Redis在工程中的应用可以参考项目: https://github.com/xzwsloser/heima-comment.git
Redis介绍
- Redis是一个键值对数据库,里面存储的就是一个一个又一个的字符串,其中键值可以是用户id,另外值可以是一个json字符串用于存储各种数据
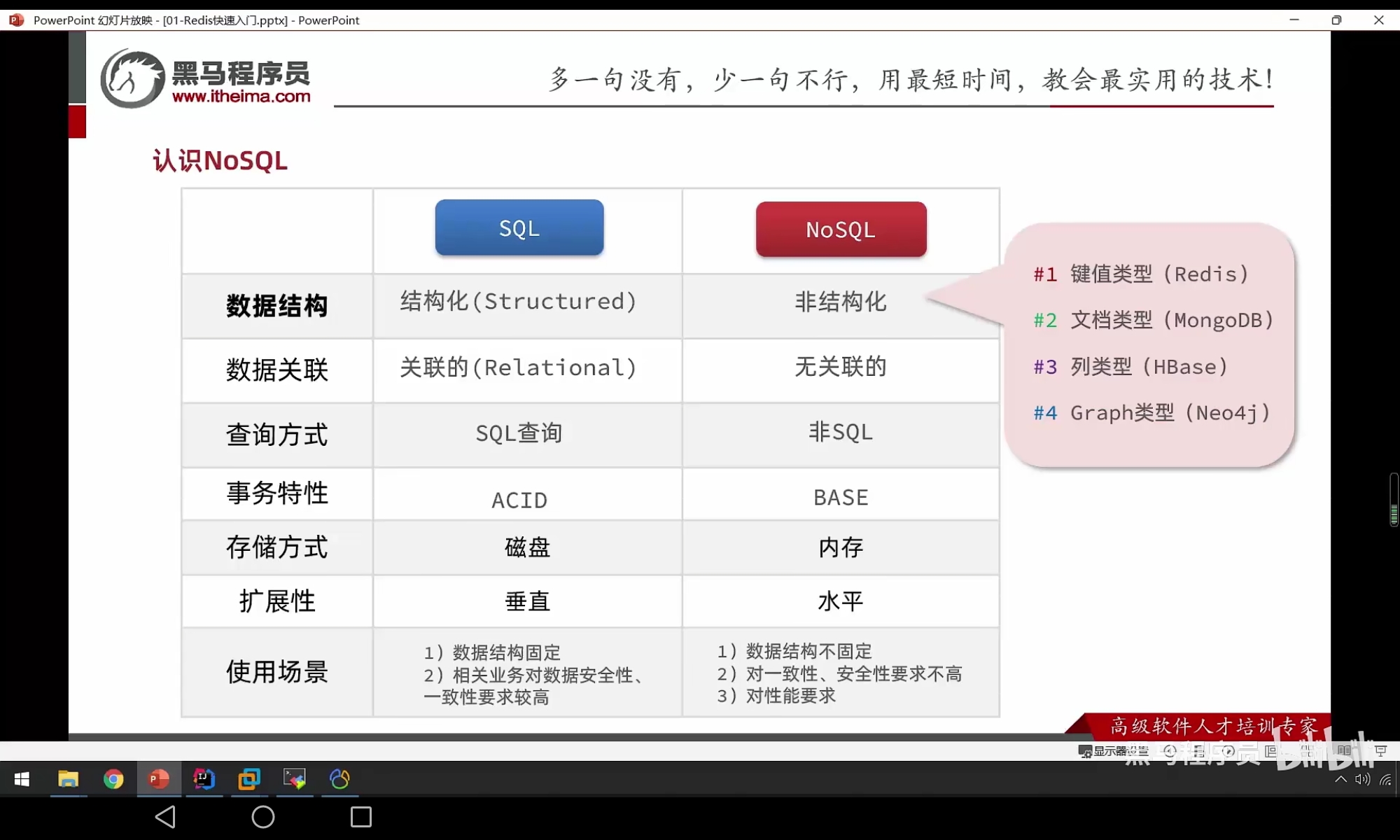
NoSQL
- 表示非关系性数据库,比如sql(s表示结构化,其中的数据需要满足各种约束),但是NoSQL是非结构化的,字段约束没有那么强,存储的一个数据其实就似乎一个节点,每一个节点中可以形成一个图,并且结构改变对于NoSQL的影响较小
- 另外就是关系型和非关系型,关系型数据库其实就是不同表之间通过外键相互关联,但是NoSQL中没有关联,数据存储中可能会存在重复的现象
- 非SQL型的,没有固定语法对于数据进行查询,就是操作数据库没有固定的语法,但是语法较为简单
- 所有关系型数据库都满足事物的ACID特性,但是非关系型数据只是基本满足ACID特性
- NoSQL中的数据类型有: 键值类型(Redis),文档类型(MongoDB),列类型(Hbase)和Graph(Neo4j)类型
- SQL和NoSQL的详细比较和使用场景 :
Redis是什么
Redis的各种特征
- 键值(key-value)型,value支持多种不同的数据类型,功能丰富
- 单线程,每一个命令具有原子性(不会产生线程安全的问题)
- 低延迟,速度快(基于内存(直接从内存中读取数据比 从磁盘中读取数据更快),IO多路复用,良好的编码习惯)
- 支持数据持久化(定期把数据从内存写入到磁盘中)
- 支持主从集群,分片集群
- 支持多语言客户端
redis在linux中的部署
- 具体安装步骤如下:
:::info sudo apt install -y gcc // 安装gcc的依赖
sudo mv redis7.2.4.tar.gz /usr/local/src/ // 移动到一个目录下,这一个目录通常用于安装软件(相当于windows的下载目录)
sudo tar -zxvf redis7.2.4.tar.gz // 注意前面的sudo
cd redis // 进入目录
sudo make && make install // 利用makefile编译
sudo chown -R ubuntu:ubuntu /usr/local // make失败的解决方案
cd /usr/local/bin // 查看是否安装成功
// 安装不成功就需要安装 pkg-config
sudo apt install -y pkg-config
// 另外可以利用 wget下载 安装包
:::
- 之后的配置信息如下(使得后台启动配置)
:::danger cp redis.conf redis.conf.bck // 拷贝一份文件
// 配置文件信息
bind 0.0.0.0 // 使得每一个都可以访问
daemon... yes// 配置守护进程
requirepass 密码
logfile 日志文件名称
// 其实还可以配置多个文件
// 最后就可以通过 redis-server 后台运行redis了
// 通过ps -ef 命令查看进程
利用 kill -9 进程号 终止进程
:::
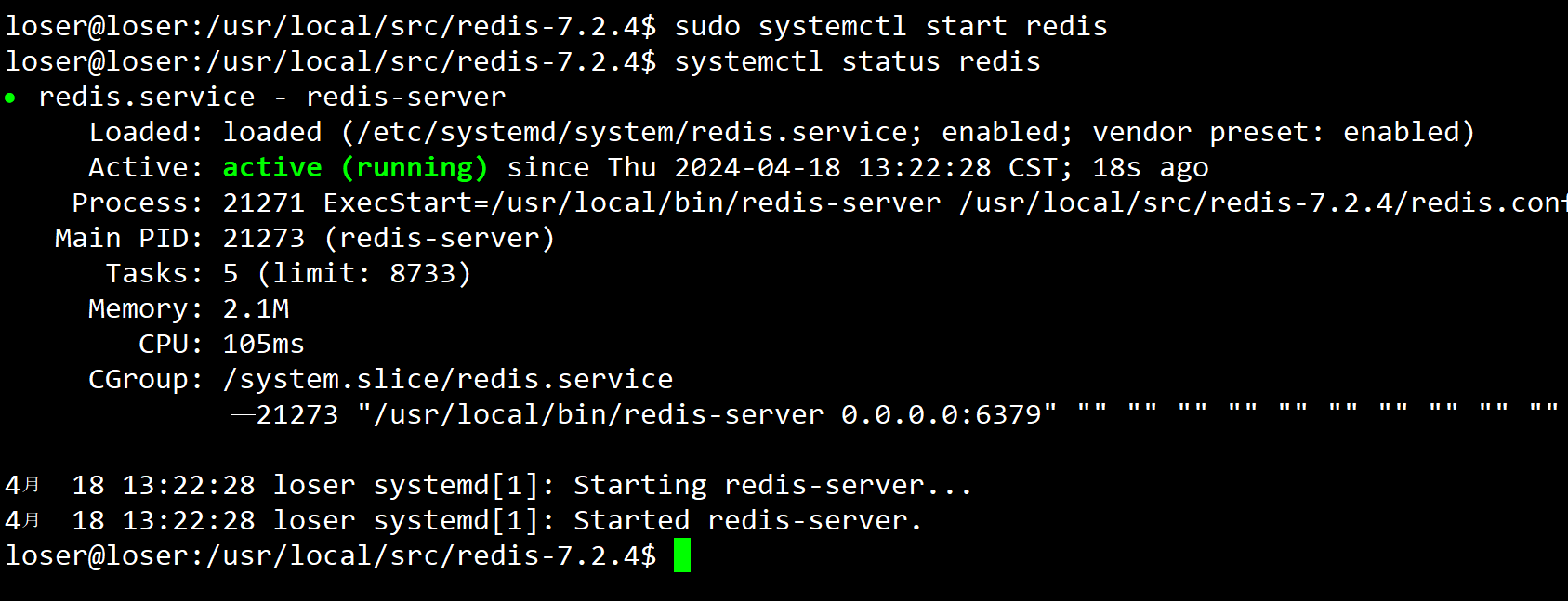
- 配置开机自启动
:::success 首先添加配置文件
sudo vim /etc/systemd/system/redis.service
添加配置信息
。。。 。。。
启动
sudo systemctl daemon-reload
开启或者结束
sudo systemctl start/stop/status/enable redis 即可
// 设置开机自启动只用配置相关信息之后利用 enable启动服务即可
sudo systemctl enable redis
// 一定要注意 systemctl命令
