mysql在linux环境下的部署
- 首先可以下载mysql-server服务端(其实也可在官网找到对应的安装包进行安装,其实就是下载rpm包或者tar包,利用tar -zxvf进行解压,注意配置环境变量,首先解压到opt目录下 之后移动到bin目录下)
- 查看mysql服务状态 sudo service mysql status
- 启动mysql服务 sudo service mysql start
- 开始配置用户密码 alter user 'root'@'localhost' indentify with mysql_native_passworld by 'password'
- 启动mysql: mysql -u root -p 即可
- 利用quit就可以退出mysql服务啦
索引
索引的概念
索引是帮助mysql高效获取数据的数据结构(有序),在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构用某一种方式指向数据,这样就可以在这些数据结构中使用高级查找算法,这种数据结构就是索引(实际上是利用二叉树的数据结构),没有索引就会发生全表扫描(效率低下) ,利用索引可以提升查询效率
索引结构
mysql的结构根据不同的存储引擎,但是大致包含B+ Tree,Hash索引,R-tree(空间索引),Full-text(全文索引),但是InnoDB支持B+ Tree(一般都是B+ tree索引)
BTree
- 二叉树的弊端:顺序插入时会退化成一个链表,查询速率降低,并且数据较多时,层级比较深,检索速度慢
B树: 多路平衡查找树,根节点用于存放每一个区间的极大和 极小值,极大和极小值不断向下面分叉,就可以大大降低树的层次,比如利用4个key值就可以有5个指针
B树的构建方式: 根据度的不同根据插入数据的大小,就会发生树的裂变(中间元素向上裂变)
:::warning 分享一个特别好用数据结构可视化的网站: https://www.cs.usfca.edu/~galles/visualization/
:::
B+Tree
- 所有元素都会出现叶子节点,叶子节点会形成一个单链表,非叶子节点的元素都是索引的作用,其实就是向上裂变的过程中会在叶子节点中留下备份,所以这样的话就只用遍历单链表就可以找到对应元素了
- mysql中对于B+Tree进行了改进,把叶子节点的单向链表换成了循环双向链表
哈希索引
- 注意哈希索引只用于等值比较,不支持范围查询(between,<,>)
- 无法利用索引完成排序操作
- 查询效率高,通常只用一次检索就可以了,效率通常高于B+tree索引
索引种类(还是要关注索引的定义,是一种存储数据的结构)
| 分类(存储对象不同) | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 正对于表中主键创建的索引 | 默认自动创建,只可以有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键字,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
InnoDB存储引擎中,根据索引的存储方式,分为以下几种
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 | 将数据存储和索引放在一起了,索引结构的叶子节点保存了行信息 | 必须有并且 只可以有一个 |
| 二级索引 | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引的选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一索引作为聚集索引
- 如果不存在主键,也没有适合的唯一索引,就会自动生成一个rowid作为隐藏的聚集索引
查找方式:
- 一定要通过聚集索引才可以找对对象行信息
- 如果不是通过聚集索引对应的数据进行查询的话,就会首先查询二级索引(每一个字段对应了一个二级索引),通过二级索引找到对应的主键,拿到对应的主键之后再到聚集索引中查询(称为回调查询)
