定 元素的排名
- ZCARD key : 获取sorted set中的元素的个数
- ZCOUNT key min max : 统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member : 让sorted set中的指定元素自增,步长为指定的额increment值
- ZRANGE key min max : 按照 score排序之后,获取指定排名范围内的元素(但是根据角标排序,角标默认 从0开始)
- ZRANGBYSCORE key min max: 按照score排序之后获取指定的score范围内的元素
- ZINTER ,ZDIFF ,ZUNION: 表示求差集,交集,并集
- 注意所有的排名都是升序的,如果降序就需要在命令的后面添加REV即可
利用golang操作redis数据库
- 利用go-redis操作redis数据库,相应的客户端的github地址 : https://github.com/redis/go-redis
安装 go-redis库
- 利用 go get安装go-redis库
:::success // redis 6
go get github.com/go-redis/redis/v8
// redis 7
go get github.com/go-redis/redis/v9
// 现在是
go get github.com/redis/go-redis/v9
:::
使用 go-redis库
连接redis
- 连接方式如下(入门代码演示):
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
var rdb *redis.Client
func init() {
rdb = redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0, // 和集群相关
})
}
func main() {
// 入门引用
ctx := context.Background()
err := rdb.Set(ctx, "test-key", "test-value", 0).Err() // 表示不会过期
if err != nil {
panic(err)
}
// 首先拿到相应的值
result, err2 := rdb.Get(ctx, "test-key").Result()
if err2 != nil {
panic(err2)
}
fmt.Println(result)
// 如果使用原生命令就可以使用Do函数
result1, err3 := rdb.Do(ctx, "get", "test-key").Result()
if err3 != nil {
panic(err3)
}
fmt.Println(result1.(string))
}
redis中string类型应用
- 除了其中的GetSet方法之外其他的方法基本就是原生的命令,基本就是利用上下文路径进行操作,基本的操作和命令差不多
- 部分函数的代码演示:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
"time"
)
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
// 获取成功之后插入数据
ctx := context.Background()
err := rdb.Set(ctx, "newk1", "v1", 0).Err()
if err != nil {
panic(err)
}
// 演示 GetSex方法 , 获取到的就是一个老的值
// 但是新的值已经被改变了
result, err := rdb.GetSet(ctx, "newk1", "newv1").Result()
if err != nil {
panic(err)
}
fmt.Println(result)
// 演示setnx方法
err = rdb.SetNX(ctx, "newk1", "newnewv1", 0).Err()
if err != nil {
panic(err)
}
result1, _ := rdb.Get(ctx, "newk1").Result()
fmt.Println(result1)
// 演示批量设置和批量查询
// 批量查询数据,利用mget方法
result2, _ := rdb.MGet(ctx, "k1", "k2", "k3").Result()
fmt.Println(result2)
// 演示批量插入的方法
err = rdb.MSet(ctx, "key1", "value1", "key2", "value2", "key3", "value3").Err()
if err != nil {
panic(err)
}
// 演示自增方法 incr incrby incrfloatby
rdb.Set(ctx, "num1", 12, 0)
// 自增
result4, err := rdb.Incr(ctx, "num1").Result()
if err != nil {
panic(err)
}
fmt.Println(result4)
// 演示另外的自增方法
result5, err := rdb.IncrBy(ctx, "num1", 9).Result()
if err != nil {
panic(err)
}
fmt.Println(result5)
// 演示浮点数的自增方法
result6, err := rdb.IncrByFloat(ctx, "num1", 2.2).Result()
if err != nil {
panic(err)
}
fmt.Println(result6)
// 自减的操作 ,其实就是改为 dsc 或者改为负数
// 删除 数据 Del可以批量删除
err = rdb.Del(ctx, "k1", "k2", "k3").Err()
// 每一个函数有一个返回值有一个异常值应该总和运用
if err != nil {
panic(err)
}
// 利用expire函数设置过期时间
err = rdb.Expire(ctx, "num1", 10*time.Second).Err()
if err != nil {
panic(err)
}
i, err := rdb.Exists(ctx, "num1").Result()
fmt.Println(i)
}
hash结构的常用方法
- 重点注意 oop的思想,其中hset,hmset方法第二个参数可以传递一个对象过去
- 代码演示:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 演示hash中的方法
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
// 演示 HSet
ctx := context.Background()
err := rdb.HSet(ctx, "hash1", "count", 1).Err()
if err != nil {
panic(err)
}
// 演示 HGet
result, err := rdb.HGet(ctx, "hash1", "username1").Result()
fmt.Println(result)
// 演示 HGetAll
result1, err := rdb.HGetAll(ctx, "hash1").Result()
fmt.Println(result1)
// 演示 Hincrby , 其实就是累加元素
result3, err := rdb.HIncrBy(ctx, "hash1", "username1", 2).Result()
fmt.Println(result3)
// 演示 hkeys
result4, err := rdb.HKeys(ctx, "hash1").Result()
fmt.Println(result4)
// 演示字段数量 hlen
len, err := rdb.HLen(ctx, "hash1").Result()
fmt.Println(len)
// 批量查询
result5, err := rdb.HMGet(ctx, "hash1", "username1", "count").Result()
fmt.Println(result5)
// 批量设置,可以利用map结合设置
data := make(map[string]interface{})
data["username2"] = "lisi"
data["index"] = 1
err = rdb.HMSet(ctx, "key", data).Err()
// 利用 hsetnx
err = rdb.HSetNX(ctx, "hash1", "username1", "wangwu").Err()
// 演示 hdel 删除操作
err = rdb.Del(ctx, "hash1", "username1").Err()
// 所有字段删除之后键值就会消失
}
List类型中的常用方法
- 没有见过的方法有 :
- Lindex: 根据索引寻找元素
- LpushX等 : 如果有相应的键值才会插入元素,否咋不会插入元素
- LRem: 删除元素,可以指定删除位置和删除次数
- LInsert: 插入元素,可选在之前还是之后插入元素
- 代码演示如下:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
// 演示 List集合中的常见方法
// Lpush , Rpush
ctx := context.Background()
err := rdb.LPush(ctx, "list", 1, 2, 3, 4, 5, 6, 7).Err()
if err != nil {
panic(err)
}
err = rdb.RPush(ctx, "list", 8, 9, 10, 11, 12, 13).Err()
// 演示 Lpop,Rpop方法
result, err := rdb.LPush(ctx, "list").Result()
fmt.Println(result)
result2, err := rdb.RPop(ctx, "list").Result()
fmt.Println(result2)
// lpushx , rpushx 方法 ,就是相当于 setnx
// 只有链表存在才会插入数据
result3, err := rdb.LPushX(ctx, "list1", 1, 2, 3).Result()
fmt.Println(result3) // 控制台信息
// 演示 LLen返回链表长度
result5, err := rdb.LLen(ctx, "list").Result()
fmt.Println("链表的长度为", result5)
// 演示 Lrange方法 , 其中停止位置为 -1 表示取出全部元素
vals, err := rdb.LRange(ctx, "list", 0, -1).Result()
fmt.Println(vals)
// 演示 lrem函数,用于删除 元素 ,后面第一个参数就是删除次数(可以指定删除次数),后面就是删除的值
// 返回的就是删除次数 , rrem也是一样
// 如果参数是 负数的话就表示从右边开始删除
// 如果参数是 0 的话就表示 删除 所有符合条件的元素
result6, err := rdb.LRem(ctx, "key", 1, 100).Result()
fmt.Println(result6)
// 演示 lindex 函数
// 根据索引坐标查询数据
val, err := rdb.LIndex(ctx, "list", 4).Result()
fmt.Println(val)
// 演示在指定位置插入数据
// 演示 linsert函数 , 参数中的options参数表示在之前还是之后插入元素
// 可选 after或者 insert, 之后的参数 pivot表示对象名称,这里就是在 5 的前面插入 9
err = rdb.LInsert(ctx, "list", "before", 5, 9).Err()
}
Set类型中的常用方法
- 与命令不同的只有:
- SPop,SPopN : 随机删除元素
- 但是其他的命令一定要记住
- 代码演示如下:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 用以演示 set类型的方法
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
ctx := context.Background()
// 首先是 sadd方法添加元素
err := rdb.SAdd(ctx, "set", 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15).Err()
if err != nil {
panic(err)
}
// 演示 srem方法删除元素
err = rdb.SRem(ctx, "set", 1).Err()
// 演示获取集合元素个数 scard
result, err := rdb.SCard(ctx, "set").Result()
fmt.Println(result)
// 演示随机删除 元素 spop
result4, err := rdb.SPop(ctx, "set").Result()
fmt.Println(result4)
// 随删除多个元素
result5, err := rdb.SPopN(ctx, "set", 2).Result()
fmt.Println(result5)
// 判断元素是否 在集合中 sismemeber
result2, err := rdb.SIsMember(ctx, "set", 2).Result()
fmt.Println(result2)
// 获取所有元素 smembers
vals, err := rdb.SMembers(ctx, "set").Result()
fmt.Println(vals)
// 演示集合方法 差集 交集和并集
err = rdb.SAdd(ctx, "set1", 1, 2, 3, 4, 56, 57, 58, 59).Err()
result6, err := rdb.SDiff(ctx, "set", "set1").Result()
fmt.Println(result6)
result7, err := rdb.SUnion(ctx, "set", "set1").Result()
fmt.Println(result7)
result8, err := rdb.SInter(ctx, "set1", "set2").Result()
fmt.Println(result8)
}
// 演示可变参数
func manyParameters(key ...int) {
for _, ele := range key {
fmt.Println(ele)
}
}
sorted set中的常用方法
- 方法基本一样,但是注意事项如下:
- 首先 函数的 z 后面加上 rev表示降序排列,最后加上 withscores表示带回分数
- 代码演示如下:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 用于演示 sorted set中的常见方法
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
// 演示 zadd 方法
ctx := context.Background()
err := rdb.ZAdd(ctx, "sorted-set", redis.Z{Score: 100, Member: "zhangsan"}).Err()
if err != nil {
panic(err)
}
// 演示 zcard函数
result, err := rdb.ZCard(ctx, "sorted-set").Result()
fmt.Println(result)
// 演示统计函数 zcount 函数 统计范围, 可以指定是否开闭区间
result2, err := rdb.ZCount(ctx, "sorted-set", "80", "99)").Result()
fmt.Println(result2)
// 增加操作
result3, err := rdb.ZIncrBy(ctx, "sorted-set", 2, "zhangsan").Result()
fmt.Println(result3)
// 演示排序操作 zrange 和 zrevrange(表示降序排列)
result4, err := rdb.ZRange(ctx, "sorted-set", 0, -1).Result()
fmt.Println(result4)
// 演示按照分数查找
op := redis.ZRangeBy{
Min: "70",
Max: "100",
Offset: 0, // 相当于 sql中的limit,从第几条语句开始查询
Count: 3, // 表示返回的记录条数
}
result5, err := rdb.ZRangeByScore(ctx, "sorted-set", &op).Result()
fmt.Println(result5)
// 演示 zrangebysocrewithsocre ,返回元素和分数
result6, err := rdb.ZRangeByScoreWithScores(ctx, "sorted-set", &op).Result()
fmt.Println(result6)
// 删除元素可以使用 zrem,zremrangebyrank(利用索引删除元素),zremByscore(表示根据分数范围删除元素)
// 查询分数
result7, err := rdb.ZScore(ctx, "sorted-set", "zhangsan").Result()
fmt.Println(result7)
// 查询排名 , 同时可以加上 withscores后缀找到分数,zrevrank也可以找到
// 注意排名需要利用 索引 + 1
result8, err := rdb.ZRank(ctx, "sorted-set", "zhangsan").Result()
fmt.Println(result8)
}
redis 连接池
- 相当于 JDBC 中的 druid 连接池
- 实现初始化好一个连接池,需要使用连接时,直接从连接池中取出一个连接
- 提高的效率
redis 连接池的操作
- 利用 redis 连接池的操作
这一次一定学会
KMP算法
为什么要求解最长前缀
- 首先什么是最长前缀:
- 比如字符串为 $aabaaf$,那么索引范围为 $[0 , 4]$ 内的最长前缀就是$aa$
- 最长前缀在字符串匹配中的含义:
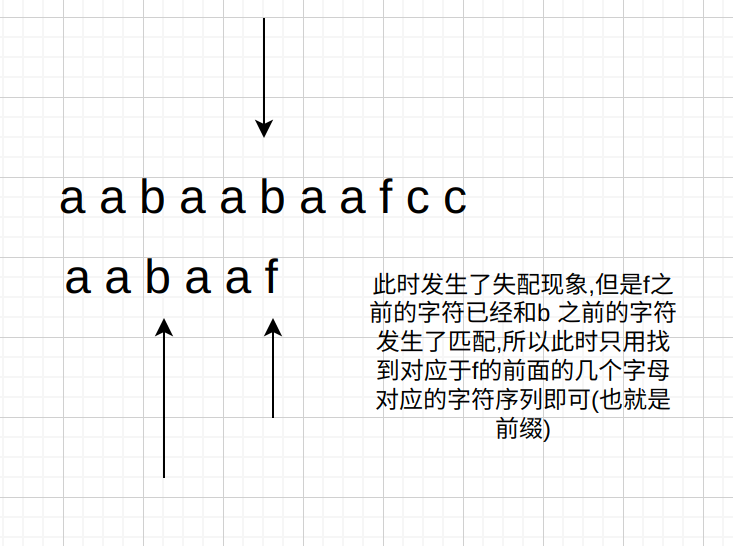
- 前缀表的含义: $prefix[j]$ 表示索引范围为$[0,j]$ 的范围内最长前缀的长度大小,比如$aabaaf$的前缀表就是$0 1 0 1 2 0$
- 另外注意前缀表还是最长的公共子字符串: 也就是说可以重复,比如$abcabcabc$ 的前缀表就是
0 0 0 1 2 3 4 5 6,也就是abcabc可以充当最大公共前后缀,但是后面的讨论依然生效,只需要把不同的区域进行重合部分重合即可
next数组
next数组的作用就是指定如果在发生失配的时候,子字符串中的指针需要回退到哪一个位置,当然next可以就是前缀表,但是这样的化,比如j的位置失配了,此时需要重新匹配的位置就是next[j - 1]的位置,这样比较不方便,所以我这里采用的实现方式就是把前缀表中的数字减去$1$ 就可以得到next数组- 换而言之,$next[j]$ 表示字符串的索引范围为 $[0 , j]$ 的位置的最长前缀的最后一个字母的索引位置,比如字符串$aabaaf$的$next$ 数组也就是
-1 0 -1 0 1 -1
next 数组的求解方式
- 定义两个指针:
i指向当前遍历到的位置,j指向索引范围为$[0 , i -1]$ 的前缀的最后一个字符,考虑如下两种情况 - 如果$s[i] == s[j + 1]$ 那么说明,$i$ 的位置和前面的前缀匹配,所以此时需要把前缀表最后一个指针的位置向后面移动$1$ ,同时$next[i] = j$ ,这样就可以求解得到$next[i]$
- 如果$s[i] != s[j + 1]$ 那么此时就需要不断令$j = next[j]$ 知道二者相等或$j = -1$,这一种情况不太好理解,画图解释:
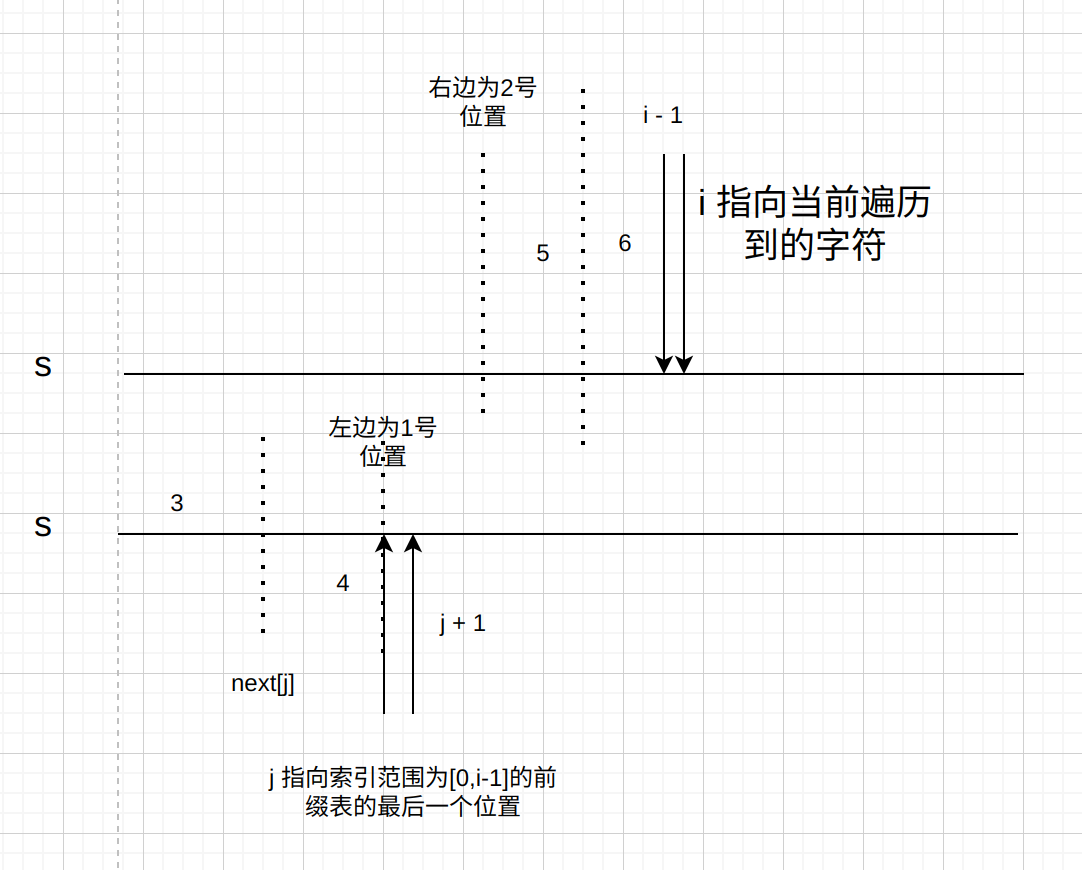
- 解释一下上图中,比如$s[j+1]!=s[i]$ ,==但是此时 $1$号位置和$2$号位置的字符串相同,并且对于$next[j]$ 左边的$3$ 号位置和右边的$4$ 号位置相同,由于$4$号位置和$6$号位置相同,所以$3$ 号位置和$6$号位置也相同==,所以此时可以利用$j = next[j]$ 进行回退
- 所以求解
Next数组的代码如下:
void getNext(vector<int>& next , string s) {
int j = -1; // 表示最长前缀的最后一个字母的位置,也就是前缀的结尾
next[0] = j;
int i = 1; // 表示当前指向的字母,注意这一个字母的前面 (j + 1) 个字母都已经匹配了
int n = s.size();
for( ; i < n ; i ++) {
while(j >= 0 && s[i] != s[j + 1]) {
j = next[j];
}
if(s[i] == s[j + 1]) {
j ++;
}
next[i] = j;
}
}
匹配过程
- 终于到了匹配过程,匹配过程中比较重要的一点就是主字符串中的指针不移动,一直都是子字符串中的指针移动
- 匹配过程中明确两个指针的含义:
i表示此时遍历到主字符串中的哪一个字符了,也就是当前字符的索引,j表示i前面已经匹配的最后一个字符的索引位置,这样做也是为了直接使用next[j]进行回溯 - 还是考虑两种情况:
s[i] == t[j + 1]此时匹配成功,j ++即可s[i] != t[j + 1]此时匹配失败,需要回退指针j = next[j](具体原因看上面的图解)
- 最后匹配的代码如下:
int kmpMatch(string& s , string& t) {
vector<int> next(t.size() , 0);
getNext(next , t);
// j 指向 t 中已经匹配的最后一个字母 , i 表示 s 的当前字母
int j = -1 , i = 0;
for( ; i < s.size() ; i ++) {
while(j >= 0 && s[i] != t[j + 1]) {
j = next[j];
}
if(s[i] == t[j + 1]) {
j ++;
}
if(j == t.size() - 1) return i - j; // 注意在循环中
}
return -1;
}
参考题目: https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string/description/ https://leetcode.cn/problems/repeated-substring-pattern/
Leetcode中的hot100记录
- 两数之和 哈希表,记录值和索引之间的关系即可
- 字母异位单次分组 哈希表用于分组,这里可以把字符串排序之后的值得作为
key, 字符串本身作为value - 最长连续子序列 利用
unordered_set进行去重操作,当序列中不存在这一个数字的前面一个数字的时候就说明不是开头跳过,否则就说明是开头一次往后面找看可以找到那里
- 总结:
unordered_map用于统计,以及寻找相同的关系进行元素的统一,重点是找到元素的统一特点unordered_set用于去除重复,或者进行单个元素的搜索
- 移动零 双指针,
slow指向的都是已经满足条件的位置,fast指针用于搜索元素,当遇到非0元素就可以交换到前面即可 - 盛装最大水的容器 一个指针从前面开始一个指针从后面开始,对应的长度小的一个指针进行移动即可,并且在移动的过程中记录最大的容量即可
- 三数之和 三指针法,首先第一个指针用于确定起点,之后的两个指针一个前一个后并且进行类似于二分查找的操作即可,特别注意减枝操作和去重操作
- 接雨水 经典
hard,还是利用单调栈的方法,在遍历的过程中找到右边第一个大于该元素的元素,注意最后考虑三个元素,中间的一个元素就是装水的元素 ,result += (min(height[st.top()] , height[st.top()]) - height[mid]) * (i - st.top() - 1)
- 总结:
- 双指针的类型:
- 快慢指针
- 首尾指针(类似于二分查找)
- 注意边界的控制
- 双指针的类型:
-
最长的无重复字符的字符串长度 字符串作为滑动窗口即可,注意最后一个元素需要加入到滑动窗口中,另外注意滑动窗口的加入 元素和删除与删除元素的规则
-
字符串中的所有异位词 定长滑动窗口 or 非定长滑动窗口, 注意异位词的最快的方法就是使用哈希表,所以这里也是一样,注意哈希表在使用的过程中加入元素可以抽象为:
count[s[right] - 'a'] --, 取出元素可以抽象为:count[s[right] - 'a'] ++ -
滑动窗口最大值 单调队列,每一次加入元素需要弹出所有小于这一个元素的所有元素,并且注意弹出元素的时候判断最大元素是否是需要弹出的元素即可,可以参考: 栈与队列
-
最小覆盖子串 滑动窗口的经典题目,注意滑动窗口中的元素要求的时候就需要移动滑动窗口的指针使得要求被破坏从而使得滑动窗口的指针移动可以继续执行,之后会总结滑动窗口的所有题目类型 参考: 滑动窗口
-
最大子数组和 可以用
dp,dp[i]表示数组中以i结尾的序列的元素最大值, 也可以使用贪心算法 -
合并区间 按照左端点排序,压入第一个元素,之后不断比较当前遍历道德元素和数组中最后一个元素的结尾位置,如果小于结尾位置,那么就可以更新结尾位置了,参考 贪心算法
-
轮转数组 反转整个数组,反转前
K个元素,反转后面的nums.size() - K个元素 -
除自身以外数组的乘积 凡是和数组元素相关的问题都需要可以使用前缀表和后缀表来做,这里的前缀表和后缀表的定义和作用如下: $$ prefix[i] = nums[0] * nums[1] * ... * nums[i - 1] $$ $$ suffix[i] = nums[i + 1] * nums[i + 2] * ... * nums[n - 1] $$ 所以最终的答案数组为: $$ answer[i] = prefix[i] * suffix[i] $$
-
缺失的第一个正数 非常新颖的一个题目,注意到查找元素需要使用哈希表,但是这里使用哈希表就会让空间复杂度变成
O(n),所以这里可以把数组本身当成哈希表,如果数组长度为N, 那么如果之需要判断数组中是否出现1 - N即可,如果都出现了答案就是N + 1,否则就是没有出现的元素,这里的策略就是,所有非正数变成N + 1,另外的正数假设为i就可以标记nums[i + 1]为负数即可,找到第一个正数下标增加一即可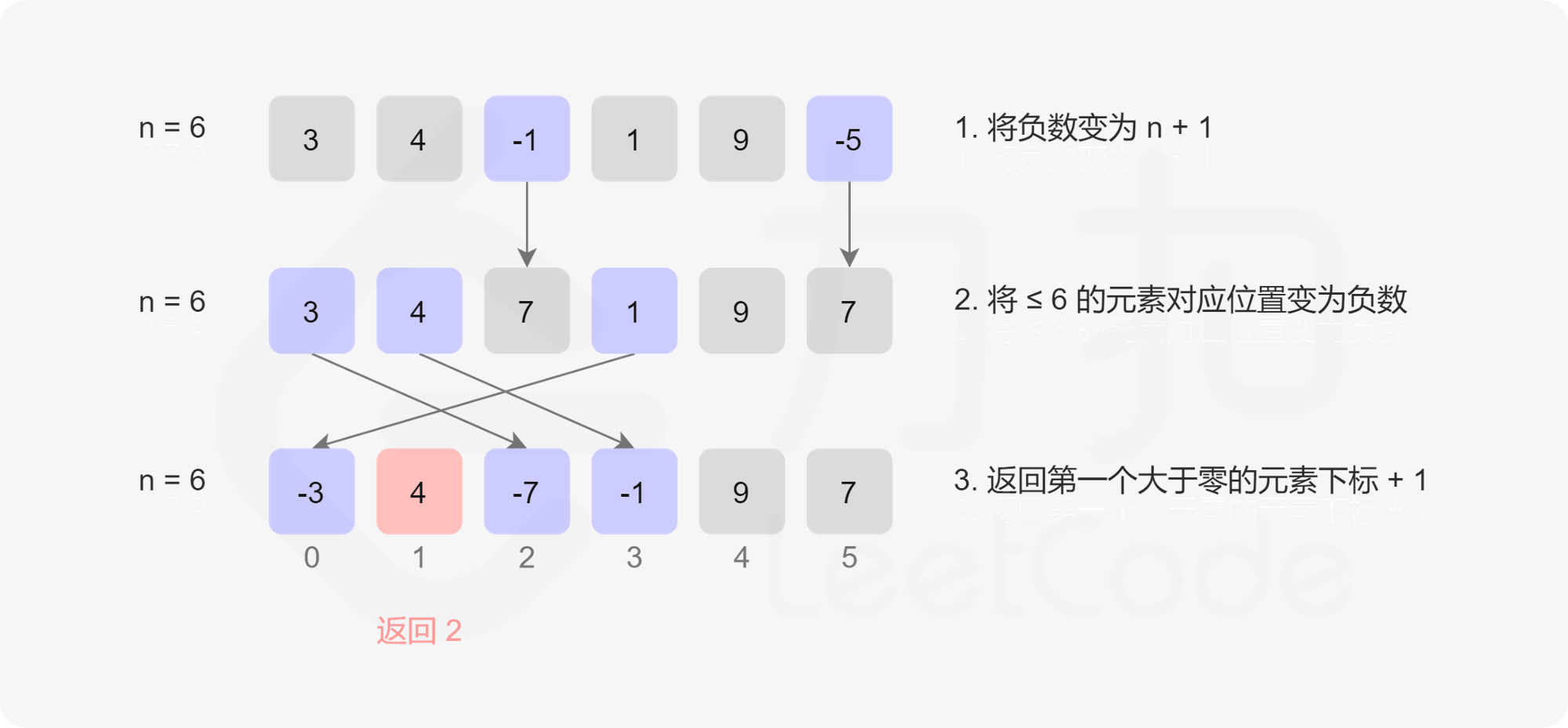 18 - 21. 参考 矩阵操作
22 - 35. 参考 链表
18 - 21. 参考 矩阵操作
22 - 35. 参考 链表 -
二叉树的中序遍历 参考二叉树的统一迭代法(使用通用的模板即可)
c> 用于记录Leetcode中二叉树相关题目的解法,首先最基本的二叉树的前序遍历,中序遍历和后序遍历,层次遍历的迭代实现方式一定需要倒背如流,注意理解转移的顺序即可,另外二叉树的题目一般都可以使用递归法来实现,但是注意递归三要素(递归函数的返回值,递归函数的终止条件,单层递归逻辑),看到一种比较好的统一遍历方式,可以参考以下,感觉总结出来通用的模板了: 统一的迭代法实现
- 添加统一迭代法代码实现
- 统一迭代法和层序遍历法实现方式: tree.cpp
常见算法题型
- 层序遍历:
- 层序遍历 基本的层序遍历,但是需要记录每一层的节点数目,注意此时需要获取到队列的长度来确定每一层的数量
- 层序遍历II 直接层序遍历得到数组并且进行反转即可,但是注意
C++中的reverse算法在反转vector<vector<T>>会反转内层数组的元素,所以这里需要在加入节点的时候首先加入右节点,之后加入左节点(但是我本地没有问题?) - 二叉树的右视图 只用在层序遍历的过程中记录最后一个遍历到的节点的值即可
- 二叉树的层平均值 一样的,注意定义
sum为double类型,或者$*0.1$ 来转换为double类型 - N叉树的层序遍历 注意不知道
Node*&怎么写,可以使用自动类型推导auto - 二叉树行中的最大值 同上
- 填充每一个节点的下一个节点注意在
C++中进行指针的赋值操作,其实指针就是存储数据的int,所以对于指针指向的变量进行改变的时候,堆区地址指向的变量就会发生改变,所以指针可以起到关联更新的作用 - 填充每一个节点的下一个节点II 和上面一个样,如果需要进行从右边到左边的连接,就可以使用首先加入右边的节点,之后加入左边的节点
- 二叉树的最大深度 注意层次遍历就是一种
bfs,所以可以利用bfs进行最小路径的寻找,这一个题目就是一个例子
- 翻转二叉树 除了利用递归的方式(注意递归的三要素),另外还可以利用迭代法,这是由于利用迭代法的时候每一次已经把所有节点都入栈了,所以只用在遍历每一个节点的时候对于每一个节点进行操作即可
- 对称二叉树 利用递归的方法,可以比较左右子树是否对称,所以需要定义一个函数用于判断两个树是否是镜像关系,强烈建议首先排除两个树中有
nullptr的情况 可以利用栈来记录层序遍历中相邻的元素并且进行比较操作 Leetcode_101.cpp - 二叉树的最大深度 可以利用层序遍历,也可以利用递归,两行代码速通
- 二叉树的最小深度 注意最小深度的概念,也就是距离根节点最近的叶子节点距离根节点的距离,可以利用递归,并且此时递归需要分情况判断,也就是需要分类讨论根节点的左右子树是否为空
- 完全二叉树的节点个数 层序遍历
- 判断平衡二叉树 首先利用前面的求解最大深度的方式求解树的高度,之后针对于每一个节点判断两边树的高度差是否超过
1即可,当然注意此时的遍历顺序应该是后序遍历,这是由于此时需要获取到左右子树的高度之后才可以进行判断,求解高度的迭代实现方式可以利用层序遍历或者利用其他遍历方式也可以,重点就是遇到叶子节点就可以回溯了,比如利用后序遍历获取最大高度: Leetcode_110.cpp - 二叉树的所有路径 由于此时需要向下获取节点的相关信息,所以应该使用前序遍历(广义的前序遍历就是首先处理中间节点的逻辑,之后处理子节点的逻辑) Leetcode_257.cpp 注意一定需要统一节点处理方式,比如首先需要把根节点加入到队列中才开始操作队列取决于递归函数的单层处理逻辑
- 二叉树的所有左叶子节点的和 首先确定遍历顺序,此时只需要取出不同的节点判断左边节点是否为叶子节点即可,随便那一种遍历方式都可以,或者也可以使用递归函数,使用递归函数的时候一定需要明确递归函数的作用,这掩才可以在递归函数中把自己当成以已知条件使用
- 树中最左下角的值使用层序遍历,遍历的过程中不断记录最左边的值即可
- 路径总和 还是回溯算法,注意此时只用利用一个全局变量来记录总和,注意回溯函数的终止条件: 当前节点为叶子节点并且全局变量的值和目标值一样,代码:Leetcode_112.cpp
- 利用中序遍历和后序遍历构造二叉树 还是递归三部曲,但是注意单层递归逻辑,首先找到后序遍历的最后一个节点作为根节点,之后在中序遍历中找到这一个节点,这一个节点左边的就是左子树,右边的就是右子树,注意规划区间即可,注意终止条件 Leetcode_106.cpp
- 最大二叉树 和上面一样的套路,形成模板
- 合并二叉树 使用递归的方法非常简单,就是只是对于一个节点进行操作,判断左子树或者右子树是否为空,利用迭代法就可以利用层序遍历的方式,把两棵树的节点压入到栈或者队列中并且进行元素的比较即可,注意形成模板: Leetcode_617.cpp
- 二叉搜索树中的搜索 如果使用递归法,就类似于二分查找,没有找到就可以找左子树,找到了就可以找右子树,如果利用迭代法就不用考虑遍历方式了,由于
BST的性质,路径已经被规划出来了,只需要按照路径走即可,另外这也是一种比较高效的搜索方式 - 验证二叉搜索树 注意二叉搜索树的特点: 左子树的的的所有节点都要大于右子树中的所有节点,所以利用递归比较困难,但是考虑到二叉搜索树的中序遍历是一个有序的序列,可以求解中序遍历之后判断中序遍历有序即可,这样利用递归函数就可以做了,利用迭代法也可以
- 二叉搜索树的最小绝对值差 还是一样求解中序遍历,求解中序遍历的过程中求解相邻两个数字的差值
- 二叉搜索树的众数 迭代法结合哈希或者利用中序遍历结合最长子序列,注意中序遍历中无论那一种操作,递归函数的核心逻辑都存在于中间节点的位置不要写到其他的位置,注意形成模板: Leetcode_501.cpp
- 二叉树的最近公共祖先节点 首先需要确定遍历顺序,这里需要首先获取到底层节点的状态反馈给上层节点,所以需要使用回溯法(也就是首先遍历底层,之后遍历上层),后序遍历就是一种回溯法,具体的方法就是利用回溯进行节点的搜索,如果遇到
root == p || root == q || root == nullptr就可以直接返回了,之后上层节点接受底层节点的状态,判断返回值是否为空(其实就是判断两边树上是否存在p或者q),如果一个返回值不是nullptr那么就可以返回这一个值,表示节点都在这一颗树上面 Leetcode_236.cpp,回溯法的遍历过程如下(注意回溯法一定需要遍历到复合要求的底层才可以返回进行逻辑处理):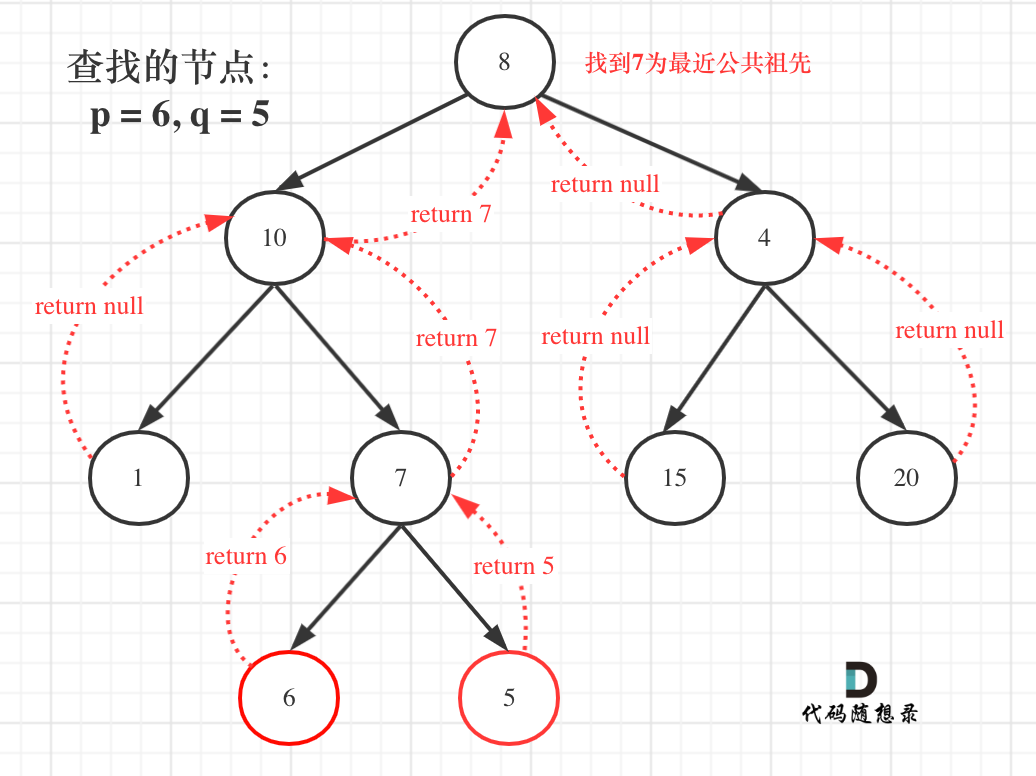
- 二叉搜索树的最近公共祖先节点 首先一定需要理解二叉树回溯的本质,其实就是利用递归进行节点的搜索,所以我们做题时需要首先判断遍历方式,确定相应遍历方式之后在确定单层递归的逻辑关系,这里可以使用递归法,如果当前节点的值小于两个节点的值,就可以向右递归,如果当前节点的值大于两个节点的值,就可以向左递归,同理使用跌达法也是一样的,这是由于二叉搜索树的方向已经确定了
- 二叉搜索树中的插入操作 可以使用递归或者迭代进行操作,注意递归和迭代的本质都是对于元素进行遍历操作,在迭代中注意使用一个
pre指针记录标志位置,从而确定插入点 - 删除二叉搜索树中的节点 注意删除节点的操作,使用递归的本质就是节点的搜索,所以每一次使用递归只需要关注当前节点即可,此时注意单层递归的逻辑就是首先找到右子树最左边的节点,之后把左子树的值复制给右子树最左边的节点 Leetcode_450.cpp
- 修剪二叉搜索树 注意写递归函数的时候,明确当前递归到的节点的含义,比如这里递归函数的参数为
root就说明此时遍历到节点root,所以只用关注root的逻辑即可 ,递归法: Leetcode_669_r.cpp 迭代的逻辑与递归类似,注意当某一个节点不满足要求的时候,删除方式是把左边节点或者右边节点设置为当前节点进行删除,迭代算法: Leetcode_669.cpp - 有序数组转换为平衡二叉树 这里的递增数组,由于对于根节点左边的序列,一定是向左边偏转的一段链表,同样,对于根节点右边的需要也可以是向右边偏转的链表,所以利用递归法的时候,利用区间构造当前节点的方式就是找到开始位置和结束位置的中点,利用这一个中点左边的部分构建左子树,利用中点右边的部分构造右子树,这里迭代法利用了队列来记录递归时需要的变量: Leetcode_108_d.cpp
- 将二叉搜索树转换为累加树 首先明确遍历顺序: 反中序遍历 递归法: 明确递归法的本质就是遍历到当前节点,顺序已经有递归函数的调用顺序确定了,所以只用关注当前节点的处理逻辑即可,迭代法: 利用统一迭代法的模板即可 递归法: Leetcode_538_r.cpp
- 二叉树的直径 定义链长: 叶子节点到该节点的距离(类似于深度) , 本体可以在遍历深度的过程中不断记录最大直径即可 , 并且有
直径 = 左边链长度 + 右边链长度 + 2, 遍历过程中不断记录即可
前缀和的主要作用就是求解数组中某一个连续区间中元素的和,重点在与前缀表的计算
-
前缀和模板题 前缀表的计算方式和对应的区间和的计算方式如下: $$ 前缀表: prefix[0] = 0
prefix[i + 1] = prefix[i] + nums[i] $$ 利用前缀表计算区间和的方式如下: $$ prefix[right + 1] = \sum_{i = 0}^{right} nums[i] $$ $$ prefix[left] = \sum_{i = 0}^{left - 1} nums[i] $$ 所以把两个式子相减就可以得到: $$ \sum_{i = left}^{right} nums[i] = prefix[right + 1] - prefix[left] $$
-
和为k的子数列 首先还是利用递推公式得到前缀表,之后在遍历的过程中利用哈希表记录前缀表中数字出现的个数,如果要求子串和为
k也就是: $$ prefix[j + 1] - prefix[i] = k $$ 可以转换为: $$ prefix[i] = prefix[j + 1] - k $$ 所以遍历到prefix[j + 1]的时候只需要求解prefix[j + 1] -k的个数即可,所以需要在遍历的过程中记录,这一个题目与两数之和类似,只是两数之和不需要几次次数,这里需要记录次数(所以两数之和可以使用unordered_set但是这里不可以)
cle动态规划解题步骤:
- 确定创建的
dp数组中对应下标元素的含义 - 确定递推公式
- 利用递推公式画出状态图,利用状态图确定数组的初始化
- 确定遍历的方式,比如背包问题中首先遍历背包还是首先遍历物品
动态规划例题
- 斐波那契数 简单的
dp斐波那契数.cpp - 爬楼梯 注意初始化 爬楼梯.cpp
- 使用最小花费爬楼梯 递推公式:
dp[i] = min(dp[i - 1] + cost[i - 1] , dp[i - 2] + cost[i - 2])使用最小花费爬楼梯.cpp - 不同路径 最基本二维
dp,递推公式:dp[i][j] = dp[i - 1][j] + dp[i][j - 1]遍历顺序:顺序遍历即可 不同路径.cpp - 不同路径II 此时递推公式还是上面的,但是此时如果周围的位置存在障碍,那么障碍的位置需要初始化为
0不同路径II.cpp - 拆分整数 这一个题目的递推公式并不是取决于周围的值,而是取决于前面的一切值得,比如对于
n,如果拆分成两个整数就是(i - k) * i, 如果拆分为多个整数那么就是dp[i - k] * k, 这里的k就是假设除去一个k之外看最大的乘积,注意这里的循环索引最大可以到i / 2这是由于均值不等式,所以尽可能平均分配才可以使得乘积最大,所以这一个数字不可能超过i / 2拆分整数.cpp - 不同的二叉搜索树 注意此时的递归函数又是比较难想,此时需要把不同的节点作为头节点,确定左右子树中节点的个数,从而确定总共的方案数量,比如对于
n个节点的树木,当使用j作为头接电脑的时候,左子树中的索引范围为1 - j - 1, 右子树的范围为j + 1 - n所以此时需要加上dp[j - 1] * dp[n - j]不同的二叉搜索树.cpp 01背包系列(背包的容量有限并且每一个物品只有两种状态: 取或者不取):- 01背包二维数组 注意这一个问题很重要,这里
dp[i][j]的含义就是在索引为范围为[0,i]内的元素中任意选取元素并且背包容量为j此时可以获得的最大价值 , 递推公式: 当背包容量无法容纳weight[i]的时候就延续之前的dp[i - 1][j]如果可以容纳weight[i]那么就选取是否装下第i个元素中最大的一个值,也就是:dp[i][j] = max(dp[i - 1][j] , dp[i - 1][j - weight[i]] + value[i])01背包二维数组.cpp - 01背包滚动数组 观察上面的递推公式,发现只是利用
i来控制索引,所以可以把二维数组压缩为一维数组,dp[j]表示背包容量为j的时候可以容纳的最大价值,初始化只需要把所有位置初始化为0即可,只是由于第一次遍历的时候不需要之前的状态(也就是没有物品的时候价值一定是0) ,另外在遍历的过程中,注意外层循环遍历物品,表示控制层数,内层循环遍历背包表示控制背包容量,需要从后面向前面遍历,这是由于遍历的过程中需要使用前面的数据这这里是为了放置覆盖前面的数据,递推公式:dp[j] = max(dp[j] , dp[j - weight[i]] + value[i])01背包滚动数组.cpp
- 01背包二维数组 注意这一个问题很重要,这里
- 分割等和子集 典型的
01背包问题,首先把背包容量设置为sum / 2,之后判断背包所有元素的和是否等于背包容量即可,这里注意weight和value是一致的,都是表示数值大小,递推公式:dp[j] = max(dp[j] , dp[j - nums[i]) + nums[i])分割等和子集.cpp - 最后一块石头的重量II 简单思考一下,粉碎之前两块是否的重量为
y + x,粉碎之后两块石头的重量为y - x, 此时重量的差值为2*x,所以此时只需要令背包的容量为sum / 2, 求出背包的最大可以容纳的石头重量即可,最后答案就是sum - 2*dp[sum / 2],递推公式同上: 最后一块石头的重量II.cpp
01背包总结,01背包的基本问题: 有m中物品,每一种物品的重量为weight[i],价值为value[i], 背包容量为n, 求解背包中可以装下的物品的最大值,这里的一个基本思路就是对于第i个物品分为两种情况讨论(也就是是否需要装这一个物品),从而就可以确定递推公式了,两种表现形式如下:- 二维数组:
dp[i][j]表示任意选取索引范围为[0,i]的物品装入到背包容量为j的背包可以获得的最大价值,遍历方式: 顺序遍历即可(注意此时如果无法装载第i样物品就直接继承之前即可) - 滚动数组:
dp[j]表示背包为j的物品在第i层可以装载物品的最大价值,遍历方式: 首先遍历物品,之后遍历容量并且需要倒序遍历容量(为了放置覆盖上一层在本层中需要使用的值)
- 二维数组:
01背包的用途除了处理传统的背包问题,还可以用于处理给定一个最大值,求解通过装载一定元素到达距离这一个最大值最近点的值
- 目标和 类似于上面的题目,也就是对于求和的题目都应该想到背包问题(背包问题的重点就在于是否放入第
i中物品),但是主要这里的递推公式:dp[i][j] = dp[i - 1][j] + dp[i - 1][j - nums[i]]注意在列初始化的时候如何找到和为0的情况,也就是确定和为0的总共情况数量 - 一和零 注意
01背包的思想就在与是否去除第i个元素,滚动数组和多维数组的方法都是一样的,这里就是多维情况下的01背包问题 , 注意使用三位数组的初始化方式: 一和零.cpp
- 背包问题的种类:
- 完全背包问题: 和
01背包问题不同的地方就在于完全背包问题中元素可以去取出无数次,所以相对于01背包问题利用滚动数组的时候,遍历第二层的时候就需要注意,此时应该正序遍历,就是为了后面可以用到前面的结果,比如也就是遍历到(i,j)的时候就是需要把i装入到背包中,从后面向前面遍历,前面的没有改变(也就是没有装下i) ,但是从前面向后面遍历,前面的元素已经装下i了,后面的元素可以重复装 ,只是遍历顺序不同 完全背包.cpp
- 零钱兑换II 完全背包问题,还是分为第
i个物品是否装入到背包中,递推公式:dp[j] += dp[j - coins[i]], 但是注意测试用例中有超过int的版本,所以需要使用比较大的无符号整型变量 , 所以需要使用uint64_t零钱兑换 1.cpp - 组合总和IV 注意对于完全背包问题:
- 如果需要求解组合数,那么就需要外层遍历物品,内层遍历背包容量
- 如果要求求解排列数,那么就需要外层遍历背包容量,内层遍历物品 组合总和IV.cpp
- 爬楼梯(进阶版) 两种思路: 爬楼梯(进阶版).cpp
- 抽象为背包问题: 注意此时需要求解的是排列数,所以需要首先遍历容量之后遍历背包,递推公式为:
dp[i] += dp[i - j] - 不抽象为背包问题: 此时的递归公式为:
$$ dp[i] = \sum\limits_{k = i - m}^{i - 1} dp[k] $$
- 抽象为背包问题: 注意此时需要求解的是排列数,所以需要首先遍历容量之后遍历背包,递推公式为:
- 零钱兑换 递推公式:
dp[j] = min(dp[j] , dp[j - coins[i]] + 1)注意此时需要注意初始化方式:dp[0] = 0 , dp[j] = INT_MAX,当元素为INT_MAX的时候就表示没有初始化,没有满足要求的组合 零钱兑换 1.cpp - 完全平方数 和上面的题目一个样,只不过这里的目标数组可以看成:
dp[i] = i*i完全平方数字.cpp - 单词拆分 比较难想,注意此时只需要考虑
s,只需要把s划分为不懂得段并且在字典中寻找对应的元素即可 ,dp[j]表示长度为j的从头开始的子字符串是否可以由字典中的元素组成,递推公式:if(us.find(s.substr(j , i - j)) != us.end() && dp[j]) dp[i] = true注意此时由于需要求解排列数,所以需要首先遍历背包(也就是dp),之后遍历元素,也就是i之前的元素 (元素是子串,背包是字符串) 单词拆分.cpp - 多重背包问题 特征就是一个物品可以使用有限次数,解决方法就是把可以使用有限次数的物品拆分为可以使用次数个物品数量,从而转换为
01背包问题,注意01背包问题中是顺序遍历物品的,所以只需要每一次在内层循环中遍历多次物品(也就是在有限次数下遍历物品)即可 多重背包.cpp
- 背包问题总结:
- 背包问题的特点如下:
01背包: 每一物品只可以使用一次- 完全背包: 每一个物品可以使用多次
- 多重背包: 每一物品可以使用有限次
- 背包问题解决方法:
01背包利用二维数组或者滚动数组,注意利用滚动数组的时候需要内层反序遍历背包容量,外层遍历物品- 完全背包利用滚动数组,但是注意遍历背包和遍历物品的顺序,并且遍历背包容量的过程总是从左到右的(比如从
weight[i]到s.size()) ,注意遍历顺序:- 如果是组合数,外层遍历物品,内层遍历背包
- 如果是排列数,外层遍历背包,内层遍历物品(注意条件判断)
- 多重背包问题: 把物品的使用此时看成新的各种物品从而把问题转换为
01背包的问题即可
- 背包问题的特点如下:
- 注意背包问题的精髓在与递推公式:
dp[j] = max(dp[j] , dp[j - weight[i]] + value[i])递推公式表明的是第i件物品时候选取
- 打家劫舍 还是类似于背包问题,就在于是否需要取出第
i个元素,递推公式:dp[i] = max(dp[i - 1] , dp[i - 2] + nums[i]),需要初始化前面两个元素 打家劫舍.cpp - 打家劫舍II 考虑两种情况: 偷第一家,不偷第一家两种情况,可以利用一个数组
dp[i][2]表示相应的情况,dp[i][0]表示不偷第一家的情况,dp[i][1]表示偷第一家的情况,注意初始化方式即可 打家劫舍II.cpp - 打家劫舍III 每一个根节点有两种情况,偷或者没有被偷,所以需要分别讨论这两种情况,所以可以使用一个
vector<int>数字表示这两种情况:dp[1]表示节点被偷,dp[0]表示节点没有被偷走 打家劫舍III.cpp - 买卖股票的最佳时机(特点: 只允许一次买卖) :
- 第一种思路: 在遍历的过程中不断找到前面元素的最小值和后面的元素与最小值的最大差值即可
- 第二种思路: 利用动态规划思想,每一个节点由两种状态,
dp[i][0]为第i天不持有股票的最大利润,dp[i][1]为第i天持有股票的最大利润,递推公式如下:dp[i][0] = max(dp[i - 1][0] , dp[i - 1][1] + prices[i])和dp[i][1] = max(dp[i - 1][1] , -prices[i])买卖股票的最佳时机.cpp
- 买卖股票的最佳时机II (特点: 允许多次买卖)
- 动态规划:
dp[i][j]的含义和上面一样,递推公式:dp[i][0] = max(dp[i - 1][0] , dp[i - 1][1] + prices[i])dp[i][1] = max(dp[i - 1][1] , dp[i - 1][0] - prices[i]) - 贪心算法: 每一次只要后面的价格大于前面的价格就可以叠加了 买卖股票的最佳时机II.cpp
- 动态规划:
- 买卖股票的最佳时机III (特点: 可以买卖有限次数) 定义不同的状态:
0表示不操作 ,1表示第一次买入之后,2表示第一次卖出之后,3表示第二次买入之后,3表示第二次卖出之后 ,之后通过递推公式即可求解 买卖股票的最佳时机III.cpp - 买卖股票的最佳时机IV (特点: 规定了买卖次数),需要定义
2*k + 1中状态,注意递推公式 买卖股票的最佳时机IV.cpp - 买卖股票的最佳时机含冷冻期 这一个题目最难的就是规划状态,注意如何进行状态的规划,首先一定需要清除各种状态之间的转换关系,比如今天卖出就会导致下一天处于冷冻期,所以大体上可以分为持有股票与否,细分又可以范围今天是否卖出股票,是否处于冷冻期等 买卖股票的最佳时机含有冷冻期.cpp
- 买卖股票的最佳时机含手续费 还是两种状态,注意递推公式即可,注意在卖出的时候加上手续费 买卖股票的最佳时机含手续费.cpp
- 股票问题总结: 股票问题引出了动态规划的一种新的题型,也就是同一个节点具有不同的状态,需要利用一个多为数字来记录不同节点的不同状态从而确定相应的递推公式,特别需要注意状态的划分,在状态机中需要具有连续性:
- 买卖股票问题 --> 只可以买卖一次
- 买卖股票问题II --> 可以买卖无数次
- 买卖股票问题 III --> 可以买卖
2次 - 买卖股票问题 IV --> 可以买卖
k次 - 含冷冻期 --> 注意状态机的应用
- 含手续费 --> 注意递推公式的使用即可
- 最长递增自序列 又是一个新的开端,这里的
dp[i]不仅仅与前面的状态有关,同时也和之前的状态有关,注意dp[i]表示以索引为i的数字结尾的最长自序列 最长递增子序列.cpp - 最长连续递增子序列 还是只和前面的状态有关,可以利用动态规划或者贪心 最长连续递增子序列.cpp
- 最长重复子数组 注意这里需要求解的子数组需要是连续的,并且注意定义的时候可以定义:
dp[i][j]表示长度为i的num1子串和长度为1的nums2子串的公共子串的长度,所以递推公式:if(nums1[i - 1] == nums2[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1, 另外也可以使用一维数组模拟(但是注意和一维dp,01背包问题中一样,需要内层反序遍历): 最长重复子数组.cpp (前面的元素只是计算一次 -> 反序,需要多次使用 -> 正序) 此时注意前面的元素不可以重复利用(比如num1[i - 1] != nums2[j - 1]) 的时候需要清空而不是把前面的加上 - 最长公共子序列 注意这里的子序列可以是不连续的,有一点编辑距离问题的意思,这里还是使用
dp[i][j]表示长度为i,j的字符串的最长公共子串,注意dp[i][j]的状态由dp[i - 1][j - 1]和dp[i - 1][j] 和 dp[i][j - 1]决定, 最长公共子序列.cpp - 不相交的线 和上面一样 不相交的线.cpp
- 最大子数组和 动态规划的思路比较好想,类似于前面的递增子序列问题,只需要考虑
j结尾即可,递推公式:dp[j] = dp[j - 1] < 0 ? nums[j] : dp[j - 1] + nums[j], 也可以使用贪心算法: 最大子数组和 1.cpp - 判断子序列 这里还是一样,对于这里的序列的题目(也就是编辑距离的题目),总是考虑新加入到序列中的两个元素的关系(比如这里就是
dp[i]和鄂dp[j]) , 这里的递推公式:if(s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] else dp[i][j] = dp[i][j - 1]判断子序列.cpp - 不同的子序列 还是和其他的编辑距离的题目一样,只需要关注后面两个元素的比较即可:
if(s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] + dp[i][j - 1] else dp[i][j] = dp[i - 1][j]注意此时结果会发生溢出,所以可以使用uint64_t或者unsigned long long不同的子序列.cpp - 两个字符串的删除操作 还是比较常规的编辑距离的问题,这里还是考虑最后一个字母,相等的时候删除前面的字母即可,不相等的时候分为三种情况讨论即可(删除第一个,删除第二个,删除所有) 两个字符串的删除操作.cpp
- 编辑距离 还是典型的编辑距离的问题,还是哪一个方法,
dp[i][j]分别表示长度为i和j的满足要求的子串进行变化需要的次数 , 还是分为两种情况(也就是新加入的两个字母是否想等): 相等就不需要修改了,如果不相等可以分为删除一个,添加一个或者改变一个的策略,根据策略的不同就可以得到递推公式了:dp[i][j] = min(dp[i - 1][j] , dp[i][j - 1] , dp[i - 1][j - 1]) + 1编辑距离.cpp
- 编辑距离总结: 编辑距离问题的通用方法就是,首先可以定义
dp[i][j]为长度分别为i和j的子串或者子数组需要进行题目中给定的变化的最小次数,之后需要分别讨论word1[i - 1] == word2[j - 1]和word1[i - 1] != word2[j - 1]的情况,第二种情况中有需要分别讨论增删改查的最小次数
- 回文子串 经典题目,首先判断回文子串,之后统计回文子串的个数即可,注意
dp[i][j]表示索引范围为[i,j]内的字符串是否为回文子串,这里可以通过判断s[i]和s[j]和之间的字符串确定,递推公式:dp[i][j] = dp[i + 1][j - 1]所以注意遍历顺序从下到上,从左边到右,同时注意此时遍历包含边界所以不需要初始化,另外一种方法就是中心扩散法,测试可以考虑字符串的长度是奇数还是偶数,可以以中间一个为中心或者两个为中心 回文子串.cpp - 最长的回文子串长度 和上面一个题目一个样子,都是需要考虑前后两个方面,此时相等的是的递推公式为:
dp[i][j] = dp[i + 1][j - 1] + 2不相等的时候的递推公式为:dp[i][j] = max(dp[i][j - 1],dp[i + 1][j],注意画出状态图从而确定递推公式的推导方向: 最长的回文子串长度.cpp
单调栈主要用于解决找到后面比前面大的元素的位置,具体的增加规则就是一旦遇到比栈顶元素大或者小的元素就不断弹出栈顶元素知道栈顶元素不大于或者小于当前元素之后把当前元素入栈即可,不同于单调队列
- 每日温度 经典的单调栈的题目,注意每一次弹出的时候都需要初始化结果数组中的元素值 每日温度.cpp
- 下一个最大元素I 这一个题目需要以
nums2为主体,为nums1的元素和索引之间建立哈希表,之后在对于nums2的单调栈中根据哈希表初始化结果数组即可 下一个最大元素I.cpp - 下一个最大元素II 把数组遍历两边即可(或者利用
vector.insert()方法把数组进行拼接也可以),遍历两边的同时需要建立单调栈,在单调栈中注意把当前元素的下标对于数组长度进行取模运算,其他的都是一样的,对于当前元素等于栈顶元素的情况为了两个都可以得到更新可以入栈 下一个最大元素II.cpp - 接雨水 字节的经典面试题,注意此时需要考虑三个元素: 当前元素,栈顶元素和栈顶元素的下一个元素,其实这一个过程可以是连续的,也就是只要遇到当前元素大于栈顶元素就就可以开始计算可以扎装的水了,也就是中间的元素已经计算完毕了,只需要计算前面的元素即可,同时也可以使用双指针法,此时只用关注当前元素最多可以装的水量即可: 接雨水.cpp
- 柱状图中的最大矩形 注意这一个题目和接雨水一样都是考虑中间的元素,接雨水中考虑中间的元素可以接多少雨水,可以考虑两边距离这一个元素第一个大于这一个元素的元素位置,所以在这一个区间中就可以接雨水了,但是这一个题目中如果考虑当前元素那么就表示当前元素最长可以延伸到那里,所以需要找到两端小于这一个元素的元素即可,对于双指针法,接雨水时累加所以不用考虑下标这里是延伸所以需要记录下标,总之关注当前位置即可,看当前位置可以延伸到那里: 柱状图中的最大矩形.cpp
- 单调栈总结:
- 单调栈的作用: 找到当前元素右边和左边第一个小于或者大于这一个元素的元素,注意当前元素就是指的栈顶元素
- 单调栈的实现方式: 利用一个栈,加入元素的同时删除小于或者大于这一个元素的元素即可
- 单调栈的使用方式:
- 搞清楚什么是当前元素也就是栈顶元素,一般利用单调栈可以求解左边和右边第一个小于或者大于当前元素的元素,所以一般用于题目中需要考虑三个元素(需要加入的元素,栈顶元素和栈顶元素的下面一个元素)
- 接雨水中关注接下了多少雨水,所以需要找到左边和右边第一个大于当前元素的元素
- 柱状图中的最大矩阵中关注当前元素最大可以延伸到那里,所以需要寻找左边和右边第一个小于当前元素的元素
双指针法主要用于对于数组中元素的操作,对于元素的不同操作需要确定两个指针指向位置的含义,并且注意指针的移动时机
常见题型总结
- 移除元素 两个指针都从头开始,一个指针(
slow)用于指向满足要求的元素,另外一个指针fast用于遍历元素,遇到满足要求的元素就可以移动到slow的位置 - 反转字符串 一个指针从头开始,一个指针从尾巴开始
- 替换数字 首先进行扩容,一个指针指向扩容之后的尾巴,另外一个指针指向原来的尾巴,从后面向前面遍历,遇到数字就把相应的元素移动到尾巴的位置
- ==反转单词== 首先利用移除元素的方法对于空格进行去重操作,之后整体反转字符串,最后反转每一个单词即可(可以参考
Leetcode上的笔记) - 反转链表 利用两个指针指向相邻的位置,并且在遍历的过程中不断记录遍历到的位置,不断调整指针的指向即可,另外推荐一道题目两两交换链表中的节点,这里确定不了终止位置可以分情况讨论
- 删除链表的倒数第K个元素 首先需要找到倒数第
K个节点的前面一个节点,还是利用双指针法,让一个指针首先走K步,这一个指针走到末尾的时候就是需要的位置,删除操作可以设置虚拟头节点 - 链表相交 首先求解长度,之后和上面一样
- 环形链表 还是定义两个指针,一个指针每一次走
2步,另外一个指针每一次走1步,相遇点和起点距离交点的距离相同(注意推导过程) - 三数之和 首先排序,第一个指针指向需要遍历范围的开头,第二个指针指向第一个指针的下一个位置,第三个指针指向最后一个位置,得到三个数字的和之后就可以和
0进行比较,如果大与0就可以移动最后一个指针,否则移动第二个指针,注意去重操作 - 四数之和 利用四个指针,一个指针用于确定遍历的范围,另外的三个指针重新演绎三数之和即可,
Leetcode上的坑点还是比较多的,比如剪枝的时候还需要判断的当前数字是否大与0,可以参考笔记
回溯算法的本质其实就是穷举法,回溯算法可以用于解决各种问题
- 回溯算法可以解决的问题如下:
- 组合问题(
N个数字里面找出K个数字的集合(部分顺序)) - 切割问题(一个字符串的切割方式)
- 子集问题(一个集合中有多少个符号要求的子集)
- 排列问题(
N个数字按照一定规律进行全排列总共的排列方案种类数) - 棋盘问题(比如
N皇后等)
- 组合问题(
- 解决回溯算法的问题一定要列举状态图,也就是每一层递归之后选择的元素一定需要列出来
- 回溯算法的模板:
void backtracking(参数) {
if(终止条件) {
存放结果
return ;
}
for(选择下一层的元素) {
处理节点
backtracking(路径,目标);
回溯,撤销选择
}
}
组合问题
- 组合 组合问题的模板题,注意这里需要一个变量来控制但前的层数(也就是当前遍历节点的状态),这里使用一个
Index进行遍历,[index + 1 , n]表示这一个节点的下一层 代码: make_pair1.cpp 同时注意利用有效索引范围来进行减枝操作,注意最大有效索引的推导方式,减枝代码如下: make_pair2.cpp - 组合总和III 组合问题,需要一个
startIndex来控制当前遍历到的行数,另外减枝操作,当当前遍历的startIndex向后面循环的时候如果遇到sum > target的情况就需要立刻返回(之后的数字都不满足要求了,注意return和continue的区别) 组合问题III.cpp - 电话号码的字符组合 还是一定需要注意递归的层数的表示方式,这里每一层其实就是每一个字符的集合,所以每一层中只需要遍历字符集合即可,所以递归的参数就是需要传入可以代表字符集合的控制量,这就是当前遍历到的索引值,一定需要明确每一层到底遍历的时什么,可以作状态图: 电话号码的字符组合.cpp
- 组合总和 还是注意此时需要遍历的层数,比如第一层的元素为
arr[1] , arr[2] , arr[3] ...,那么下一层的元素就是arr[1] , arr[2] , arr[3] ...,所以需要利用一个标志来控制遍历到的层数,并且开始位置索引为index,那么下一层的开始索引也是index, 组合总和.cpp - 组合总和II 本题目的不同之处在与待取元素的集合中存在重复的元素,但是有要求最终返回的集合中没有重复元素,所以如果直接利用最简单的组合方法,就会导致组合中的元素重复,比如
[1,7,1] target = 8就会造成答案及集合中的元素重复,所以这里使用一个used数组来标记数据正在使用,如果一个数字正在使用,表示当前遍历到的数字和原来的数字在同样一个树枝上面,如果used的值为false,那么说明当前元素和待遍历元素在同一个树层上面需要跳过,同时注意去重: 组合总和II.cpp
组合问题的总结(三类组合问题):
- 最一般的情况: 数组中的元素不重复并且最终要求集合中的元素不重复,比如
123解决方式: 直接利用一个索引startIndex用于控制当前遍历的层数,每一次递归直接传入curIndex + 1表示遍历后面的元素即可 - 数组中的元素不重复,但是数组中的每一个元素都可以使用多次,但是最终的集合中不可以出现相同的集合, 解决方法: 此时上面一个树层中的开始元素可以再一次和它自己组合,所以此时需要传递一个
startIndex控制遍历索引,同时递归的时候传入curIndex本身作为下一层的开始的位置即可 - 数组中的元素重复,并且要求最终的组合中没有重复的组合,解决方法: 此时不可以重复使用元素,所以利用一个
used来标记相同元素的位置,如果used[i] = false表示当前遍历的相同元素和与它相同的元素在同一个树层,此时直接continue即可,如果used[i] = true,表示当前元素正在使用,所以此时和它相同的元素可以使用 - 另外注意给定元素个数的减枝操作和组合总和的减枝
- 各种情况的状态图如下:
- 元素不重复并且组合不重复:
- 元素不重复并且可以无限次使用要求组合不重复
- 元素重复并且要求组合中的元素不重复(注意
used数组的含义):
分割问题
- 分割回文字符串 注意此时状态图的画法,和上面不同的是,这里需要使用分割线的位置来确定当前层数,至于减枝操作,就是如果遇到当前位置截取的字符串已经不是回文字符串了就可以直接返回了 分割回文字符串.cpp
- 复原IP地址 这里就是分割字符串的操作的基础上面加上了对于子字符串的判断和最终分割的集合中的元素个数进行判断,这里还是需要一个变量来控制层数
startIndex,这一个变量作为该层开始分割的起点,之后从这一个位置开始遍历知道集合的末尾,并且需要一个变量pointNum来标记字符串中.的个数,当个数为3的时候就可以判断剩余的部分是否满足要求即可 代码: 复原IP地址.cpp
- 对于分割问题,这里需要控制最开始的一个切点,在这一个切点开始,从后面的每一个字母后面进行切割操作从而达到回溯的效果,随着层数的底层,切痕的数量也会增加,
startIndex表示上一个切痕后面的一个字母,移动后面的切痕即可截取一段字符串 - 分割回文字符串的树状图:
- 复原
IP地址的树状图:
子集问题
- 子集 注意回溯算法中
for循环用于水平遍历,同时递归用于纵向遍历,所以如果需要收集所有的子集就需要收集树状图中的每一个节点,所以必须在回溯函数的入口处进行节点的收集,明确这一点之后子集问题就变成组合问题了(子集的一个特点就是不重复) 子集.cpp - 子集II 这里的特点就是数组中有重复元素但是最终的结果中没有重复元素(子集的性质),所以这里就可以转换为相应的组合问题 ,需要去重操作 子集II.cpp
- 递增的子序列 这一个题目相对于前面的子集问题对于结果子集和进行限定了(递增并且长度大于
2,所以这一次加入把子集加入到结果集中的时候需要判断长度),同时注意理解树状图,在选择下一层节点的时候上一层节点已经被加入到集合中了,所以只用选择大于这一个节点的下一个节点即可(此时也不需要使用used进行去除重复操作,这是由于每一层都需要去重操作,不是整体的去重复操作),所以可以每一层使用一个unordered_set进行去重复操作 递增的子序列.cpp
- 子集问题总结: 对于只是简单收集子集的问题,只需要收集每一层每一个节点位置的
path即可,根据数组中元素的情况把子集问题转换为对应的组合问题即可,另外如果是需要收集满足条件的子集的情况,此时就需要进行条件判断之后才开始收集元素,同时需要画树状图来看如何去重 - 子集问题
II树状图:
- 递增子序列树状图:
排列问题
- 全排列 还是需要注意树状图的画法,单层递归逻辑中每一次选取的都是集合都是已经选取元素在原来集合中的补集,利用一个
used数组记录元素是否被访问过,如果元素被访问过就跳过访问,另外此时由于不需要排除元素,所以不需要一个下标来控制索引 全排列.cpp - 全排列II 首先还是需要对于已经存在于集合中的元素进行去重复,同时对于一个集合中有重复元素但是要求在最终得到的排列中不可以有重复排列就需要使用
used数组进行去重复,也就是只有元素出现在一个树枝中才可以使用,出现在一个树层中不可以使用,这两个过程中可以使用同样一个used数组(注意对于数组首先进行排序操作) 全排列II.cpp 去重方法还是同一个树层中去除重复元素,当然可以利用set集合进行去重操作
- 总结: 排列问题和子集问题以及组合问题的不同之处就在与需要获取集合中的所有元素,所以此时遍历层数不需要一个索引
startIndex控制,而是需要一个数组used来找到没有访问过的节点(排除子集),其他的细节基本和组合总结的三种类型一致(没有重复,没有重复无限使用,有重复),总结三种问题的差异:- 组合问题: 无序并且一般需要满足特定的条件才可以收集节点
- 子集问题: 无序,如果题目没有说明对于子集的条件,在递归函数入口处收集节点即可
- 排列问题: 有序,每一次回溯都需要遍历数组,不需要索引指示层数
- 全排列的树状图:
- 全排列II树状图(类似于组合II):
其他问题
- 其他问题包含八皇后和棋盘问题等
- 重新安排行程 一道
hard,本题的几个难点:- 如何使用字典顺序来进行地点名称的排列(想到了使用哈希表,但是没有想到哈希表中的第二个元素可以使用
map<string,int>类型对于key进行排序操作) - 如果判断死循环(这里一一开始想的就是如果已经遍历了一条路径就可以直接在对应的
map集合中移除路径了,但是原来使用的vector,所以回溯之后需要加回来就会比较困难,并且两个地点之间存储多张票的情况,所以这里使用map<string,int>叠二个值用于记录次数,每一次只用对于次数进行操作即可) - 如果找到一条满足条件的路径之后立刻返回,这里回溯函数的参数使用
bool类型表示是否找到满足条件的路径,找到就可以返回true代码: 重新安排行程.cpp (实际上回溯就是深度优先遍历的一种体现,只不过需要利用深度优先遍历找到所有满足要求的节点)
- 如何使用字典顺序来进行地点名称的排列(想到了使用哈希表,但是没有想到哈希表中的第二个元素可以使用
- N皇后 注意树状图的画法,也就是每一层的一个递归,需要传入每一层的参数来控制递归层数,想清楚之后很简单 N皇后.cpp
- 求解数独 还是需要在脑子中构建出树状图,由于这里不用收集节点,只需要找到一个位置就可以返回了,所以回溯函数的返回值可以设置为
bool类型,同时由于此时只是需要遍历棋盘找到空缺的位置所以在回溯函数也不需要传入一个参数来控制遍历的层数,最后就是如果对于任意一个节点此时无论填哪一个数字都无法使得数独满足要求就需要返回false求解数独.cpp
- 其他问题总结: 这一部分题目最重要的就是明确每一层回溯的对象,以及如何由上面一层来遍历下面一层(准确来说,下面一层就是上面一层的子集),最好的方式就是构建树状图,明确控制层数的变量以及递归函数的返回值得即可
- 重新安排行程的树状图如下:
N皇后问题中的树状图:
- 数独问题:
回溯算法总结
- 回溯算法可以解决的问题如下:
- 组合问题
- 分割问题
- 子集问题
- 排列问题
- 棋盘问题
- 深度优先遍历(深度优先遍历就是一种回溯算法)
- 总结解决方式:
- 组合问题: 分三种情况,判断需要操作的数组中是否有元素重复以及集合中是否可以有重复元素以及元素是否可以使用多次(另外如果对于组合有条件限制注意减枝)
- 分割问题: 此时需要回溯的变量就是分割线的位置,每一次回溯到一个分割线段之后,下一层的位置就是
[startIndex,i]其中i就是一个循环变量,范围为startIndex -> (size-1) - 子集问题: 类似于组合问题,也就是在回溯函数入口的位置收割函数,如果有特定的条件还需要满足特定的条件,另外注意如果需要明确对于结果进行去重操作和对于每一层进行去重复操作的区别(其实可以混用)(也就是
used数组和unordered_set其实是等效的) - 排列问题: 注意利用
used数组进行去重复操作(本身结果不允许重复),注意此时used数组的作用:已经使用过的元素不可以再一次使用了,此时不需要一个变量来控制循环,另外这一个used数组也可以用于对于结果进行去重复,可以参考之前的排列问题 - 棋盘问题: 明确树状图的画法和递归函数的写法即可
- 深度优先遍历: 回溯函数的返回值为
bool类型,注意什么时候可以找到正确的位置即可
主要记录图的存储方式和两种遍历方式r (
bfs和dfs)另外还有图中的各种例题
- 存储方式:
- 邻接表
- 邻接矩阵
- 遍历方式:
bfs: 广度优先遍历,比如二叉树的层次遍历dfs: 深度优先遍历,也就是回溯算法
例题
- 所有可达路径 深度优先遍历即可,注意深度优先遍历的过程就是回溯的过程,需要遍历所有与当前元素连接的元素,之后就者这一个元素不断递归找到最终需要的元素即可 另外注意图的存储方法有邻接表和邻接矩阵的方式: dfs_邻接表.cpp dfs_邻接矩阵.cpp
- 岛屿的数量 这里只需要定义方向,之后根据方向来进行深度优先遍历和广度优先遍历即可 岛屿的数量_dfs.cpp 岛屿的数量_bfs.cpp
- 岛屿的最大面积 和上面一样 岛屿的最大面积_dfs.cpp 岛屿的最大面积_bfs.cpp
- 孤岛的最大面积 和上面一样,可以首先遍历靠近陆地的所有岛屿
- 沉没孤岛 还是和上面一样的写法
- 水流问题 注意到遍历方法
dfs和bfs的作用就是遍历,可以用于标记可以到达的地方,所以此时只需要从边界标记边界可以访问的每一个节点即可,对于边界上的节点使用dfs和bfs即可 水流问题.cpp - 建造最大岛屿 可以首先把各个陆地使用序号进行标记,标记完成之后就可以找到所有的有水的地方,找到有水的地方之后就可以向两边进行遍历,一旦遍历到标记的地方就可以累加了,之后针对于累加值选取其中的最大值即可 建造最大岛屿.cpp
- 字符串接龙 类似于层序遍历,注意把每一层遍历完成之后才把层数进行累加即可 字符串接龙.cpp
- 有向图的完全可达性 可以利用深度优先遍历或者广度优先遍历,类似于无向图 有向图的完全可达性.cpp
- 岛屿的周长 本质上就是两种遍历方法加上一定的条件,所以这里只需要改变遍历的条件即可
- 如下是并查集中的问题(注意并查集的主要作用就是判断两个元素是否存在于同一个集合中):
- 寻找存在的路径 判断终点和起始点在同一个集合中即可,并查集模板题目 寻找存在的路径.cpp
- 冗余连接II 首先题目中的含义就是每一个节点的入度都是
0或者1,同时由于只有n条边,所以之可能出现有一个入度为2的节点或者入度全部都是1的节点,分别讨论两种情况即可,注意这里并查集的作用只是用于判断是否存在环路,也就是是否可以构成有向树 冗余连接II.cpp - prim算法 注意
prim算法的过程,在这一个过程中需要维护一个minDist数组以及一个最小生成树木(如果需要记录可以使用vector,如果指需要指示是否加入到树中只需要使用 一个bool类型的数组) (注意利用循环开控制获取的边的数量):- 首先在
minDist数字中找到距离当前最小生成树距离最间的节点 - 节点加入到树中
- 更新
minDist数组 prim.cpp
- 首先在
- kruskal算法 还是一样拥有计算最短路径,步骤为:
- 把边按照权值大小排列
- 遍历集合,集合中不构成环的边相连即可(使用并查集) kruskal.cpp
prim算法和kruskal算法要解决的问题都是求解把所有节点串联起来的边的最短总长度,如果节点多,边少的情况可以优先使用kruskal算法,对于节点稀疏的情况可以使用prim算法
- 拓扑排序 解决节点之后的依赖型问题,解决思路也就是加上了一定逻辑的
bfs, 把入度为0节点看成根节点,之后不断删除子结点的入度知道入度为0就可以加入到结果集中了,解题步骤:- 首先记录每一个节点的入度
- 把入度为
0的节点入队列 - 把队列中的元素出队列加入到结果集中并且把这一个节点关联的节点的入度减少
--,如果这些节点的入度减少为0,按么就可以加入到队列中即可 tupu.cpp
- 注意拓扑排序解决节点之间的依赖关系,笔记课程关系或者软件关系之间的依赖关系(比如
Linux的软件依赖管理)
- dijkstra算法 主要用于解决最短路径问题,和
prim算法类似都需要使用到minDist数组,只不过prim算法中的minDist数组的作用是记录每一个节点到达最小生成树的距离,dijkstra算法中是记录者每一个节点到达源点的距离,dijkstra算法的步骤为:- 首先找到距离源点最近的节点(外层需要遍历所有的节点所以需要遍历
1 - n) - 把最近的节点变为访问过的状态
- 更新所有节点到开始点的距离即可 dijkstra_1.cpp
同时注意到第一部中每一次都要遍历找到距离源点最近的节点,所以这里可以使用最小堆来初始化边,每一次都从最小堆中取出边来即可 dijkstra_heap.cpp 但是注意dijkstra算法的特点就是边的权值不可以为负数,这是由于对于已经访问过的节点不可以重复访问,但是回路中出现负值的时候就会导致可能被访问过的节点还需要被重复访问才可以
- 首先找到距离源点最近的节点(外层需要遍历所有的节点所以需要遍历
- Bellman_ford算法 也是求解单源最短路径问题,但是允许有负值权值,重点就是一个松弛操作,一次松弛操作也就是对于一个边,查看起点边到源点的距离是否更新,如果更新就需要更新这一条边了,本质上就是动态规划的一种思想,由于一次松弛其实就是求解和源点一条边相连的边的最短距离(最少) , 如果需要更新所有的边就需要松弛
N - 1次即可 Bellman_ford.cpp 感觉类似于层序遍历,也就是每一层每一层的松弛 - SPFA算法
Bellman_ford算法的队列优化形式,注意在Bellman_ford算法中很多更新都是没有用处的,也就是 虽然每一次更新周围一层的数据,但是还是会更新许多没有用的位置,所以可以进行顺序更新,也就是遍历到那里就可以更新到哪里,由于上面说过类似于层序遍历,所以可以使用队列进行优化,也就是把松弛过后的节点加入到队列中,这些节点后面的节点才值得更新 SPFA算法.cpp - Bellman_ford算法判断负权回路 负权回路(也就是一个通路中所有边的权值为负), 注意到
Bellman_ford算法其实就是一个不断松弛的过程,所以在松弛的过程中如果松弛到N次还是回到是最短路径减少那么就说明此时存在负权回路,对于spfa算法,如果一个节点入队N次并且权值减少那么也说明形成了负权回路 - Bellman_ford算法判断单源最短路径
Bellman_ford算法的本质就是bfs之前由于只需要把每一条边松弛N次即可,所以没有体现广度优先搜索的特点,这里要求中间只可以经过K个城市这一个限定就使得广度优先遍历只需要遍历K层即可,并且注意每一次使用的minDist都需要是上一层更新的minDist防止互相依赖关系,并且使用spfa的时候就像树的层序遍历一样记录队列中的节点依次出队即可(可以利用一个visited数组防止重复入队)
- 注意
dijkstra算法和Bellman_ford算法都是用于解决单元最短路径问题的,两种算法都需要minDist数组,dijkstra算法类似于prim算法,只是对于minDist的定义和更新方式不同,Bellman_ford注意对于边的一个松弛操作,同时也需要掌握dijkstra的优先队列优化方法和SPFA算法, 由于都是求解最短路径所有基本思想都是bfs
- floyd算法
floyd算法要解决的问题就是多源最短路径长度,本质上还是动态规划,这里dp数组的含义就是:dp[i][j][k]表示从i -> j以k为中间节点的最短距离,递推公式为:dp[i][j][k] = min(dp[i][j][k - 1] , dp[i][k][k - 1] + dp[k][j][k - 1])有递推公式,可以看出需要从三维平面的下面向上面遍历,同时也可以使用二维数组来模拟这一个过程,就像背包问题中一样(注意回忆01背包和完全背包问题的解法) floyd.cpp - Astar算法
A*算法的核心算法就是bfs,只不过是根据每一条边的一个权值进行排序操作,权值小的就可以放在前面首先取出,这一个过程可以使用一个小根堆来代替队列即可 Astar.cpp
记录字节跳动青训营刷题任务中比较好的题目
- 计算子串UCC个数 难度太大了,放弃 code
- 匹配创意模板标题 思路正确但是调试太费劲了,首先利用栈提取模板,之后把每一个元素和模板中的元素进行比较即可,注意前缀和后缀 匹配创意模板标题.cpp
主要用于记录
Leetcode中利用栈与队列这两种数据结构进行求解的题目解法
题目总结
- 用栈实现队列 定义两个栈
in,out,当插入元素的时候直接插入到in中,当需要弹出元素的时候,首先判断out中是否有元素,有元素直接弹出,没有元素依次弹出in栈中的元素到out栈中并且弹出out栈中的元素 - 用队列实现栈 利用一个队列就可以实现了,在插入元素的时候首先插入元素,然后把之前的元素全部出队并且重新入队列(利用
que.size() - 1次循环完成即可) - 有效的括号 栈的最常见的应用,如果遇到满足要求的两个括号就可以同时出栈了,遇到不同的括号就直接把字符压入到栈中,最后判断栈中的元素是否为空即可
- 删除字符串中的所有相邻重复项 这里还是和上面一样的策略,但是不同的是这里可以直接把
string类型作为栈来使用,本来string类型就类似于vector<char>类型 - 逆波兰表达时求值 对于当前元素,如果是数字直接使用
stoi函数入栈,如果是符号,就可以取出栈顶的两个元素进行相应的运算之后在压入到栈中即可 - 滑动窗口最大值 一道
hard,自己构造单调队列进行求解即可,单调队列中的元素按照元素之间的某一个大小关系来决定出队的顺序而不是按照插入的顺序来确定出队和入队的关系,构造方式: 笔记 - 前K个高频元素 向这一种求解前面的几个元素的题目一般都可以使用堆的数据结构进行求解(就是优先队列的底层实现),注意
C++中的优先的队列的自定义方式,可以参考笔记查看解法,另外这里使用到了利用unordered_map进行数据统计的操作 笔记:
auto cmp = [](const T& a , const T& b) -> bool { return a < b; };
priority_queue<T , vector<T> , function<bool(const T& , const T&)>> pq(cmp);
注意滑动窗口的策略,也就是加入元素和删除元素的规则,注意滑动窗口一般与哈希表一起考查(查找元素是否存在使用
unordered_set,对应关系使用unordered_map)或者大数组,这里我把题目分成两种类型
第一种是求解 "最大子串",求出所有满足要求的位置: 这一类题目需要通过一个while循环找到满足要求的区间,找到满足要求的区间的时候就可以直接更新结果了
- 最大无重复字符子串 这里的要求是哈希表中不包含加入的字符,所以需要不断增加右边界从而满足要求
- 所有字母异位词 这里的要求是哈希表中字符出现次数减少为
0,同时收集字符的条件就是字符长度为目标字符串的长度 第二种是求解 "最小子串" , 或者找出满足条件的区间,这一各类题目需要破坏已经满足满足的条件,从而不断找到最终可以满足题目条件的临界值,比如: - 最小覆盖子串 条件是滑动窗口中包含目标子串,需要破环这一个条件
- 长度最小的子数组 条件是总和大于目标值
矩阵操作一定需要注意边界条件和变化公式等
- 矩阵置0:
- 空间复杂度为
O(m + n): 准备两个unordered_set放入需要置为0的行和列之后把这些行和列相应的位置置为0即可 - 空间复杂度为
O(1): 利用两个辅助变量,分别记录第一行或者第一列是是否需要置为0,之后在遍历的过程中如果遇到需要置为0的位置就可以直接令martix[i][0] = martix[0][j] = 0即可,最后遍历矩阵把需要置0的位置置为0
- 空间复杂度为
- 螺旋矩阵 模板挺多的,感觉最简单的模板是: 记录矩阵中的数字个数 + 转圈,利用四个变量记录边界位置即可
- 矩阵旋转 本质就是矩阵变化,两种方法:
- 利用辅助变量来进行矩阵的逆转: 矩阵旋转的变化公式为(注意观察一个数字的变化): $$ matrix[row][col] -> matrix[col][n - 1 - row] $$ 此时可以利用一个临时变量记录边界位置: $$ temp = matrix[row][col] $$
- 接下来确定 哪一个位置旋转到
matrxi[row][col](上面一个式子的逆变化) $$ matrix[row][col] = matrix[n - 1 - col][row] $$ 持续变化: $$ matrix[n - 1 - col][row] = matrix[n - 1 - row][n - 1 - col] $$ $$ matrix[n - 1 - row][n - 1 - col] = matrix[col][n - 1 - row] $$ $$ matrix[col][n - 1 - row] = matrix[row][col] = temp $$ 此时就构成了一个循环,不断进行上述的操作即可(奇数 or 偶数) - 同时需要确定开始区域,开始区域如下:
- 第二种方法: 矩阵变化,首先水平翻转之后转置即可: $$ 水平翻转: matrix[row][col] -> matrxi[n - 1 - row][col] $$
$$ 转置: matrix[row][col] -> matrix[col][row] $$ 所以进行复合变化可以得到: $$ matrix[row][col] -> matrix[col][n - 1 - row] $$ 刚好得到矩阵的旋转公式 4.二维矩阵搜索 把矩阵看成一个二叉搜索树即可,可以把左下节点或者右上节点当成开始节点,那么就可以得到:
- 如果
matrix[i][j] < target -> j ++ - 如果
matrix[i][j] > target -> i --即可,最终不断搜索就可以找到目标节点
d> 贪心算法的核心思想就是由局部最优解推出全局最优解,所以每一次指用考虑局部最优即可,如果要想证明局部最优可以推出全局最优可以使用数学归纳法或者反证法
- 分发饼干 此时的贪心策略就是尽量把小饼干发放给胃口小的孩子,这样就可以找到局部最优算法,此时只需要利用两个指针,一个指针指向孩子另外一个指针指向饼干,在遍历的过程中不断找到小的饼干喂给孩子即可 分发饼干.cpp
- 摆动序列 可以画图理解,此时局部最优算法就是把单调坡上面的所有数字删除,只是留下局部峰值中的数据,例如此时使用
preDiff记录前面两个数字的差值,curDiff记录当前数字和后面数字的差值,当preDiff与curDiff异号的时候就表示遇到了局部峰,此时就可以把结果进行自增操作了,但是注意这里的细节比较多,比如:- 遇到平坡并且最有一个元素出现峰值的情况,所以此时要想要把记录平坡中的最后一个元素,允许
preDiff = 0 - 对于第一个元素,可以默认是一个局部峰(一定包含在最终的结果中,可以证明),所以可以把
preDiff设置为0从而得到这一个局部峰并且把result初始化为1表示第一个元素是一个局部峰 - 对于平坡并且单调的情况,注意此时只有早出现波动的时候才可以更新
preDiff = curDiff代码 摆动序列.cpp
- 遇到平坡并且最有一个元素出现峰值的情况,所以此时要想要把记录平坡中的最后一个元素,允许
- 最大子数组和 非常经典的一个题目,贪心策略: 当当前的总和小与
0的时候还不如从下面一个元素重新开始加,但是注意这里有一个小坑,也就是不可以在当前元素和最大元素进行比较的时候设置count = 0,否则就会导致最大值可能为0,所以智能在最后把总和设置为0(代码随想录的做法) ,当然也可以直接把总和设置为当前数字并且进行比较也是一样的 最大子数组和 1.cpp - 买卖股票的最佳时间II 贪心策略有两种:
- 由于利润是累加的,所以可以只要后面一天的利润大于前面一天的利润就可以卖出股票了
- 或者把数组想象成一个山峰,在谷底买入股票,在山顶卖出股票,但是代码实现可能较为困难 另外注意写代码的时候不要害怕对于双指针的移动,可以看一个例子,并且根据这一个例子找出指针移动的规律,对于边界条件注意在每一次改变变量的时候添加即可,如果出错大不了直接改 代码: 买卖股票的最佳时间II.cpp
- 跳跃游戏 局部最优: 获取到最大覆盖的索引的位置,每一次不断更新最大索引的位置,并且遍历当前位置到最大索引的所有元素,如果遇到当前元素可以覆盖到数组末尾就可以返回
true了,当然也可以使用一个范围[startIndex,endIndex],每一次计算这一个范围可以到达的下一个索引范围即可 代码: 跳跃游戏.cpp - 跳跃游戏II 此时还是需要基于范围,每一次范围就表示走一步了,还是采用两种方法:
- 自己自创的方法,范围扩散,每一次利用一个
startIndex记录当前位置开始的索引,endIndex用于记录最大索引范围,每一次遍历这一个范围内的数字并且更新这两个值即可 - 代码随想录的方法,利用一个变量记录当前可以遍历到的范围,利用一个索引记录下一步可以到达的索引,当走到当前索引的位置的时候就可以更新步数了,更加接近实际 代码 跳跃游戏II.cpp
- 自己自创的方法,范围扩散,每一次利用一个
- K次去反之后最大化的整数和 这里还是两种贪心的思路: 第一种就是不断找到最小的元素并且把最小的元素反转即可,另外一种思路就是首先按照绝对值排序,对于绝对值大的元素如果小与
0就可以反转,如果最终反转此时没有使用完毕,就可以堆对这其中某一个元素多次反转,如果最后还剩下一次就可以反转绝对值最小的以一个元素 K次取反之后的最大化的整数和.cpp - 加油站 三种方法: 暴力解法(写出来了,但是测试用例中二十万个
0... ) , 贪心算法:- 全局最优: 从
0出发计算所有的差值总和,如果得到所有的差值总和大小小与0说明不可能找到对应的索引,同时在这一个过程中记录累加值的最小量,之后从后面向前面遍历直到找到可以完全填补min的位置就可以返回了(这一个位置一定可以填补最小值) - 局部最优: 局部最优的特点就是不断调整策略,所以局部最优的方法就是如果遇到当前的累加值
<0说明这一个区间的前面一个区间的任意一个位置开始都不可以(注意此时前面的累积值都是大于0的),所以此时需要把当前总和设置为0重新开始从新的索引位置开始对于元素执行相加操作 代码: 加油站.cpp
- 全局最优: 从
- 分发糖果 一道
hard,解法就是由于这里事物有两面性,所以此时需要考虑左边和右边的情况,考虑右边孩子大于左边孩子的情况从左边向右边遍历,考虑左边孩子大于右边孩子的情况需要从右边向左边遍历,遍历的过程中注意后面一个遍历的过程中每一个孩子糖果数量的确定方式就是只用满足比两边的孩子的糖果数量多即可,所以此时的递归公式为 :candyVec[i] = max(candyVec[i] , candyVec[i + 1] + 1)代码: 分发糖果.cpp - 柠檬水找零 经典的贪心算法,这里注意对于
10元只可以使用一个5元进行找零,对于20元可以使用一个10元和一个5元或者3个5元,所以需要尽可能多的保留5元,遇到不同的情况具体处理即可 柠檬水找零.cpp - 根据身高重建队列 这里还是有两个维度,首先考虑身高维度按照身高排序,之后按照次数把相应的元素插入到队列中的相应位置即可(注意此时前面的元素已经插入好了),此时需要使用
list进行元素的插入减少插入元素的时间复杂度 根据身高重建队列.cpp - 用最少的箭引爆气球 这里一定需要站在局部性的角度考虑问题,首先可以考虑如果前后两个气球可以被同一个箭击破,那么需要满足的条件就是
points[i][0] <= points[i-1][1],在考虑三支箭,那么就需要求解前面两支箭的最小的一个右边边界值,之后判断第三支箭的头部位置和这一个边界值之间的关系即可 用最少的箭引爆气球.cpp - 无重叠区间 注意这里还是考虑局部性,对于两个区间,如果重叠,那么一定是第二个区间的第一个元素小与第一个区间的最后一个元素,所以此时需要删除一个区间,这里选择删除哪一个区间可以根据哪一个区间的右边边界最小,这样 就可以尽量避免空位 无重叠区间.cpp
- 划分字母区间 这里给出两种思路:
- 第一种: 首先记录每一个元素出现的次数,之后利用一个集合
unordered_set在遍历的过程中记录遍历到的元素,如果某一个元素遍历到就可以把它出现的次数减少,当次数减少为0的时候就可以把元素从集合中移除了,此时就可以此时结果了 - 第二种: 首先记录每一个元素出现的最远索引的位置,之后在便利的过程中不断更新右边边界为最远索引,当遍历到右边边界的位置的时候就可以记录结果了 代码: 划分字母区间.cpp
- 第一种: 首先记录每一个元素出现的次数,之后利用一个集合
- 合并区间 一定需要总结区间相关问题的套路:
- 对于区间相关的问题,首先需要对于左边边界进行排序,排序之后考虑局部性,也就是对于两个区间,区间重叠的判断条件就是:
intervals[i][0] <= end,之后根据区间是否重叠两种情况分别对于end进行不同的更新并且记录结果即可 代码: 合并区间.cpp
- 对于区间相关的问题,首先需要对于左边边界进行排序,排序之后考虑局部性,也就是对于两个区间,区间重叠的判断条件就是:
- 单调递增的数字 还是需要不断模拟,这里还是提供两种思路:
- 从前向后面遍历,比如
344521中,一旦遇到第一个递减的位置,这里也就是2的位置,此时就需要找到最前面的一个5,把这一个位置减少一,之后把这一个位置之后的位置全部都设置为9即可 - 从后面遍历到前面,记录最前面的一个递增的位置,此时只需要把此时突然递增的位置减少一并且把后面的位置都设置为
9即可,注意这里的条件是strNum[i - 1] > strNum[i]没有相等 代码: 单调递增的数字.cpp
- 从前向后面遍历,比如
- 监控二叉树 一道名副其实的
hard,如果第一次做基本上做不出来(其实第二次做也可能做不出来) 注意到每一个节点有三种状态并且注意根节点的处理方式即可,三种状态0 --> 没有覆盖 1 --> 有摄像头 2 --> 被覆盖了,这里空节点不需要被覆盖所以可以返回2,所以此时需要利用后序遍历的方式遍历二叉树,并且根据返回结果的状态来确定当前节点的状态,但是注意根节点的覆盖方式! 代码: 监控二叉树.cpp
链表的题目一般都可以使用递归方法,但是注意一定要清楚链表操作,时用迭代法更加清晰
- 相交链表 双指针法,两个指针分别从
A和B的头节点开始走到A的尾巴的节点从B的头节点开始,另外一个指针也是一样的,当两个指针相等的时候就可以退出了:- 长度相同,同时走到终点: 如果没有交点就返回
nullptr - 长度不相同,那么就会同时走相同的距离,如果相遇得到的位置就是交点或者
nullptr
- 长度相同,同时走到终点: 如果没有交点就返回
- 反转链表 经典题目,迭代法或者递归法,利用两个指针即可,注意记录后面一个节点即可
- 回文链表 首先找到链表的中点,把中点和后面的部分反转,之后一个指针从头节点,另外一个指针从中间节点反转之后的位置开始查看位置是否相同
- 环形链表 两个指针,一个快指针,一个慢指针,
fast的速度总是slow的两倍,如果相遇那么就是有环 - 环形链表II 上面的相遇点和头节点距离入环点的距离相同
- 合并两个有序链表 最好使用虚拟头节点,递归法和迭代法都可以使用,这里可以使用
l1为基准,如果当前节点小于l1的位置,那么就需要把l2的节点插入到l1对应节点的前面,注意l2的节点保持在虚拟头节点的位置即可,l1的位置不断移动即可,使用递归法更简单,判断当前节点大小即可 - 两数相加 递归法很妙,使用三个参数:
l1 , l2 , carry(进位)作为入参,并且在l1为空的位置交换两个链表头节点是重点,迭代法中判断终止的条件就是两个都为空并且carry为0, 注意此时循环的迭代过程(相当于新建了一个链表) - 删除链表倒数第N个节点 设置虚拟头节点,
fast节点从头节点的位置开始走N个位置 ,slow开始走,当fast走到尾节点的位置,slow的位置就是需要删除的节点的前面一个位置(虚拟头接电使用栈空间,利用RAII的思想) - 两两交换链表中的节点 使用递归法或者迭代法,注意新的头节点是
head -> next, 所以需要进行如下操作:auto newHead = head -> next,head -> next = swapPair(newHead -> next),head -> next = new Head, 使用递归法还是用我的方法的,题解里面的方法不好理解 k个一组反转链表 可以使用递归或者迭代法,利用递归法可以每一次判断长度,利用迭代法首先记录长度,之后不断把链表分组反转即可,这里可以利用虚拟头节点来此操作链表- 随机链表复制 利用一个哈希表存储此时的链表和原来链表之间的关系即可
- 排序链表 使用归并排序,可以时用迭代法实现 #TODO可以使用快排实现
- 合并K个升序链表 两种方法:
- 利用最小堆,把所有链表的头节点都加入到最小堆中,之后不断取出最小堆的顶端节点,并且把顶端节点的下一个节点加入到堆中(类似于合并链表)
- 分治法: 相当于不断把数组分割开,知道只有一个链表此时就不需要分割了,需要使用递归和链表的合并(此时最后利用栈空间创建一个新的头节点并且不断向头节点中插入元素即可)
- LRU缓存 可以参考
Java中的LinkedHashMap, 利用哈希表 + 双向循环链表来存储数据,其中哈希表用于存储key到节点的映射关系,双向循环链表记录插入时间的关系,比如不经常使用的节点就需要插入到后面,最终删除的时候也就只用删除后面的节点即可
ar
pytorch安装: 官方复制相关的命令 https://pytorch.org/get-started/locally/
ear
anaconda
参考: anaconda基本使用
- 创建虚拟环境
conda create --name myenv
conda create --name myenv python=3.8 # 指定python版本
- 激活虚拟环境
conda activate myenv
- 退出虚拟环境
conda deactivate
- 查看所有环境
conda env list
- 复制环境
conda create --name my-clone --clone my-env
- 删除环境
conda env remove --name my-env
- 安装包
conda install package_name
conda install package_name=version # 指定版本
- 更新包
conda update package_name
- 卸载包
conda remove package_name
- 查看安装的包
conda list
- 其他命令
conda --version
conda --help
conda search package_name # 搜索包
conda clean --all # 清除所有不需要的包
jupyter notebook
jupyter notebook常用快捷键: https://blog.csdn.net/mighty13/article/details/118395979
强化学习中的概念
-
状态(
state): 表示当前所处的环境 -
行为(
Action): 表示智能体可以作出的动作 -
智能体(
Agent): 表示可以作出动作的实物 -
策略(
policy): 也就是 $\pi$ 函数,也是强化学习的目标 $\pi(a | s) = \mathbb P(A = a| S = s)$ ,也就是根据各种行为的条件概率来确定下一步需要采取的动作 -
奖励(
reward): 表示采取相关的行为之后就会得到相应的奖励 -
状态转义(
state transition): 从一个状态转移到另外一个状态 $p(s^{'}|s,a) = \mathbb P(S^{'}|S = s,A = a)$ -
交互方式:

-
注意随机性:
- 根据策略函数 $\pi(a|s)$ 会根据环境随机得到下一步动作
- 根据状态转义函数 $\mathbb P(S^{'}|S ,a)$ 会随机进入下一个环境
-
轨迹: $s_1 -> a_1 -> r_1 -> s_2 -> a_2 -> r_2 ... s_T -> a_T -> r_T$
-
回报(
Return): 表示从当前时刻开始的奖励一致累积加到游戏的最后时刻的奖励之和,也就是: $U_t = R_t + R_{t + 1} + R_{t + 2} + R_{t + 3} + ...$ -
折扣回报(
Discounted): 这是由于当前的奖励的权重需要大于之后奖励的权重,所以定义折扣回报: $U_t = R_t + \gamma R_{t + 1} + {\gamma}^2 R_{t + 2} + {\gamma}^3 R_{t + 3} + ...$ (折扣率是超参数) -
给定环境,回报依赖于随机变量: $A_t , A_{t + 1} , A_{t + 2} , A_{t + 3} ...$ 和 $S_t , S_{t + 1} , S_{t + 2} , S_{t + 3} ...$
-
动作价值函数: 由于强化学习的目标是让当前的回报最大,所以引入了动作价值函数的概念: $$ Q_{\pi}(s_t,a_t) = \mathbb E[U_t | S_t = s_t , A_t = a_t] $$
-
动作价值函数反映了,当前环境$s_t$下采取$a_t$动作,产生的回报的均值,也就是随机变量是 $A_{t + 1} , A_{t + 2} ...$ 和 $S_{t + 1} ,S_{t + 2}...$ 定义 $Q^$函数如下 $$ Q^(s_t,a_t) = max_{\pi}Q_{\pi}(s_t,a_t) $$
-
状态价值函数: 反映了当前环境 $s_t$下采取不同行为的动作价值函数的均值: $$ V_{\pi}(s_t) = \mathbb E_A[Q_{\pi}(s_t,A)] = \sum\limits_a{\pi}(a|s_t)Q_{\pi}(s_t,a_t) $$
-
如果动作是连续的,就可以利用如下公式: $$ V_{\pi}(s_t) = \mathbb E_A[Q_{\pi}(s_t,A)] = \int{\pi}(a_t|s_t) Q_{\pi}(s_t,a_t) da $$
-
强化学习的过程:
- 学习策略: $\pi(a_t|s_t)$ (对于策略,输入环境即可得到动作$a_t$ )
- 学习动作价值函数: $Q_{\pi}^*(s_t | a_t)$ (选出最好的动作)
-
gym是类似于强化学习的训练集,也就是可以利用gym类似于环境,可以利用其中的环境
价值学习
- 目标近似 $Q^(s,a)$ , 当前需要采取的动作就是 $a = argmax_aQ^(s,a)$
DQN: 利用一个神经网络来近似与 $Q^*(s,a)$ 函数,只要训练次数足够多就可以使得足够近似- 利用
DQN进行强化学习的过程如下:
TD算法: 需要每一次完成一个动作,估计实际的收益和预测的收益,利用损失函数求解梯度,从而利用梯度下降从而更新模型参数,实际上也是一种深度学习算法,通过学习$Q^*$ 函数从而求解参数- 深度强化学习中: $$ Q(s_t,a_t;\mathbf w) = r_t + \gamma Q(s_{t + 1},a_{t + 1};\mathbf w) $$
- 利用这一个关系就可以进行递推公式,所以可以利用如下的关系式来确定参数
- 下图中的
TD target表示表示实际值,通过与预测值求解损失函数的方法确定下降梯度:
策略学习
- 利用神经网络来近似策略函数 $\pi(a|s)$ 输入状态 $s$ 输出动作 $a$
- 利用神经网络来确定策略网络 $\pi(a | s;\mathbf \theta)$ ,可以利用
softmax最后得到一个分布列 - 主要是对于状态价值方程:
- 算法的工作流程:

- 其中计算 $q_t = Q_{\pi}(s_t,a_t)$ :
- 可以利用一个整个过程,对于这一个过程直接计算 $Q_{\pi}(s_t,a_t)$ 也就是 $E[U_t]$ 即可
- 另外一种方法就是利用神经网络近似
- 神经网络需要预测的策略函数可以写成: $$ V(s;\mathbf \theta) = \sum_a{\pi}(a|s;\mathbb \theta)Q_{\pi}(s,a) $$
- 利用梯度上升函数即可计算: $$ \mathbf \theta = \mathbf \theta + \frac {\partial V(s;\mathbf \theta)} {\partial \mathbf \theta} $$
- 两种导数形式如下:

Actor-Critic 方法
-
Actor策略网络(决定动作) -
Critic价值网络(评价动作) -
基本模型如下: $$ V_{\pi}(s) = \sum_a{\pi}(a|s)Q_{\pi}(s,a) = \sum_a{\pi}(a|s;\mathbf \theta) q(s,a;\mathbf \omega) $$
-
其中后面两个是利用神经网络近似得到的函数
-
策略网络: 输入状态,输出各种特征的概率,为了得到更大的回报
-
价值网络: 输入状态和动作,输出回报,从而使得评判更加精准
-
对于价值网络,可以使用
TD算法来训练,需要使得打分更加精准
-
利用策略梯度算法使得策略网络可以得到的回报更大