:::
- 终于成功了
Redis客户端的运用
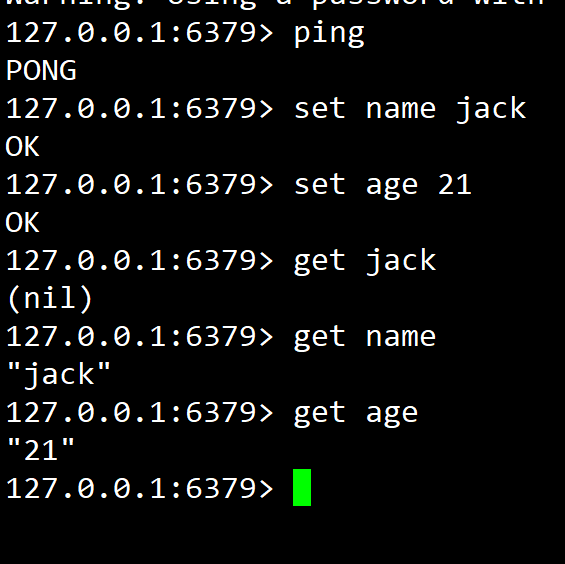
- redis的各种客户端
- 命令行客户端 ctl结尾的 (启动方式: redis-ctl [-h 地址 -p 端口号(6379) -a 密码] commands,成功之后的现象,其实也可以不用指定密码进入之后 就可以利用 AUTH指定密码啦:

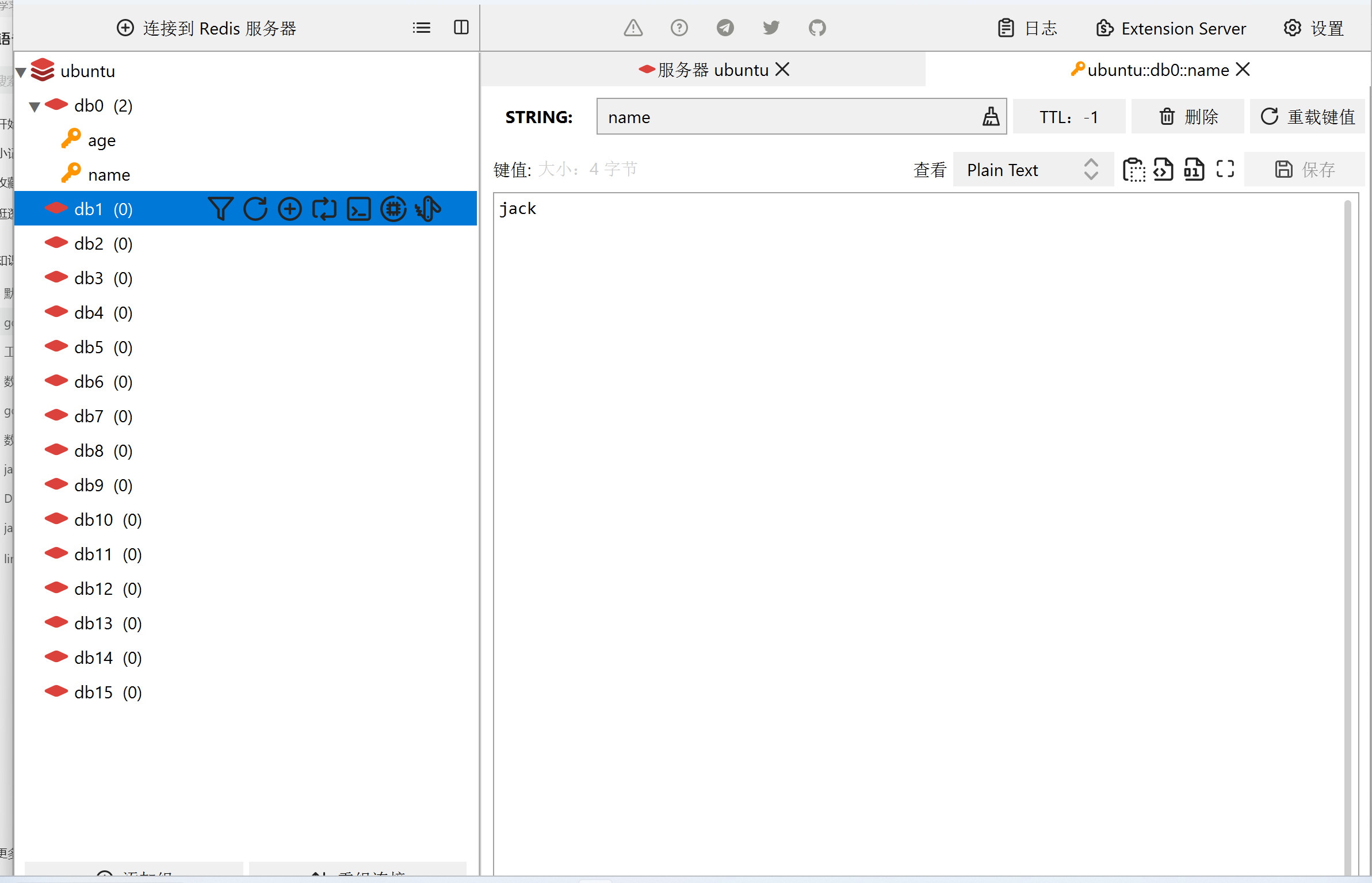
- 图形化客户端: 开源地址: github.com/uglide/RedisDesktopManager,免费地址: github.com/lework/RedisDesktopManager-Windows/releses
图形化界面操作图像:
Redis数据结构介绍
- Redis是一个key-value的数据库,但是key一般是String类型的,但是value的类型多种多样,大致分为两类:
- 基本数据类型: String,Hash,List,Set,SortedSet
- 特殊数据类型:GEO,BitMap,HyperLog
- Redis的帮助文档(基本包含所有命令): https://redis.io/docs/latest/commands/
- 后者可以利用help命令查询命令:
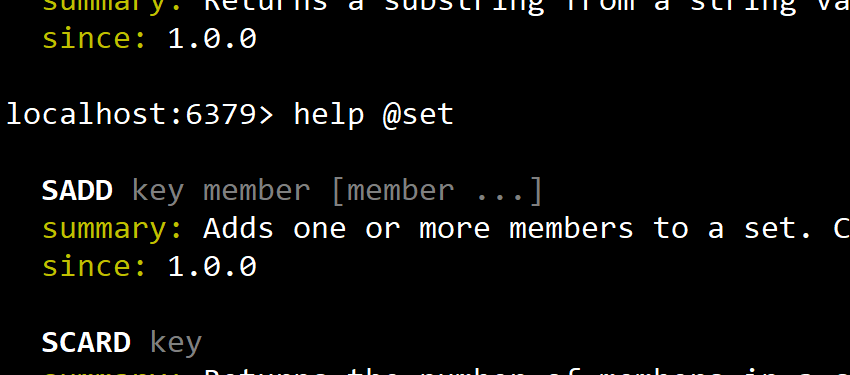
Redis通用命令
- 官方文档中可以查看,同时可以利用命令行客户端查看
- 可以利用help 命令名 查看命令的使用方法
常见指定
- Keys : 用以匹配各种格式的键值数据,例如 keys name* ,由于命令查询效率较低并且容易阻塞服务所以在生产环境下一般少使用
- DEL: 删除指定的key值 例如 del name age ... ... ,可以删除多个字段,会有一个返回值代表删除了几个值
- Exists 判断一个key值是否存在 例如 : exists name,返回值就是 0 或者 1
- Expire: 给一个Key值设置一个有效期,目的就是只在一段时间内缓存数据,防止数据的数量过大 ,例如 expire key1
- TTL : 查看一个key值的有效期 语法: TTL 键的名称 ,利用TTL查询数据表示被删除 或者返回-1表示不会被删除
Redis各种数据类型常用命令
String类型常用命令
String类型的介绍
- String类型就是字符串类型,最简单那的存储类型,注意数据类型都是value的类型
- value是String类型,但是根据字符串的格式不同,又分为一下几种类型:
- string 普通字符串
- int 整数类型,可以进行相应的运算操纵
- float: 浮点类型,可以做运算操作
- 最大空间不会超过512m
常用命令如下
- SET: 向redis中添加一个或者修改一个已经存在的string类型的键值对
- GET: 根据Key值获取String类型的value值
- MSET: 批量添加键值对数据
- MGET: 根据多个键获取多个值
- INCR: 让一个整数的key值自增1
- INCRBY: 让一个整形的key值自增并且指定步长,例如 incrby num 2表示num自增2,值改为负数就可以自减啦
- INCRBYFLOAT: 让一个浮点数自增并且指定步长,但是对于整数使用这个指令就会把他变成浮点数
- SETNX: 添加一个键值对数据,前提是这一个 key不存在,否咋不执行,返回值 是是否成功,和set key value nx作用类似
- SETEX: 添加一个string类型的键值对并且指定有效期, 语法 setex key 有效期 value,和 set key value ex 有效期 相同
key的层级格式
- Redis中的key允许多个单词组成的层级结构,多个单词之间可以使用 : 分隔开,格式如下 : 项目名:业务名:类型:id , 比如 heima : user :id