索引的操作语法
创建索引(create index关键字)
- create [unique|fulltext(其实就是索引的类型)] index index_name** on** table_name (index_col_name) (注意索引名称和字段名称不同),如果只为一个字段创建索引就是单列索引
查看索引(show关键字)
- show index from table_name
删除索引(drop index关键字)
- drop index index_name** from** table_name
-- 创建常规索引 注意索引名称的书写 idx_表名_字段名
create index idx_user_name on user(name);
-- 创建唯一索引
create unique index idx_user_phone on user(phone);
-- 创建联合索引(利用同一个索引关联多个字段)
create index idx_user_pro_age_sta on user(profession,age,status);
-- 查看数据表中的索引
show index from user;
-- 删除指定的索引
drop index idx_user_ema from user;
sql性能分析工具
sql性能分析
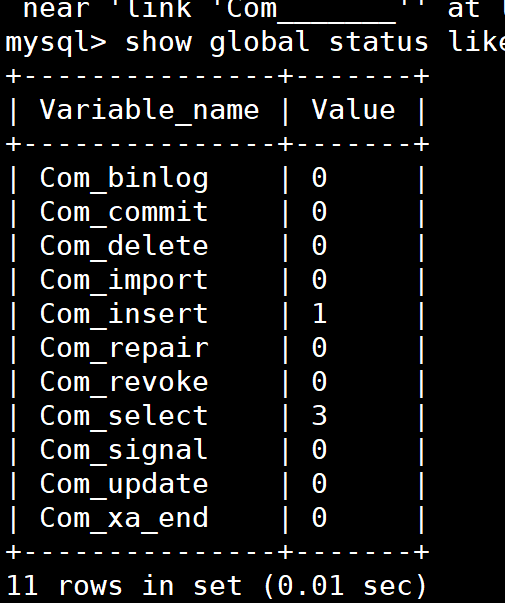
- sql执行频率: mysql客户端连接成功之后,通过show [session|global] status 命令就可以提供服务器状态信息,通过如下指令,可以查看当前数据库的insert update ,delete,select执行的频率:
:::warning show global status like 'Com_____' -- 7个字符
:::
查询结果演示:
慢查询日志
- 慢查询日志记录了所有执行时间超过指定参数(long_query_time 默认为10秒) 的所有sql语句的日志,mysql的慢查询日志默认没有开启,需要在mysql的配置文件(/etc/my.cnf)中配置信息(但是ubuntu上好像不行):

- 利用 show variables like 'slow_query_log' 可以查看慢查询日志是否开启
profile详情
- show profiles可以在sql优化时帮助我们了解事件都耗费在哪里,利用have_profiling参数,可以看到当前Mysql是否支持profile操作,利用select @@have_profiliing 命令查看
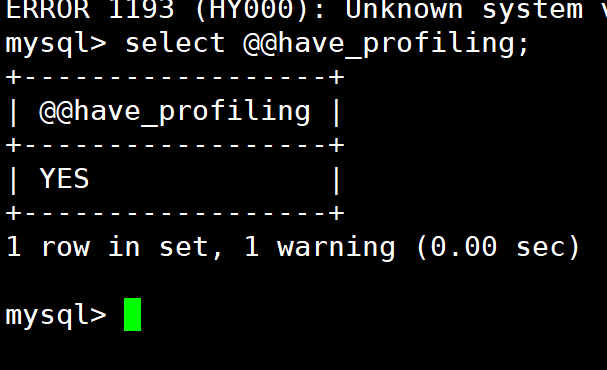
- 默认profile没有 开启,需要利用 set profiling =1 指定开启状态
# 查看每一条sql的耗时基本情况
show profiles;
# 查看指定query_id 的sql语句的各个阶段耗时情况
show profile for query query_id;
# 查看指定的query_id的sql语句的cpu使用情况
show profile cpu for query query_id;
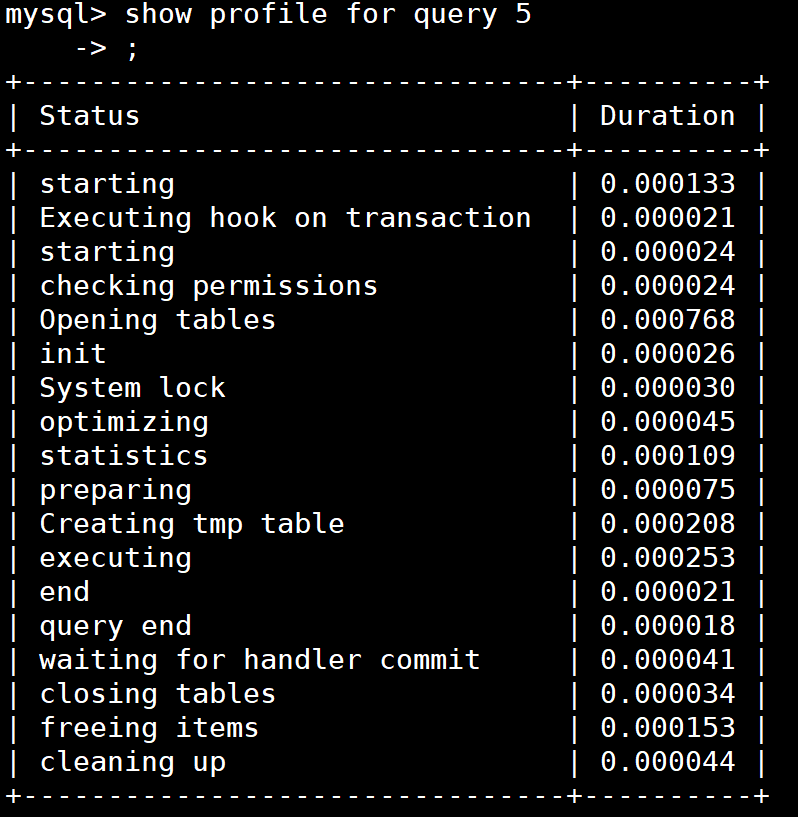
sql执行阶段的耗时:
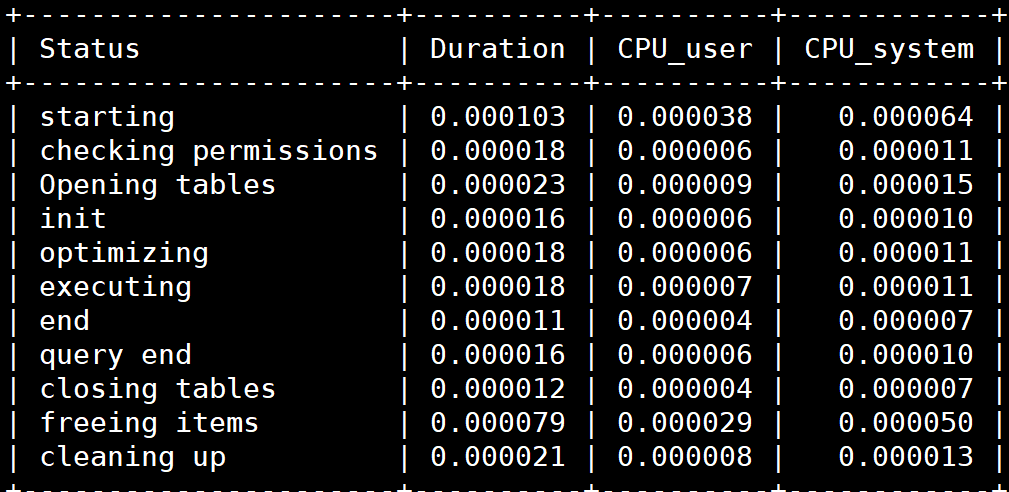
sql占用cpu的情况:
explain执行计划
- explain 或者desc命令后去mysql如何执行select 语句的信息,包含select语句执行过程中如何连接和连接的顺序
:::warning
- 语法如下 (直接在select语句前面加上explain或者desc即可)
explain/desc select 字段列表 from 表名 where 条件
:::
- 执行计划示例:

各个字段的含义
- id : select 查询的序列号,表示查询中执行select子句或者操作表的顺序(id相同,执行顺序从上向下,id不同,执行顺序从下到上,值越大越先执行)(id可以相同,利用规则查看执行顺序)(说明id的大小代表优先级的大小)