-
使用
Actor-Critic算法的步骤:
-
最后的 $q_t$ 也可以使用 $\delta _t$ ,最好使用后者
-
最后的目的是学习策略网络
实例(围棋游戏)
- 状态: 存储一个棋盘和上面的棋子,可以使用一个
tensor,大小为19*19*2 - 动作: 可以使用一个一维的
tensor记录为之即可,比如n表示放置到第n个位置
蒙特卡诺方法
- 表示利用随机变量来估计目标值: 比如利用随机变量估计$\pi$
- 近似求解积分:
$$ 对于 F(x) = \int_a^bf(x)dx 可以利用如下方法求解积分,在区间里面取得x_1,x_2...,求解 (b - a)\frac{1}{N}\sum f(x_i) 即可近似F(x) $$
Q-learning算法
- 用于求解 $Q^*(s_t,a_t)$
- 核心公式: $$ Q^(s_t,a_t) = \mathbb E[R_t + \gamma max_a Q^(S_{t + 1},a)] = r_t + \gamma max_aQ^*(s_{t + 1},a) $$
- 神经网络的
Q-learning算法:
A2C算法
机器学习
机器学习中的基本概念
- 特征: 表示需要预测对象的特点(比如芒果的大小,形状颜色等特征信息)
- 标签: 表示最终需要预测的变量(比如芒果的甜度等信息),可以是离散的也可以是连续的
- 一个标记好特征以及标签的对象可以看成一个样本
- 一组样本构成的集合称为数据集(Data Set).一般将数据集分为两部分: 数据集也训练集和测试集.训练集(Training Set)中的样本是用来训练模型的,也叫训练样本(Training Sample),而测试集(Test Set)中的样本是用来检验模型好坏的,也叫测试样本(Test Sample)
- 可以使用一个
D维的向量来表示样本的特征,叫做特征向量: $$ {\mathbf x} = [x_1 , x_2 , ...,x_D]^T $$ - 训练集由
N个样本组成,每一个样本都是独立同分布的,记为: $$ {\mathcal D} = {({\mathbf x}^{(1)} , {\mathbf y}^{(1)}) , ({\mathbf x}^{(2)} , {\mathbf y}^{(2)}) , ... , ({\mathbf x}^{(N)} , {\mathbf y}^{(N)})} $$ - 给定训练集需要从函数集合
$$
\mathcal F = {f_1(\mathbf x) , f_2(\mathbf x) ... }
$$
中找到一个最有的函数
f(x)来近似表示特征向量与标签之前的关系,也就是: $$ \widehat y = f^(\mathbf x) $$ 或者条件概率 $$ \widehat p(y|\mathbf x) = f_y^(\mathbf x) $$ - 寻找着一个最优函数的过程叫做学习,一般通过学习算法来完成
- 一般可以通过测试集确定模型的准确率:

- 机器学习的基本流程:
机器学习的三要素
模型
- 也就是上面说的最优函数,一般可以从一个函数集合(这里成为假设空间中找到这一个最优模型): $$ {\mathcal F} = {f({\mathbf x};\theta)|\theta \in \mathbb R^D} $$
- 线性模型: $$ f(\mathbf x ; \theta) = {\mathbf \omega}^T{\mathbf x} + b $$
- 非线性模型:

学习准则
- 一般可以通过期望风险来衡量,定义为: $$ \mathcal R(\theta) = \mathbb E_{(x,y) - p_r(x,y)}[\mathcal L(y,f(\mathbf x;\theta))] $$
- 其中也就是测试集中每一个点的风险函数的取值的均值
损失函数
- 用于衡量模型预测与真实标签之间的差异
- 常用的损失函数:
01损失函数:
- 平方损失函数:
- 交叉熵损失函数(一般用于分类问题),类似于期望

风险最小化
- 一般利用经验风险评估模型的准确性:

- 同时为了防止过拟合,一般可以引入参数的正则化来限制模型的能力,这一种准册叫做结构风险最小化:
- 欠拟合,过拟合和正常的情况:
优化算法
- 可以看成利用寻找最优模型的算法,是一种迭代算法(寻找经验风险
or结构风险最小的点)
梯度下降法
- 利用如下公式进行参数的迭代:
提前停止
- 划分出验证集,每一次将得到的模型在验证集上面进行验证,如果发现验证集中的错误率不再下降就会停止,可以防止过拟合
随机梯度下降
- 为了防止每一次迭代都需要计算训练集中每一个样本的偏导数,所以可以参用随机梯度下降法,也就是随机选择一个样本进行梯度下降:

批量梯度下降
- 也似乎为了减少梯度下降的复杂度,每一次只是抽取一个小部分的元素
机器学习算法的种类
- 监督学习(回归,分类,结构化等问题)
- 无监督学习
- 强化学习
- 三者的差别:

- 交叉验证:

线性模型
Logistic回归
- 首先回归问除了需要获取一个判别函数($f(x; \mathbf \omega) = {\mathbf \omega}^T {\mathbf x} + b$ ) 之外还需要确定一个决策函数$g(x)$ 用于把判别函数的结果映射到一个有效的类别上
Logistic回归可以利用于解决二分类的问题,考虑后验概率: $$ p(y = 1 | {\mathbf x}) = g(f({\mathbf x}; {\mathbf \omega})) $$Logisitc回归中使用Logistic函数作为激活函数,比如标签$y = 1$ 的后验概率为 $$ p(y = 1 | x) = \sigma({\mathbf \omega}^{T}{\mathbf x}) = \frac{1}{1 + \exp(-{\mathbf \omega}^{T}{\mathbf x})} $$- 这里的$\omega$ 增广权重矩阵 , $\mathbf x$ 是增广特征矩阵
- 从而可以得到: $$ p(y = 0 | {\mathbf x}) = 1 - p(y = 1 | {\mathbf x}) $$
- 结合上面两个式子可以得到: $$ {\mathbf \omega}^{T}{\mathbf x} = log{\frac{p(y = 1 | {\mathbf x})}{p(y = 0 | {\mathbf x})}} $$
- 参数学习的过程中使用交叉熵函数作为损失函数并且利用梯队下降算法来优化参数
- 后验概率为:
$$
\widehat y^{(n)} = \sigma({\mathbf \omega}^{T}{\mathbf x}^{{n}})
$$ - 所以可以得到:
$$
p_r(y^{n} = 1 | {\mathbf x}^{n}) = y^{(n)}
$$ $$ p_r(y^{n} = 0 | {\mathbf x}^{n}) = 1- y^{(n)} $$
Softmax回归
Softmax中预测最终结果属于类别c的条件概率为,其中x为样本: $$ p(y = c | \mathbf x) = softmax({\mathbf \omega}c^T{\mathbf x}) = \frac{exp(\mathbf \omega_c^T{\mathbf x})}{\sum\limits {c' = 1}^{C} exp({\mathbf \omega}_{c'}^T{\mathbf x})} $$- 决策函数使用如下函数:
- 但种类为
2的时候就会退化成Logistic回归 - 利用向量形式可以表示为:

参数学习
- 这里使用交叉熵模型作为损失函数,那么可以得到风险函数如下:
- 利用梯度下降算法求解参数,这里需要求解风险函数的梯度,求解过程如下:

- 从而利用梯度下降算法进行参数的迭代更新就可以求解得到最优的矩阵 $\mathbf W$

感知器
- 感知器是一种最简单的人工神经网络,只有一个神经元,对于外界的特征信息只会输出
1或者-1, 所以最终的分类准则为: $$ \widehat y = sgn({\mathbf \omega}^T{\mathbf x}) $$
参数学习
- 学习策略:

- 学习策略可以抽象为如下的代码:

- 参数学习的过程(注意注意这里使用了梯度下降算法,每一次需要利用向量的运算规则来决定新的向量需要指向哪一个位置):
参数平均感知器
- 由于这一种利用错误数据决定变化方向的规则会使得后面的错误数据相对于前面的错误数据的影响更大,所以引出一种利用参数平均感知器也就是给每一个迭代的到的模型赋予一个权值,从而利用这一个权值得到最终的结果,同时又可以利用平均值

- 如果扩展到多分类,那么就需要建立一个广义的感知机模型:
支持向量机
- 支持向量机也是一种二分类算法,也是为了寻找一个超平面对于样本进行分类,这里寻找的方法就是不断计算样本距离目前的模型的平面的距离,从而不断调整模型的参数(比如利用梯度下降算法等方式)(注意训练的过程是参数不断更新的过程,需要不断调整模型的参数)

参数学习
- 一般利用拉格朗日法进行参数的学习(注意随着训练集的数据的不断读取,模型参数会不断调整)

- 利用拉格朗日对偶函数就可以求解最优的参数 $y^*$ 了,知道最优的参数之后可以使用支持向量的任意一个点求解偏置
b
核函数和软间隔
- 核函数用于把原始空间映射到更加高维度的空间,这一个过程中需要使用核函数

- 软间隔: 类似于参数的正则化,放置样本在线性不可分开的区间里面无法找到最优解

损失函数对比
Logistic的损失函数利用了交叉熵损失函数- 感知器损失函数
- 支持向量器损失函数
- 平方损失函数
- 效果对比(最终得到的模型的
yf(x;w)大并且损失函数的值小就是比较好的模型):
- 几种线性模型的对比:

基本模型
前馈神经网络
神经元
- 人工神经元是对于生物神经元的一种模拟,生物神经元通过树突接受信息,通过突触发送信息给之后的神经元,所以人工神经元也是一样的(接受信息,输入信号到达一定的阈值之后就会使得神经元处于激活状态,从而产生电脉冲完成信息的传递)
激活函数
- 假设一个神经元接受$D$个输入$x_1,x_2,x_3 ... , x_D$ ,可以利用向量 $\mathbf x = [x_1,x_2,x_3, ... , x_D]$ 来表示输入,并且使用净输入量来表示一个神经元获得的输入信息的加权和 $$ z = \sum_\limits{d = 1}^D{\omega}_d{x}_d + b = {\mathbf \omega}^T{\mathbf x} + b $$
z经过一个非线性函数f(.)之后就可以得到神经元的活性值a,其中 $a = f(z)$ ,非线性函数f(.)就是激活函数
Sigmoid函数
- 一种
S型曲线函数,两端饱和函数(也就是两个极限位置都是趋于一个常数) Logistic函数,定义如下: $$ \sigma(x) = \frac{1}{1 + exp(-x)} $$- 性质如下: $$ \sigma^{'}(x) = \sigma(x)(1 - \sigma(x)) $$
- 当信号比较小的时候,活性基本为
0,信号比较大的时候活性接近与1 Tanh函数,定义如下: $$ tanh(x) = \frac{exp(x) - exp(-x)}{exp(x) + exp(-x)} $$- 也就是: $$ tanh(x) = 2\sigma(2x) - 1 $$
Tanh函数的输出是零中心化的,Logistic函数的输出恒大于0,非零中心化的输出会使得后面一层的神经元的输入发生偏置从而使得梯度下降的收敛速度变慢
Hard Logistic函数和Hard Tanh函数,都是一种近似的线性分段函数
ReLU函数
- 一种斜坡函数,定义如下: $$ ReLU(x) = \begin{cases} x & \text{if } x >= 0 \ 0 & \text{if } x < 0 \end{cases} = max(0,x) $$
- 优点: 操作简单,稀疏性比较好(分布均匀),大于
0时 导数为1 - 缺点: 非零中心化,如果一个神经元接收到负信号就会死亡无法被激活
- 带泄漏的
ReLU和带参数的ReLU
ELU函数和Softplus函数
Swish函数
- 一种自门空控激活函数
Maxout单元
- 用于描述上一层神经元的整体输出,

网络结构
- 前馈网络: 每一个神经元按照接受信号的先后顺序分为不同的组,每一层可以看成一个神经层,每一层的神经元接受前面一层的输出并且输出到下一层神经元,信息都是朝着一个方向传递的 包含 全连接前馈网络和卷积神经网络
- 记忆网络: 反馈网络,网络中的神经元不但可以接受其他神经元的信息还可以接受自己的历史信息,包含循环神经网络等
- 图网络: 应用与图结构的数据结构,同时也是前馈网络和记忆网络的优化,包含各种不同的实现方式,比如图卷积网络等
前馈神经网络
- 也叫做多层感知器,因为前馈神经网络其实是多层的
Logistic回归模型 - 第 0 层称为输入层,最后一层称为输出层,其他中间层称为隐藏层.整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示.
- 相关参数如下:

- 前馈神经网络利用如下迭代进行信息传递: $$ {\mathbf z}^{(l)} = {\mathbf W}^{(l)}{\mathbf a}^{(l - 1)} + {\mathbf b}^{(l)} $$ $$ {\mathbf a}^{(l)} = f_l({\mathbf z}^{(l)}) $$
- 每一层可以看成一个仿射变化(也就是从一个空间映射到另外一个空间的变化),整个网络可以看成一个复合函数 $\phi({\mathbf x};{\mathbf W},{\mathbf b})$ , 所以通过不断的传递,最后就可以得到第
L层的输出作为整个函数的输出: 其中 𝑾, 𝒃 表示网络中所有层的连接权重和偏置
其中 𝑾, 𝒃 表示网络中所有层的连接权重和偏置 - 根据通用近似定理,前馈神经网络可以用于拟合各种连续非线性函数
应用到机器学习
- 比如用于分类问题: 注意神经网络的作用可以看成进行函数的一个仿射变化,也就是可以对于函数进行复合操作,所以可以利用输入层把$x$映射到$\phi(x)$ ,得到更加明显的特征,之后再把输出交给下一层
- 如果是二分类问题,最后一层只需要一个神经元即可,激活函数可以设置为
Logistic函数 - 如果是多分类问题,可以把最后一层设置为
C个神经元用于输出每一个类别的神经网络,可以利用softmax函数作为激活函数
- 如果是二分类问题,最后一层只需要一个神经元即可,激活函数可以设置为
- 可以见得,通过神经网络层的连接情况可以进行不同函数的拟合从而完成各种操作
参数学习
- 利用交叉熵作为损失函数,并且利用正则化来限制模型能力从而保证泛化能力,同时利用梯度下降的方法进行参数的学习:
 梯度下降法需要计算损失函数对参数的偏导数,如果通过链式法则逐一对
每个参数进行求偏导比较低效.在神经网络的训练中经常使用反向传播算法来
高效地计算梯度
梯度下降法需要计算损失函数对参数的偏导数,如果通过链式法则逐一对
每个参数进行求偏导比较低效.在神经网络的训练中经常使用反向传播算法来
高效地计算梯度
反向传播算法
- 由于每一次对于一个矩阵计算梯度的时间复杂度比较大,所以为了减小时间复杂度,就需要使用反向传播算法计算梯度,下面介绍反向传播算法的公式的基本推导过程和结论 矩阵求导参考: 矩阵求导
- 首先求解损失函数对于每一权重的偏导数:
- 接下来只需要分别求解如下量即可 $$ \frac {\partial {z}^{(l)}} {\partial {\omega}_{ij}^{(l)}} 和 \frac {\partial {z}^{(l)}} {\partial {\mathbf b}^{(l)}} 和 \frac {\partial {\mathcal L}({\mathbf y},{\widehat {\mathbf y}})} {\partial {\mathbf z}^{(l)}} $$
- 计算方式如下(涉及到大量的矩阵运算)

- 接下拉计算误差 ${\sigma}^{(l)}$ 的传递规则:
- 最终可以得到反向传播的结论:

- 通过上面的推导,误差可以使用递推公式进行计算,同时梯度可以转换为矩阵的计算,总体的计算方式如下:

自动梯度计算
- 三种方式: 数值计算(定义计算),符号计算(类似于按照各种不同的方式进行符号解析),自动微分
- 自动微分计算可以把函数拆分为各种运算符号和各种基本函数的结合,利用各种基本函数的微分求解方式来确定最终可以得到的偏导数,举例如下:

- 前向计算: 首先从
h1开始计算向最终目标计算 - 反向计算: 从
h6开始逐步积累 - 各种计算方式之间的关系
优化问题
非凸优化问题
- 对于多层网络组成的复合函数,可能不是一个凸函数,那么就难以利用梯度下降找到最优解
梯度消失问题
- 对于误差传递公式:
- 需要计算激活函数的导数,所以如果哪一个层的导数为
0就会到时最终得到的结果中的梯度消失(回想反向传播公式中由误差项目) - 但是对于一些激活函数,比如 $\sigma(x)$ 和 $tanh(x)$ 都是存在导数为
0的点,所以都会导致梯度消失
卷积神经网络
卷积的计算可以参考: https://zhuanlan.zhihu.com/p/268179286?ivk_sa=1024320u
卷积
- 我的理解卷积其实就是利用一组权重(可以是向量或者矩阵)从而对于输入的数据进行一系列的特征化得到新的数据的过程
一维卷积
- 定义和距离如下:

- 一维卷积的图解(步长都是为
1)
二维卷积
- 卷积核变成了一个矩阵,这一个矩阵用于表示一定范围内的元素的权重,可以用于计算权重和从而计算最终得到的矩阵中的元素,公式如下(看不懂...):
- 计算过程:
- 比如可以使用一个范围内的平均值来计算经过卷积之后的特殊值
互相关
- 也就是在利用卷积核的时候可以按照
Hardmanda乘积的方式计算(也就是你想的那样),效果一样,变化公式如下:
卷积的种类
- 注意步长就是卷积核每一次沿着样本滑动的距离,和卷积核本身无关,卷积的种类如下:
卷积的数学性质
- 交换性:

- 卷积的导数求解:

卷积神经网络(CNN)
卷积神经网络的特点
- 局部连接: 也就是在卷积层中每一个层的神经元都是只与前面的一部分神经元连接而不是和前面的神经元全连接,所以此时每一层的活性值(输出)与下一层的净输入量有如下的关系:
- 权重共享: 就是值得卷积核在输入特征的对应通道中扫描,所以所有被扫描到的部分都是共享同样一个权重的,也就是卷积核对应通道的权重
卷积神经网络的结构
- 注意卷积神经网络中神经元的连接是三维度的,比如对于一个图像,长和宽表示图像的分辨率,深度表示图像中的通道数量
卷积层
- 作用: 提取一个局部区域的特征,不同的卷积层相当于不同的特征提取器(比如一个用于提取颜色,一个用于提取轮廓等)
- 下面是对于输入特征映射组和输出特征映射组以及卷积核的阐述:

- 解释一下我比较困惑的几个点:
- $X \in \mathbb R^{M \times N \times D}$ 表示输入是一个三维度的张量,可以类比为图片,
M和N表示长和宽,D表示深度(通道数量) - $Y \in \mathbb R^{M' \times N' \times P}$ 表示输出也是一个三维度的张量,只不过这里把
D个特征映射为了P个特征,这一个过程通过卷积操作 - $\mathcal W \in \mathbb R^{U \times V \times P \times D}$ 首先
U,V表示每一个权重矩阵的边长,P表示总共需要提取的特征个数(可以看成卷积层的层数),D表示每一个卷积核中权重矩阵的个数(也就是通道数量), $\mathcal W^{p,1}$ 表示用于提取第p个特征的第1个通道的权重矩阵
汇聚层(池化层)
- 作用类似于卷积层,作用也是用于提取特征,池化其实也是对于每一个区域进行一个下采样的过程(上采样表示把低维度的图片转换为高维度的图片)
- 一般就是把一个特征的某一个通道矩阵进行划分,并且利用划分区域中的特征来代表这一个区域的特征,常见的两种汇聚函数分为最大汇聚和平均汇聚(不用过多介绍了)
- 实际常常使用最大汇聚来实现下采样
- 整体结构如下,注意卷积块可以更具需要提取特征的特殊来确定:
参数学习
- 梯度计算方式: 就是把点积换成卷积即可,其他的和全连接网络的计算方式一样:

CNN中的反向传播算法
- 误差反向传播算法在池化层和卷积层中不一样
- 在池化层中,误差传递公式和推导方式如下:

- 在卷积层中,误差传递公式如下(全连接网络中把乘积操作换成卷积操作即可)

- 需要注意如下事项:
- 卷积神经网络中的神经元分为三维度空间,用于采集比如图像一类的数据等
- 卷积操作和池化操作其实都是对于特征的提取,但是不同之处在与卷积操作需要利用卷积核(也就是具有对应通道个数的权重矩阵的集合)从而确定输出的特征图,但是池化只是对于输入图本身的一些操作,比如取平均值等
- 注意误差传递公式在池化层和卷积层中的应用
- 另外除了标准卷积还有很多卷积方式,同样标准卷积中神经元的个数可以通过公式计算
csapp中的Labs汇总: https://github.com/xzwsloser/csapp-labs/tree/master 这里主要用于记录在之后的学习过程中有所遗忘的知识点
处理器体系结构
1. 指令执行流程
- 看书的过程中发现自己对于
ret指令和pushq指令还有popq指令的执行过程有所遗忘,执行过程如下: pushq和popq指令的作用(特别注意popq):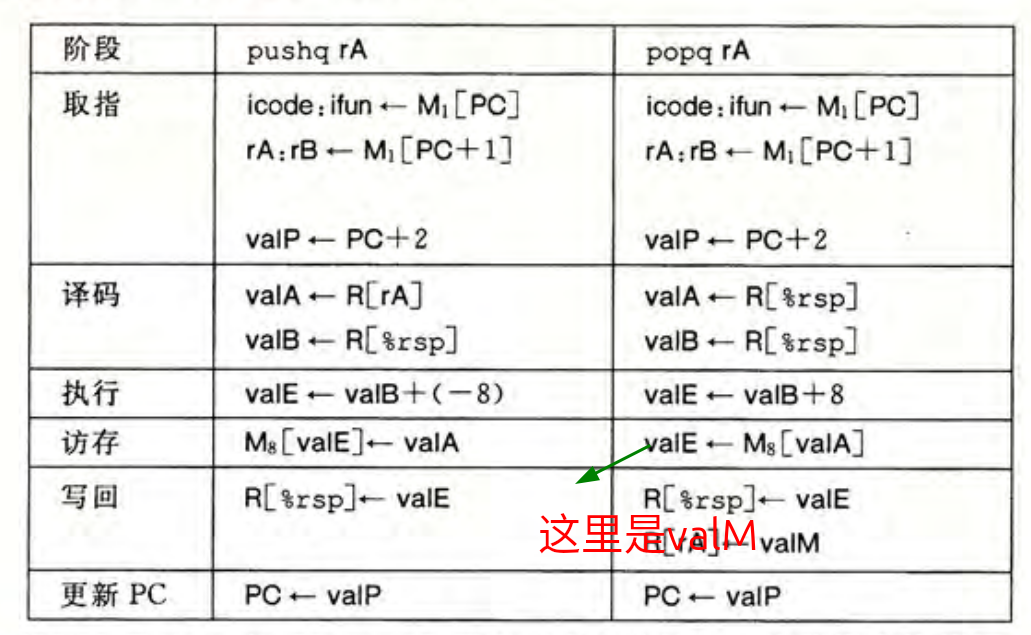
pushq指令: 把栈指针向下面移动8并且把原来的rA中存储的地址存放在内存中,加入rA中存储这指令实体,那么利用这一个指令就会导致新的栈指针执行的地址对应在内存中就是这一条指令实体(attacklab)(相当于向内存中储存储指令,之前的指令存储在新的栈指针指向的位置)popq指令: 把栈指针向上面移动8并且把原来的栈指针指向的地址实体放入到寄存器rA中(完成了从内存到寄存器的映射),这里可以是把内存中的指令取出到寄存器中了(相当于从内存中取出指令,取出之前的指令存储在rA中,栈指针也可以存储数据(比如上下文))ret指令:
- 类似于
pushq指令,这里从原来的栈顶指针中取出指令并且跳转执行原来栈顶指针指向的指令,也会把栈顶指针`+8
CPU虚拟化
操作系统概述
- 本书首先简单介绍了操作系统,根据我的理解操作系统就是硬件和软件的桥梁,对于硬件(比如
CPU,内存,硬盘,IO设备等),操作系统把硬件的各种资源进行抽象,也就是书中所讲述的虚拟化(接下来的讨论一般来说都是针对于单CPU的情况),比如CPU只有一个但是需要同时运行多个程序,那么操作系统就使用时分复用的方式在一个很小的时间片段内执行不同的程序这就造成了CPU同时执行多个程序的假象,在比如对于内存资源,不同的程序运行的时候就算使用了某种特定的方法使得程序中的某些变量的地址一样,但是对于这个变量的操作却不会相互干扰,这里操作系统对于内存做了虚拟化,制造了单个程序独享内存的假象;另外由于CPU同时执行多个程序,所以这就会引发并发的问题,并发的问题在我的理解下就是软件层面的问题,比如多个线程同时访问一个共享变量;最后操作系统还需要持续存储它保存的数据,操作系统必须持久化的保存数据,所以这里就会设计文件系统等,这一个特点成为持久化
系统调用,上下文切换与中断
- 接下来,讲述了进程的抽象概念,进程就是运行起来的程序,
CPU通过把程序加载道内存中对于程序进行运行,这一个过程中回首先加载代码片段和数据片段(现代操作系统倾向于懒加载,需要数据才会加载),之后回初始化程序运行时栈和堆并且进行一系列初始化任务 - 之后介绍了进程的状态(注意就绪是没有调度到这一个进程,运行是调度到了这一个进程)
- 接下来介绍了与进程有关的各种
API, 这就不多说了 - 下面的一些中主要讲述了
CPU如何运行一个进程,首先提到了不受限制的运行,这就会导致用户进程可以访问系统的所有资源,所以引出了用户模式和内核模式的概念,但是当用户有时候需要访问系统资源(比如接受网络包,存储文件时),就需要转换到内核模式进行调用,所以这里引出了System call的概念,系统调用本来是普通的C库函数,但是其中利用汇编加入了trap指令得以让CPU陷入内核模式,从而执行各种操作,这里操作系统启动时加载陷阱表记录着遇到怎样的trap需要执行那一种操作 - 接下来就引出了上下文切换的概念,也就是在不同的进程之间进程切换,在此之前还讲述了操作系统如何获得执行权,主要时通过时钟中断的方式,之后加少了保存和恢复上下文的方式,操作系统需要进行调度时,首先把各种寄存器的值存储在该进程的内核栈中(比如
PCB中,PCB中就有存储者各种寄存器的结构体),同时将需要被调度的进程的内核栈中存储的寄存器的值加载道物理寄存器中并且执行该进程,比如相关指令如下:
进程调度方式
- 在讨论完
CPU如何进行进程的切换(上下文切换)之后,书中着重讲述了进程的调度方式 - 考虑如下指标: 周期性: 也就是所有进程执行完毕之后的平均时间,响应时间: 表示进程从开始运行到被调度的时间
- 首先是
FIFO(先进先执行的原则): 也就是首先到达的进程首先执行,但是这一种调度方案使得如果一个执行时间比较长的进程首先执行就会拖慢后面的进程的执行时间 - 之后是
SJF(最短任务优先): 也就是首先执行需要时间最短的任务,虽然这一种调度方式在所有进程同时开始的时候是最优的,但是如果出现了时间长的进程首先被加载到内存中,由于这一种调度方式是非抢占性的,所以这一个进程就会拖慢后面的进程 - 之后引出了抢占式的最短任务优先(
STCF),和上面相比,如果一个长任务来到的时候就会被后面到来的任务抢占执行从而停止被调度 - 另外考虑了响应性,引出了轮询
RR的调度方式也就是进行时分复用,分出时间片来执行不同的进程,注意RR中的时间片段需要是时钟的周期的倍数从而保证可以正常利用中断进行模式的切换,另外选择时间片长度的一个方式就是考虑上下文切换的开销,但是即使选择了合适的时间片还是回使得周期时间过长 - 接下来考虑
IO操作等需要阻塞进程的操作和进程运行时间的不可知性,引入了通过历史预测从而完成调度的一种算法==MLFQ(多级反馈队列)==,在MLFQ中分出不同优先级别的队列,CPU优先执行优先级别高的队列中的任务并且轮询执行相同队列中的任务,同时在一个时间片内执行某一个任务之后使得它的优先级别下降但是如果在这一个期间有任务主动释放CPU(表示阻塞),那么优先级别不会改变,但是这就会产生那些长任务的"饥饿问题",所以又引出了提升优先级别的方法,最后为了防止某一些进程长时间占用优先级别,有引入了执行份额的方式,所以最终的调度策略如下:- 如果
A的优先级别>B的优先级别,运行A - 如果
A的优先级别=B的优先级别,轮询运行A和B - 工作进入系统被放在优先级别最高的队列中
- 一旦工作用完了在某一层中的(无论中间放弃过多少次
CPU)都会降低优先级别 - 经过一段时间
S,就将系统中所有工作重新加入到最高的优先级队列中(boost)
- 如果
- 最后引入了按照份额的调度方式: 引出了彩票调度和步长调度的方式,彩票调度每一段时间进行一次抽奖活动,抽到对应彩票的进程被调度,并且进程可以利用自己的货币给子任务分配彩票,抽奖时这些彩票转换为全局彩票,步长调度则是为每一进程设置步长,每一次调度完某一个进程就会给这一个进程的行程值加上步长,最后调度最小行程的进程,这一种算法保证了在很短的一个时间内实现份额的加权分配,但是当有进程需要被插入时这一个算法却难以找到合适的行程初始值,彩票调度虽然对于插入的进程的处理相对容易,但是却难以确定每一个进程的彩票数量,这两种调度方式使用很少,主要是使用
MLFQ调度策略 - 另外书中还拓展将了多处理器的调度机制,首先多处理器相对于单处理器还会出现如下的问题: 缓存的一致性,也就是所有的进程都公用一个内存,如果一个进程更新缓存中的数据就会导致内存中的数据没有及时的更新(这是由于
CPU使用回写的方式,知道该缓存中的内容被驱逐的时候才会写入到内存中),但是此时其他的CPU也是公用这一个内存,所以如果再一次读取这一个数据读取到的就是旧值,导致了缓存的一致性问题,一种可能的解决方法就是利用监控内存的访问,通过总线窥探所有缓存和内存的总线来发现内存访问,如果发现该数据被修改,就会使得缓存中的本地副本作废;第二个问题就是同步问题,也就是多线程操作同样一个共享数据时引发的并发安全问题,解决方式就是加锁,但是这会拖慢CPU执行的速度;另外一个问题就是缓存亲和性的问题,也就是说如果一个进程在某一个CPU上面运行的时候,CPU回缓存进程的许多状态,所以这一个进程下一次在这一个进程上面运行的时候就可以运行的更快,但是如果在多CPU的系统中也会面对这一个问题; 从而引出了多处理器进程调度的方式:SQMS简单的把所有进程放入到一个列表中,每一个CPU并行执行队列中的每一个进程,这一种调度方式会产生两个问题: 锁导致CPU执行速率被拖慢,另外一个问题就是缓存亲和性的下降,后者解决方式的就是可以牺牲某一个进程的缓存亲和性从而使得其他的CPU的大量时间执行同样一个进程,但是对于这一个被牺牲进程的调度又成为了新的问题MQMS为每一个CPU配置队列,单个CPU执行自己队列中的操作,这样随着CPU的增加,队列的数量增加,锁和缓存的竞争就会减小,同时保证了缓存的亲和性,另外一个问题就是负载均衡的问题,如果一个队列中的任务被执行完毕那么就会导致这一个CPU处理空闲或者这一个队列中的任务占用CPU执行的大部分时间,解决方式就是工作窃取,也就是工作少的队列从工作多的队列中窃取任务(先天牛马圣体),从而保证了负载均衡,但是这里的窃取间隔时间又回成为新的问题
lear> 教育不是注满一桶水,而是点燃一把火
相关的知识可以参考: csapp
操作系统概述
- 本书首先简单介绍了操作系统,根据我的理解操作系统就是硬件和软件的桥梁,对于硬件(比如
CPU,内存,硬盘,IO设备等),操作系统把硬件的各种资源进行抽象,也就是书中所讲述的虚拟化(接下来的讨论一般来说都是针对于单CPU的情况),比如CPU只有一个但是需要同时运行多个程序,那么操作系统就使用时分复用的方式在一个很小的时间片段内执行不同的程序这就造成了CPU同时执行多个程序的假象,在比如对于内存资源,不同的程序运行的时候就算使用了某种特定的方法使得程序中的某些变量的地址一样,但是对于这个变量的操作却不会相互干扰,这里操作系统对于内存做了虚拟化,制造了单个程序独享内存的假象;另外由于CPU同时执行多个程序,所以这就会引发并发的问题,并发的问题在我的理解下就是软件层面的问题,比如多个线程同时访问一个共享变量;最后操作系统还需要持续存储它保存的数据,操作系统必须持久化的保存数据,所以这里就会设计文件系统等,这一个特点成为持久化
虚拟化
CPU虚拟化
Target: 对于单CPU的系统,虚拟化为多个CPU在同时运行多个进程的假象- 笔记: CPU虚拟化
虚拟内存
Target: 构建虚拟内存,制造一个进程运行的时候以为自己独占物理内存空间的假象- 笔记: 虚拟内存
并发
- 介绍多线程环境下的线程同步等问题
- 笔记: 并发
持久化
- 主要介绍操作系统中的文件系统
- 笔记: 持久化
er> 书中对于并发问题的引入举了一个比较有意思的例子: 当多个人共享同一个桃子的时候,所有人首先在视觉上看到了桃子,但是当多个人伸手去拿桃子的时候却会惊奇的发现桃子不见了
并发引入
- 还是通过经典的线程同步的例子引出并发中线程安全的问题,和
csapp中一样,把对于共享数据的处理拆分为指令级别的,之后说明在一个线程执行这些指令的过程中,可恶的中断调度其他线程导致线程安全问题,最后提出了各种解决线程安全问题的方式: 提供原子操作指令或者停止屏蔽中断
锁
锁的定义
- 根据上面的讨论自然而然引出了锁的概念,一个锁其实就是一个变量,这一个变量中可以记录各种各样的信息,比如对于锁的标识,锁的状态甚至可以记录阻塞在锁上面的线程队列等信息
评价锁的指标
- 正确性: 是否可以正确的完成互斥的任务
- 公平性: 所有线程都可以拿到锁,放置某些线程因为拿不到产生的饥饿问题
- 性能
实现一个锁
- 一般而言,对于操作系统中某一个功能的支持或者某一个操作性能的提升一般都需要操作系统的支持和硬件的支持,硬件的支持主要用于提供各种可以使用的指令,操作系统的支持则是利用硬件提供的各种指令来操作数据结构完成对于操作的优化
硬件支持
- 硬件支持主要是为操作系统各种操作的原子指令(这些指令的实现依赖于底层的数字逻辑结构),如下总结书中提到的几种可以用于实现锁的原子指令
测试并且设置指令
- 测试并且设置指令运行把设置一个内存空间处的值为新的值并且返回旧的值这一个操作作为一个原子指令,相似的原子指令比如
x86中的xchg指令,实现的功能如下:
int TestAndSet(int* old_ptr , int new) {
int old = *old_ptr;
*old_ptr = new;
return old;
}
- 所以依赖于这一个指令,可以利用如下操作实现互斥锁:

- 上面的锁,当线程被阻塞的时候就会不断判断条件并且阻塞等待,这一个过程成为自旋,所以这一个锁被称为自旋锁
- 对于自旋锁的评价:
- 正确性: 可以保证互斥性
- 公平性: 自旋的线程会在阻塞处不断自旋占用
CPU,没有公平性,会导致自旋操作不断占用CPU,执行其他任务的线程占用CPU的时间减少或者拿不到锁而饿死 - 性能: 单
CPU上性能不好,多CPU上由于执行任务的线程和自旋的线程可以在不同的CPU上面执行所以性能不错
比较并且交换指令
- 指令的伪
C代码实现:
int CompareAndSwap(int* ptr , int expected , int new) {
int actual = *ptr;
if(actual == expected)
*ptr = new;
return actual;
}
- 利用这一条指令实现锁:

- 但是以上实现的还是自旋锁,还是会导致以上的问题
链接的加载和条件式存储指令
- 原子指令的伪
C代码实现:
- 利用这一条指令实现锁:

获取并且添加指令
- 获取并且添加指令的实现方式如下:
int FetchAndAdd(int* ptr) {
int old = *ptr;
*ptr = old + 1;
return old;
}
- 利用这一条指令可以实现
tickets锁:
- 以上实现锁的过程保证了每一个尝试的线程都可以获取到锁,保证了公平性
- 最后可以发现如何仅仅依靠硬件层面实现的原子指令来实现锁,那么难以保证自旋过多的问题,所以此时就需要软件(操作系统)支持了
操作系统支持
- 通过操作系统支持,可以提供各种数据结构或者系统调用来控制进程的调度
自旋的时候让出CPU
- 最简单的一种方法: 自旋的时候让出
CPU:
- 但是利用这一种方式当很多线程同时竞争一把锁的时候就会导致很多线程不断处理礼让-自旋的这一种的状态中,也就是不可以让自旋的进程处于就绪状态
使用队列: 休眠替代自旋
- 一种比较巧妙的方法就是让自旋的线程进入休眠状态,同时所有休眠状态中的线程被放入到队列中,实现方法如下:

- 这一种方法就使得自旋的线程在经过一次条件判断之后都处于休眠状态了,减少了自旋线程对于
CPU的占用
两阶段锁
- 核心思想: 如果第一个自旋阶段没有获取到锁,第二个阶段调用者就会休眠知道锁可以使用,比如
Linux中就是使用这一种方式,并且Linux中设置自旋次数为1:
- 不太明白这一段代码
并发的数据结构
- 有了互斥锁之后就可以利用互斥锁构建各种并发安全的数据结构,并且构建这一些数据的结构的时候都可以使用一个非常简单粗暴的方法(对于每一个操作都使用加锁的方式进行互斥),同时注意拓展性,拓展性也就是指在进行某一个操作的时候是否可以并发的操作数据结构的另外的部分,拓展性能的实现方式就是控制更小的锁的力度,比如对于链表,给链表的每一个节点上锁,对于队列,给队列头和队列尾上锁
- 注意锁的语义: 就是保护相应的共享变量,比如对于队列头上的锁就是保护队列头部,里面就是操作头部的代码
- 书中主要介绍了并发的计数器,链表,队列和散列表的数据结构 , 参考书中实现代码即可(也就是注意加锁的粒度即可),另外注意并发计数器的实现方式即可(惊为人天的一种操作)
条件变量
- 条件变量的作用: 可以让线程阻塞在某一个条件的位置
- 和锁这样的并发原语一样,条件变量其实也是一个结构,它其实是一个显示队列
- 相关的操作:
pthread_cond_t cond; // 声明条件变量
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr); // 初始化条件变量
int pthread_cond_destroy(pthread_cond_t *cond); // 销毁条件变量
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex); // 根据条件阻塞线程
int pthread_cond_signal(pthread_cond_t *cond); // 随机唤醒一个阻塞在条件变量上的一个线程
int pthread_cond_broadcast(pthread_cond_t *cond); // 唤醒阻塞在条件变量上的所有线程
- 特别注意,
pthread_cond_signal的作用如下:- 首先会释放互斥锁
- 阻塞等待条件满足(也就是
pthread_cond_signal唤醒) - 重新获取锁
- 本节中的引入方式就是通过不断完善生产者消费者模型从而引出条件变量的各种特性的,所以这里直接阐述利用条件变量实现生产者消费者模型的注意事项 代码: pro_con_cond.c
- 注意事项如下:
- 为了保护共享变量(
count)和队列,需要加上互斥锁 - 这里需要使用
while判断条件的原因在与,pthread_cond_wait中释放了锁,所以接下来的过程中,当一个线程被唤醒的时候,另外的一个线程可能已经越过锁了(此时条件被满足了,判断结束),所以一旦这一个线程此时获取变量就会发生线程安全问题 - 注意互斥锁的位置,如果互斥锁出现在条件变量的前面就会导致生产者和消费者同时获取锁时候的线程安全问题
- 另外一个小的注意事项就是就算子线程中利用
pthread_detach一旦主线程结束,所有子线程都会跟着结束,所以最好还是使用phtread_join回收子线程
- 为了保护共享变量(
信号量
- 信号量也可以叫做
PV信号量,可以参考csapp ,信号量是一个整数值的对象,通常信号量的操作方式如下:
#include <semaphore.h> // 头文件
int sem_init(sem_t *sem, int pshared, unsigned int value); // 初始化信号量
int sem_wait(sem_t *sem); // P 操作,使得sem_t - 1
int sem_post(sem_t *sem); // V 操作,使得sem_t + 1
- 利用信号量可以构建互斥锁: 互斥锁就是一个二值的信号量
- 利用信号量可以构建条件变量: 但是比较复杂(需要很多锁来支持
ptread_cond_wait中的几个步骤) - 利用信号量可以构建消费者生产者模型,此时可以利用空格数量锁住生产者,利用物品的数量锁住消费者 代码实现: pro_con_sem.c
- 另外可以利用信号量实现读者-写者模型 但是树上的代码没有保证在写者和读者都被阻塞的时候写者的优先级别,它的思路就是让第一个读者获取到互斥锁,之后的读者都可以读取数据,但是写者必须在读者读完之后才可以写入数据
- 可以解决各种有趣的并发问题,比如哲学家进餐问题
- 注意可以利用条件变量和互斥锁来实现信号量,信号量也就是一个整数和互斥锁的集合(但是实际的信号量的实现比较复杂) 实现方式: sem.c (注意这里
sem_wait要做的事情就是把value--并且阻塞,sem_post要做的事情就是把value++然后唤醒即可)
并发问题
- 一般来说并发问题分为死锁问题和非死锁问题
- 非死锁问题的种类和解决方式:
- 违反原子性,也就是在操作共享数据的时候没有加上锁,导致多个线程操作同一个共享数据时产生的线程安全问题,解决方式就是加上锁即可
- 违反顺序缺陷,类似于循环应用问题,这里的一种解决方案就是利用条件变量,只有条件满足的时候才会执行相应的操作
- 死锁问题的预防策略:
- 死锁问题的出现条件: 互斥
- 持有并且等待
- 非抢占
- 循环等待
- 预防方式:
- 循环等待: 也就是两个线程使用反序或者不适当的方式获取到锁,解决方式就是偏序,也就是规定不同锁之间上锁的顺序,比如
Linux内核中一组代码规定了十中不同的加锁方式 - 持有并且等待: 把抢锁的代码在使用一层锁来保卫,保证原子性
- 非抢占: 利用
trylock,一次尝试之后就不可以在尝试了,这里可以规定重试的时间,但是可能出现活锁问题 - 互斥: 不要使用锁,而是通过各种策略构建无锁的数据结构
- 循环等待: 也就是两个线程使用反序或者不适当的方式获取到锁,解决方式就是偏序,也就是规定不同锁之间上锁的顺序,比如
- 最后比如可以通过调度避免死锁定,银行家算法就是一种可能的策略,可以参考银行家算法 算法的实现逻辑还是比较简单的,注意搞清楚每一个矩阵的用法即可(特别是使用
work矩阵模拟剩余容量的过程),这里我就不想写了
基于事件的并发
- 并发程序的三种实现方式: 进程,线程,
IO多路复用 - 核心思想就是事件循环,也就是同时监听不同的事件,当监听到某一个事件发生的时候就会采取相应的操作来处理对应的事件,相关的实现函数比如
select,poll,epoll等 - 基于事件的并发实际上是单线程的,但是如果在基于事件的并发中使用阻塞的系统调用(比如
read和write等IO操作),可能会导致程序阻塞导致资源被大量占用,一种可能的解决方案就是异步的IO,许多系统中提供了一种异步的IO,允许在后台进行IO操作并且在IO操作完成的时候通知进程(信号或者相应的函数返回值) - 但是编写基于事件的并发程序比较困难,需要处理事件集合之间的关系
这一个部分我其实有很多地方没有仔细看,另外这一部分有大量的内容作者也只是介绍了一部分,所以我这里就总结一些比较基本的文件系统和文件系统实现方式相关的例子
IO设备
- 一个计算机系统的各种
IO设备的一个经典架构如下(IO设备也就是对于内存进行读写的各种设备,比如硬盘,显卡等):
- 这里的各种总线的性质不同并且传递数据的速度也不同
标准设备
- 这里标准设备的一个抽象方式适用于各种硬件,也就是各种硬件向操作系统提供接口,操作系统利用这些接口来实现各种系统调用从而完成对于硬件的控制,一个典型的标准设备如下:

- 这里底层的硬件向上一层提供各种接口(比如状态寄存器,命令寄存器,数据寄存器等)
- 同时标准设备依托于标准协议完成操作系统与硬件之间的交互,一个例子比如操作系统可以通过不断读取硬件提供的接口中的状态寄存器的值来判断硬件的状态从而决定什么时候发送请求,这里如果
CPU使用轮询的方式完成对于硬件状态的判断就会到时这里会浪费大量的时间,所以此时硬件采用中断的方式,也就是硬件完成某一个请求或者发生故障的时候会进行一个时钟中断来同时CPU,所以此时就可以让IO操作与CPU计算并行执行:
DMA
- 但是如果考虑到
CPU还需要从内存送到硬盘硬盘才可以开始IO操作,这就又会产生时间的浪费,所以这里利用DMA来借助CPU完成数据从内存到磁盘的转义,DMA可以协调内存与各种设备之间的数据传递并且不需要CPU介入,利用DMA那么此时的时序图如下(并且DMA可以通过中断来向CPU发送命令完成的信号,中断就类似于进程中的信号):
设备的交互方式
- 内存映射: 操作系统把设备寄存器的值当成内存地址使用,这样就可以在每一次读取的时候像读取进程地址空间中存储的变量一样读取到数据了
- 特权指令(比如各种
IO指令),通过IO指令完成设备之间的交互
驱动程序
- 操作系统的一部分就是驱动程序
- 驱动程序解决的问题就是对于同一个操作系统,不同的设备提供不一样的接口,那么如何统一各种设备的接口使用方式,这里驱动程序其实也就是一个中间层,把硬件接口转换为操作系统可用的,统一的接口,比如文件系统栈如下:

- 这样对于不同的设备就可以统一交互方式了
磁盘驱动器(磁盘)
- 偏向于硬件并且过时,不做阐述
RAID
- 本质上是一个系统,充当磁盘驱动器的作用,可以提供各种数据存储服务和差错校验方式,不做阐述
文件与目录
- 这一个部分介绍了操作文件和目录的各种方式以及相关操作,这里介绍重要的知识点
fsync用于直接把写入到文件中的内容同步到硬盘中- 获取文件信息的方式:
stat函数,当然也可以使用stat命令: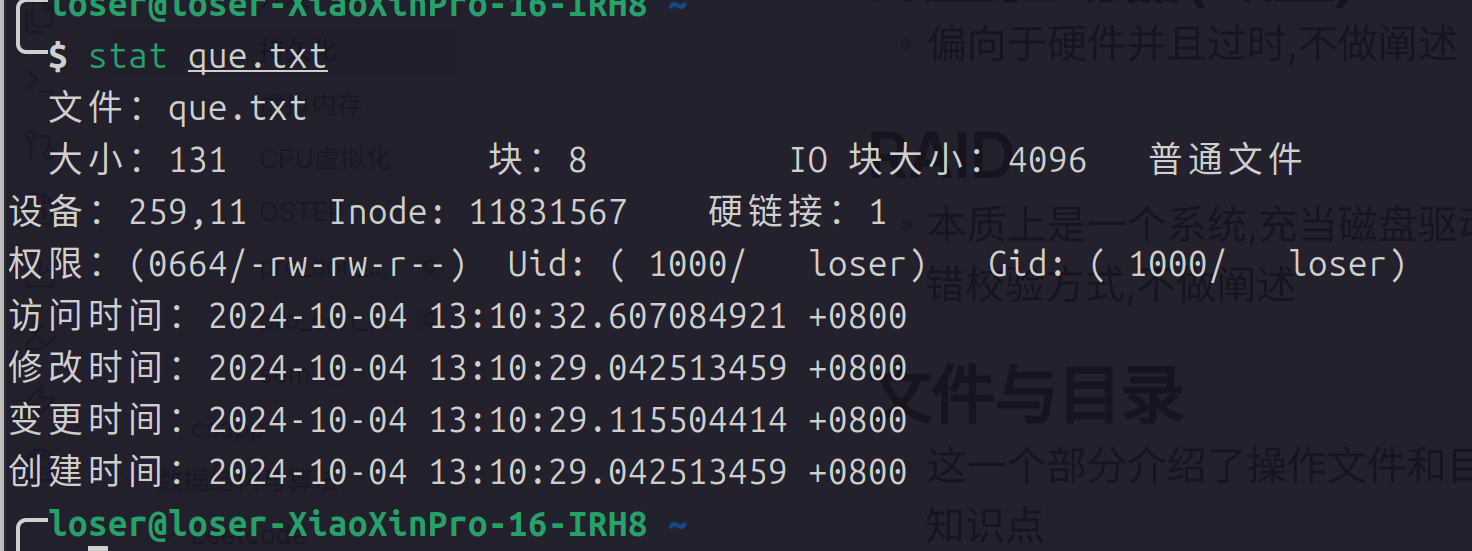
stat结构体的成员如下,可以利用其中的各种成员来判断文件的类型等信息:
stat系统调用如下:
int stat(const char *restrict pathname,struct stat *restrict statbuf);
- 硬链接: 可以看作创建了这一个文件的副本和这一个文件指向同一个
Inode,并且每一次创建一个硬链接都会使得硬链接数量增加 - 符号链接(软链接): 相当于创建了一个快捷方式,也就是符号链接原来的文件,所以一旦删除原来的文件,符号链接就不起作用了
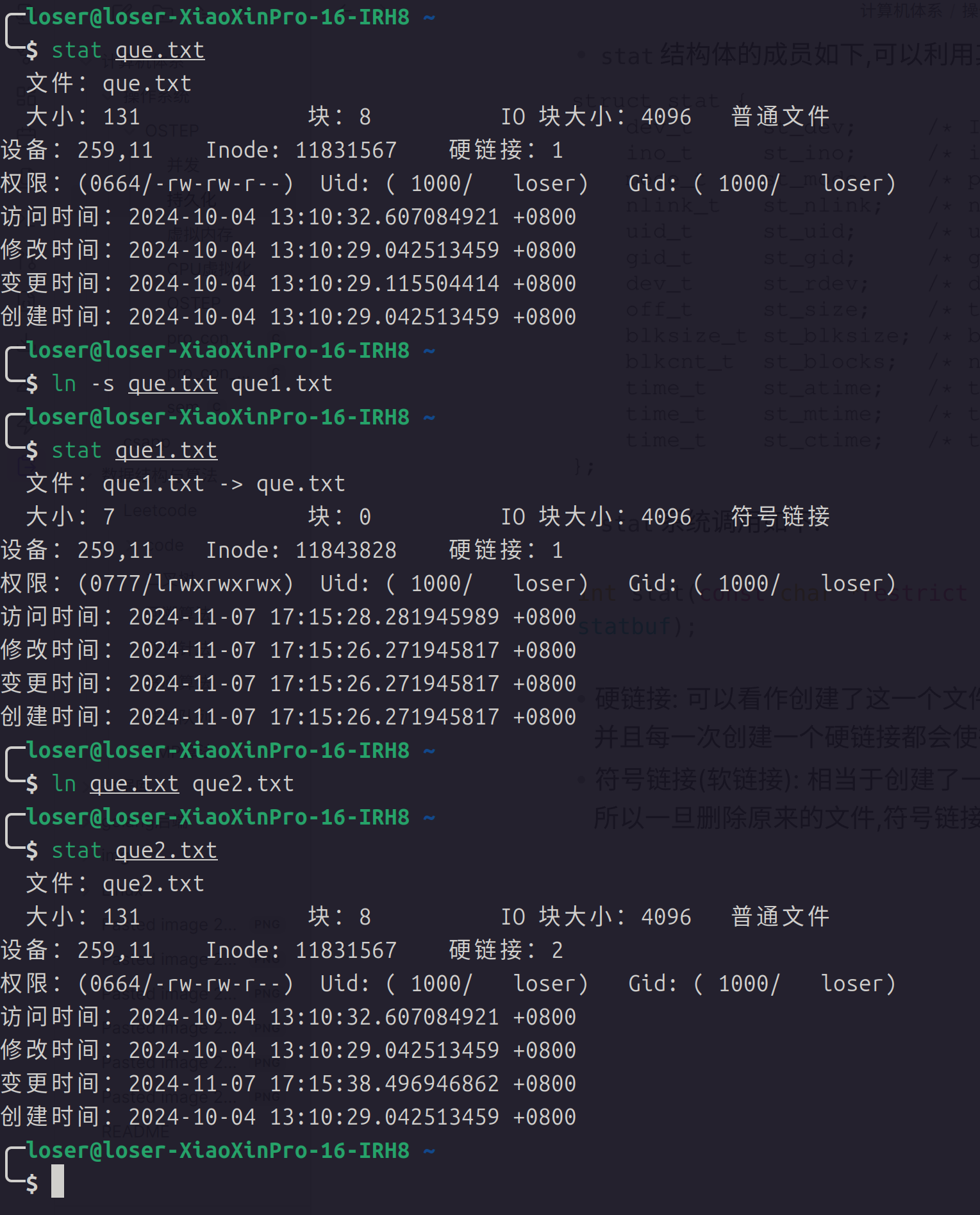
- 文件系统的挂载,可以使用
mount命令完成对于文件系统的挂载,所以可以间的即使在同一个目录下的不同的文件夹可能处于的文件系统或者所处与的磁盘都是不同的,所以不要一位/目录下的全部空间都是用于分配下面的所有目录,很多目录可以使用不同的文件系统甚至占用不同的磁盘,比如使用mount命令可以查看挂载情况,或者进行挂载,比如:
mount -t ext3 /dev/sda1 /home/users // 表示在这一块磁盘中利用ext3文件系统挂载目录 /home/user,此时/home/users 相等于文件系统的根目录
文件系统的实现方式
整体组织方式
- 包含超级块,
inode和数据位图以及inode还有各种数据,整体组织方式如下:
inode组织方式
- 可以认为
inode就是一个结构体记录着文件的各种信息,并且inode通过顺序排列的方式进行组织,并且每一个inode都有一个索引编号,所以利用相应的索引编号就可以锁定inode结构体的位置了,inode的组织方式如下:
inode结构体记录的内容如下(ext2文件系统为例,类似于stat结构体):
多级索引
- 为类支持大文件,
inode固定的文件指针是不够的,所以引出了间接指针的方式(和多级页表的设计方式几乎一样),让一个指针直线一个间接块,这一个间接块中存储者更多指针
目录组织方式
- 目录就是内容为
(文件名,inode)列表的文件,和文件一样拥有inode号等信息
空间空间管理
- 通过两个
bitmap,也就是数据位图和inode位图来判断相应的位置是否被占用
读取和写入
- 读取: 首先读取顶层目录,找到下一层目录的
inode,之后利用这一个inode找到相应文件的inode并且对于文件指针等信息进行更改即可,比如读取过程如下:
- 写入磁盘的过程也是一样的,但是此时需要查询数据位图和
inode位图从而找到空闲的块进行空间分配:
- 另外对于如此大量的文件
inode的读取和写入过程,怎么可能少了缓存,所以这里内存中会有一块区域来缓存磁盘中的某些信息,另外为了避免对于磁盘的多次操作还会使用缓冲的方式,也就是把写入的内容放入到缓冲区中,一起写入,当然可以利用系统调用fsync来进行数据的直接写入
局部文件系统和快速文件系统(FFS)
- 改变磁盘组织方式,添加柱面组的概念,从而保证时间和空间局部性
- 大文件组织方式: 首次适配,为了不破坏之后数据的局部性
崩溃一致性: FSCK和日志
fsck: 简单的扫描磁盘从而确定那一些数据发生了丢失,检查的时候根据不同的状态确定应对策略
日志
数据日志
- 也就是在写入真实的数据的时候首先写入数据日志,从而可以根据数据日志的内容对于崩溃的内容进行恢复,数据日志的一种组织方式如下:

- 利用数据日志之后的写入方式如下:
- 日志写入
- 加检查点(也就是写入带处理的元数据和实际数据)
- 为了保证日志的崩毁一致性,引入了事物的概念,所以此时需要改变写入顺序:
- 日志写入
- 日志提交(等待写入
TxE) - 加检查点
- 可以通过把一系列的读写操作组织在一起从而形成同一个事务
- 为了使得日志占用的空间有限使用循环队列的方式存储数据并且即使释放数据
元数据日志
- 为了方式对于同一个数据的多次写入利用元数据日志,基本没有什么不同的,组织方式如下:

- 此时的操作顺序为:
- 数据写入
- 日志元数据写入
- 日志提交
- 加检查点元数据
- 释放
日志文件系统(LFS)
- 组织方式如下:
- 这一种文件系统在写入的时候总是把数据写入到没有使用的块,对于使用过的块总是采用清除的方式,这一种方式提高了写入的速率,在文件系统中成为写时复制(
Copy-on-write)
这里梳理一下
OSTEP中对于虚拟内存的说明,本书的组织方式: 机制->策略,并且介绍策略的时候首先提出简单的假设,之后根据假设建立模型,并且论述模型的的特点,最后引出模型的缺点,最后根据缺点提出新的模型, 虚拟内存这一块的组织方式: 简单的存储和地址转换方式 -> 分段 -> 空闲空间管理 -> 分页 ->TLB硬件翻译 -> 多级分页,分段分页
虚拟内存引入
- 首先书中提出了让多个进程使用同样一个物理内存的方法(利用时分复用的方式,也就是么一个进程使用全部内存的一小段时间),之后就引出了保护的概念
- 为了虚拟出每一个进程独占一个很大的内存空间的假象,引出了虚拟内存的概念,对于虚拟内存需要考虑具备的特点就是: 透明(欺骗进程使得它以为自己独占内存空间),高效率,隔离(使得不同的进程之间隔离)
内存操作API,内存泄漏
- 之后引出了内存操作的
API(malloc,free) - 其中介绍了
strdup(这一个函数在堆区开辟空间并且把s中的内容拷贝到开辟的空间并且返回,返回的结果可以使用free进行释放)
char *strdup(const char *s);
- 另外介绍了监视内存的工具:
purify和valgrind(非常强大)valgrind使用
简单的虚拟内存组织方式
无分段
- 首先书中只是假设每一个进程在物理内存中占用一块特定的区域,所以进行虚拟内存和物理内存映射关系的时候利用一个寄存器存储物理内存的基址和最大的物理地址界限,利用
PA = VA + Base就可以通过虚拟地址计算得到物理地址 - 但是这一种方法的缺点就是一块进程占用的一块地址空间中有多个位置回发生空缺(也就是堆栈之间没有使用的位置),所以会产生许多内部碎片,导致物理内存的空间利用率下降
分段
- 接着提出了分段的概念,也就是根据程序内每一个作用不同的连续存储区域进行分段,比如分成堆栈等区域,有了分段的概念之后,就可以给每一个段一个寄存器用于存储每一个段的基址和界限,所以这样寻址方式还是一样的,只不过此时虚拟地址需要利用前面的几位来确定子集所属的段(
segment),此时虚拟地址的组织方式如下:
- 这一种方式有效的避免了内部碎片的产生,并且分成的段的大小不一样,所以回造成物理内存的外部碎片增多,导致空间利用率低
空闲空间组织方式
- 主要是利用那一种数据结构来存储各种不同的空闲块,另外如何找到适配指定大小的空闲块,可以参考 csapp 以及
Malloc
分页的组织方式
- 以上产生外部碎片的原因就是物理内存中对于虚拟内存的映射块的大小不固定,产生内部碎片的原因就是给进程分块时,很多块没有使用,为了解决这一种问题,就引出了分页的组织方式
分页
- 分页的方法就是把虚拟内存和物理内存都进行分页,并且利用一个映射关系把虚拟内存中分的块和物理内存中的块联系起来为了反应这一种映射关系,就需要引入页表的概念,页表项(
PTE)中记录了这相应的虚拟页号和实际的物理页号的映射关系,组织方式如下:
- 一方面为了找到数据在物理内存中的实际地址,虚拟内存中需要记录虚拟页面和偏移量,组织方式如下:
- 对于页表项(
PTE),需要记录VPN和PFN的映射关系,并且还需要各种标志位来记录是否可以访问,是否脏页是否有效等概念,所以组织方式如下:
- 分页存在的问题:
- 页表存在于物理内存中,所以每一次访问一个数据还需要页表(页表的基址存储在一个寄存器中),所以需要两次访问,如果虚拟页表中没有对应的页面还需要在物理内存中分配新的页面并且重试指令
- 页表的大小比较大(比如一个
32位的地址空间,页的大小为4KB,那么需要的VPN个数为$2^{20}$ ,如果一个PTE的大小为4个字节,那么一个页表的代大小就是4MB,如果100个进程,就需要400MB的空间存储页表,就会有很多页表项(就算没有分配的物理页面只是有效位标记为0而已,还是回被存储)) - 另外页表查询比较慢
TLB: 快递地址转换
TLB时MMU中的一个组成部分,用于缓存地址转换关系,也就是记录这VPN和PFN之间的关系,由于TLB距离CPU比较近,所以访问数据的速度相当快,所以利用TLB缓存进行虚拟地址和物理地址转换非常快- 同时对于一个页中的数据,
VPN相同,但是偏移量不同,所以只需要存储一个页面的VPN和PFN之间的关系就可以找到全页的数据 - 对于
TLB未名中的处理方式(软件处理): 当查询到TLB中没有相应的转换的时候,硬件就会发出一个异常,把控制权交给操作系统,操作系统执行相应的异常处理程序,查询物理内存中的页表项并且把页表项更新到TLB中,之后重试这一条指令导致TLB命中 - 对于
TLB中的内容,必须存在PFN和相应的VPN,同时还需要有效位等(这里的有效位仅仅标记是否时有效的地址映射,页表中的有效位标记是否使用这一个页面),同时有一些系统为了方便上下文切换,防止上下文切换的时候失去之前进程的虚拟内存地址映射缓存,还会存储一些与进程PID有关的位,一种TLB中项的组织方式如下:
- 最后谈到缓存一定会讨论的一个主题就是驱逐方式,常见的驱逐方式比如
LRU,LFU等,之后继续讨论 TLB的出现解决了页表访问速度慢的缺点
多级页表和分段
- 为了解决页表过大的问题,提出了两种方法: 分段和分页结合和多级页表
分段和分页结合
- 这里发现页表过大的一个原因就是页表中需要存储地址空间中所有虚拟页面的
PTE,这就会导致很多没有没有使用的地址空间仍然被分页并且占用页表 - 所以解决方法就是给每一个段一个页表,每一个段进行分页,这样一个页表中只需要存储表较少的表项,最重要的是,没有使用的段就没有对应的
PTE了,这就减少了页表占用的空间,此时虚拟地址的组织方式如下:
- 但是这一种方式的缺点就是: 页表的大小不同,回造成比较多的外部碎片
多级页表
- 核心思想: 把原来的页表分到很多页面中,如果整个页面的页表中都没有有效的数据,直接不分配这一个页的页表即可,同时使用页目录的结构来寻找页表页,组织方式:
- 所以为了标记页目录和页表的位置虚拟地址的组织方式如下:
- 另外有时候如果页目录的大小比较大(比如页目录比较到到时无法放入到一个页面中,此时就需要多级分页),比如对于三级页表的虚拟地址的组织方式如下(寻地址方式和二级一样):
- 利用一个多级页表的缺点就是当
TLB寻址失败的时候就会导致需要多次访问物理内存才可以确定一个地址的实际位置
超越物理内存
机制
- 有时候物理内存比较小,所以我们的目标就是扩展物理内存(比如有时候计算机的内存只有
4GB,却可以运行8GB程序),机制就是使用了交换分区,也就是回利用硬盘中的空间来存储一些页面并且这一部分位置被成为交换分区,交换分区中的分页会与物理内存中的分页进行交换,比如:
- 为了标记一个页面是否存在于物理内存中,
PTE中利用一个存在位来标记一个页面是否存在于物理内存中,同时可以利用这一个位来标记是否存储硬盘中数据的地址 TLB发现页面不在物理内存中就会发生页错误(缺页故障),此时就会发出异常交给操作系统的却页处理程序来处理,这一个程序会首先找到一个可用的物理页面(基于驱逐算法或者空闲的页),之后把这一个数据交换到物理内存中,同时重试指令(当然此时访问TLB时还是会发生重试)- 另外交换发生的时间还会基于一定的算法
策略
- 主要是各种驱逐算法:
FIFO也就是驱逐最先加入的页Random随机算法LRU(如果在循环的例子中命中率很差)- 近似
LRU: 通过硬件模拟LRU,比如利用几个寄存器记录优先级别(每一次访问就会把优先级别-1),当优先级减少为0就会驱逐
VAX/VMS虚拟内存系统
- 页表的组织方式: 使用分段 + 分页
- 地址空间的组织(和
Linux系统太不一样了):
- 替换策略: 利用
FIFO,为么以一个进程设置一个RSS(驻留集大小),当该进程需要的页面超过RSS的时候就会驱逐首先加入的页面,如果一个页面真的被驱逐,会有一个二次机会队列,如果是干净的页就加入到干净页队列,脏页就加入到脏页队列,如果一个进程需要新的页面就在干净页队列中找对应的页,如果一个进程需要回收原来的页面,首先在脏页队列中寻找(这就体现了软件控制逻辑和硬件控制逻辑的区别,软件可以通过不同的数据结构来提高效率,但是硬件本身具有比较快的速度) - 页聚集: 把脏页列表中的页聚集在一起并且一起写入到磁盘中
- 比较好的虚拟内存技巧:
- 按需要放置
0: 操作系统在页表中标记不可以访问的条目,当进程需要读写这一个空间的时候就会导致操作完成物理寻址并且置0,并且映射到进程的地址空间中 - 写时赋值(
copy-on-write): 如果多个地址空间共享一个页,那么就把这一个页标记为只读,如果有一个进程写这一个页就会进入操作系统,操作系统就会分配新的页面,并且把这一个页面的数据复制到新的页面中,这就使得共享库不会占用进程空间,并且fork就是利用这一种机制完成创建子进程的
- 按需要放置
- 最后: 以上的所有讨论中物理页面可能存在于物理内存或者高速缓存中(高速缓存的访问也是使用物理地址),可以参考 csapp 中讲解缓存的一个章节
参考教材: 《《计算机网络:自顶向下方法》》 参考教程: https://www.bilibili.com/video/BV1JV411t7ow/?spm_id_from=333.337.search-card.all.click&vd_source=b419802666550a8f77628730aa29c06b 这里主要是对课程的一些总结(自己不熟悉的地方)以及自己的一些思考
概论
主要内容概括
- 计算机网络中的每一层具有一定的功能,并且提供一定的服务,功能和服务:
- 功能: 也就是具体协议需要具有的功能,比如
TCP的可靠数据传输等 - 服务: 也就是功能具体的应用,比如
cdn,p2p网络应用等
- 功能: 也就是具体协议需要具有的功能,比如
- 为什么会有数据平面和控制平面:
- 网络工作的传统方式: 网络层中利用
IP协议和路由协议,路由协议也就是运行在路由器上的软件也就是不同路由器之间交换信息,通过这一些信息获得路由表,同时IP协议使用路由表,也就是根据路由表来确定发送数据的目的地 - 软件定义网络: 分为数据平面(交换机)和控制平面(网络操作系统), 控制平面计算流表并且发送给数据平面,数据平面接受了流表之后就可以通过流表中的数据来确定分组的目的地址等信息,这一种设计方式其实就是实现了可编程的网络,可以通过在控制平面中加入各种不同的功能来拓展网络的功能
- 网络工作的传统方式: 网络层中利用
- 不同的层之间,使用下一层的接口为上一层提供服务:
- 链路层: 通过链路层协议完成点到点的数据传递
- 网络层: 通过网络层协议完成端到端的数据传递
- 传输层: 网络层提供的是一种尽力而为的协议,传输层为网络层提供更加可靠的协议
- 应用层: 指定不同的应用层协议,用于不同设备上应用程序的数据交互
什么是internet
- 网络: 由节点和边构成
- 计算机网络:
- 节点:
- 主机节点(比如计算机,移动设备等,也就是各种端系统(就是指的主机))
- 数据交换设备,比如路由器,防火墙,负载均衡设备等
- 边(链路):
- 接入网: 主机设备与数据交设备相连的边
- 骨干链路: 数据交换设备之间的边
- 协议:
- 具有对等地位的两个设备之间交换数据的规则,包含数据的个数,语法,语义以及发送顺序等规则
- 节点:
- 因特网:
- 两种视角:
- 网络连接视角: 各种不同的网络通过网络互连设备连接起来的一个更大的网络
- 分布式应用程序的视角: 为分布式应用程序提供数据交换功能的基础设备,提供的服务可以是可靠的也可以是不可靠的
- 两种视角:
网络结构
- 网络结构的大体结构如下:
网络边缘
- 网络边缘包含各种端系统和运行在端系统上的各种主机进程(应用程序)
- 如果不考虑网络核心和接入网,端系统中通信模型包含如下几种:
C/S架构,也就是客户端服务器端架构B/S架构,也就是浏览器服务器端结构P2P架构,同一个端系统可以作为客户端或者服务器端并且不同的主机可以向同一个主机发送数据,比如迅雷的服务器,在下载的时候可以使用不同的服务器向同一个主机发送数据
- 网络边缘中各种端系统之间数据传递的基础: 应用层协议(包含
TCP,UDP等)
网络核心
- 网络核心的主要作用就是进行不同的端系统(网络边缘)之间的数据交换,数据交换的方式分为线路交换和分组交换
- 线路交换: 通过信令在两个主机之间建立一条连接,这一条连接可以使用频分复用,时分复用,波分复用等方式建立连接:
- 频分复用: 对于一定带宽的链路(带宽的单位为
bps),为每一条连接划分一个频率区间,每一条连接使用对应的频率空间即可 - 时分复用: 类似于操作系统进行进程的调度,也就是把一个周期划分为不同的时间片,每一个用户独享一个时间片
- 波分复用: 每一条连接使用不同的波长,用于光纤通信 但是线路交换存在一些缺点: 比如如果通信链路空闲就会造成资源的浪费,由于使用了复用的技术,信息传输的延时时间比较长
- 频分复用: 对于一定带宽的链路(带宽的单位为
- 分组交换: 把需要交换的数据分组,分组到达每一个路由器的时候,路由器存储分组并且在一定的之间之后发送分组(如果阻塞分组会排队发送)
- 分组交换的优点: 可以完成不同主机对于链路的共享,充分利用了资源
- 分组交换的缺点: 排队延迟时间,分组丢失,存储时间等
- 利用分组传输数据的方式:
- 数据报: 比如
TCP,UDP,无连接的,也就是路由器不知道主机之间建立了连接,只是主机直到彼此建立了连接(注意面向连接只是指端系统之间建立了连接) - 虚电路: 也就是不同的路由器建立虚电路表,分组根据虚电路表传播,这是一种有连接的通信方式(有连接体现在不仅仅是两台主机直到自己建立了连接,路由器也知道建立了连接)
- 数据报: 比如
接入网和物理媒体
- 接入网的类型:
DSL,电缆等: 依赖于调制解调器,不同的频率段用于传输不同的数据- 以太网和
WIFI: 相当于不同的主机连接到同一个局域网的以太网交换机,这一个交换机向外界转发数据 - 广域无线接入
- 物理媒介: 光纤,卫星通信等
Internet结构与ISP
Internet是网络的网络,也就是不同的主机接入到不同的ISP(Internet Service provider) , 不同的ISP之间又通过会发生级联,从而构成了网络的网络,同时一些大厂也会建立自己的数据中心从而加速自家的服务中的数据交换速度
分组时延,丢失和吞吐量
- 分组时延包含如下几个组成部分:
- 处理时延: 也就是一个路由器处理分组所需要的时间(比如进行路由表拆查询,差错校验等操作)
- 排队时延: 也就是一个分组在缓冲队列中排队所需要的时间(注意可以利用流量强度的方式来衡量排队时延,比如分组到达队列的速度为
a分组/s, 每一个分组的大小为L bit,那么流量强度 $I = \frac{La}{R}$ ) , 其中R就是传输速率(也就是打出一个比特的速率),如果流量强度趋近于1就会导致传输时延接近与无穷大 - 传输时延: 打出一整个分组需要的时间: $d = \frac{L}{R}$ ($L$ 表示分组的长度,$R$ 表示打出一个比特的速率,$\frac{1}{R}$ 表示波特率)
- 传播时延: 也就是信号传递的时间
- 丢包的原因: 分组到队列的速度大于队列的最大容量导致分组丢失
- 吞吐量: 也就是目的主机单位时间可以接收到的分组的数量(也就是可以接收到的数据大小),本身描述的是速率,注意吞吐量取决于两个端系统之间的链路中的可用带宽的最小值
python虚拟环境管理
- 虚拟环境用于防止不同的
python项目之间发生依赖冲突的问题
$ python3 -m venv myenv // 创建虚拟环境
$ source myenv/bin/activate // 激活虚拟环境
(myenv) $ deactivate // 退出虚拟环境
python -m venv --clear path/to/venv // 删除虚拟环境
- 虚拟环境中创建了
python解释器的副本还有各种库