- 如果value是一个java对象,就可以使用JSON可是的字符串存储数据,演示如下:
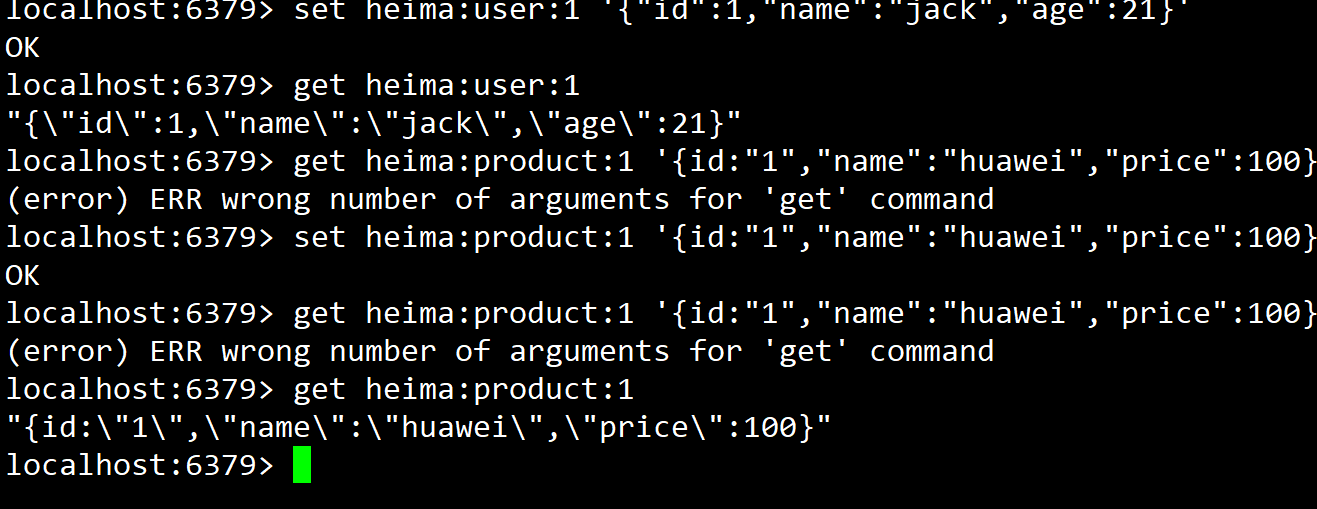
- 层级结构演示:
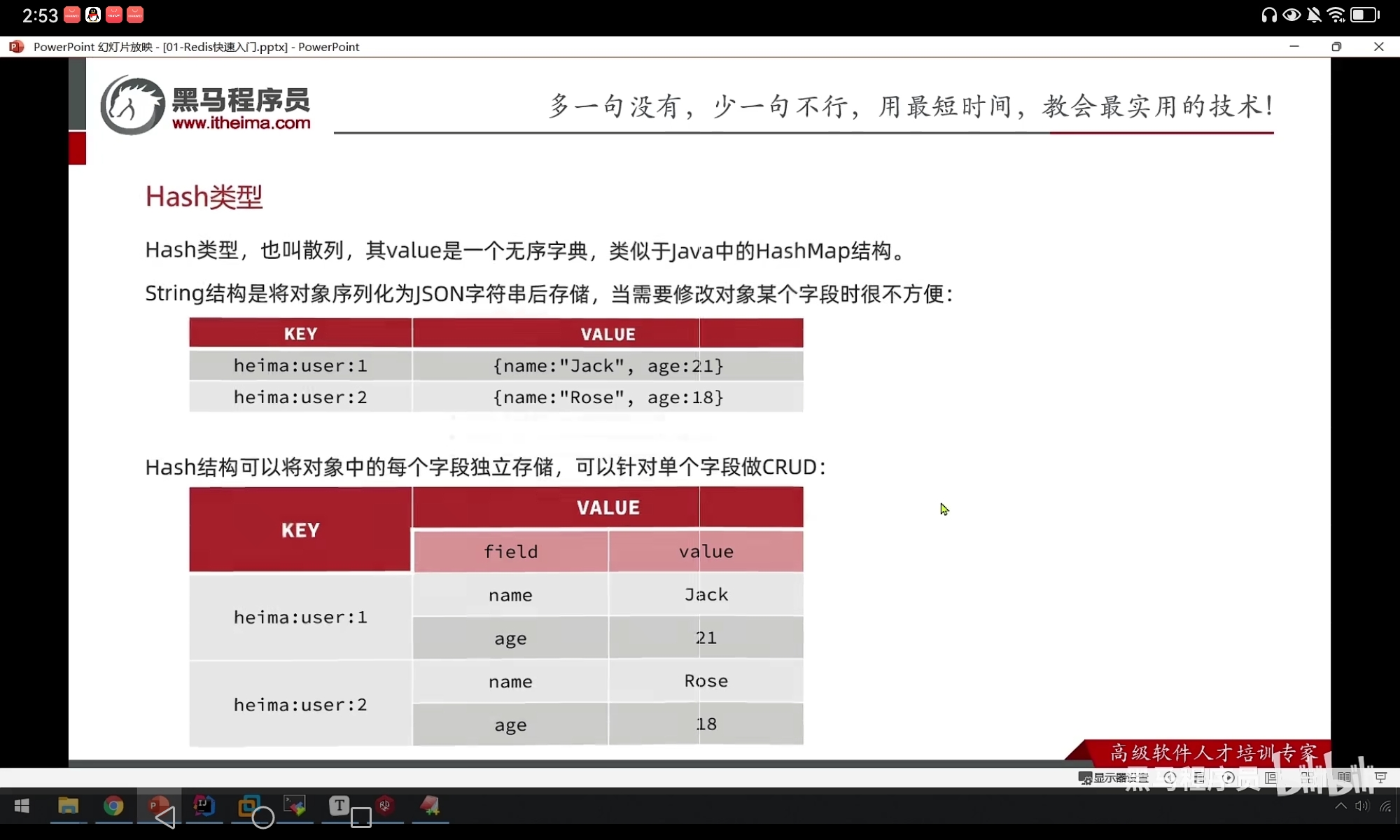
Hash类型
Hash类型结构介绍
- Hash类型也叫做散列,其value是一个无序字典(其实就是key值也是一个有一个键值对),相当于java中的hashmap
- key都是 string类型的,这里指的就是 value 就是 hash 类型的
- Hash结构演示:
Hash类型中的常见命令
- HSET key field value : 表示添加或者修改hash类型的 key 的field值
- HGET key field : 获取一个hash类型的key的field值
- HMSET : 批量添加多个hash类型key的field值(但是每一次可以添加多个字段,但是为什么利用hset也可以)
- HMGET: 获取多个hash类型key的field值
- HGETALL : 获取一个key中记录的多个键值对的值
- HKEYS: 获取一个hash类型中key中的所有field
- HVALS: 获取一个hash类型的key中的所有value
- HINCRBY: 是一个hash类型的字段值自增并且指定步长(退回一级,就是填写以下field字段名即可)
- HSETNX : 添加一个hash类型的key的field值,前提是这一个field不存在(注意判断的额是每一个字段),否咋执行失败
List类型
List类型的介绍
- Redis中的List类型基本和java中的LinkedList类似,可以当成一个双向链表使用,既可以支持正向检索也可以支持反向检索
- List类型的特点基本和链表一致(有序,元素可以重复,插入和删除元素快,查询速度一般)
List中的常见命令
- LPUSH key element ... : 向链表 左侧插入一个或者多个元素(头插法),可以利用图形化界面查看数据顺序
- LPOP key: 移除并且返回列表左侧的第一个元素,没有就会返回 nil
- RPUSH key element ... : 向列表右侧插入一个或者多个元素(尾插法)
- RPOP key : 移除并且返回链表右侧的第一个元素(尾删法)
- LRANGE key start end : 返回一段角标范围内的所有元素
- BLPOP和BRPOP : 和LPOP和RPOP类似,只不过元素没有等待时间,而不是直接指定返回nil (没有元素就是等待一段时间,相当于一个阻塞队列) 语法 lpop 字段名称 等待时间
利用List模拟栈和队列的数据结构
- 利用链表模拟队列 : 出口和入口不在一边(其实就是一边使用 自己的push ,另外一边使用自己的pop)
- 利用链表模拟栈 : 出口和入口在在一边(只可以利用一边的push和pop方法)
- 利用链表模拟阻塞队列 : 基本和队列一致(入口和出口一致),同时取出元素使用BLpop和BRpop
Set类型
Set类型的介绍
- Redis中的set结构基本和java中的hashset类似,可以看作一个value为null的hashmap,因为是一个hash表,所以需要具备和hashset类似的特征(无序,元素不可以重复,查找元素的速度快,支持并集,差集和交集)
Set类型中的常见命令
- SADD key member ... : 向set中添加一个或者多个元素
- SREM key member ... : 移除set中的指定元素
- SCARD key : 返回set中的元素个数
- SISMEMBER key member : 判断一个元素是否存在于set集合中
- SMEMBERS : 获取set集合中的所有元素
- SINTER key1 key2...... : 求解key1 与 key2的交集
- SDIFF key1 key2 ...... : 求解 key1 和 key2的差集