- select_type: 表示select 的类型,常见的取值有simple(简单表,只有单表查询),primary(主查询,就是外层的查询),union(union中第二个或者后面的查询语句),subquery(select/where之后包含子查询)等
- type: 表示连接类型,性能由好到坏的连接类型有NULL(不用访问任何表的情况),System,const(使用唯一以索引进行查询),eq_ref,ref(使用非唯一索引),range,index(表示遍历了索引),all (决定优化是否成功)
- possible_key: 显示可能应用到这张表上的索引,一个或者多个
- key: 实际用到的索引,如果为null,就表示没有使用索引
- key_len: 表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失准确性的情况下,长度越短越好
- rows:Mysql认为必须执行查询的函数,在InnoDB存储引擎中,是一个估计值,可能并不准确
- filtered: 表示返回结果的行数占需要读取行数的百分比,值越大越好
- extra: 额外展示的字段(有时候也可以反应sql语句执行的效率)
索引的使用
验证索引优化情况的方法
- 在没有建立索引之前,执行如下sql语句,查看sql语句的耗时,建立索引之后再查询一遍
:::warning select * from tb_sku where sn = '100000003145001'; 只是一个例子,不是必须的
:::
- 建立索引之后还可以实验一次查看一下时间,执行时间会自动显示(加上id = 1/G可以分行展示)(create index idx_表名_字段名 on 表(字段)
索引的使用原则
最左前缀法则(针对联合索引,查询条件中不要跳过某一个中间的字段,否则就不会使用索引(或者跳过某一列查询失效))
- 如果索引了多列(联合索引),需要遵循最左前缀法则,最左前缀法则就是指查询从索引的最左列开始,并且不跳过索引中的列,如果跳跃了某一列,索引就会部分失效(后面的索引就会失效)
- 索引失效,基本和连接条件中各个条件的位置没有关系,只需要最左边的索引存在就可以了
范围查询
- 联合索引中,如果出现范围查询(> <),范围 查询右侧的索引就会失效
- 解决方法: 尽量使用 >= <= 等比较运算符号,此时右侧的索引就会失效
索引失效情况1
索引列运算
- 不要再索引上进行运算操作(就是用对应的字段进行查询),否则索引就会失效 (利用expain查看索引是否使用)
字符串不加单引号
- 字符串类型不加单引号,索引就会失效
模糊匹配
- 如果仅仅是尾部进行模糊匹配(比如 软件%),索引不会失效,如果是头部进行模糊匹配,索引就会失效
索引失效情况2
or连接的条件
- 用or 分割开的索引,如果or前面的条件中的字段有索引,但是后面的字段中没有索引,那么涉及的索引就都不会用到(其实利用or连接的条件中涉及到的两个字段都有索引索引才不会失效)
- 解决方法: 给没有索引的字段创建索引就可以了
数据分布影响
- 如果MySQL评估使用索引比全表更慢,就不会使用索引(比如所有数据都会满足,或者表中绝大多数满足条件,全表扫描就会快于索引)(如果返回的数据为绝大多数数据,就会返回全表扫描,如果返回的数据较少就会使用索引)
SQL提示
- SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些认为的提示来达到优化操作的目的
具体分类如下:
-- use index (使用索引)
-- explain select * from 表名 use index (索引名称) where 条件 例如
explain select * from tb_user use index (idx_user_pro) where profession = '软件工程';
-- ignore index (忽略索引)
-- explain select * from 表名 ignore index(索引名称) where prefession = '软件工程';