- SUNION key1 key2 ... ... : 求解key1和key2的并集
SortedSet类型
SortedSet 介绍
- Redis中的SortedSet是一个可排序的set集合,和java中的Treeset类似,但是底层的数据结构相差较大,SortedSet中的每一个元素都带有一个score属性,可以基于score属性对于元素进行排序,但是底层是一个跳表(SkipList) 加上一个 hash表
- 特点:
- 可以排序
- 元素不可以重复
- 查询速度快
- 可以用于做排行榜等功能
SortedSet的常见命令
- ZADD key score member : 添加一个元素或者多个元素到sorted set集合,如果已经存在就会更新它的score值(就是member 对应的分数)
- ZREM key member : 删除一个sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member : 获取sorted set中的指定 元素的排名
- ZCARD key : 获取sorted set中的元素的个数
- ZCOUNT key min max : 统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member : 让sorted set中的指定元素自增,步长为指定的额increment值
- ZRANGE key min max : 按照 score排序之后,获取指定排名范围内的元素(但是根据角标排序,角标默认 从0开始)
- ZRANGBYSCORE key min max: 按照score排序之后获取指定的score范围内的元素
- ZINTER ,ZDIFF ,ZUNION: 表示求差集,交集,并集
- 注意所有的排名都是升序的,如果降序就需要在命令的后面添加REV即可
利用golang操作redis数据库
- 利用go-redis操作redis数据库,相应的客户端的github地址 : https://github.com/redis/go-redis
安装 go-redis库
- 利用 go get安装go-redis库
:::success // redis 6
go get github.com/go-redis/redis/v8
// redis 7
go get github.com/go-redis/redis/v9
// 现在是
go get github.com/redis/go-redis/v9
:::
使用 go-redis库
连接redis
- 连接方式如下(入门代码演示):
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
var rdb *redis.Client
func init() {
rdb = redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0, // 和集群相关
})
}
func main() {
// 入门引用
ctx := context.Background()
err := rdb.Set(ctx, "test-key", "test-value", 0).Err() // 表示不会过期
if err != nil {
panic(err)
}
// 首先拿到相应的值
result, err2 := rdb.Get(ctx, "test-key").Result()
if err2 != nil {
panic(err2)
}
fmt.Println(result)
// 如果使用原生命令就可以使用Do函数
result1, err3 := rdb.Do(ctx, "get", "test-key").Result()
if err3 != nil {
panic(err3)
}
fmt.Println(result1.(string))
}
redis中string类型应用
- 除了其中的GetSet方法之外其他的方法基本就是原生的命令,基本就是利用上下文路径进行操作,基本的操作和命令差不多
- 部分函数的代码演示:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
"time"
)
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
// 获取成功之后插入数据
ctx := context.Background()
err := rdb.Set(ctx, "newk1", "v1", 0).Err()
if err != nil {
panic(err)
}
// 演示 GetSex方法 , 获取到的就是一个老的值
// 但是新的值已经被改变了
result, err := rdb.GetSet(ctx, "newk1", "newv1").Result()
if err != nil {
panic(err)
}
fmt.Println(result)
// 演示setnx方法
err = rdb.SetNX(ctx, "newk1", "newnewv1", 0).Err()
if err != nil {
panic(err)
}
result1, _ := rdb.Get(ctx, "newk1").Result()
fmt.Println(result1)
// 演示批量设置和批量查询
// 批量查询数据,利用mget方法
result2, _ := rdb.MGet(ctx, "k1", "k2", "k3").Result()
fmt.Println(result2)
// 演示批量插入的方法
err = rdb.MSet(ctx, "key1", "value1", "key2", "value2", "key3", "value3").Err()
if err != nil {
panic(err)
}
// 演示自增方法 incr incrby incrfloatby
rdb.Set(ctx, "num1", 12, 0)
// 自增
result4, err := rdb.Incr(ctx, "num1").Result()
if err != nil {
panic(err)
}
fmt.Println(result4)
// 演示另外的自增方法
result5, err := rdb.IncrBy(ctx, "num1", 9).Result()
if err != nil {
panic(err)
}
fmt.Println(result5)
// 演示浮点数的自增方法
result6, err := rdb.IncrByFloat(ctx, "num1", 2.2).Result()
if err != nil {
panic(err)
}
fmt.Println(result6)
// 自减的操作 ,其实就是改为 dsc 或者改为负数
// 删除 数据 Del可以批量删除
err = rdb.Del(ctx, "k1", "k2", "k3").Err()
// 每一个函数有一个返回值有一个异常值应该总和运用
if err != nil {
panic(err)
}
// 利用expire函数设置过期时间
err = rdb.Expire(ctx, "num1", 10*time.Second).Err()
if err != nil {
panic(err)
}
i, err := rdb.Exists(ctx, "num1").Result()
fmt.Println(i)
}
hash结构的常用方法
- 重点注意 oop的思想,其中hset,hmset方法第二个参数可以传递一个对象过去
- 代码演示:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 演示hash中的方法
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
// 演示 HSet