explain select * from tb_user ignore index (idx_user_pro) where profession = '软件工程';
-- force index(强制使用索引)
-- explain select * from 表名 froce index (索引名称) where 条件
explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';
覆盖索引
- 尽量使用覆盖索引(查询使用了索引,并且需要返回的字段,在这个索引中可以全部被找到),在该字段中已经全部可以找到了,减少了select *
- 这些差异会体现在extra中,如果extra中出现的信息不同,就说明查询效率降低
:::warning
extra中的补充内容 :
- using index condition: 查找使用了索引,但是需要回表查询(其实就是首先利用二级索引找到主键,之后再根据主键找到待展示的数据)
- using where;using index : 查找使用了索引,但是需要的数据都在索引中可以找到,所以不需要回表查询数据
:::
利用上述原则进行sql优化:
:::color4 对如下sql语句进行优化:
select id,username,password from user where username = 'zhangsan';
解决方案:覆盖索引的原则,应该为username和password建立联合索引
:::
前缀索引
前缀索引的概念:
- 当字符类型为字符串(varchar 或者 text等)时,有时候需要索引很长的字符串,这会使得索引变得很大,查询时回浪费大量的磁盘IO,影响查询效率,此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提升索引效率
前缀索引的创建语法:
- create index 字段名称(idx_表名_字段名缩写) on table_name(字段名(n)) // n表示提取几个字段名作为前缀
前缀长度:
- 可以根据索引的长度来决定,而选择性是指不重复的索引值(基数),和数据表中的记录总数的比值,索引选择性高则查询效率高,唯一索引的选择性是1,所以查询效率最好,求解公式如下(往往需要利用公式,需要综合考虑索引的体积和索引选择性):
:::success
- select count(distinct email) / count(*) from tb_user; -- 利用distinct就可以用于去重
- select count(distinct substring(email,1,5))/count(*) from tb_user;
:::
关于单列索引和联合索引的选择问题
- 单列索引和联合索引的定义不用多说
- 在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引,建议建立联合索引,而非单列索引
- 如何实验: 定义某一个字段,创建联合索引和单列索引,查看mysql使用了哪一个索引
- 注意创建联合索引时字段的所在的位置,再次查询时一定要满足最左前缀法则
索引的设计原则
:::color1
- 针对于数据量较大的数据库,并且查询比较繁忙的表建立索引
- 针对于常作为查询条件(where),排序条件(order by),分组(group by)操作的字段建立索引
- 尽量选择区分度高的索引建立字段(索引选择度高),尽量使用唯一索引,区分度越高,使用索引的效率就越高
- 如果是字符串类型的字段,字段的长度较长,可以根据索引体积和选择性建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,减少了回表查询,提高查询效率
- 要控制索引的数量,索引不是越多越好,索引越多,维护索引的代价越高,会影响增删改查的速度
- 如果索引列不可以存储NULL值,可以在创建表时加上非空约束,当优化器直到每一列是否包含NULL值时,它可以更好的确定哪一个所以更加有效进行用于查询
:::