ctx := context.Background()
err := rdb.HSet(ctx, "hash1", "count", 1).Err()
if err != nil {
panic(err)
}
// 演示 HGet
result, err := rdb.HGet(ctx, "hash1", "username1").Result()
fmt.Println(result)
// 演示 HGetAll
result1, err := rdb.HGetAll(ctx, "hash1").Result()
fmt.Println(result1)
// 演示 Hincrby , 其实就是累加元素
result3, err := rdb.HIncrBy(ctx, "hash1", "username1", 2).Result()
fmt.Println(result3)
// 演示 hkeys
result4, err := rdb.HKeys(ctx, "hash1").Result()
fmt.Println(result4)
// 演示字段数量 hlen
len, err := rdb.HLen(ctx, "hash1").Result()
fmt.Println(len)
// 批量查询
result5, err := rdb.HMGet(ctx, "hash1", "username1", "count").Result()
fmt.Println(result5)
// 批量设置,可以利用map结合设置
data := make(map[string]interface{})
data["username2"] = "lisi"
data["index"] = 1
err = rdb.HMSet(ctx, "key", data).Err()
// 利用 hsetnx
err = rdb.HSetNX(ctx, "hash1", "username1", "wangwu").Err()
// 演示 hdel 删除操作
err = rdb.Del(ctx, "hash1", "username1").Err()
// 所有字段删除之后键值就会消失
}
List类型中的常用方法
- 没有见过的方法有 :
- Lindex: 根据索引寻找元素
- LpushX等 : 如果有相应的键值才会插入元素,否咋不会插入元素
- LRem: 删除元素,可以指定删除位置和删除次数
- LInsert: 插入元素,可选在之前还是之后插入元素
- 代码演示如下:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
// 演示 List集合中的常见方法
// Lpush , Rpush
ctx := context.Background()
err := rdb.LPush(ctx, "list", 1, 2, 3, 4, 5, 6, 7).Err()
if err != nil {
panic(err)
}
err = rdb.RPush(ctx, "list", 8, 9, 10, 11, 12, 13).Err()
// 演示 Lpop,Rpop方法
result, err := rdb.LPush(ctx, "list").Result()
fmt.Println(result)
result2, err := rdb.RPop(ctx, "list").Result()
fmt.Println(result2)
// lpushx , rpushx 方法 ,就是相当于 setnx
// 只有链表存在才会插入数据
result3, err := rdb.LPushX(ctx, "list1", 1, 2, 3).Result()
fmt.Println(result3) // 控制台信息
// 演示 LLen返回链表长度
result5, err := rdb.LLen(ctx, "list").Result()
fmt.Println("链表的长度为", result5)
// 演示 Lrange方法 , 其中停止位置为 -1 表示取出全部元素
vals, err := rdb.LRange(ctx, "list", 0, -1).Result()
fmt.Println(vals)
// 演示 lrem函数,用于删除 元素 ,后面第一个参数就是删除次数(可以指定删除次数),后面就是删除的值
// 返回的就是删除次数 , rrem也是一样
// 如果参数是 负数的话就表示从右边开始删除
// 如果参数是 0 的话就表示 删除 所有符合条件的元素
result6, err := rdb.LRem(ctx, "key", 1, 100).Result()
fmt.Println(result6)
// 演示 lindex 函数
// 根据索引坐标查询数据
val, err := rdb.LIndex(ctx, "list", 4).Result()
fmt.Println(val)
// 演示在指定位置插入数据
// 演示 linsert函数 , 参数中的options参数表示在之前还是之后插入元素
// 可选 after或者 insert, 之后的参数 pivot表示对象名称,这里就是在 5 的前面插入 9
err = rdb.LInsert(ctx, "list", "before", 5, 9).Err()
}
Set类型中的常用方法
- 与命令不同的只有:
- SPop,SPopN : 随机删除元素
- 但是其他的命令一定要记住
- 代码演示如下:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 用以演示 set类型的方法
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
ctx := context.Background()
// 首先是 sadd方法添加元素
err := rdb.SAdd(ctx, "set", 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15).Err()
if err != nil {
panic(err)
}
// 演示 srem方法删除元素
err = rdb.SRem(ctx, "set", 1).Err()
// 演示获取集合元素个数 scard
result, err := rdb.SCard(ctx, "set").Result()
fmt.Println(result)
// 演示随机删除 元素 spop
result4, err := rdb.SPop(ctx, "set").Result()
fmt.Println(result4)
// 随删除多个元素
result5, err := rdb.SPopN(ctx, "set", 2).Result()
fmt.Println(result5)
// 判断元素是否 在集合中 sismemeber
result2, err := rdb.SIsMember(ctx, "set", 2).Result()
fmt.Println(result2)
// 获取所有元素 smembers
vals, err := rdb.SMembers(ctx, "set").Result()
fmt.Println(vals)
// 演示集合方法 差集 交集和并集
err = rdb.SAdd(ctx, "set1", 1, 2, 3, 4, 56, 57, 58, 59).Err()
result6, err := rdb.SDiff(ctx, "set", "set1").Result()
fmt.Println(result6)
result7, err := rdb.SUnion(ctx, "set", "set1").Result()
fmt.Println(result7)
result8, err := rdb.SInter(ctx, "set1", "set2").Result()
fmt.Println(result8)
}
// 演示可变参数
func manyParameters(key ...int) {
for _, ele := range key {
fmt.Println(ele)
}
}
sorted set中的常用方法
- 方法基本一样,但是注意事项如下:
- 首先 函数的 z 后面加上 rev表示降序排列,最后加上 withscores表示带回分数
- 代码演示如下:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 用于演示 sorted set中的常见方法
rdb := redis.NewClient(&redis.Options{
Addr: "192.168.59.132:6379",
Password: "808453",
DB: 0,
})
// 演示 zadd 方法
ctx := context.Background()
err := rdb.ZAdd(ctx, "sorted-set", redis.Z{Score: 100, Member: "zhangsan"}).Err()
if err != nil {
panic(err)
}
// 演示 zcard函数
result, err := rdb.ZCard(ctx, "sorted-set").Result()
fmt.Println(result)
// 演示统计函数 zcount 函数 统计范围, 可以指定是否开闭区间
result2, err := rdb.ZCount(ctx, "sorted-set", "80", "99)").Result()
fmt.Println(result2)
// 增加操作
result3, err := rdb.ZIncrBy(ctx, "sorted-set", 2, "zhangsan").Result()
fmt.Println(result3)
// 演示排序操作 zrange 和 zrevrange(表示降序排列)
result4, err := rdb.ZRange(ctx, "sorted-set", 0, -1).Result()
fmt.Println(result4)
// 演示按照分数查找
op := redis.ZRangeBy{
Min: "70",
Max: "100",
Offset: 0, // 相当于 sql中的limit,从第几条语句开始查询
Count: 3, // 表示返回的记录条数
}
result5, err := rdb.ZRangeByScore(ctx, "sorted-set", &op).Result()
fmt.Println(result5)
// 演示 zrangebysocrewithsocre ,返回元素和分数
result6, err := rdb.ZRangeByScoreWithScores(ctx, "sorted-set", &op).Result()
fmt.Println(result6)
// 删除元素可以使用 zrem,zremrangebyrank(利用索引删除元素),zremByscore(表示根据分数范围删除元素)
// 查询分数
result7, err := rdb.ZScore(ctx, "sorted-set", "zhangsan").Result()
fmt.Println(result7)
// 查询排名 , 同时可以加上 withscores后缀找到分数,zrevrank也可以找到
// 注意排名需要利用 索引 + 1
result8, err := rdb.ZRank(ctx, "sorted-set", "zhangsan").Result()
fmt.Println(result8)
}
redis 连接池
- 相当于 JDBC 中的 druid 连接池
- 实现初始化好一个连接池,需要使用连接时,直接从连接池中取出一个连接
- 提高的效率
redis 连接池的操作
- 利用 redis 连接池的操作